Page 1
V. Megalooikonomou
Distributed Databases
(based on notes by Silberchatz,Korth, and Sudarshan and notes by C. Faloutsos at CMU)
Temple University – CIS Dept.CIS616– Principles of Data Management
Page 2
Overview Problem – motivation Design issues Query processing – semijoins transactions (recovery, conc.
control)
Page 3
Problem – definition centralized DB:
LA NY
CHICAGO
Page 4
Problem – definition distributed DB:
DB stored in many places (cites) ... connected
LA NY
Page 5
Problem – definition
distributed DB: stored in many connected cites DB typically geographically separated separately administered transactions are differentiated:
Local Global
possibly different DBMSs, DB schemas (heterogeneous)
LA NY
Page 6
Problem – definition
LA NY
EMPEMPLOYEE
connect to LA; exec sql select * from EMP; ...
connect to NY; exec sql select * from EMPLOYEE; ...
now:
DBMS1 DBMS2
Page 7
Problem – definition
LA NY
EMP
EMPLOYEE
connect to D-DBMS; exec sql select * from EMPL;ideally:
DBMS1 DBMS2
D-DBMSD-DBMS
Page 9
Pros + Cons Pros
data sharing reliability & availability autonomy (local) speed up of query processing
Cons software development cost more bugs increased processing overhead (msg)
Page 10
Overview Problem – motivation Design issues Query processing – semijoins transactions (recovery, conc.
control)
Page 11
Design of Distr. DBMS Homogeneous distr. DBs
Identical DBMS Same DB Schema Aware of one another Agree to cooperate in transaction processing
Heterogeneous distr. DBs Different DBMS Different DB Schema May not be aware of one another May provide limited facilities for cooperation in
transaction processing
Page 12
Design of Distr. DBMS
what are our choices of storing a table?
Page 13
Design of Distr. DBMS replication (several copies of a
table at different sites) fragmentation (horizontal; vertical;
hybrid) or both…
Page 14
Design of Distr. DBMS Replication: a copy of a relation is
stored in two or more sites Pros and cons
Availability Increased parallelism (possible
minimization of movement of data among sites)
Increased overhead on update (replicas should be consistent)
Page 15
Design of Distr. DBMS
ssn name address
123 smith wall str.
... ... ...
234 johnson sunset blvd
horiz.
fragm.
vertical fragm.Fragmentation:
• keep tuples/attributes at the sites where they are used the most• ensure that the table can be reconstructed
Page 16
Transparency & autonomy
Issues/goals: naming and local autonomy replication transparency fragmentation transparency location transparencyi.e.:
Page 17
Problem – definition
LA NY
EMP
EMPLOYEE
connect to D-DBMS; exec sql select * from EMPL;ideally:
DBMS1 DBMS2
D-DBMSD-DBMS
Page 18
Overview Problem – motivation Design issues Query processing – semijoins transactions (recovery, conc.
control)
Page 19
Distributed Query processing
issues (additional to centralized q-opt) cost of transmission
parallelism / overlap of delays
(cpu, disk, #bytes-transmitted, #messages-transmitted)
minimize elapsed time?
or minimize resource consumption?
Page 20
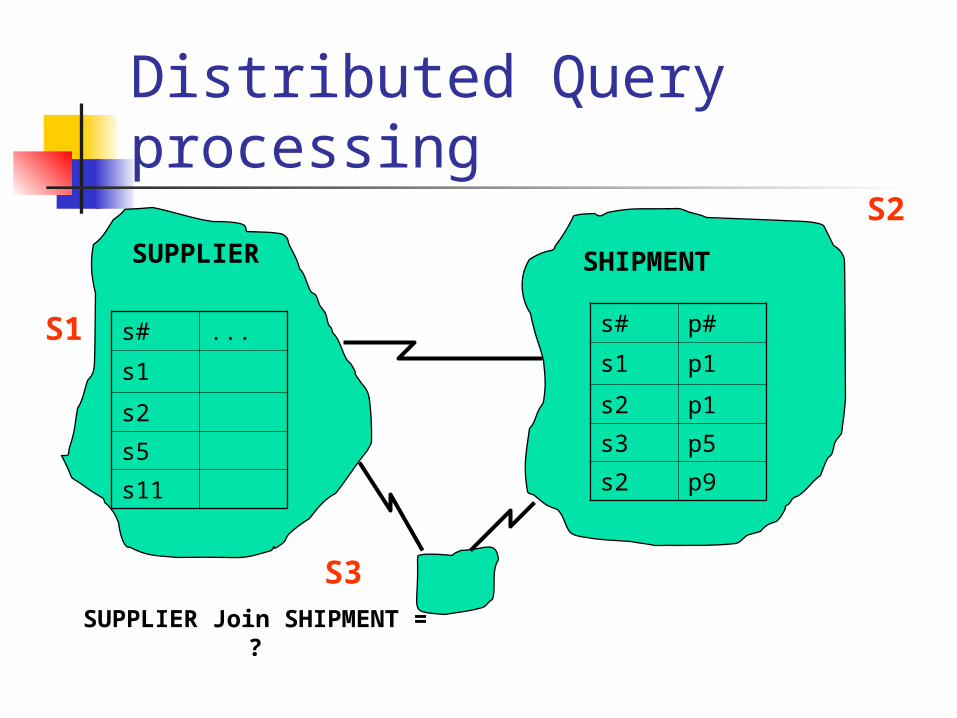
Distributed Query processing
s# ...
s1
s2
s5
s11
S1
SUPPLIER
s# p#
s1 p1
s2 p1
s3 p5
s2 p9
SHIPMENT
S2
S3SUPPLIER Join SHIPMENT = ?
Page 21
semijoins choice of plans? plan #1: ship SHIP -> S1; join; ship ->
S3 plan #2: ship SHIP->S3; ship SUP->S3;
join ... others?
Page 22
Distr. Q-opt – semijoins
s# ...
s1
s2
s5
s11
S1
SUPPLIER
s# p#
s1 p1
s2 p1
s3 p5
s2 p9
SHIPMENT
S2
S3SUPPLIER Join SHIPMENT = ?
Page 23
Semijoins
Idea: reduce the tables before shipping
s# ...
s1
s2
s5
s11
S1
SUPPLIER
s# p#
s1 p1
s2 p1
s3 p5
s2 p9
SHIPMENT
S3SUPPLIER Join SHIPMENT = ?
Page 24
Semijoins How to do the reduction, cheaply? E.g., reduce ‘SHIPMENT’:
Page 25
Semijoins
Idea: reduce the tables before shipping
s# ...
s1
s2
s5
s11
S1
SUPPLIER
s# p#
s1 p1
s2 p1
s3 p5
s2 p9
SHIPMENT
S3SUPPLIER Join SHIPMENT = ?
(s1,s2,s5,s11)
Page 26
Semijoins Formally: SHIPMENT’ = SHIPMENT
SUPPLIER express semijoin w/ rel. algebra
Page 27
Semijoins Formally: SHIPMENT’ = SHIPMENT
SUPPLIER express semijoin w/ rel. algebra
)(
'
SR
SRR
R
Page 28
Semijoins – e.g.: suppose each attr. is 4 bytes Q: transmission cost (#bytes) for
semijoinSHIPMENT’ = SHIPMENT semijoin
SUPPLIER
Page 29
Semijoins
Idea: reduce the tables before shipping
s# ...
s1
s2
s5
s11
S1
SUPPLIER
s# p#
s1 p1
s2 p1
s3 p5
s2 p9
SHIPMENT
S3SUPPLIER Join SHIPMENT = ?
(s1,s2,s5,s11)
4 bytes
Page 30
Semijoins – e.g.: suppose each attr. is 4 bytes Q: transmission cost (#bytes) for
semijoinSHIPMENT’ = SHIPMENT semijoin
SUPPLIER A: 4*4 bytes
Page 31
Semijoins – e.g.: suppose each attr. is 4 bytes Q1: give a plan, with semijoin(s) Q2: estimate its cost (#bytes
shipped)
Page 32
Semijoins – e.g.: A1:
reduce SHIPMENT to SHIPMENT’ SHIPMENT’ -> S3 SUPPLIER -> S3 do join @ S3
Q2: cost?
Page 33
Semijoins
s# ...
s1
s2
s5
s11
S1
SUPPLIER
s# p#
s1 p1
s2 p1
s3 p5
s2 p9
SHIPMENT
S3
(s1,s2,s5,s11)
4 bytes
4 bytes 4 bytes
4 bytes
Page 34
Semijoins – e.g.: A2:
4*4 bytes - reduce SHIPMENT to SHIPMENT’ 3*8 bytes - SHIPMENT’ -> S3 4*8 bytes - SUPPLIER -> S3 0 bytes - do join @ S3
72 bytes TOTAL
Page 36
Other plans?
P2: reduce SHIPMENT to SHIPMENT’ reduce SUPPLIER to SUPPLIER’ SHIPMENT’ -> S3 SUPPLIER’ -> S3
Page 37
Other plans?
P3: reduce SUPPLIER to SUPPLIER’ SUPPLIER’ -> S2 do join @ S2 ship results -> S3
Page 38
A brilliant idea: two-way semijoins
(not in book, not in final exam) reduce both relations with one more
exchange: [Kang, ’86] ship back the list of keys that didn’t
match CAN NOT LOSE! (why?) further improvement:
or the list of ones that matched – whatever is shorter!
Page 39
Two-way Semijoins
s# ...
s1
s2
s5
s11
S1
SUPPLIER
s# p#
s1 p1
s2 p1
s3 p5
s2 p9
SHIPMENT
S3
(s1,s2,s5,s11)
(s5,s11)
S2
Page 40
Overview Problem – motivation Design issues Query processing – semijoins transactions (recovery, conc.
control)
Page 41
Transactions – recovery Problem: e.g., a transaction moves
$100 from NY $50 to LA, $50 to Chicago 3 sub-transactions, on 3 systems how to guarantee atomicity (all-or-
none)? Observation: additional types of
failures (links, servers, delays, time-outs ....)
Page 42
Transactions – recovery Problem: e.g., a transaction moves
$100 from NY -> $50 to LA, $50 to Chicago
Page 43
Distributed recovery
NY
CHICAGO
LA NY
T1,1:-$100
T1,2: +$50
T1,3: +$50
How?
Page 44
Distributed recovery
NY
CHICAGO
LA NY
T1,1:-$100
T1,2: +$50
T1,3: +$50
Step1: choose coordinator
Page 45
Distributed recovery Step 2: execute a commit protocol, e.g., “2 phase commit” when a transaction T completes
execution (i.e., when all sites at which T has executed inform the transaction coordinator Ci that T has completed) Ci starts the 2PC protocol
->
Page 46
2 phase commit
time
T1,1 (coord.) T1,2 T1,3
prepare to commit
Page 47
2 phase commit
time
T1,1 (coord.) T1,2 T1,3
prepare to commit
Y
Y
Page 48
2 phase commit
time
T1,1 (coord.) T1,2 T1,3
prepare to commit
Y
Y
commit
Page 49
2 phase commit (e.g., failure)
time
T1,1 (coord.) T1,2 T1,3
prepare to commit
Page 50
2 phase commit
time
T1,1 (coord.) T1,2 T1,3
prepare to commit
Y
N
Page 51
2 phase commit
time
T1,1 (coord.) T1,2 T1,3
prepare to commit
Y
N
abort
Page 52
Distributed recovery Many, many additional details
(what if the coordinator fails? what if a link fails? etc)
and many other solutions (e.g., 3-phase commit)
Page 53
Overview Problem – motivation Design issues Query processing – semijoins transactions (recovery, conc.
control)
Page 54
Distributed conc. control also more complicated: distributed deadlocks!
Page 55
Distributed deadlocks
NY
CHICAGO
LA NYT1,la
T2,la
T1,ny
T2,ny
Page 56
Distributed deadlocks
LA NY
T1,la
T2,la
T1,ny
T2,ny
Page 57
Distributed deadlocks
LA NY
T1,la
T2,la
T1,ny
T2,ny
Page 58
Distributed deadlocksLA NY
T1,la
T2,la
T1,ny
T2,ny
• cites need to exchange wait-for graphs
• clever algorithms, to reduce # messages
Page 59
Conclusions Distr. DBMSs: not deployed BUT: produced clever ideas:
semijoins distributed recovery / conc. control
which can be useful for parallel db / clusters ‘active disks’ replicated db (e-commerce servers)