16
Violin Memory November, 2010 Violin Memory vRAID Flash RAID Overview

Violin Memory November, 2010
Violin Memory vRAID
Flash RAID Overview

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 2
Table of Contents
Violin Executive Overview............................................................................................................... 3
Flash Technology in the datacenter ................................................................................................ 4
SSD Performance over time......................................................................................................... 5
SSD vs. HDD.................................................................................................................................. 5
PCIe Based SSDs ........................................................................................................................... 5
Flash introduces new RAID challenges ........................................................................................ 6
Violin vRAID ................................................................................................................................. 8
RAID Comparison ....................................................................................................................... 11
Appendix ....................................................................................................................................... 12
RAID Overview ........................................................................................................................... 12
RAID Types ................................................................................................................................. 13
RAID 0: Striping....................................................................................................................... 13
RAID 1: Mirroring.................................................................................................................... 14
RAID 5: Rotating Parity ........................................................................................................... 14
RAID 6: Dual Rotating Parity ................................................................................................... 15
RAID 10: Nested Striping and Mirroring ................................................................................. 15
JBOD ....................................................................................................................................... 15
Contact Violin................................................................................................................................ 15

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 3
Violin Executive Overview
Violin Memory pioneered and leads the Memory Array market segment allowing the Enterprise to realize the long-‐held ideal of balancing the performance of computing, networking, and storage resources. Violin’s 3200 series product line brings flash memory into the Enterprise Data Center with inherent reliability (vRAID), sustained throughput, market-‐leading and “spike free” latency, and Enterprise class availability, reliability, and serviceability.
Today’s performance storage solutions are built with low-‐cost disk drives aggregated by external controllers and software to ensure data reliability; usually using various forms of RAID. While massive aggregation of drives, be they magnetic or solid-‐state, can ramp up throughput (IOPS), the overhead of the controllers and legacy hard-‐drive interfaces act to limit improvements to latency performance. Typically, storage providers do not talk much about latency because within traditional storage arrays it cannot be improved by scaling the quantity of drives.
Violin Memory solves both the throughput (IOPS) problem and the latency problem in its Memory Arrays by embedding RAID within Violin’s patent pending switched-‐memory architecture in an integrated platform: NAND flash bundled into hot-‐swappable memory modules (VIMMs) using hardware flash RAID controllers designed specifically to aggregate the flash and protect the data within the Memory Array itself. The RAID controller is integrated for low cost, low latency and high-‐speed performance…and not an add-‐on or separate controller. Violin’s unique tightly-‐embedded vRAID enables the delivery of Violin’s sustained performance with very low, spike-‐free latency.
Figure 1: Violin Flash Aggregation

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 4
Violin’s switched memory architecture allows for a unique scalable and reliable aggregation of any type of memory into a sharable Memory Array. The use of Violin Memory Modules (VIMM) enables the aggregation of ten(s) of terabytes of RAID-‐protected capacity in a minimal amount of space, with every component hot swappable and easily serviced. Violin’s current production product (Summer 2010) delivers 10 terabytes in 3 rack units. Density is increased by improving the capacity of the individual VIMMs, which is possible by leveraging the sweet spot for commodity flash pricing.
Violin’s Flash Memory Arrays offer better price and performance metrics than traditional performance storage with or without SSDs. Enterprise customers now have a few new options to take advantage of when optimizing new centralized storage platforms. These decisions should be first and foremost be based on the throughput and latency requirements of the applications being run. In traditional storage arrays it can be very costly to allocate spindles based on the performance needed for the IOPS that the application or dataset requires. Along with vendor maintenance costs, data center space, cooling and electricity, the cost per IOPS can grow exponentially, resulting in an inefficient storage model.
Violin Memory appliances can provide a superior storage efficiency model by utilizing a high availability flash Memory Array architecture with:
• 10x the performance, in • 1/10 of the space, and at • less than half the cost of traditional storage arrays.
This provides for a greater ROI in the enterprise datacenter saving cost on footprint, cooling and electricity, etc. Increased application performance and CPU utilization makes the business case very compelling.
Flash Technology in the Datacenter
The benefits of NAND flash to the enterprise as non-‐volatile high-‐speed memory have been known for many years. Price was the initial barrier to adoption, but as consumer device penetration (and their considerable use of flash memory) has exploded it has driven the price down to levels where a significant investment in flash based storage technologies makes economic sense. The first approach was packaging NAND flash in HDD form factors, creating the SSDs heard about so often in the press. The second generation is composed of a number of companies that have built PCIe cards to make use of the high-‐speed (PCIe) connection to the server CPU and build flash memory cards. Both HDD form factor and PCIe card form factor approaches have merit for limited applications with lower performance and/or reliability requirements. However, when one looks at creating a networked shared high-‐capacity silicon memory tier for the enterprise datacenter one needs to decide “what is the right way to aggregate NAND flash” for a broader set of critical applications.

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 5
SSD Performance over time
Any flash device will operate at its best performance until it becomes filled with data and the controller software needs to reclaim retired blocks – i.e. “garbage collection,” “page reclamation” or “grooming.” Flash blocks must be erased (reclaimed) in order for new data to be written while at the same time handling wear leveling and error handling. The “cost” in performance from these background and controller functions shows up only after filling the device past its base capacity, which stresses the device as it would be used in a typical 7 x 24 x 365 enterprise datacenter.
Flash operates differently than DRAM. While DRAM can be read and written at nearly the same speed at very granular levels, flash cannot. If a flash block is being erased, data in the flash chip cannot be read during that interval, which can range from 2-‐10 milliseconds. Reads, on the other hand, can normally happen in 50us – this causes a queue of reads to pile up waiting for the erase to finish and potentially results in severe latency spikes and HDD-‐like response times. Latency spikes are the most common complaint of enterprise SSD customers. Violin Memory’s vRAID technology avoids latency spikes while delivering consistent high-‐speed performance.
SSD vs. HDD
Most traditional storage vendors implement flash technology as Solid States Drives (SSDs) utilizing a Hard Disk Drive (HDD) form factor as well as the associated protocols, controllers, and management tools. Using the current HDD form factor takes advantage of the extensive disk aggregation infrastructure already in place to mount and connect drives to the host system. But, but this has quickly exposed the limitations of today’s aggregation technologies; a shelf that might normally house 24 HDDs may only support 2 SSDs before overtaxing the aggregation controller.
Adding flash to existing storage system captures some of throughput advantages of flash drives, although less than a PCIe card or a Memory Array. However, compared with a PCIe card or Memory Array latency is a couple of orders of magnitude greater.
PCIe Based SSDs
PCIe-‐based flash cards take advantage of the speed and low latency of the PCIe bus in the server. This works well for raw performance but this is usually at the expense of consuming considerable server CPU and memory resources to manage the metadata for the PCIe card itself. The end result is that the applications you are trying to accelerate may actually be competing for compute resources with the SSD chosen to accelerate the application in the first place.
• The biggest limitation of a PCIe-‐based flash storage card is it cannot be shared, or managed across all of the datacenter servers and applications.
• While a single server can see a large performance benefit from a PCIe-‐based flash card, enterprise use is limited to a narrow set of applications because of two important factors:
o The server itself can fail, or the PCIe cards can fail, meaning the application
delivery cannot be dependent on any single server.

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 6
o PCIe cards are not hot-‐swappable and enterprises typically do not service servers. This means the maintainability of a PCIe-‐based card solution is difficult for most IT shops.
Flash introduces new RAID challenges
The implementation of RAID in any memory or storage system defines much of that system’s performance along the dimensions of redundancy, reliability, and availability, as well as price. Because of the specific flash issues described above, the common types of RAID algorithms do not work well with flash. Specifically, RAID5 and 6, which use Read-‐Modify-‐Write algorithms, add latency and reduce IOPS, reducing the overall performance benefits of flash memory. RAID 0 is unreliable since there is no redundancy; and RAID 1 is inefficient and expensive since all data (and hardware) is mirrored.
The last 20 years have seen tremendous advances in algorithms for managing rotating media devices: RAID algorithms, disk access elevator algorithms, database algorithms, OS buffering algorithms. All have been optimized for this storage technology. The most convenient way for existing vendors to treat flash, therefore, would be as another HDD that runs one hundred times faster.
Even when used in that fashion, flash provides some performance benefits. In particular, random reads with lower latency and higher IOPS can be provided. Unfortunately, flash is a very different technology than HDDs and has its own issues. These flash challenges need their own algorithmic solutions:
1. Flash Writes are slower than Reads. 2. Flash Writes must be sequential within a Flash “block” (typically 128-‐256 Kbyte). 3. Flash blocks are larger than user data blocks, and hence a mapping system is required. 4. Flash blocks must be erased before they are written. 5. Flash Erases take a long time (milliseconds) and can block Reads or Writes to the same
chip. 6. Flash blocks can only be erased a number of times before they physically wear out and
cannot be used again. 7. Flash errors increase with Reads. 8. Flash loses data over time, even when not being used. 9. Flash can fail at the block, page, or die level; all of which must be accounted for.
These issues are most obvious when measuring the sustained random write performance of flash SSDs. The performance is initially good when the flash memory is clean or empty, but drops dramatically (over a so-‐called “Write Cliff”) when the blocks have to be recycled in a process called Garbage Collection (or grooming or page reclamation.) An online forum called Anand Tech provided a review of two higher-‐performing PC SSDs that showed the significance of the Write Cliff with random 4K IOPS. PCIe cards suffer from the same issue.

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 7
Figure 2: The Flash SSD Write Cliff
Violin solves these challenges through high-‐performance flash controllers and a purpose-‐built flash RAID algorithm: vRAID. This results in a sustained performance profile and does not suffer from the going over the infamous “Write Cliff”.
Figure 3: Violin Sustained Writes

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 8
Violin vRAID
Violin Memory’s primary innovation is a hardware-‐based flash vRAID. It is cost effective, highly reliable, imposes low overhead, and guarantees sustained performance and application acceleration. Most important, a flash Erase can never delay a Read or a Write.
The benefits of vRAID:
• Significantly lower latency, free of latency spikes.
• 80% flash efficiency for lower cost per GByte (compared to 50% efficiency for RAID 1)
• Massively parallel striping for high bandwidth and IOPS
• Fail-‐in-‐place support of flash memory device failures
• Fast rebuilds that have minimal impact on application performance
• RAID-‐6 like data loss rates
• Convenient serviceability through hot swap and fail-‐in-‐place capabilities
This paper provides an overview of the patent-‐pending vRAID used in Violin Memory Arrays. A single 3U appliance provides over 10TB of SLC flash capacity with integrated hardware flash RAID and 250K sustained IOPS. vRAID is designed to enable cost-‐effective and large-‐scale deployment of flash in the enterprise data center.
Figure 4: Violin 3200 VIMMs

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 9
Data comes into the Violin Memory Array as blocks of any size from 512Bytes to 4Mbytes using a Logical Block Address (LBA). Larger blocks are split into 4K blocks and striped across multiple RAID groups to raise bandwidth and lower latency. Each RAID group consists of five Violin Intelligent Memory Modules (VIMMs); four Data and one Parity. The 4K block is written as 5 x 1K pages, each of which share a Logical Page Address, but on different VIMMs.
Each 1K page is independently managed by the VIMM and can be assigned to any of the flash memory devices on the VIMM. This approach improves the scalability and performance of the RAID controller while eliminating complexity from redundant RAID controller schemes.
If any flash die/block fails, its data is reconstructed using the parity VIMM. This fail-‐in-‐place capability allows faults to be managed without data loss and without having to replace VIMMs. Violin’s Memory Array supports up to four hot spare VIMMs to enable this fail-‐in-‐place capability.
Failed VIMMs can be replaced at the next convenient maintenance cycle, a very convenient serviceability feature. In the meantime, the RAID group is rebuilt using one of the spare VIMMs in the system. No data is lost and the fast rebuild reduces the probability of a secondary fault occurring during this time window.
Additionally, flash bit errors are normally corrected using the ECC protection provided across each 1K block. Any VIMM errors due to metadata corruption or other causes are detected with a RAID Check (RC) code.
vRAID reduces latency for 4K block reads in two ways:
• Striping 4K across five VIMMs allows flash devices to Read and Write in parallel with increased bandwidth
• vRAID (patent-‐pending) has the capability to ensure that multi-‐millisecond Erases never block a Read or Write. This architectural feature enables spike-‐free latency in mixed Read/Write environments. This is possible because only 4 out of 5 VIMMs need to be read at any time.

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 10
Figure 5: Violin vRAID
Two cases of these latency benefits of vRAID are shown in the figure below. The first case shows a load level at 10% of rated capacity. Even at 10% load the latency of vRAID is many times lower than a comparable RAID stripe of SSDs. Violin striping is more granular and its RAID is embedded in hardware; both of which reduce latency.
Figure 6: Violin Latency vs RAIDed SSDs at 10% load
Violin Memory Flash Overview Technical Whitepaper
Violin Memory 11
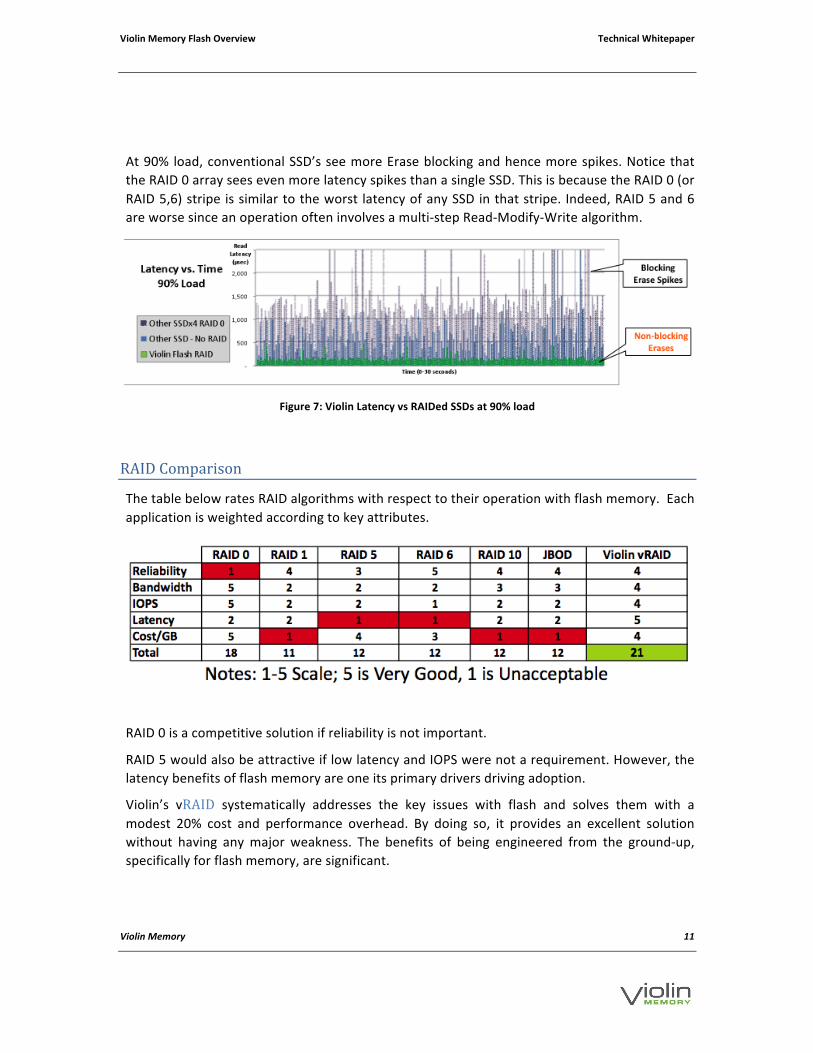
At 90% load, conventional SSD’s see more Erase blocking and hence more spikes. Notice that the RAID 0 array sees even more latency spikes than a single SSD. This is because the RAID 0 (or RAID 5,6) stripe is similar to the worst latency of any SSD in that stripe. Indeed, RAID 5 and 6 are worse since an operation often involves a multi-‐step Read-‐Modify-‐Write algorithm.
Figure 7: Violin Latency vs RAIDed SSDs at 90% load
RAID Comparison
The table below rates RAID algorithms with respect to their operation with flash memory. Each application is weighted according to key attributes.
RAID 0 is a competitive solution if reliability is not important.
RAID 5 would also be attractive if low latency and IOPS were not a requirement. However, the latency benefits of flash memory are one its primary drivers driving adoption.
Violin’s vRAID systematically addresses the key issues with flash and solves them with a modest 20% cost and performance overhead. By doing so, it provides an excellent solution without having any major weakness. The benefits of being engineered from the ground-‐up, specifically for flash memory, are significant.

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 12
Appendix
RAID Overview
Redundant Array of Inexpensive Disks (RAID) was invented in the 1980s by Garth Gibson and David Patterson. The technology behind RAID, ironically enough, originated with the objective of making redundant memory systems. However, it has gained widespread acceptance managing Hard Disk Drives (HDDs), affectionately known as “Rotating Rust”. More recently, the term “Independent” has been substituted for “Inexpensive”.
Violin has extended the original RAID technology with techniques specific to flash memory. These techniques are described in Section 5. However, in this case “Devices” should be substituted for “Disks” since nothing rotates except for the fans.
Why is RAID so important? It’s used as the primary aggregation technology for thousands of disk drives and is designed to solve the following problems; reliability, bandwidth and IOPS. The challenge is to solve them without adding significantly to latency and cost.
Reliability
There’s a saying that there are only two types of disk drives; those that have failed and those that are about to fail! Fundamentally, it’s hard to make disk drives any more reliable that they already are. Placing a magnetic recording head microns from a piece of magnetic media rotating at 15K rpm is an amazing piece of engineering. The outer edge of a 3.5” disk is moving almost at the speed of sound.
HDDs fail and wear out, but data loss is not acceptable. In some situations, nightly back-‐ups to tape are adequate protections. For most businesses, though, real-‐time recovery from disk failure is critical. In large data centers with hundreds of thousands of HDDs and hence frequent failures, RAID or some other form of redundancy is required for operational reliability and simplicity.
Bandwidth
Individual HDDs are too slow to keep up with modern processors. An individual HDD can provide between 1 and 200 MB per second, depending on how it’s accessed. An individual multi-‐core processor can consumer over 1GB/s. This is equivalent to 100 disk drives for most applications. Clearly, the hard drive is the primary performance constraint in modern computer systems.
RAID enables many disk drives to be aggregated (striped) into a single Logical Unit (LUN) that an application can access as if it were a single drive. That LUN can have bandwidth which is measured in GB/s. While this increases the cost, it simplifies applications and their configuration.
IOPS
Similar to bandwidth constraints, HDDs are limited by the physics of rotating media to about 400 Input/Outputs per Second (IOPS). A CPU can consume about 400,000 IOPS or the IOPS of

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 13
1,000 disk drives. RAID enables the creation of a single LUN which aggregates the IOPS of many HDDs, but unfortunately, RAID reduces IOPS if reliability is also required.
Latency
The latency of HDDs is limited by their rotational speeds and head seek times. Typically read latency is 4-‐10ms. Write latency is much less of an issue because of write buffers/caches and the ability for file systems to write sequentially, which is much faster than random reading of the drive.
RAID algorithms impact latency is several ways:
1. Wider striping means that smaller transfers are required from each HDD 2. Wide striping also means that a Read must wait for all HDDs to complete their
transfer before that Read can be completed. Worst-‐case latency becomes more important.
3. Smart queuing (e.g. elevator algorithms) can increase bandwidth and IOPS, but at the expense of latency.
Cost per GB
All RAID algorithms rely on writing some amount of redundant data. As a consequence, storage capacity is less efficiently used and hence the cost per GB to the user is increased. Minimizing the additional cost per GB is always a goal.
RAID Types
Multiple RAID types have been developed for HDDs. Each flavor of RAID has a different set of characteristics and was typically designed to solve a specific HDD problem. The following RAID algorithms are of specific interest to users of Flash memory.
For each RAID type, there are several metrics that have to be considered:
• Reliability
• Bandwidth
• IOPS
• Latency
• Cost or storage efficiency
RAID 0: Striping
RAID 0 is commonly used on HDDs and flash PCIe cards. Data is striped across multiple (N) units, which increase system bandwidth, by a factor of N.
RAID 0 also raises failure rates by a factor of N. Any unit that fails brings down the whole stripe. Never use RAID 0 if reliability is important.

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 14
Further, the impact of RAID 0 on read latency is significant. Any of the flash devices in the stripe can be blocked by an Erase, the whole Read is delayed resulting in access latencies can go from 100 microseconds to several milliseconds as a result.
RAID 1: Mirroring
RAID 1 solves reliability problems by mirroring data. Each Write is replicated to two drives. Each Read can be serviced by either drive, but must be done in order.
RAID-‐1 is typically used by SSD customers to cope with SSD or flash memory failures. Whole chips can fail without data loss. However, the downside to RAID-‐1 is that write IOPS are halved and the cost per GByte is doubled! (50% efficiency right our of the gate)
RAID 5: Rotating Parity
RAID 5 has become a popular approach to reducing the cost overhead of mirroring. Data and parity are combined on every disk so that parallel data read and write operations can take place. Though not as fast as RAID-‐0 and not providing as much protection as RAID-‐1, RAID-‐5 offers a decent level of speed and protection for HDDs.
The challenge with RAID 5 is that even the writing of a small block means that both Data and Parity have to be written. In addition, Parity must go through a Read-‐Modify-‐Write process which adds significant latency to Writes and reduces IOPS.
With flash, Read-‐Modify-‐Write is especially bad since the Read may be delayed or blocked by an ongoing Erase process. For these reasons, RAID 5 is not recommended for flash SSDs of any type.
And like RAID 0, a latency challenge is caused by reading wide stripes of data from many devices. If any one of the devices is blocked by an Erase taking place, the whole Read is delayed until the last device responds.
When an HDD fails, the RAID 5 group must be rebuilt using the remaining HDDs and parity. This process used to be workable, but as HDDs are now over 1 T in capacity, the rebuild process can take most of a day. If any other failures or disk errors occur during this process, data loss can occur.

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 15
RAID 6: Dual Rotating Parity
RAID 6 reduces the probability of data loss significantly by employing a dual parity scheme that allows any two HDDs to fail without data loss.
The overhead associated with RAID 6 is much higher as each small write requires 2 additional Read-‐Modify-‐Write operations which reduce IOPS and increase Write latency. This is not recommended for Flash.
The impact of striping on latency is the same for RAID 5 and RAID 6. This latency impact negates the inherent value of flash memory.
RAID 10: Nested Striping and Mirroring
RAID 10 or RAID 1+0 is a combination of mirroring and striping. Data is striped across pairs of mirrored disks. This provides both bandwidth and reliability.
On the surface, this is a good solution for PCIe cards. However, if grooming or Garbage Collection and/or metadata handling is done in the host CPU, that host must do a lot more work. With 4 PCIe cards, the system may only perform 30% faster than a single PCIe card.
For RAID 10, the latency impact of striping is similar to RAID 0.
JBOD
More recently, software solutions that enable RAID-‐like redundancy have become popular. This approach treats storage systems as “Just a Bunch Of Disks” (JBOD) and provides redundancy at a higher level. For example, Google’s Big Table software replicates data for both performance and reliability reasons.
This technique works relatively well because HDD storage is cheap and replicating data many times is affordable while increasing Read IOPS. However, flash is more expensive capacity and inherently supports higher Read IOPS. Given these characteristics, techniques that replicate less data are more affordable when it comes to flash technology.
Contact Violin

Violin Memory Flash Overview Technical Whitepaper
Violin Memory 16
Diamond Point International Suite 13, Ashford House, Beaufort Court, Sir Thomas Longley Road, Rochester, Kent, ME2 4FA, UK Tel: +44 (0)1634 300900 Fax: +44 (0)1634 722398 Email: [email protected] Web: storage.dpie.com

















