Abstract We present an improved uniform subdivisionbased discrete and continuous collision detection approachfor deformable objects consisting of triangle meshes withoutany assumption about triangle size. A previously proposedtechnique using control bits can effectively eliminate redun-dant object pairs appearing in multiple cells, but this schemerequires the grid cell size adapted to the largest object, andefficiency tends to be severely impaired when object sizevaries strongly. In this paper, we discuss an approach thatvirtually subdivides large triangles into a number of childtriangles to enable the use of a smaller, better suited cellsize, resulting in a considerable decrease in the number ofcollision tests in the broad phase, with a corresponding re-duced memory requirement. The virtual subdivision is usedonly for the purpose of collision detection and is recomputedeach frame, with the original mesh retained for collision re-sponse and physical simulation. Our method exploits thebenefits of GPU architecture to accelerate the computation-ally intensive task for improved performance. The resultsshow that the method provides speedups by comparing per-formance with existing methods.
Spatial subdivision has been widely used to accelerate col-lision detection (CD) by significantly reducing the number
T.H. Wong (�) · G. Leach · F. ZambettaSchool of Comp Sci & IT, RMIT University, GPO Box 2476,Melbourne, Victoria 3001, Australiae-mail: [email protected]
of collision tests. The main strategy is to partition the spaceinto many cubic cells, and then perform collision tests onlyfor primitive pairs belonging to the same cell, resulting inan average complexity of O(n logn) in a scene contain-ing n features such as triangles and their bounding volumes(BVs). Early spatial subdivision based CD approaches fo-cus on simulation of rigid objects, such as [14, 23], and [3].Later, a number of methods employing spatial subdivisionfor CD of deformable objects have been proposed. In gen-eral, these approaches use a uniform grid whose cell sizeis object-independent [20], a uniform grid with an object-dependent cell size [15], a two-level hierarchical grid [7],or a general multilevel hierarchical grid [6]. Recently, sev-eral papers have focused on utilizing the GPU’s parallelismto achieve high performance for CD by taking advantage ofthe features of spatial subdivision [12, 15], and [7].
The main drawback of methods employing a uniformgrid is that an inappropriate cell size can lead to a very highnumber of false positive CD tests. Features may overlap toomany cells if the cell size is small, or too many features canbelong to the same cell when the cell size is large. In fact,it is unrealistic to expect a mesh with evenly sized trianglesin many scenarios. One way to alleviate this limitation isthe hierarchical grid of multiple cell levels, but this kind oftechnique suffers from maintaining and updating the com-plicated hierarchy or additional computation for CD acrossdifferent levels. In addition, because we are interested in uti-lizing the parallel capability of the GPU, it is important thatthe simplicity and scalability of the uniform grid is moresuited to the nature of the GPU architecture, compared tothe hierarchical spatial subdivision.
Another issue is the removal of duplicate CD tests due toobject pairs assigned to multiple cells. There are a number ofexisting methods to address this issue, such as running itera-tion steps, checking objects against others appearing in adja-
Fig. 1 Snapshots from the reef knot benchmark: Two pieces of ribbonare tied into a reef knot
cent cells, and utilizing the location of the minimal vertex ofthe overlapped axis-aligned bounding box (AABB). With-out relatively expensive operations, Grand [8] presented amuch cheaper scheme to handle this problem in parallel onGPUs using control bits (CBs). In their method, a strategythat sets the cell size greater than the largest feature ensuresthat a feature can be assigned to up to eight cells in 3D space,so one integer per object is enough to specify the cells over-lapped by this object (one bit for one cell). In the subsequentbroad phase CD, all that is needed is to perform cheap bit op-erations [8]. However, because it only works for grids withan object-dependent cell size adapted to the largest object,the problem that cells can contain too many features stillexists if the size of largest feature is much greater than theaverage feature size.
In order to avoid the relative large cell size and still takethe advantage of CBs, we present a simple method for uni-form grid based CD algorithm to use a more optimal cellsize by subdividing large triangles into small child trianglesevery frame. The subdivision is virtual because virtual childtriangles are only used for the purpose of CD in the broadphase, and the newly generated vertices and edges are notused in the simulation. Therefore, reconstruction of the tri-angle mesh and the linear system for the simulation is notrequired. We do not retain the refined triangle mesh so thatthe input mesh is virtually subdivided on the fly each frame.In our GPU-based implementation, the virtual subdivisioncan be quickly completed. Most duplicate collision testsin the broad phase caused by triangle subdivision are effi-ciently avoided. Although some child triangles are generatedin our approach, we demonstrate that our method dramati-cally reduces the number of broad phase collision tests andthe GPU memory requirement due to the smaller cell size,and thus increases the overall performance. This method canwork with both discrete and continuous collision detection(DCD and CCD). We implemented our method entirely on
the GPU using the CUDA toolkit 4.1 on a machine with anNVIDIA GeForce GTX 470 graphics card.
2 Related work
In this section, we briefly introduce previous work directlyrelated to spatial subdivision based CD methods. For moredetailed information on CD, we refer interested readersto [21].
Because of its efficiency, spatial subdivision has provento be a very useful technique for CD. Early approacheshave been proposed for CD of rigid object simulation, suchas [14, 23], and [3].
Teschner et al. [20] presented a technique using a uni-form grid with spatial hashing for CD of deformable objectsconsisting of tetrahedral meshes. In this method, the cell sizeis object independently chosen. They have discussed how aset of parameters and properties affect the performance, andtheir results suggest that the best performance is achievedwhen the cell size is set to about the same as the averagesize of the AABBs. In [8], Grand proposed a GPU-basedCD algorithm employing a uniform grid with an object de-pendent cell size for spheres. The cell size is at least threetimes larger than the radius of the largest sphere, limitingany sphere to appear in less than or equal to eight cells. In or-der to efficiently avoid redundantly performing the same col-lision test between two spheres multiple times in the broadphase, they introduced a new scheme using CBs. Recently,based on the above technique, Pabst et al. [15] presented ahybrid CPU/GPU approach focused on deformable trianglemeshes. Our work addresses the primary shortcoming iden-tified in their work. In order to solve problems that manytriangles may appear in a cell and the uneven geometry dis-tribution Fan et al. [7] employed a two level hierarchical gridto increase culling efficiency. Each dense cell of the top levelis subdivided into eight subcells (bottom level). However,update and access of hierarchy and bottom-to-top assign-ment are required. In fact, the step of building the hierar-chical grid takes around one fifth of the total running time.Other spatial subdivision techniques for CD are discussed in[6] and [1].
3 Approach
In this section, we present our virtual subdivision based CDapproach. In the broad phase of our collision pipeline, BVtests are performed to cheaply select triangle pairs that needto undergo further intersection tests in the narrow phase.In the narrow phase, proximity tests used in [4] are per-formed to compute the collision and intersection informa-tion of vertex-triangle (VT) and edge-edge (EE) pairs. For
Virtual subdivision for GPU based collision detection of deformable objects using a uniform grid 831
Algorithm 1 Collision detectionupdate BVs of featuresupdate cell size of the adaptive uniform gridwhile triangle list is not empty do
for all triangles dodetermine if subdivision is requiredsubdivide it if necessary and put child triangles intothe listremove it from the list
end forend whilefor all triangles that are not subdivided do
assign to cells overlapped by itend forsort cell-triangle pairsremove redundant cell-triangle pairsfor all triangle pairs in cells do
CBs test to remove duplicate collision teststriangle-based BV cullingR-triangles cullingfeature-based BV cullingoutput candidate feature pairs (VT/EE)
end forfor all output candidate VT and EE pairs do
proximity testend for
DCD, tests are carried out to calculate intersections at eachdiscrete time step. In the case of CCD, the path of mov-ing primitives between two time steps is considered to findout the first contact instant by testing coplanarity, which re-duces to solving a cubic equation [16], with proximity tests.Therefore, the BV for CCD has to bound the trajectory ofthe moving primitive during the time interval. We use twotypes of BV. Spheres are used to determine triangle assign-ment and also to identify triangles which need to be subdi-vided. K discrete oriented polytopes (K-DOPs [10], specif-ically 18-DOPs) are used for BV tests in the broad phase.Algorithm 1 shows the overview of our method. Italic linesrelate to the core contribution of this paper.
3.1 Cell size
Instead of using a cell size adapted to the largest triangle, wedefine the cell size according to the average triangle bound-ing sphere size:
size = 3 × λra (1)
where ra is the average radius of triangles’ bounding spheresin the current frame. λ is a coefficient which must be greaterthan one in order to avoid subdividing too many triangles.We empirically set it to a value between 1.1 and 1.3. Fol-lowing [8], we scale λra by 3 to enable the use of CBs. Now,
Fig. 2 Some well known triangle subdivision rules
with the AABB of the entire model, three dimensions alongthe X, Y , and Z axes can be easily computed.
If λ is set too large or small, the improvement of ourmethod in the performance can degrade. However, we foundthis simple scheme works well in our benchmarks, as it isnot very performance sensitive if λ is in the range from 1.1to 1.3, and we use 1.2.
3.2 Triangle subdivision
Since this method is designed to allow the BV of each tri-angle to overlap no more than eight cells, more refined tri-angles are needed for large triangles in every time step.Some well-known subdivision rules have been proposedin level-of-detail and multiresolution areas, including theLoop scheme [13], triquad subdivision [22],
√3 subdivi-
sion [11] and√
3-refinement [2] (see Fig. 2). Since we areinterested in evenly refining triangles, the Loop scheme isthe best choice, as it subdivides a triangle into four equalchild triangles by taking midpoints of the original edges (seeFig. 2(a)).
In each frame, once the grid cell size and BVs are up-dated, we first decide if each triangle has to be subdividedby checking whether the radius of its BV is greater than one-third of the cell size, calculated as discussed above, and thensplit those marked as needed. For newly created child tri-angles, their BVs are computed, and their original root tri-angles are stored as well. This subdivision operation is re-peated until there are no triangles needing to be subdivided.In our benchmarks, the number of subdivision levels neededis up to four.
However, when it comes to CCD, the time step needs tobe taken into account. Because collisions are checked formoving objects between two time steps in CCD, the BV cov-ers the triangle’s trajectory from the beginning to the end of
832 T.H. Wong et al.
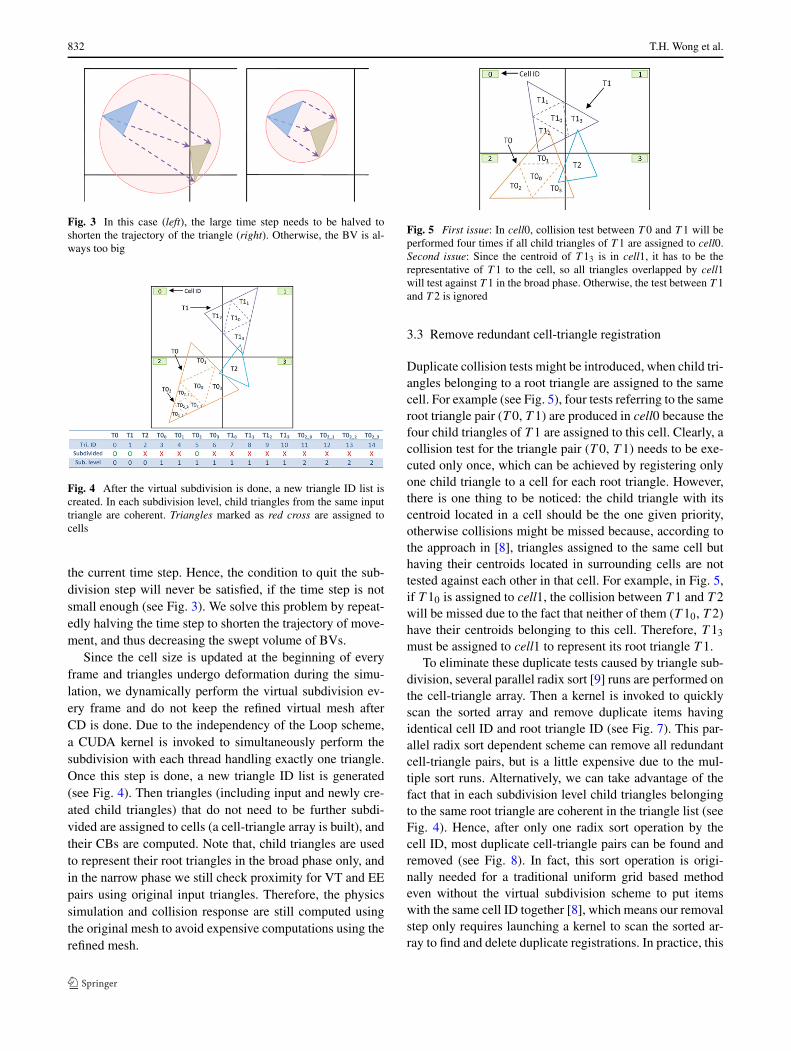
Fig. 3 In this case (left), the large time step needs to be halved toshorten the trajectory of the triangle (right). Otherwise, the BV is al-ways too big
Fig. 4 After the virtual subdivision is done, a new triangle ID list iscreated. In each subdivision level, child triangles from the same inputtriangle are coherent. Triangles marked as red cross are assigned tocells
the current time step. Hence, the condition to quit the sub-division step will never be satisfied, if the time step is notsmall enough (see Fig. 3). We solve this problem by repeat-edly halving the time step to shorten the trajectory of move-ment, and thus decreasing the swept volume of BVs.
Since the cell size is updated at the beginning of everyframe and triangles undergo deformation during the simu-lation, we dynamically perform the virtual subdivision ev-ery frame and do not keep the refined virtual mesh afterCD is done. Due to the independency of the Loop scheme,a CUDA kernel is invoked to simultaneously perform thesubdivision with each thread handling exactly one triangle.Once this step is done, a new triangle ID list is generated(see Fig. 4). Then triangles (including input and newly cre-ated child triangles) that do not need to be further subdi-vided are assigned to cells (a cell-triangle array is built), andtheir CBs are computed. Note that, child triangles are usedto represent their root triangles in the broad phase only, andin the narrow phase we still check proximity for VT and EEpairs using original input triangles. Therefore, the physicssimulation and collision response are still computed usingthe original mesh to avoid expensive computations using therefined mesh.
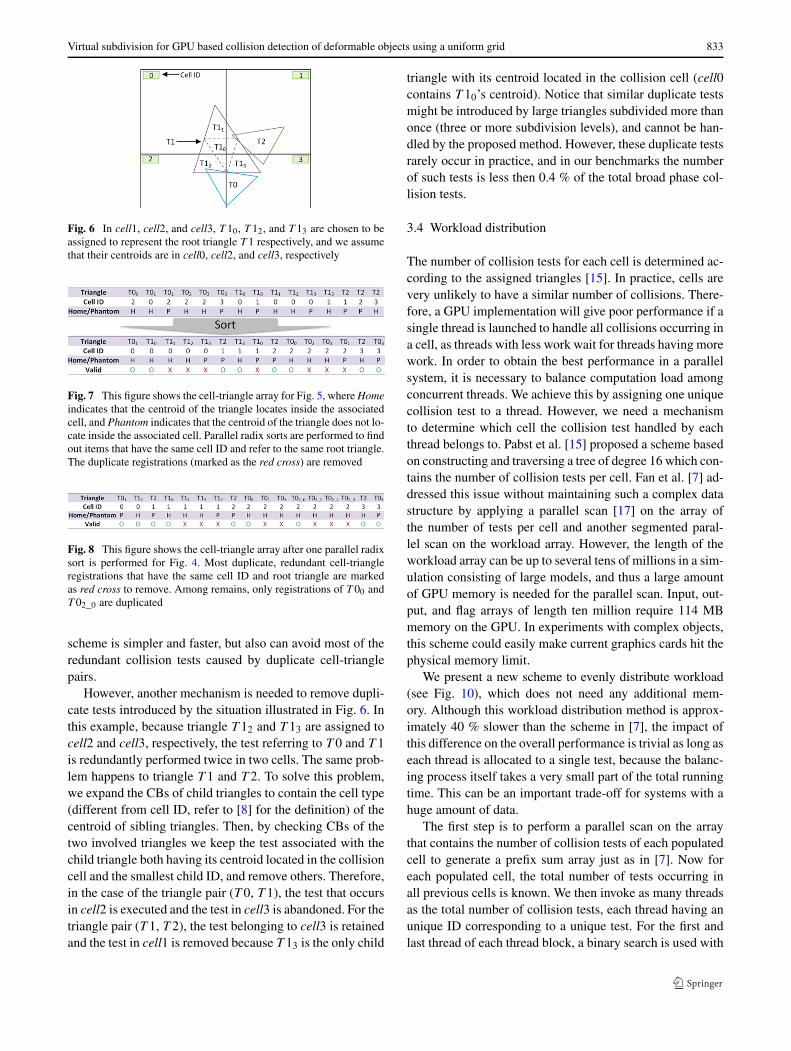
Fig. 5 First issue: In cell0, collision test between T 0 and T 1 will beperformed four times if all child triangles of T 1 are assigned to cell0.Second issue: Since the centroid of T 13 is in cell1, it has to be therepresentative of T 1 to the cell, so all triangles overlapped by cell1will test against T 1 in the broad phase. Otherwise, the test between T 1and T 2 is ignored
3.3 Remove redundant cell-triangle registration
Duplicate collision tests might be introduced, when child tri-angles belonging to a root triangle are assigned to the samecell. For example (see Fig. 5), four tests referring to the sameroot triangle pair (T 0, T 1) are produced in cell0 because thefour child triangles of T 1 are assigned to this cell. Clearly, acollision test for the triangle pair (T 0, T 1) needs to be exe-cuted only once, which can be achieved by registering onlyone child triangle to a cell for each root triangle. However,there is one thing to be noticed: the child triangle with itscentroid located in a cell should be the one given priority,otherwise collisions might be missed because, according tothe approach in [8], triangles assigned to the same cell buthaving their centroids located in surrounding cells are nottested against each other in that cell. For example, in Fig. 5,if T 10 is assigned to cell1, the collision between T 1 and T 2will be missed due to the fact that neither of them (T 10, T 2)have their centroids belonging to this cell. Therefore, T 13
must be assigned to cell1 to represent its root triangle T 1.To eliminate these duplicate tests caused by triangle sub-
division, several parallel radix sort [9] runs are performed onthe cell-triangle array. Then a kernel is invoked to quicklyscan the sorted array and remove duplicate items havingidentical cell ID and root triangle ID (see Fig. 7). This par-allel radix sort dependent scheme can remove all redundantcell-triangle pairs, but is a little expensive due to the mul-tiple sort runs. Alternatively, we can take advantage of thefact that in each subdivision level child triangles belongingto the same root triangle are coherent in the triangle list (seeFig. 4). Hence, after only one radix sort operation by thecell ID, most duplicate cell-triangle pairs can be found andremoved (see Fig. 8). In fact, this sort operation is origi-nally needed for a traditional uniform grid based methodeven without the virtual subdivision scheme to put itemswith the same cell ID together [8], which means our removalstep only requires launching a kernel to scan the sorted ar-ray to find and delete duplicate registrations. In practice, this
Virtual subdivision for GPU based collision detection of deformable objects using a uniform grid 833
Fig. 6 In cell1, cell2, and cell3, T 10, T 12, and T 13 are chosen to beassigned to represent the root triangle T 1 respectively, and we assumethat their centroids are in cell0, cell2, and cell3, respectively
Fig. 7 This figure shows the cell-triangle array for Fig. 5, where Homeindicates that the centroid of the triangle locates inside the associatedcell, and Phantom indicates that the centroid of the triangle does not lo-cate inside the associated cell. Parallel radix sorts are performed to findout items that have the same cell ID and refer to the same root triangle.The duplicate registrations (marked as the red cross) are removed
Fig. 8 This figure shows the cell-triangle array after one parallel radixsort is performed for Fig. 4. Most duplicate, redundant cell-triangleregistrations that have the same cell ID and root triangle are markedas red cross to remove. Among remains, only registrations of T 00 andT 02_0 are duplicated
scheme is simpler and faster, but also can avoid most of theredundant collision tests caused by duplicate cell-trianglepairs.
However, another mechanism is needed to remove dupli-cate tests introduced by the situation illustrated in Fig. 6. Inthis example, because triangle T 12 and T 13 are assigned tocell2 and cell3, respectively, the test referring to T 0 and T 1is redundantly performed twice in two cells. The same prob-lem happens to triangle T 1 and T 2. To solve this problem,we expand the CBs of child triangles to contain the cell type(different from cell ID, refer to [8] for the definition) of thecentroid of sibling triangles. Then, by checking CBs of thetwo involved triangles we keep the test associated with thechild triangle both having its centroid located in the collisioncell and the smallest child ID, and remove others. Therefore,in the case of the triangle pair (T 0, T 1), the test that occursin cell2 is executed and the test in cell3 is abandoned. For thetriangle pair (T 1, T 2), the test belonging to cell3 is retainedand the test in cell1 is removed because T 13 is the only child
triangle with its centroid located in the collision cell (cell0contains T 10’s centroid). Notice that similar duplicate testsmight be introduced by large triangles subdivided more thanonce (three or more subdivision levels), and cannot be han-dled by the proposed method. However, these duplicate testsrarely occur in practice, and in our benchmarks the numberof such tests is less then 0.4 % of the total broad phase col-lision tests.
3.4 Workload distribution
The number of collision tests for each cell is determined ac-cording to the assigned triangles [15]. In practice, cells arevery unlikely to have a similar number of collisions. There-fore, a GPU implementation will give poor performance if asingle thread is launched to handle all collisions occurring ina cell, as threads with less work wait for threads having morework. In order to obtain the best performance in a parallelsystem, it is necessary to balance computation load amongconcurrent threads. We achieve this by assigning one uniquecollision test to a thread. However, we need a mechanismto determine which cell the collision test handled by eachthread belongs to. Pabst et al. [15] proposed a scheme basedon constructing and traversing a tree of degree 16 which con-tains the number of collision tests per cell. Fan et al. [7] ad-dressed this issue without maintaining such a complex datastructure by applying a parallel scan [17] on the array ofthe number of tests per cell and another segmented paral-lel scan on the workload array. However, the length of theworkload array can be up to several tens of millions in a sim-ulation consisting of large models, and thus a large amountof GPU memory is needed for the parallel scan. Input, out-put, and flag arrays of length ten million require 114 MBmemory on the GPU. In experiments with complex objects,this scheme could easily make current graphics cards hit thephysical memory limit.
We present a new scheme to evenly distribute workload(see Fig. 10), which does not need any additional mem-ory. Although this workload distribution method is approx-imately 40 % slower than the scheme in [7], the impact ofthis difference on the overall performance is trivial as long aseach thread is allocated to a single test, because the balanc-ing process itself takes a very small part of the total runningtime. This can be an important trade-off for systems with ahuge amount of data.
The first step is to perform a parallel scan on the arraythat contains the number of collision tests of each populatedcell to generate a prefix sum array just as in [7]. Now foreach populated cell, the total number of tests occurring inall previous cells is known. We then invoke as many threadsas the total number of collision tests, each thread having anunique ID corresponding to a unique test. For the first andlast thread of each thread block, a binary search is used with
834 T.H. Wong et al.
Fig. 9 This figure shows the snapshots from benchmarks used for performance measuring. All benchmarks are tested on a computer with anNVIDIA GTX 470 card
Fig. 10 The diagram of the workload distribution scheme
its thread ID to find the position/cell ID (where the collisiontest occurs) in the prefix sum array in global memory. Be-cause of the continuity, cell IDs corresponding to remainingthreads in each block are between cells of the first and lastthread, which means values of this sub prefix sum array canbe copied into shared memory, and all remaining threads usebinary search to quickly find which cell their tests belong to.
3.5 Collision test
After the cell index is determined, the triangle pair involvedin the collision test can be easily found. Before performingthe broad phase CD, cell data needed for the test is loadedinto shared memory for fast access. In the broad phase test,for a triangle pair we first use their CBs to check if this testis redundant, so the CD for triangle pairs appearing in mul-tiple cells is guaranteed to be processed only once. The nextstep is the BV test, for which BVs of original triangles areused, because not all child triangles are assigned to cells.Otherwise, collisions would be missed if the BV of child tri-angles are used. Once this step is completed use of virtualsubdivision is finished.
In the subsequent steps, R-triangle tests proposed in [5]are first performed to remove duplicate VT and EE elemen-tary tests introduced by the fact that a vertex or an edge can
Fig. 11 Snapshots from the flamenco benchmark
be shared by more than one triangle in a mesh. Before out-putting VT and EE pairs for more expensive elementary testsin the narrow phase, the vertex and edge based BV cullingis carried out to further eliminate false positives. In the nar-row phase, for both DCD and CCD, proximity tests [4] tocompute exact intersection between VT and EE pairs arecarried separately by invoking two different kernels to avoidbranching and divergence. For CCD, coplanarity is checkedby solving a cubic equation before the proximity test.
4 Results and performance
We have implemented the method using the CUDA toolkit4.1 and conducted experiments on a computer with anNVIDIA GTX 470 card. All CD steps are performed on theGPU without data transfer between CPU and GPU duringthe simulation, and so the CPU and main memory do notaffect performance.
4.1 Benchmarks
In order to investigate the performance of our method, weused a set of benchmarks with different scenarios. Thesebenchmarks consist of triangles whose sizes vary consider-ably. Refer to Online Resource 1 for the animation.
Virtual subdivision for GPU based collision detection of deformable objects using a uniform grid 835
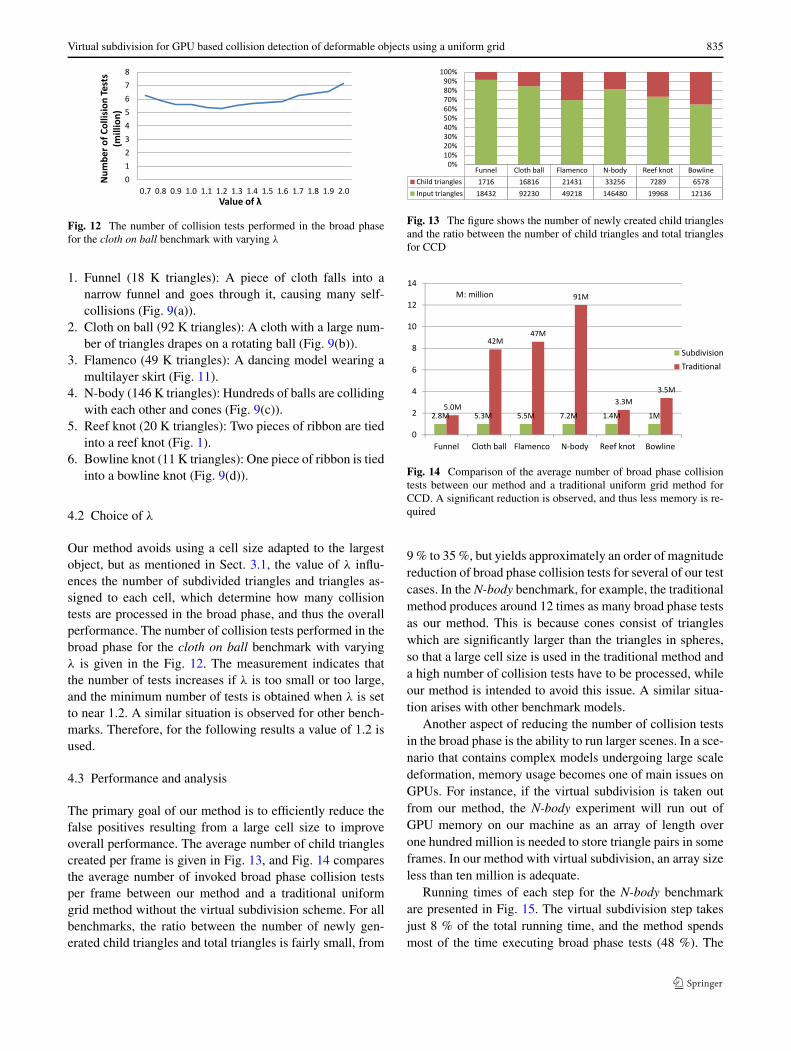
Fig. 12 The number of collision tests performed in the broad phasefor the cloth on ball benchmark with varying λ
1. Funnel (18 K triangles): A piece of cloth falls into anarrow funnel and goes through it, causing many self-collisions (Fig. 9(a)).
2. Cloth on ball (92 K triangles): A cloth with a large num-ber of triangles drapes on a rotating ball (Fig. 9(b)).
3. Flamenco (49 K triangles): A dancing model wearing amultilayer skirt (Fig. 11).
4. N-body (146 K triangles): Hundreds of balls are collidingwith each other and cones (Fig. 9(c)).
5. Reef knot (20 K triangles): Two pieces of ribbon are tiedinto a reef knot (Fig. 1).
6. Bowline knot (11 K triangles): One piece of ribbon is tiedinto a bowline knot (Fig. 9(d)).
4.2 Choice of λ
Our method avoids using a cell size adapted to the largestobject, but as mentioned in Sect. 3.1, the value of λ influ-ences the number of subdivided triangles and triangles as-signed to each cell, which determine how many collisiontests are processed in the broad phase, and thus the overallperformance. The number of collision tests performed in thebroad phase for the cloth on ball benchmark with varyingλ is given in the Fig. 12. The measurement indicates thatthe number of tests increases if λ is too small or too large,and the minimum number of tests is obtained when λ is setto near 1.2. A similar situation is observed for other bench-marks. Therefore, for the following results a value of 1.2 isused.
4.3 Performance and analysis
The primary goal of our method is to efficiently reduce thefalse positives resulting from a large cell size to improveoverall performance. The average number of child trianglescreated per frame is given in Fig. 13, and Fig. 14 comparesthe average number of invoked broad phase collision testsper frame between our method and a traditional uniformgrid method without the virtual subdivision scheme. For allbenchmarks, the ratio between the number of newly gen-erated child triangles and total triangles is fairly small, from
Fig. 13 The figure shows the number of newly created child trianglesand the ratio between the number of child triangles and total trianglesfor CCD
Fig. 14 Comparison of the average number of broad phase collisiontests between our method and a traditional uniform grid method forCCD. A significant reduction is observed, and thus less memory is re-quired
9 % to 35 %, but yields approximately an order of magnitudereduction of broad phase collision tests for several of our testcases. In the N-body benchmark, for example, the traditionalmethod produces around 12 times as many broad phase testsas our method. This is because cones consist of triangleswhich are significantly larger than the triangles in spheres,so that a large cell size is used in the traditional method anda high number of collision tests have to be processed, whileour method is intended to avoid this issue. A similar situa-tion arises with other benchmark models.
Another aspect of reducing the number of collision testsin the broad phase is the ability to run larger scenes. In a sce-nario that contains complex models undergoing large scaledeformation, memory usage becomes one of main issues onGPUs. For instance, if the virtual subdivision is taken outfrom our method, the N-body experiment will run out ofGPU memory on our machine as an array of length overone hundred million is needed to store triangle pairs in someframes. In our method with virtual subdivision, an array sizeless than ten million is adequate.
Running times of each step for the N-body benchmarkare presented in Fig. 15. The virtual subdivision step takesjust 8 % of the total running time, and the method spendsmost of the time executing broad phase tests (48 %). The
836 T.H. Wong et al.
Fig. 15 Time ratio of steps for N-body benchmark
Table 1 The average timings of our CD method for both DCD andCCD
No. of triangles(thousand)
DCD(ms)
CCD(ms)
Funnel 18 5.1 5.6
Cloth on ball 92 12.0 14.8
Flamenco 49 14.2 16.1
N-body 146 26.7 31.2
Reef knot 20 5.5 6.0
Bowline knot 12 4.3 4.0
Table 2 Specifications of three different graphics cards
GTX295 GTX470 GTX480
CUDA cores 2 ∗ 240 = 480 448 480
Graphics clock (MHz) 576 607 700
Processor clock (MHz) 1242 1215 1401
Memory clock (MHz) 999 1674 1848
performance of our approach (including all CD operations)for DCD and CCD on benchmarks is given in Table 1.
4.4 Comparison
We first compare the performance of our triangle subdivi-sion based approach against two recent grid based CD algo-rithms, followed by a comparison with previous boundingvolume hierarchy (BVH) based methods. A complicationarises from different hardware. The specifications of graph-ics cards and GPUs discussed are given in Table 2.
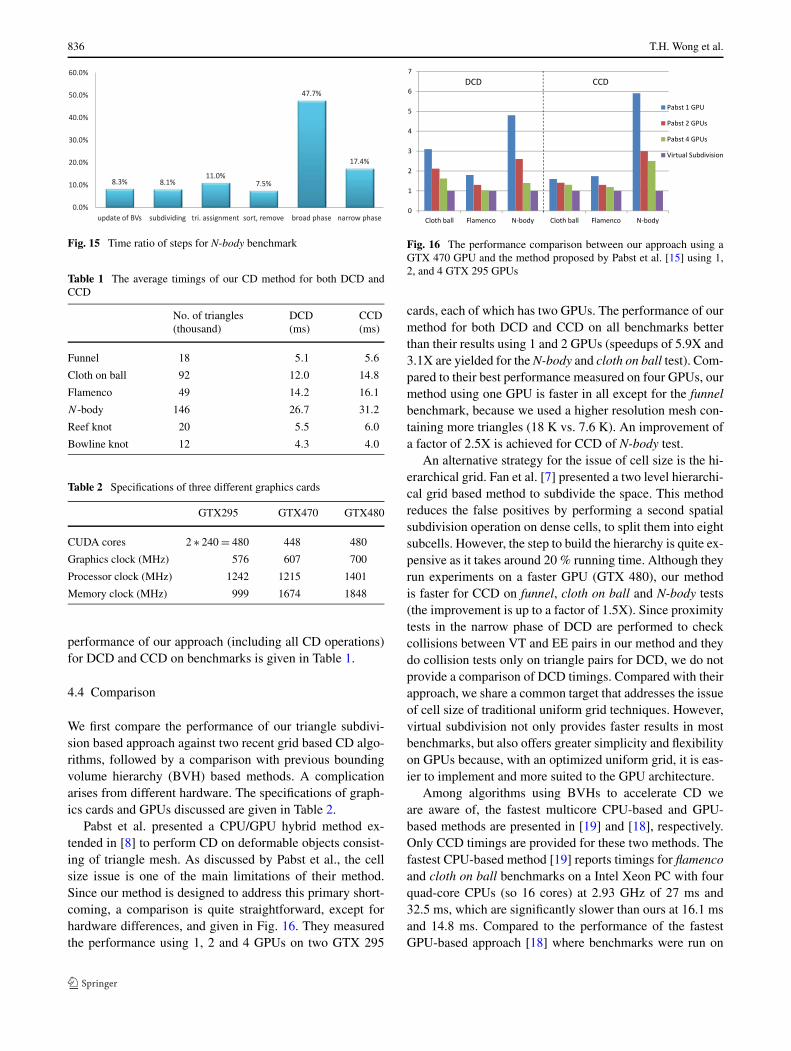
Pabst et al. presented a CPU/GPU hybrid method ex-tended in [8] to perform CD on deformable objects consist-ing of triangle mesh. As discussed by Pabst et al., the cellsize issue is one of the main limitations of their method.Since our method is designed to address this primary short-coming, a comparison is quite straightforward, except forhardware differences, and given in Fig. 16. They measuredthe performance using 1, 2 and 4 GPUs on two GTX 295
Fig. 16 The performance comparison between our approach using aGTX 470 GPU and the method proposed by Pabst et al. [15] using 1,2, and 4 GTX 295 GPUs
cards, each of which has two GPUs. The performance of ourmethod for both DCD and CCD on all benchmarks betterthan their results using 1 and 2 GPUs (speedups of 5.9X and3.1X are yielded for the N-body and cloth on ball test). Com-pared to their best performance measured on four GPUs, ourmethod using one GPU is faster in all except for the funnelbenchmark, because we used a higher resolution mesh con-taining more triangles (18 K vs. 7.6 K). An improvement ofa factor of 2.5X is achieved for CCD of N-body test.
An alternative strategy for the issue of cell size is the hi-erarchical grid. Fan et al. [7] presented a two level hierarchi-cal grid based method to subdivide the space. This methodreduces the false positives by performing a second spatialsubdivision operation on dense cells, to split them into eightsubcells. However, the step to build the hierarchy is quite ex-pensive as it takes around 20 % running time. Although theyrun experiments on a faster GPU (GTX 480), our methodis faster for CCD on funnel, cloth on ball and N-body tests(the improvement is up to a factor of 1.5X). Since proximitytests in the narrow phase of DCD are performed to checkcollisions between VT and EE pairs in our method and theydo collision tests only on triangle pairs for DCD, we do notprovide a comparison of DCD timings. Compared with theirapproach, we share a common target that addresses the issueof cell size of traditional uniform grid techniques. However,virtual subdivision not only provides faster results in mostbenchmarks, but also offers greater simplicity and flexibilityon GPUs because, with an optimized uniform grid, it is eas-ier to implement and more suited to the GPU architecture.
Among algorithms using BVHs to accelerate CD weare aware of, the fastest multicore CPU-based and GPU-based methods are presented in [19] and [18], respectively.Only CCD timings are provided for these two methods. Thefastest CPU-based method [19] reports timings for flamencoand cloth on ball benchmarks on a Intel Xeon PC with fourquad-core CPUs (so 16 cores) at 2.93 GHz of 27 ms and32.5 ms, which are significantly slower than ours at 16.1 msand 14.8 ms. Compared to the performance of the fastestGPU-based approach [18] where benchmarks were run on
Virtual subdivision for GPU based collision detection of deformable objects using a uniform grid 837
a GTX 480 GPU, with a slower GPU our method worksaround 2.0X and 2.5X times faster on flamenco and N-bodyrespectively (16.1s vs. 32.7 ms, and 31.2 ms vs. 79 ms).
5 Conclusion and future work
We presented an extended uniform grid based approach onGPU for DCD and CCD of deformable object simulation,which uses a virtual subdivision of the triangle mesh. Thismethod alleviates the common limitation of spatial sub-division techniques, which is the use of a cell size largeenough to ensure the largest triangle overlaps only a fewcells, by generating a more refined mesh to be able to use asmaller, better suited cell size by virtually subdividing largetriangles. In the most expensive stage, expanded CBs anda transition scan are used to quickly eliminate most dupli-cate collision tests in the broad phase. In terms of the na-ture of GPU features, our method provides improvements inthe programmability and extensibility, and also reduces thememory usage. In addition, the core idea in this paper canbe combined with other spatial subdivision methods with anobject-dependent cell size. Performance improvements areobserved by comparing results with those of prior methods.
There are several avenues for future work. Integrating ourmethod into a system with multiple GPUs would be inter-esting. We would also like to extend this method to performCD for techniques that refine and simplify the mesh duringsimulation, such as level-of-detail.
Acknowledgements We would like to thank Dan Yin for his help onbuilding the funnel model, Dan Yin, Pyarllel Knowles, and Min Tangfor the useful discussions. The cloth on ball and N-body benchmarksare courtesy of the UNC Dynamic Scene Benchmarks collection. Theflamenco benchmark is courtesy of Walt Disney Animation Studios andwas provided by Rasmus Tamstorf. The reef knot and bowline knotmodels were provided by David Harmon.
References
1. Alcantara, D.A., Sharf, A., Abbasinejad, F., Sengupta, S., Mitzen-macher, M., Owens, J.D., Amenta, N.: Real-time parallel hashingon the GPU. ACM Trans. Graph. 28, 154:1–154:9 (2009)
2. Alliez, P., Laurent, N., Sanson, H., Schmitt, F.: Efficient view-dependent refinement of 3D meshes using 3-subdivision. Vis.Comput. 19, 205–221 (2003)
3. Bandi, S.S., Thalmann, D.: An adaptive spatial subdivision of theobject space for fast collision detection of animating rigid bodies.Comput. Graph. Forum 14, 256–270 (1995)
4. Bridson, R., Fedkiw, R., Anderson, J.: Robust treatment of colli-sions, contact and friction for cloth animation. In: Proceedings ofthe 29th Annual Conference on Computer Graphics and Interac-tive Techniques, pp. 594–603. ACM, New York (2008)
5. Curtis, S., Tamstorf, R., Manocha, D.: Fast collision detection fordeformable models using representative-triangles. In: Proceedingsof the 2008 Symposium on Interactive 3D Graphics and Games,pp. 61–69. ACM, New York (2008)
6. Eitz, M., Lixu, G.: Hierarchical spatial hashing for real-time colli-sion detection. In: Proceedings of the IEEE International Confer-ence on Shape Modeling and Applications 2007, pp. 61–70. IEEEComput. Soc., Washington (2007)
7. Fan, W.S., Wang, B., Paul, J.C., Sun, J.G.: A hierarchical gridbased framework for fast collision detection. Comput. Graph. Fo-rum 30, 1451–1459 (2011)
8. Grand, S.L.: Broad-phase collision detection with CUDA. In:GPU Gems, vol. 3, pp. 697–721. Addison Wesley, Reading (2007)
9. Harris, M., Sengupta, S., Owens, J.D.: Parallel prefix sum (scan)with CUDA. In: Nguyen, H. (ed.) GPU Gems, vol. 3, pp. 851–876.Addison-Wesley, Reading (2007)
3-subdivision. In: Proceedings of the 27th AnnualConference on Computer Graphics and Interactive Techniques, pp.103–112. ACM press, New York (2000)
12. Liu, F.C., Harada, T., Lee, Y.E., Kim, Y.J.: Real-time collisionculling of a million bodies on graphics processing units. ACMTrans. Graph. 29, 154:1–154:8 (2010)
13. Loop, C.: Smooth Subdivision Surfaces Based on Triangles. TheUniversity of Utah, Utah (1987)
14. Mirtich, B.: Efficient algorithms for two-phase collision detection.In: Practical Motion Planning in Robotics Current Approaches andFuture Directions, pp. 203–223 (1997)
15. Pabst, S., Koch, A., Strasser, W.: Fast and scalable CPU/GPU col-lision detection for rigid and deformable surfaces. Comput. Graph.Forum 29, 1605–1612 (2010)
16. Provot, X.: Collision and self-collision handling in cloth modeldedicated to design garments. Proc. - Graph. Interface 97, 177–189 (1997)
18. Tang, M., Manocha, D., Lin, J., Tong, R.F.: Collision-streams: fastGPU-based collision detection for deformable models. In: Sym-posium on Interactive 3D Graphics and Games, pp. 63–70. ACM,New York (2011)
19. Tang, M., Manocha, D., Lin, J., Tong, R.F.: Multi-core collisiondetection between deformable models. In: 2009 SIAM/ACM JointConference on Geometric and Physical Modeling (SPM ’09), pp.355–360. ACM, New York (2009)
20. Teschner, M., Heidelberger, B., Mueller, M., Pomeranets, D.,Gross, M.: Optimized spatial hashing for collision detection ofdeformable objects. In: Vision Modeling Visualization, pp. 47–54(2003)
23. Zhang, D.L., Yuen Matthew, M.F.: Collision detection for clothedhuman animation. In: Proceedings of the 8th Pacific Conferenceon Computer Graphics and Applications, pp. 328–337 (2000)
838 T.H. Wong et al.
Tsz Ho Wong is a Ph.D. studentin Computer Science at RMIT Uni-versity. He received the master’s de-gree in RMIT University, Australia,in 2009. His major research interestsinclude physics simulation, collisionhandling, and GPU computing.
Geoff Leach is a lecturer in theSchool of Computer Science and In-formation Technology at RMIT Uni-versity. His major research interestsinclude computer graphics and dis-tribution system.
Fabio Zambetta is a senior lec-turer in the School of Computer Sci-ence and Information Technology atRMIT University. In 2004, Dr Zam-betta earned his Ph.D. degree in Uni-versitá degli Studi di Bari. His majorresearch interests include computergraphics, AI in video games, and ap-plied mathematics.