WFCAM Science Archive Critical Design Review, April 2003 The SuperCOSMOS Science Archive (SSA) CAM Science Archive prototype isting ad hoc flat file archive (inflexible, restricted access e-implemented in an RDBMS talogue data only (no image pixel data) 26 Tbytes of catalogue data plement a working service for users & developers to ercise prior to arrival of Tbytes of WFCAM data
Transcript
WFCAM Science Archive
Critical Design Review, April 2003
The SuperCOSMOS Science Archive (SSA)
• WFCAM Science Archive prototype
• Existing ad hoc flat file archive (inflexible, restricted access) re-implemented in an RDBMS
• Catalogue data only (no image pixel data)
• 1.26 Tbytes of catalogue data
• Implement a working service for users & developers to exercise prior to arrival of Tbytes of WFCAM data
WFCAM Science Archive
Critical Design Review, April 2003
SSA has several similarities to WSA:
• spatial indexing is required over celestial sphere
• many source attributes in common, eg. position, brightness, colour, shape, …
• multi-colour, multi-epoch merged source information results from multiple measurements of the same source
WFCAM Science Archive
Critical Design Review, April 2003
Entity – Relationship Models (ERMs):
• generalised, DBMS – independent
• simple, pictorial summary of relational design
• ERMs map directly to table design
WFCAM Science Archive
Critical Design Review, April 2003
SSA relational model:
• very simple relational model
• total of 5 entities
• Catalogues have ~256 byte records with mainly 4-byte attributes, ie. 50 to 60 per record
• so 2 tables dominate the DB - SurveyCat: 0.82 Tbyte - MergedCat: 0.44 Tbyte
WFCAM Science Archive
Critical Design Review, April 2003
SSA has been implemented and 1% of data ingested:
• as prototype for V1.0 WSA
• Windows/SQL Server => “SkyServer”
• real-world queries used to exercise SSA
• 100% ingested and online by end Q2 2003
• test-bed for user access tools and archive scientist curation
WFCAM Science Archive
Critical Design Review, April 2003
Development method: “20 queries approach”
• a set of real-world astronomical queries, expressed in SQL
• includes joint queries between the SSA and SDSS
• currently have been exercised in the EDR region: - SSA: 13 million records; ~ 3 Gbyte - SDSS: 14 ; ~22
WFCAM Science Archive
Critical Design Review, April 2003
WSA has significant differences, however:
• catalogue and pixel data;
• calibration and other extensive metadata;
• science – driven, nested survey programmes (as opposed to SSA “atlas” maps of whole sky) result in complex data structure;
• curation & update within DBMS (whereas SSA is a finished data product ingested once into the DBMS).
WFCAM Science Archive
Critical Design Review, April 2003
WSA key requirements:
• flexibility: - ingested data are rich in structure - ingest occurs daily, curation daily/weekly/monthly … - many varied usage modes - protect proprietorial rights for many data
• scalability: - ~2 Tbyte of new catalogue & ancillary data per year • rapid response: - need to maintain rapid response despite increasing data volumes
WFCAM Science Archive
Critical Design Review, April 2003
Schematic picture of the WSA:
• Pixels: - one flat – file image store; access layer restricts public access - filenames and all metadata are tracked in DBMS tables with unrestricted access
• Catalogues: - WFAU incremental (no public access) - Public, released DBs - external survey datasets also held
WFCAM Science Archive
Critical Design Review, April 2003
WFCAM pixel data
• pixel data consist of multiframes and combiframes in WSA parlance;
• stored as flat files (not BLOBs in the DBMS)
• metadata are stored in the DBMS
• library calibration frames are held
• default image products are held
WFCAM Science Archive
Critical Design Review, April 2003
WFCAM multiframe - any pipeline product that:
• retains instrumental “paw print” as distinct images (WSA calls these “detector frames”)
• is not made up from other ingested frames (eg. microstep interleave is a multiframe)
WSA includes difference images as multiframes
WFCAM Science Archive
Critical Design Review, April 2003
WFCAM combiframe – any pipeline or archive product that:
• is the result of combination process on stored multiframes - eg. pipeline dither/stack/mosaic product - eg. archive default stack/mosaic product
(NB: combiframe may still reflect the “paw print” so can havemultiframe characteristics)
WFCAM Science Archive
Critical Design Review, April 2003
Multiframe ERM:
• Programme & Field => vital
• library calibration multiframes stored & related
• primary/extension HDU keys logically stored & related
• this will work for VISTA
WFCAM Science Archive
Critical Design Review, April 2003
Combiframe ERM:• every combiframe has provenance linking to multiframes
• individual calibration frames not reqd. but individual confidence frames are
• combiframe may consist of multiframe-like detector combiframes
WFCAM Science Archive
Critical Design Review, April 2003
Astrometric and photometric calibration data:
• require to store calibration information (SRAD)
• recalibration is required – esp. photometric (SRAD)
• old calibration coefficients must be stored (SRAD)
• time-dependence (versioning) complicates the relational model
Calibration data are related to images; source detections arerelated to images and hence their relevant calibration data
Multiframe calibration data:
• “set-ups” define nightly detector & filter combinations: - extinctions have nightly values - zps have detector & nightly values
• coefficients split into current & previous entities• Versioning & timing recorded• highly non-linear systematics are allowed for via 2D maps
WFCAM Science Archive
Critical Design Review, April 2003
Combiframe calibration data: • no “set-ups”: each image separately calibrated;
• detector combiframes are catered for
• “luptidude” parameters stored for each image separately
WFCAM Science Archive
Critical Design Review, April 2003
Catalogue data: general model
• related back through progenitor image to calibration data
• detection list for each programme (or set of sub-surveys)
• merged source entity is maintained
• merge events recorded
• list re-measurements derived
WFCAM Science Archive
Critical Design Review, April 2003
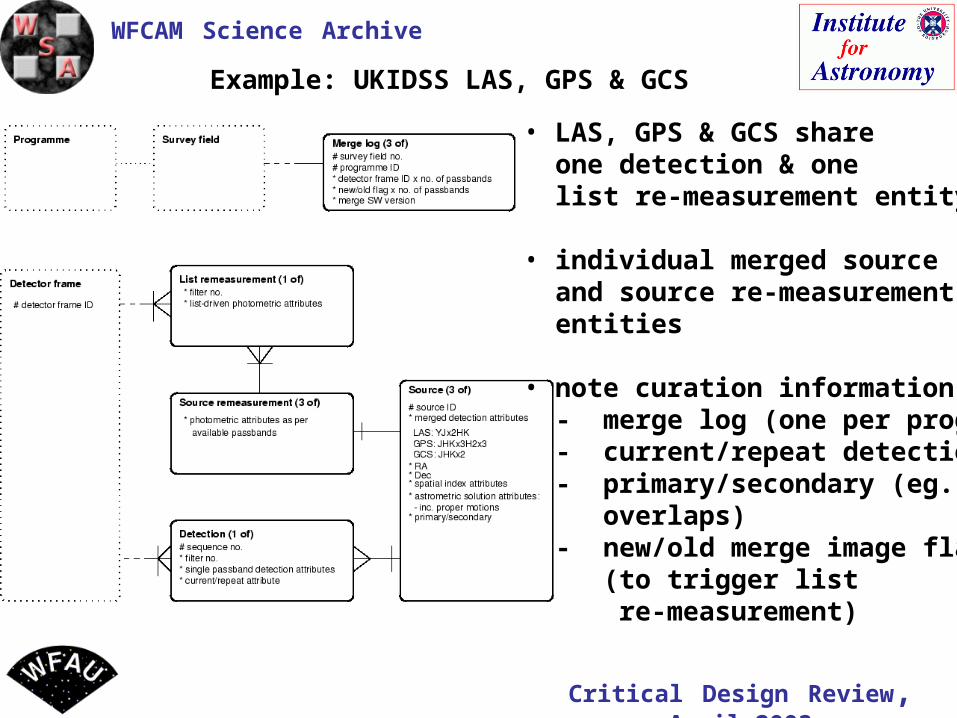
Example: UKIDSS LAS, GPS & GCS
• LAS, GPS & GCS share one detection & one list re-measurement entity
• individual merged source and source re-measurement entities
• note curation information: - merge log (one per prog.) - current/repeat detections - primary/secondary (eg. overlaps) - new/old merge image flag (to trigger list re-measurement)
Critical Design Review, April 2003
Non-WFCAM data: general model
• each non-WFCAM survey has a stored catalogue
• cross-neighbour table: - records nearby sources between any two surveys - yields associated (“nearest”) source
• non-WFCAM list measurements where image data are available (NB: V2.0 requirement)
Critical Design Review, April 2003
Example: UKIDSS LAS & relationship to SDSS
• UKIDSS LAS overlaps with SDSS
• list measurements: - at positions defined by IR source, but in optical image data; - do not currently envisage implementing this the other way (ie. optical source positions placed in IR image data)
WFCAM Science Archive
Curation – set of entities to trackin-DBMS processing:
• archived programmes have: - required filter set - required join(s) - required list – driven measurement product(s) - release date(s) - final curation task - one or more curation timestamps
• a set of curation procedures is defined for the archive
The V2.0 R&D programme for the WSA: scalability issues
• speed: wish to maintain query response performance as catalogue data accumulate to many Tbytes
- goal is ~100sec for Tbyte trawls (ie. non-indexed)
• data volume: wish to cope ultimately with single tables of size 10s of Tbytes or more …
But: we’re poor academics!
• limited financial resources - can’t afford rolls-royce SAN-type solution, for example
• staff resources limited - need low maintenance systems