26
Utilising software to enhance your research Eamonn Hynes 5 th November, 2012
| Date post: | 25-Dec-2015 |
| Category: |
Documents |
| Upload: | hilary-mason |
| View: | 219 times |
| Download: | 2 times |

Utilising software to enhance your research
Eamonn Hynes5th November, 2012

Basic statistics and some parallel computing

Basic statistics
• Probability• Mean• Standard deviation
• Simple examples:- Probability of just one six from three throws of a die?- Probability of winning the Lotto
• Tougher problems:- Transcribing speech into words- Poker robot that plays optimally
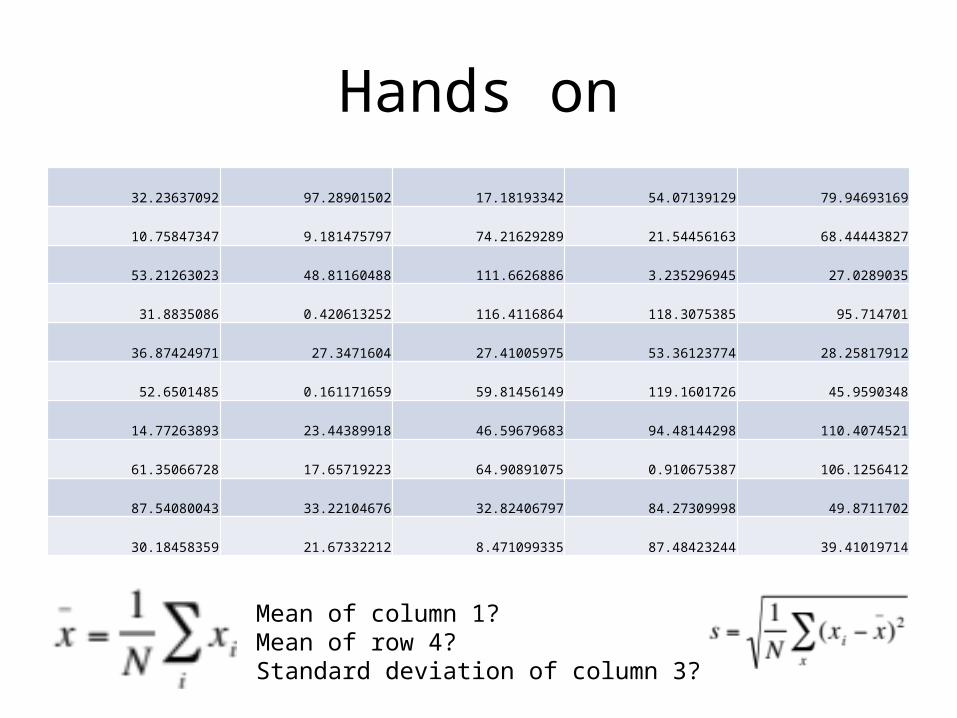
Hands on
32.23637092 97.28901502 17.18193342 54.07139129 79.94693169
10.75847347 9.181475797 74.21629289 21.54456163 68.44443827
53.21263023 48.81160488 111.6626886 3.235296945 27.0289035
31.8835086 0.420613252 116.4116864 118.3075385 95.714701
36.87424971 27.3471604 27.41005975 53.36123774 28.25817912
52.6501485 0.161171659 59.81456149 119.1601726 45.9590348
14.77263893 23.44389918 46.59679683 94.48144298 110.4074521
61.35066728 17.65719223 64.90891075 0.910675387 106.1256412
87.54080043 33.22104676 32.82406797 84.27309998 49.8711702
30.18458359 21.67332212 8.471099335 87.48423244 39.41019714
Mean of column 1?Mean of row 4?Standard deviation of column 3?
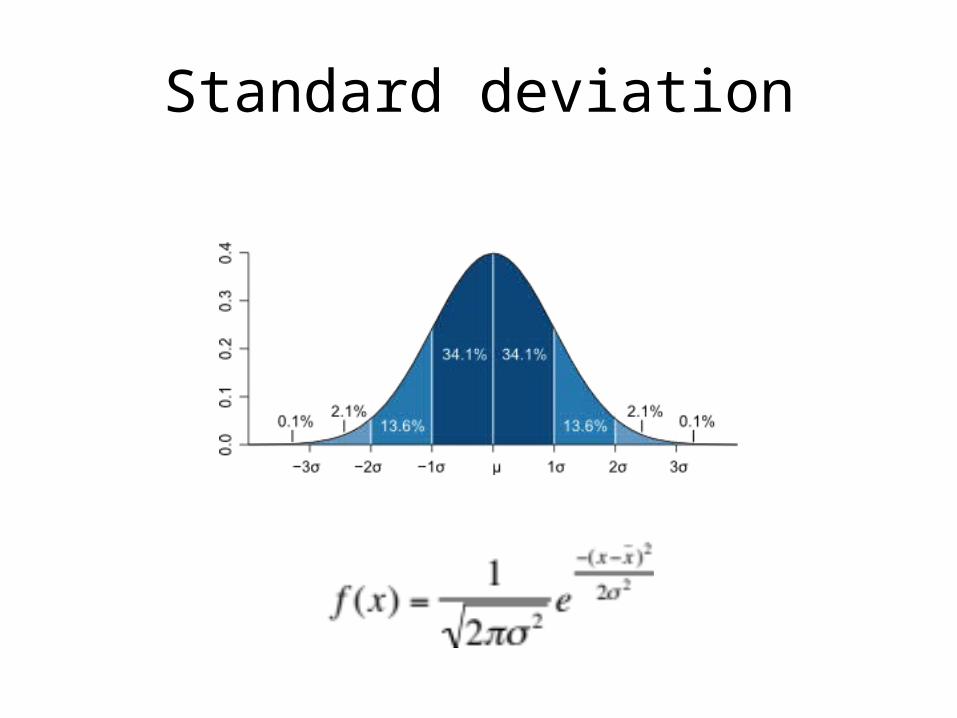
Standard deviation
13.6%
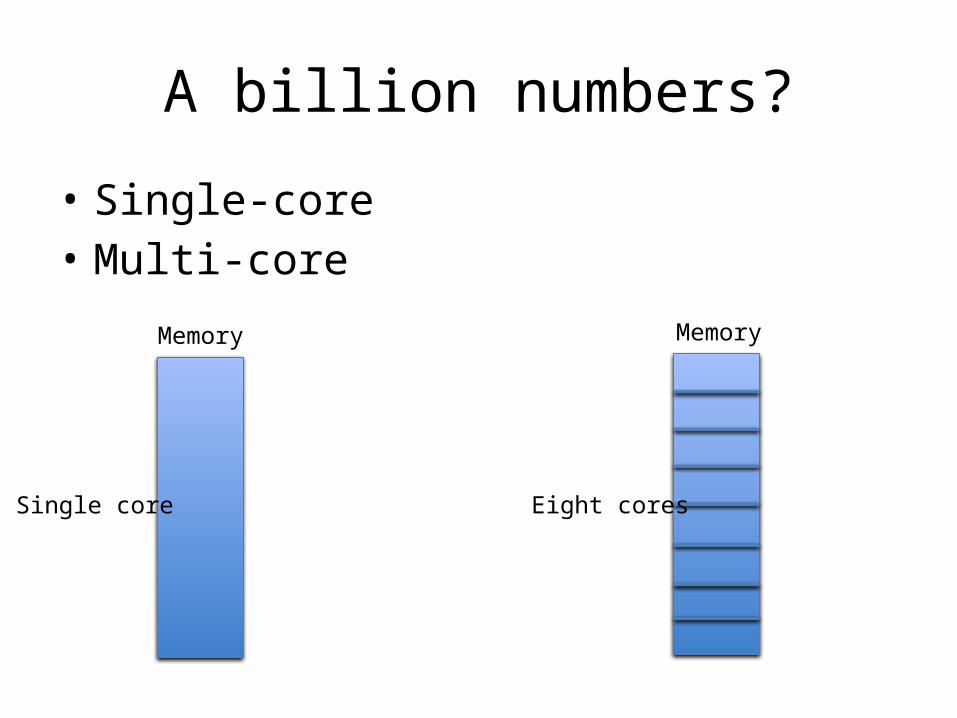
A billion numbers?
• Single-core• Multi-core
Eight coresSingle core
Memory Memory
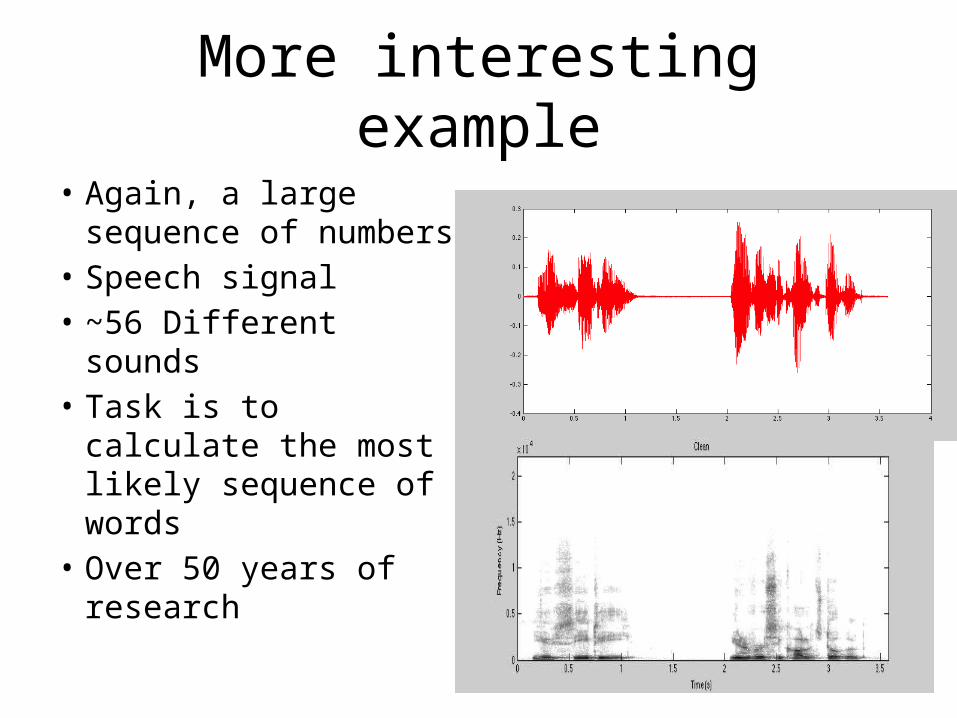
More interesting example
• Again, a large sequence of numbers
• Speech signal• ~56 Different sounds• Task is to calculate the
most likely sequence of words
• Over 50 years of research

Moore’s Law

Demise of Moore’s Law
• Reality

Moore’s Law
• The solution: – Parallel architectures– Hybrid architectures– New software – harder to write– New programming paradigms– Dedicated hardware– Beyond silicon

Amdhal’s Law
• Limitations on parallel code– Thankfully a large number of problems are parallel
in nature (rendering 3D graphics, weather prediction, image processing, DNA matching)
– But many problems are sequential in nature!– e.g. card game, legal process, ordering a laptop,
etc.– Nothing we can do except increase clock rate!

Clustering

Clustering
• Categorise data into groups• Important in many fields – speech, medical statistics, data
mining, etc.• Very loose algorithm (k-means clustering):
– Let each point be a cluster centroid– Pick a random point– Get point closest to this chosen point– Calculate centroid– Repeat until just k centroids
• Big limitation: k must be specified in advance…• Example

Clustering
• Not just for points on a 2d surface• Pixels of an image• Example

Support Vector Machines
• Support vector machines (SVMs)– Popular in the 1990s/2000s (Vapnik et al. 1992)– Non-linear classification– Beautiful maths
• Find a nonlinear boundary between k sets of points
• Example

Text analysis

Text analysis
• Searching documents task• Naïve search:– SQL query:
“SELECT * FROM articles WHERE body LIKE '%$keyword%';”
– Works fine for small document collections• Large databases: Better to index all
documents• tf-idf

Text analysis
• Process each document• Calculate the frequency of each word• Store the index, not the entire document• Much faster document retrieval• Intuitive to pick document with highest term
count• Must weight each document by the inverse
document frequency

Text analysis• Example: Simple Boolean logic• Searching for “rose”
• If word appears, then document is relevant

Text analysis
• Taking term frequencies into account

Text analysis
TFIDF = TF * IDF where:
TF = C/T where C = number of times a given word appears in a document and T = total number of words in a document IDF = D/DF where D = total number of documents in a corpus, and DF = total number of documents containing a given word

Text analysis
• Natural language follows a Zipfian distribution

Finally

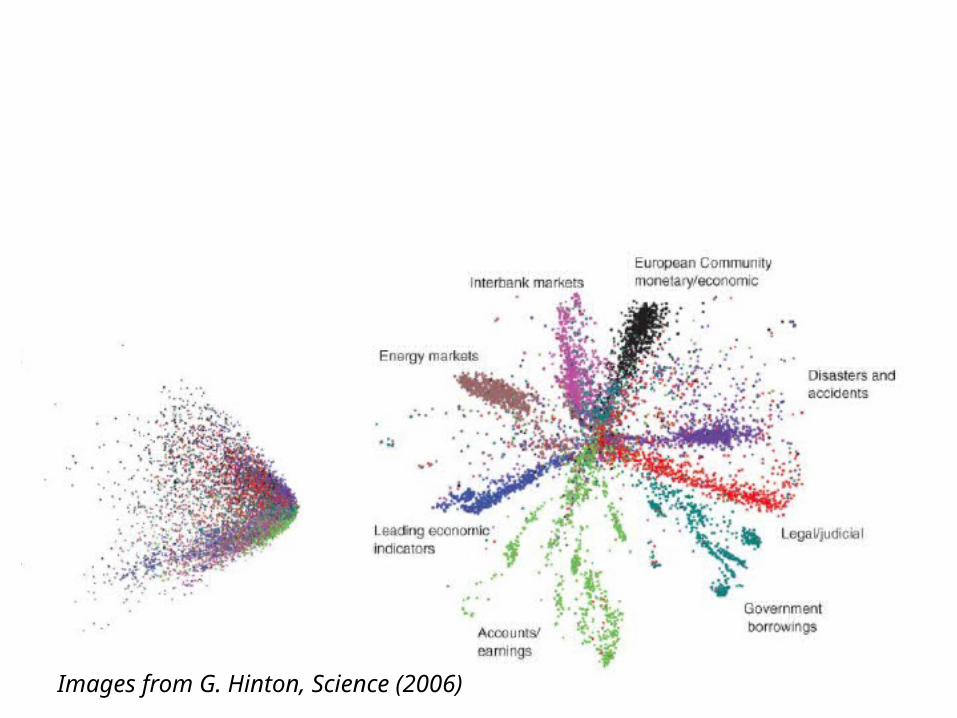
Deep belief networks
• Given a document, how to find similar documents?
• Deep belief networks (DBNs)• State-of-the-art in machine learning• More advanced than Latent Semantic Analysis
(LSA) Principal Component Analysis (PCA) and clustering

Deep belief networks
• 2000 most common word stems fed into base layer
• Gradual reduction in number of neurons
• Left with a 30-digit binary representation of a document with 2000-dimension feature vector
• Super fast document retrieval (“semantic hashing”)
Images from G. Hinton, Science (2006)
Images from G. Hinton, Science (2006)

















