42
Web Mining and Visualization for E-Commerce Presented By Vandana Janeja
| Date post: | 20-Dec-2015 |
| Category: |
Documents |
| View: | 214 times |
| Download: | 1 times |

Web Mining and Visualizationfor E-Commerce
Presented By
Vandana Janeja

Presentation Outline
Website Usage Data JDK1.3, JavaScript, Java Servlets, Java based
web servers, Database MS Access
Data Mining Algorithms- K-Means, Apriori, Text Mining
Visualization for Website management Java3D, JDK1.3

Outline
Gather Data
Analyze Data
Visualize Data
•Web Crawler•Servlets- For Server side Data•JavaScript and Java Programs - for Client side data
•Data Mining•Text Mining•Clustering
•Decision Support System-Reporting System
•Java3D Visualization Algorithm• Simulation Programs
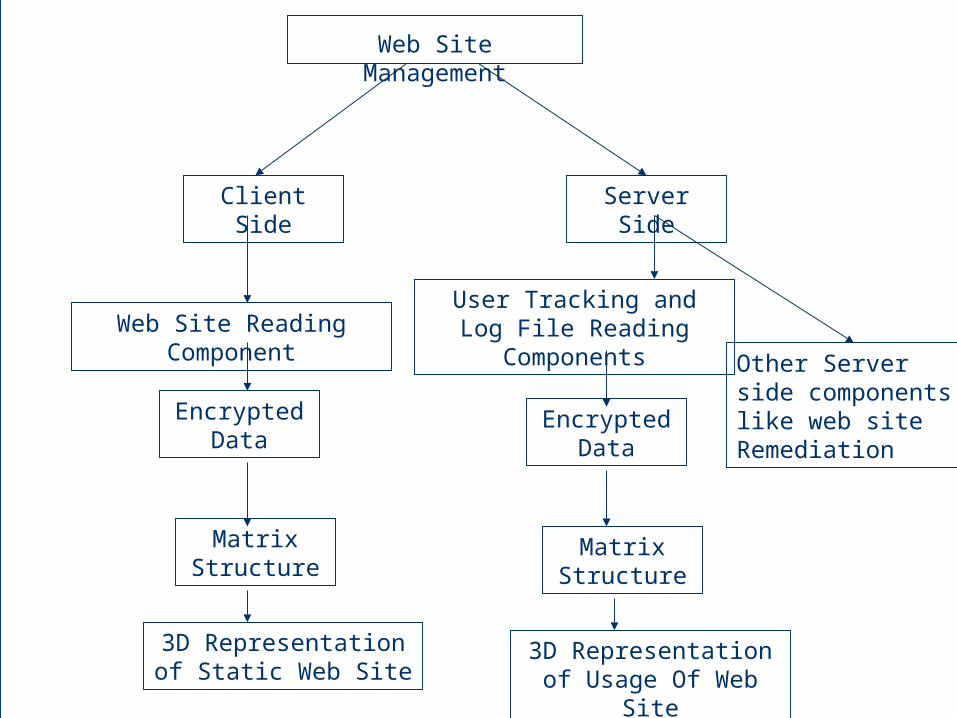
Web Site Management
Client Side Server Side
Web Site Reading Component
Matrix Structure
3D Representation of Static Web Site
Encrypted Data
User Tracking and Log File Reading Components
Matrix Structure
3D Representation of Usage Of Web Site
Encrypted Data
Other Server side components like web siteRemediation

Model
Gather Data
Analyze Data
Visualize Data
•Web Crawler•Servlets- For Server side Data•JavaScript and Java Programs - for Client side data•Collaboration
•Data Mining•Text Mining•Clustering
•Decision Support System-Reporting System
•Java3D Visualization Algorithm• Simulation Programs

Data Gathering

Application Server
Users
Browser
User Log Files
+Info from Programs
Server Side Programs
Data Base Data storage
Client Side Programs
Data mining

WEB SITE Static Site Map•http://www.library.njit.edu/etd/njit-mt2001-010/thesis.html
Usage Map: http://www.visualinsights.com

Reports
Host PingedHost names >1 hit
Host names
Intermediary Hosts Along connection path
Results of host pinging(done 4x’s per day)
Host names >1 hit
Host Traced
UsageDB Database
Table:UsageDataTable
Table:RouterInfo
Table:PrefRouterInfo
Table:Cookies
Table:UserAgent
Tables:Url; Scripts; Meta;
Applets; ...
Input Data:Servlet data
Input Data:Javascript data
Usage Database
Input Data:Client side
website parsing

Gather Data
Analyze Data
Visualize Data
•Web Crawler•Servlets- For Server side Data•JavaScript and Java Programs - for Client side data•Collaboration
•Data Mining•Text Mining•Clustering
•Decision Support System-Reporting System
•Java3D Visualization Algorithm• Simulation Programs
Outline

Visualization

The objective of the project was to develop a 3-Dimensional (3-D) visualization tool from an adjacency matrix representing connectivity between elements and usage of connectivity paths between these elements.
The visualization of connectivity could be for elements like routers and websites.

Web Crawler Web Site Link Reader******************
Matrix Structure
Index.html
Url1
Url2
Url3
Url1.html
Url4
Url5
Url6
URL2.html
Url7
Url8
Url9
Url3.html
Url10
Url11
Url12

1
2
3
5
96
78
4Adjacency Matrix:
1 : [2,3,4]2 : [5]3 : [6]4 : [7,8,1]5 : [1]6 : [9]7 : []8 : []9 : []
1 2 3 4 5 6 7 8 9
1 1 1 1 1 0 0 0 0 0
2 0 1 0 0 1 0 0 0 0
3 0 0 1 0 0 1 0 0 0
4 1 0 0 1 0 0 1 1 0
5 1 0 0 0 1 0 0 0 0
6 0 0 0 0 0 1 0 0 1
7 0 0 0 0 0 0 1 0 0
8 0 0 0 0 0 0 0 1 0
9 0 0 0 0 0 0 0 0 1
Web Page
Connectivity/ Hyperlink

Example 2:
Adjacency Matrix:1 : [2,6]2 : [3,7]3 : [4,8]4 : [5,9]5 : [1,10]6 : [8]7 : [9]8 : [10]9 : [6]10: [7]
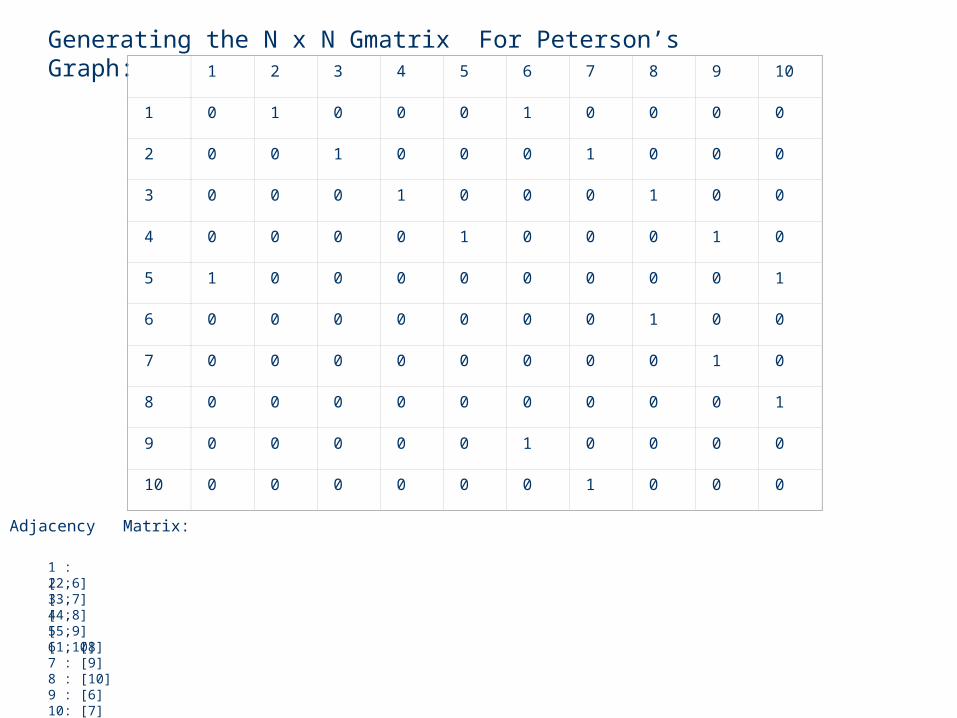
Generating the N x N Gmatrix For Peterson’s Graph: 1 2 3 4 5 6 7 8 9 10
1 0 1 0 0 0 1 0 0 0 0
2 0 0 1 0 0 0 1 0 0 0
3 0 0 0 1 0 0 0 1 0 0
4 0 0 0 0 1 0 0 0 1 0
5 1 0 0 0 0 0 0 0 0 1
6 0 0 0 0 0 0 0 1 0 0
7 0 0 0 0 0 0 0 0 1 0
8 0 0 0 0 0 0 0 0 0 1
9 0 0 0 0 0 1 0 0 0 0
10 0 0 0 0 0 0 1 0 0 0
Adjacency Matrix:
1 : [2,6]2 : [3,7]3 : [4,8]4 : [5,9]5 : [1,10]6 : [8]7 : [9]8 : [10]9 : [6]10: [7]

3D Representation as a cylinder
1 2 3 4 5 6 7 8 9
1 1 1 1 1 0 0 0 0 0
2 0 1 0 0 1 0 0 0 0
3 0 0 1 0 0 1 0 0 0
4 1 0 0 1 0 0 1 1 0
5 1 0 0 0 1 0 0 0 0
6 0 0 0 0 0 1 0 0 1
7 0 0 0 0 0 0 1 0 0
8 0 0 0 0 0 0 0 1 0
9 0 0 0 0 0 0 0 0 1

Possible Applications
Ad Placement Network Diagnostic Collaboration Detecting Anomalies

Measuring viewer usage is done in an indirect fashion. The advantage of Internet advertising is increased feedback to advertisers though the use of greater levels of interactivity, targeting and precise measurement of user behavior.Various pricing models used for currently in use are:
cost per thousand (and a related mechanism, flat fee /sponsorship); click through(CPM, CPC, CPL); hybrid models; outcomes.
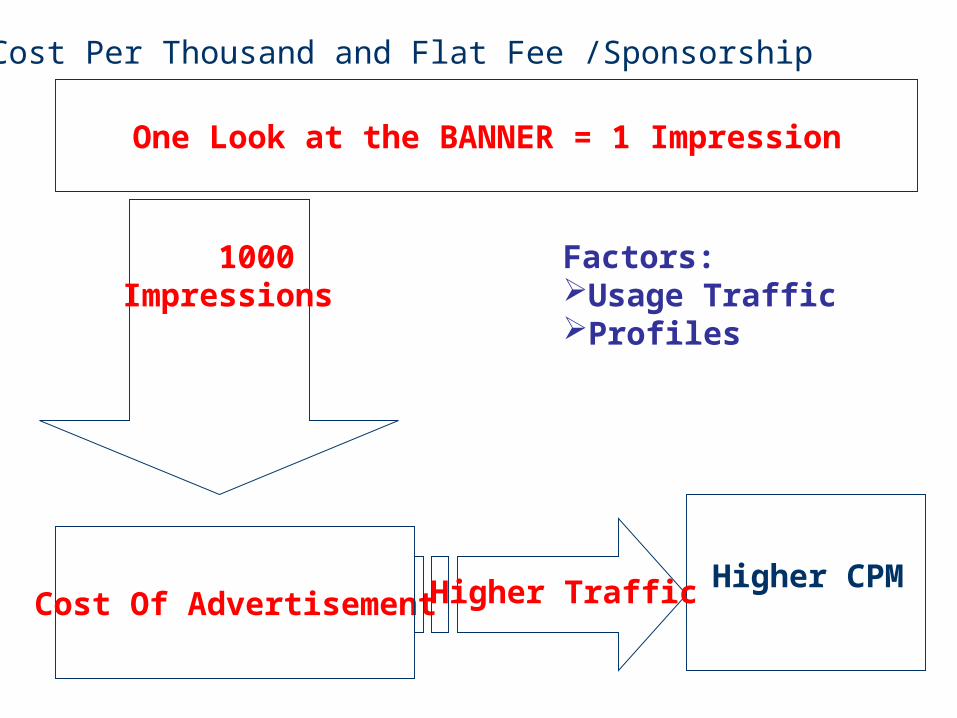
Cost Per Thousand and Flat Fee /Sponsorship
One Look at the BANNER = 1 Impression
Cost Of Advertisement
1000 Impressions
Higher Traffic Higher CPM
Factors:Usage Traffic Profiles

Network Diagnostic

UsageDatabase
Most preferred User report
RouterList
Connectiv ity Program
Connectiv ityDatabase
«process»Generates
Time /Date
HistoryCheck
ResponseIndex
<<input>>
<<input>>
UML Model of Network Diagnostic

Collaboration

Website Collaboration based on Affiliate Model
Web Site AWeb Site B
Exit point
Entry Point & source
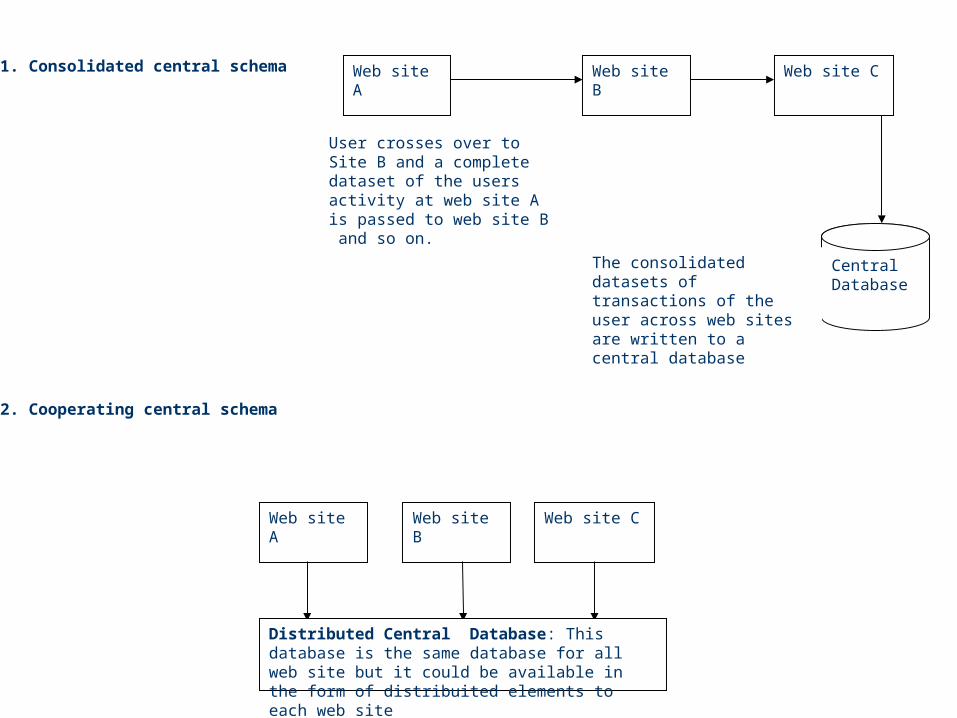
Web site A Web site B Web site C
Central Database
User crosses over to Site B and a complete dataset of the users activity at web site A is passed to web site B and so on.
The consolidated datasets of transactions of the user across web sites are written to a central database
1. Consolidated central schema
Web site A Web site B Web site C
Distributed Central Database: This database is the same database for all web site but it could be available in the form of distribuited elements to each web site
2. Cooperating central schema

Web SiteA
URL 1A
Web SiteB
URL 1BSessionID as URL rewriting
To be able to pass Session id for single window scenario(where the link appears on the URL).
Web SiteA
URL 1A
Web SiteB
URL 1B
SessionID in a bean along with other data
1> object pool for multiple windows - the object containing the entire data about the session passed as a bean to the collaborating site,
Web SiteA
URL 1A
Web SiteB
URL 1B
Cookie Table in Shared Pool
1> cookies for multiple windows with a cookie table in the shared pool,Here both collaborating sites can access the cookies for both web sites.

Web SiteA
URL 1A
Web SiteB
URL 1B
DatabaseA
LogFile SiteA from Servlet programs
LogFile SiteB from Servlet programs
DatabaseB
Query with Join = Temporary Table
Collaboration Reports
1> Table for an entire log file(generated by Servlet programs) along with Session Id for each user which can be used either as a shared pool or as an element in a join query on the databases : for eg :select * from SiteATable,SiteBTable where SiteATable.SessionID= SiteBTable.SessionID

Gather Data
Analyze Data
Visualize Data
•Data Mining•Text Mining•Clustering
•Decision Support System-Reporting System
•Java3D Visualization Algorithm• Simulation Programs
•Web Crawler•Servlets- For Server side Data•JavaScript and Java Programs - for Client side data•Collaboration
Outline

Text Mining and Association Rule Mining on the web

Some Types of Text Data Mining
Keyword-based association analysis Similarity detection
Cluster documents by a common author Cluster documents containing information from a
common source
Link analysis: unusual correlation between entities
Anomaly detection: find information that violates usual patterns
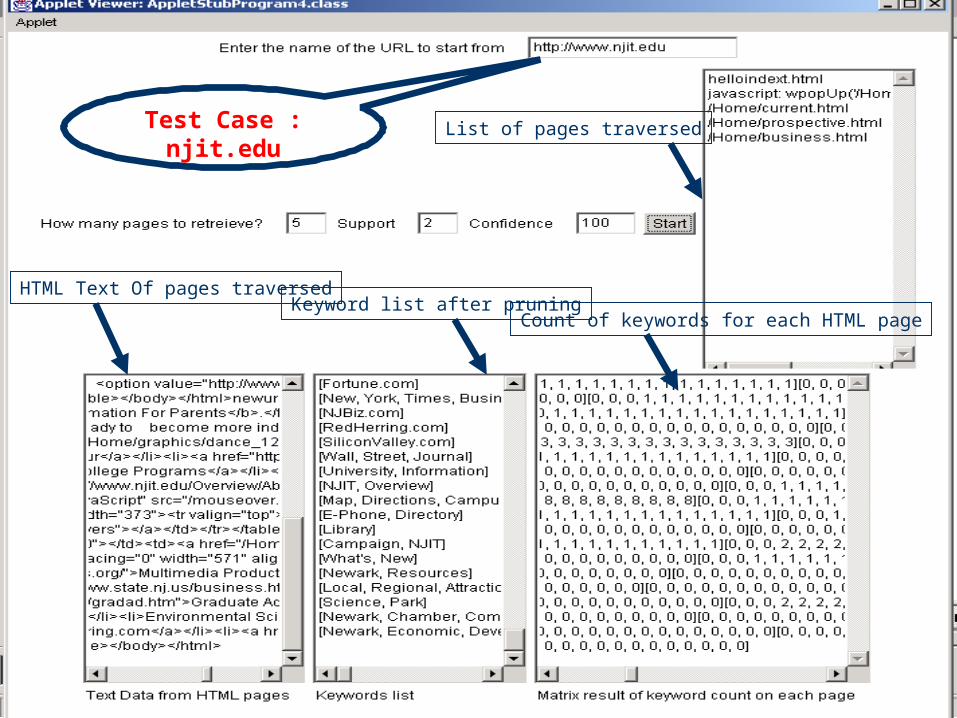
Test Case : njit.edu List of pages traversed
HTML Text Of pages traversedKeyword list after pruning
Count of keywords for each HTML page

Sample Apriori Rules
3 <- 2 (70.0%, 85.7%)2 <- 3 (70.0%, 85.7%)2 <- 1 (60.0%, 83.3%)4 <- 5 (30.0%, 100.0%)3 <- 2 1 (50.0%, 80.0%)2 <- 3 1 (40.0%, 100.0%)4 <- 3 5 (10.0%, 100.0%)4 <- 1 5 (10.0%, 100.0%)2 <- 3 4 1 (20.0%, 100.0%)

Mining Association Rules—An Example
For rule A C:support = support({A C}) = 50%
confidence = support({A C})/support({A}) = 66.6%
The Apriori principle:Any subset of a frequent itemset must be frequent
Transaction ID Items Bought2000 A,B,C1000 A,C4000 A,D5000 B,E,F
Frequent Itemset Support{A} 75%{B} 50%{C} 50%{A,C} 50%
Min. support 50%Min. confidence 50%
Reference: http://www.cs.sfu.ca/~han/DM_Book.html

Data MiningClustering Using K-Means

K-Means the clusters are formed based on the basis of distance from a centroid
•K-means cluster analysis. K-means cluster analysis uses Euclidian distance. •Initial cluster centers are chosen in a first pass of the data, then each additional iteration groups observations based on nearest Euclidian distance to the mean of the cluster. •Thus cluster centers change at each pass. •The process continues until cluster means do not shift more than a given cut-off value or the iteration limit is reached.

The K-Means Clustering Method
1.Test Case: 0 - 2,3 1 - 4,5
•Test Case: 0 – 2,6 1 – 4,5

But what if the number of clusters changes•Test Case : 0 – 3, 5 (Case in which K changes ) 1 – 6, 2

Text Mining and Visualization:
• The web site is inherently made up with a directory structure, which is essentially a tree structure. This is a kind of inherent similarity based grouping; All the related pages are kept in a directory.
• The web pages can also be grouped or clustered together based on other similarity features which can be generated by text mining.
• All the web pages can be similar to each other by the appearance of certain keywords in them. These can be extracted and pruned using certain text mining algorithms. Once this is done the web pages can be logically grouped in such a way that it will be a “Bottom Up Approach” a set of pages can be input into the text mining engine. This engine can come up with the most similar pages based on appearance of keywords (which are also gathered using an algorithm).
• This engine works on each directory and subdirectory structure. Subsequently “X” such web pages can be grouped together. This will form a hierarchy of sets of “X” pages arranged in a hierarchy.

Individual Pages clustered based on a similarity measure
Cluster of “X” such pages at the same level based on the similarity measure
Highest level with a cluster of clusters
Cylinder Visualization of Very Large Sites

Putting It all together
Data Gathered from Different sources
Mining
Visualization
Mining Result

References: Sudipto Guha, R.Rastogi, K.Shim :A clustering algorithm for categorical attributes. Technical report, Bell
laboratories, Murray Hill 1997 ROCK : A Robust Clustering Algorithm for Categorical Attributes: Sudipto Guha, Rajeev Rastogi, Kyuseok
Shim. Published in the Proceedings of the IEEE Conference on Data Engineering, 1999Discussion on K-Means
R. O. Duda and P. E. Hart. Pattern Classification and Scene Analysis. Wiley, New York, 1973. [16] O. Egecioglu and H. Ferhatosmanoglu. Circular data-space partitioning for similarity queries and
parallel disk allocation. In Proc. of IASTED International Conference on Parallel and Distributed Computing and Systems, pages 194-200, November 1999.
• A.K. Jain and R. C. Dubes. Algorithms for Clustering Data. Prentice Hall, 1988. J. MacQueen. Some methods for classification and analysis of multivariate observations. In Proceedings of
the Fifth Berkeley Symposium on Math. Stat. and Prob, volume 1, pages 281-196, 1967. http://www.cs.sfu.ca/~han/DM_Book.html J. Pei, J. Han, and R. Mao. CLOSET: An Efficient Algorithm for Mining Frequent Closed Itemsets.
DMKD'00, Dallas, TX, 11-20, May 2000.
R. Srikant, Q. Vu, and R. Agrawal. Mining association rules with item constraints. KDD'97, 67-73, Newport Beach, California.
H. Toivonen. Sampling large databases for association rules. VLDB'96, 134-145, Bombay, India, Sept. 1996.

Acknowledgements and Disclaimers
Advisors: Dr.Manikopoulos
Associate Professor,Electrical and Computer Engineering Department, New Jersey Institute of Technology
Dr.Jay Jorgenson Professor, Mathematics Department,City University Of New York
Software Development team at Network Security Solutions: Some of the material is a copyright of NSS,Inc and SiteGain,Inc.
Thesis in visualization was done during the Master’s at NJIT

















