44
What if you didn’t have any hard goals..? And got rewards continually? And have stochastic actions? MDPs as Utility-based problem solving agents
| Date post: | 19-Dec-2015 |
| Category: |
Documents |
| View: | 214 times |
| Download: | 0 times |

What if you didn’t have any hard goals..?
And got rewards continually?And have stochastic actions?
MDPs as Utility-based problem solving agents
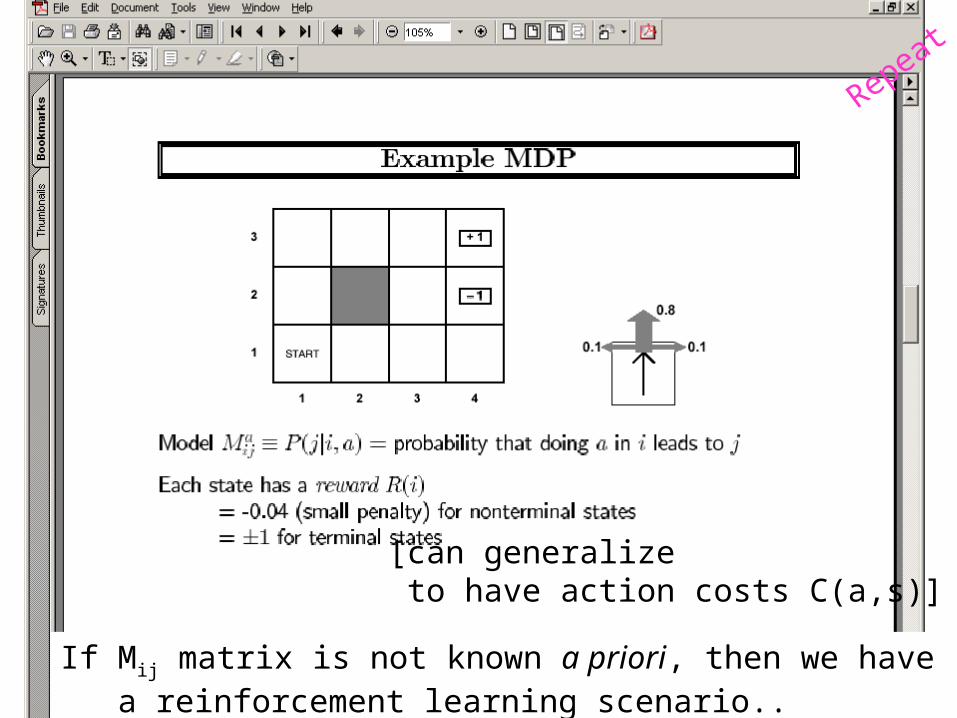
[can generalize to have action costs C(a,s)]
If Mij matrix is not known a priori, then we have a reinforcement learning scenario..
Repeat

Think of these as h*() values…Called value function U*
Think of these as related to h* values
Repeat
U* is the maximal expected utility (value) assuming optimal policy
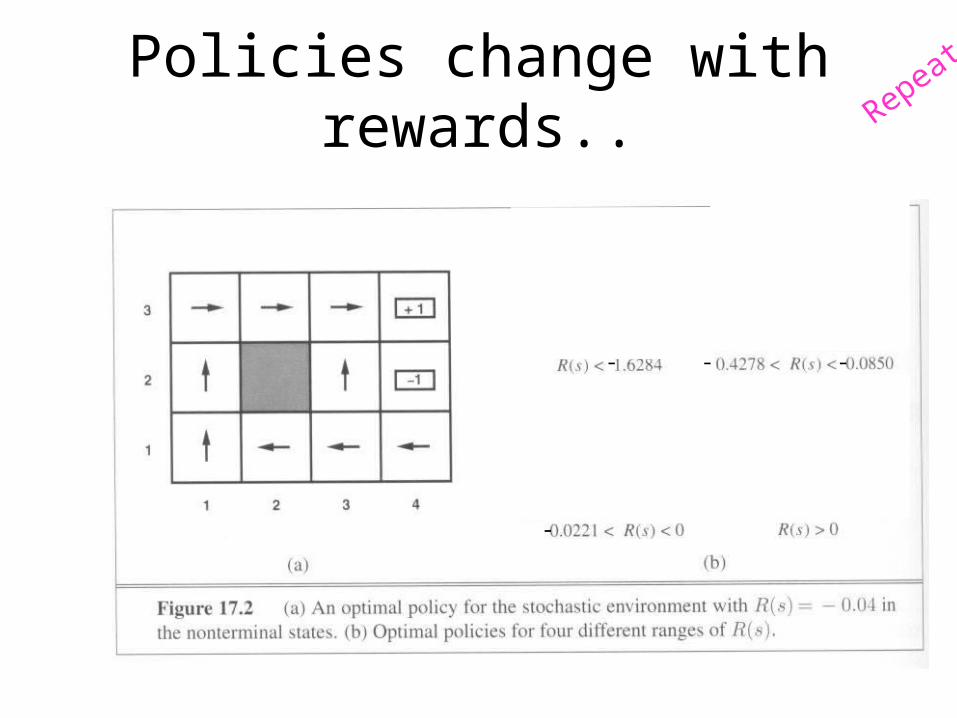
Policies change with rewards..
- -
Repeat
-
-

(Value)
How about deterministic case? U(si) is the shortest path to the goal
Repeat
(“sequence of states” = “behavior”)

MDPs and Deterministic Search• Problem solving agent search corresponds to what special case of
MDP?– Actions are deterministic; Goal states are all equally valued, and are all
sink states.• Is it worth solving the problem using MDPs?
– The construction of optimal policy is an overkill• The policy, in effect, gives us the optimal path from every state to the goal
state(s))– The value function, or its approximations, on the other hand are useful.
How?• As heuristics for the problem solving agent’s search
• This shows an interesting connection between dynamic programming and “state search” paradigms– DP solves many related problems on the way to solving the one
problem we want– State search tries to solve just the problem we want– We can use DP to find heuristics to run state search..

SSPP—Stochastic Shortest Path Problem An MDP with Init and Goal states
• MDPs don’t have a notion of an “initial” and “goal” state. (Process orientation instead of “task” orientation)
– Goals are sort of modeled by reward functions
• Allows pretty expressive goals (in theory)
– Normal MDP algorithms don’t use initial state information (since policy is supposed to cover the entire search space anyway).
• Could consider “envelope extension” methods
– Compute a “deterministic” plan (which gives the policy for some of the states; Extend the policy to other states that are likely to happen during execution
– RTDP methods
• SSSP are a special case of MDPs where
– (a) initial state is given– (b) there are absorbing goal states– (c) Actions have costs. Goal states
have zero costs. • A proper policy for SSSP is a policy
which is guaranteed to ultimately put the agent in one of the absorbing states
• For SSSP, it would be worth finding a partial policy that only covers the “relevant” states (states that are reachable from init and goal states on any optimal policy)
– Value/Policy Iteration don’t consider the notion of relevance
– Consider “heuristic state search” algorithms
• Heuristic can be seen as the “estimate” of the value of a state.

Why are they called Markov decision processes?
• Markov property means that state contains all the information (to decide the reward or the transition)
– Reward of a state Sn is independent of the path used to get to Sn
– Effect of doing an action A in state Sn doesn’t depend on the way we reached state Sn
– (As a consequence of the above) Maximal expected utility of a state S doesn’t depend on the path used to get to S
• Markov properties are assumed (to make life simple)– It is possible to have non-markovian rewards (e.g. you will get a reward in state
Si only if you came to Si through SJ• E.g. If you picked up a coupon before going to the theater, then you will get a reward
– It is possible to convert non-markovian rewards into markovian ones, but it leads to a blow-up in the state space. In the theater example above, add “coupon” as part of the state (it becomes an additional state variable—increasing the state space two-fold).
– It is also possible to have non-markovian effects—especially if you have partial observability
• E.g. Suppose there are two states of the world where the agent can get banana smell

What does a solution to an MDP look like?
• The solution should tell the optimal action to do in each state (called a “Policy”)
– Policy is a function from states to actions (* see finite horizon case below*)
– Not a sequence of actions anymore• Needed because of the non-deterministic actions
– If there are |S| states and |A| actions that we can do at each state, then there are |A||S| policies
• How do we get the best policy?– Pick the policy that gives the maximal expected reward– For each policy
• Simulate the policy (take actions suggested by the policy) to get behavior traces
• Evaluate the behavior traces• Take the average value of the behavior traces.
• How long should behavior traces be?– Each trace is no longer than k (Finite Horizon case)
• Policy will be horizon-dependent (optimal action depends not just on what state you are in, but how far is your horizon)
– Eg: Financial portfolio advice for yuppies vs. retirees.
– No limit on the size of the trace (Infinite horizon case)
• Policy is not horizon dependent• Qn: Is there a simpler way than having to evaluate
|A||S| policies? – Yes…
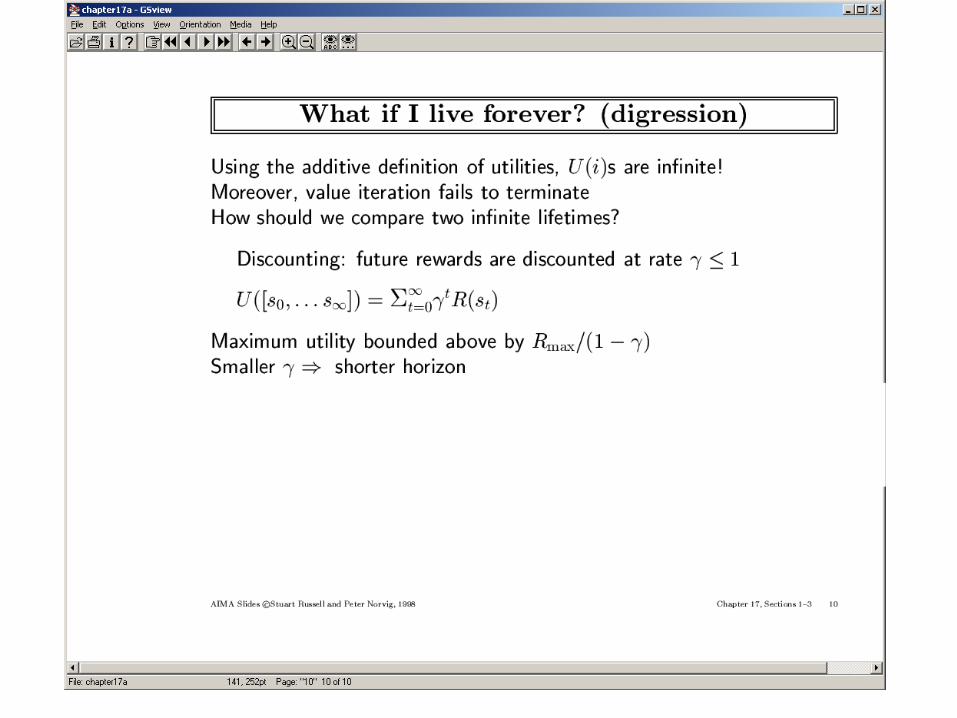
We will concentrate on infinite horizon problems (infinite horizon doesn’t necessarily mean that that all behavior traces are infinite. They could be finite and end in a sink state)
(Value)
How about deterministic case? U(si) is the shortest path to the goal

.8
.1.1

Bellman equations when actions have costs
• The model discussed in class ignores action costs and only thinks of state rewards
• More generally, the reward/cost depends on the state as well as action – R(s,a) is the reward/cost of doing action a in state s – The Bellman equation then becomes U(s) = max over a { R(s,a) + expected utility of doing a}
• Notice that the only difference is that R(.,.) is now inside the maximization
• With this model, we can talk about “partial satisfaction” planning problems where– Actions have costs; goals have utilities and the optimal plan may
not satisfy all goals.

Why are values coming down first?Why are some states reaching optimal value faster?
Updates can be done synchronously OR asynchronously --convergence guaranteed as long as each state updated infinitely often
.8
.1.1

Terminating Value Iteration
• The basic idea is to terminate the value iteration when the values have “converged” (i.e., not changing much from iteration to iteration)– Set a threshold and stop when the change across
two consecutive iterations is less than – There is a minor problem since value is a vector
• We can bound the maximum change that is allowed in any of the dimensions between two successive iterations by
• Max norm ||.|| of a vector is the maximal value among all its dimensions. We are basically terminating when ||Ui – Ui+1|| <

Policies converge earlier than values•There are finite number of policies but infinite number of value functions.
• So entire regions of value vector are mapped to a specific policy
• So policies may be converging faster than values. Search in the space of policies
•Given a utility vector Ui we can compute the greedy policy ui
• The policy loss of ui is ||UuiU*||
(max norm difference of two vectors is the maximum amount by which they differ on any dimension)
V(S1)
V(S2)
Consider an MDP with 2 states and 2 actions
P1P2
P3
P4
U*

We can either solve the linear eqns exactly, or solve them approximately by running the value iteration a few times (the update wont have the “max” operation)
n linear equations with n unknowns.

Other ways of solving MDPs• Value and Policy iteration are the
bed-rock methods for solving MDPs. Both give optimality guarantees
• Both of them tend to be very inefficient for large (several thousand state) MDPs
• Many ideas are used to improve the efficiency while giving up optimality guarantees
– E.g. Consider the part of the policy for more likely states (envelope extension method)
– Interleave “search” and “execution” (Real Time Dynamic Programming)
• Do limited-depth analysis based on reachability to find the value of a state (and there by the best action you you should be doing—which is the action that is sending you the best value)
• The values of the leaf nodes are set to be their immediate rewards
• If all the leaf nodes are terminal nodes, then the backed up value will be true optimal value. Otherwise, it is an approximation…
RTDP
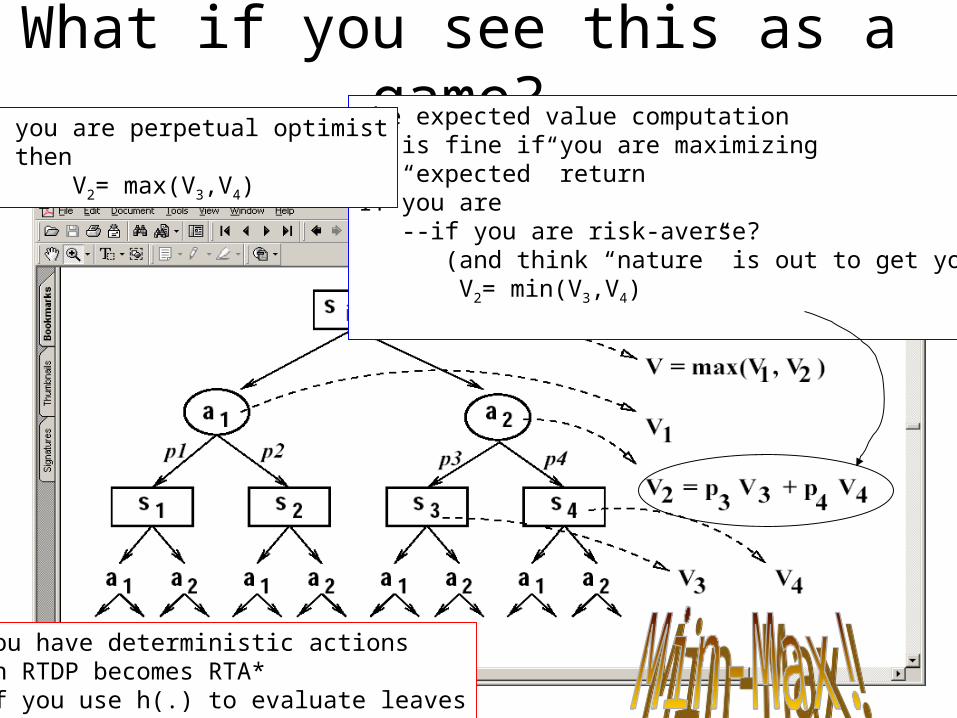
What if you see this as a game?The expected value computation is fine if you are maximizing “expected” returnIf you are --if you are risk-averse? (and think “nature” is out to get you) V2= min(V3,V4)
If you are perpetual optimist then V2= max(V3,V4)
If you have deterministic actions then RTDP becomes RTA* (if you use h(.) to evaluate leaves

Von Neuman(Min-Max theorem)
Claude Shannon(finite look-ahead)
Chaturanga, India (~550AD)(Proto-Chess)
John McCarthy (pruning)
Donald Knuth(analysis)
9/28

Agenda
• Loose ends from MDP– “Horizon” in MDP
• And making rewards finite over infinite horizons
– RTA* (is RTDP with deterministic actions)
– Min-max is RTDP with min-max instead of expectimax
• And today’s main topic– It’s all fun and
GAMESSteaming in Tempe

Announcements etc.
• Homework 2 returned • (!! Our TA doesn’t sleep)
– Average 33/60 – Max 56/60– Solutions online
• Homework 3 socket opened • Project 1 due today
– Extra credit portion will be accepted until Thursday with late penalty
– Any steam to be let off?
• Today’s class
– It’s all fun and GAMES
Steaming in Tempe

What does a solution to an MDP look like?
• The solution should tell the optimal action to do in each state (called a “Policy”)
– Policy is a function from states to actions (* see finite horizon case below*)
– Not a sequence of actions anymore• Needed because of the non-deterministic actions
– If there are |S| states and |A| actions that we can do at each state, then there are |A||S| policies
• How do we get the best policy?– Pick the policy that gives the maximal expected reward– For each policy
• Simulate the policy (take actions suggested by the policy) to get behavior traces
• Evaluate the behavior traces• Take the average value of the behavior traces.
• How long should behavior traces be?– Each trace is no longer than k (Finite Horizon case)
• Policy will be horizon-dependent (optimal action depends not just on what state you are in, but how far is your horizon)
– Eg: Financial portfolio advice for yuppies vs. retirees.
– No limit on the size of the trace (Infinite horizon case)
• Policy is not horizon dependent• Qn: Is there a simpler way than having to evaluate
|A||S| policies? – Yes…
We will concentrate on infinite horizon problems (infinite horizon doesn’t necessarily mean that that all behavior traces are infinite. They could be finite and end in a sink state)

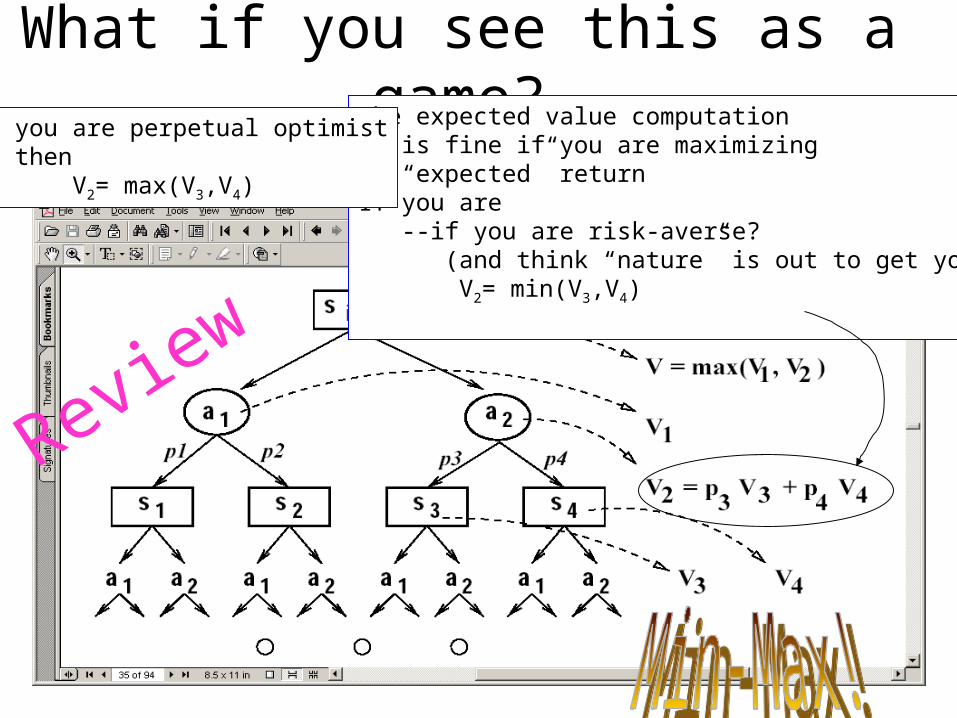
What if you see this as a game?The expected value computation is fine if you are maximizing “expected” returnIf you are --if you are risk-averse? (and think “nature” is out to get you) V2= min(V3,V4)
If you are perpetual optimist then V2= max(V3,V4)
Review

RTA*(RTDP with deterministic actions
and leaves evaluated by f(.))
S n
m
k
G
S
n mG=1H=2F=3
G=1H=2F=3
kG=2H=3F=5
infty
--Grow the tree to depth d --Apply f-evaluation for the leaf nodes--propagate f-values up to the parent nodes f(parent) = min( f(children))
RTA* is a special case of RTDP --It is useful for acting in determinostic, dynamic worlds --While RTDP is useful for actiong in stochastic, dynamic worlds

Game Playing (Adversarial Search)
• Perfect play– Do minmax on the complete game tree
• Resource limits– Do limited depth lookahead– Apply evaluation functions at the leaf nodes– Do minmax
• Alpha-Beta pruning (a neat idea that is the bane of many a CSE471 student)
• Miscellaneous– Games of Chance– Status of computer games..
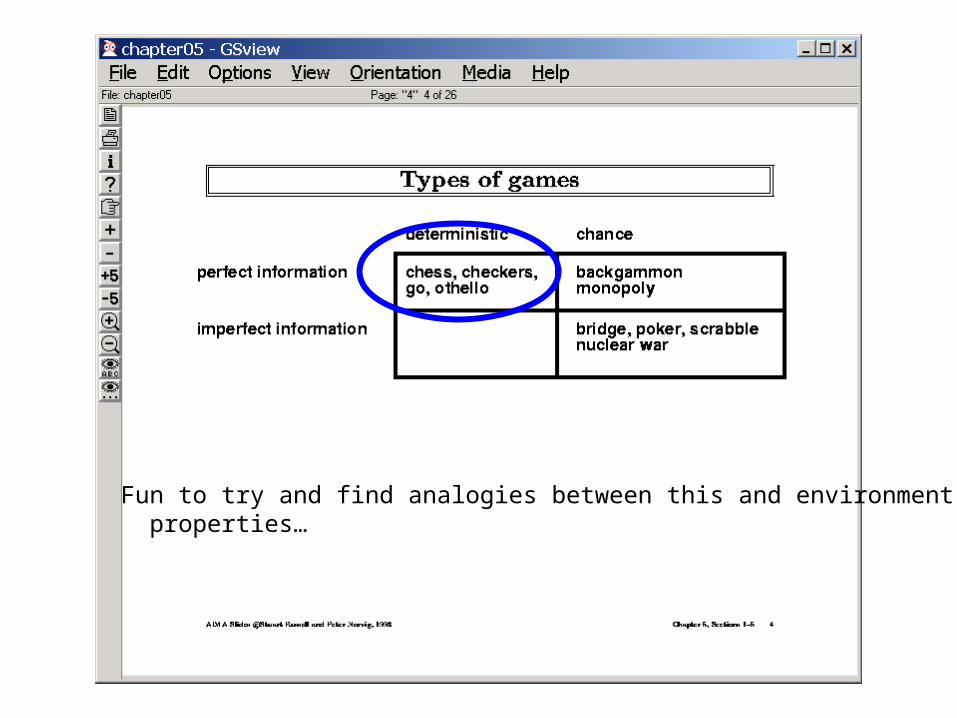
Fun to try and find analogies between this and environment properties…

(just as human weight lifters refuse to compete against cranes)
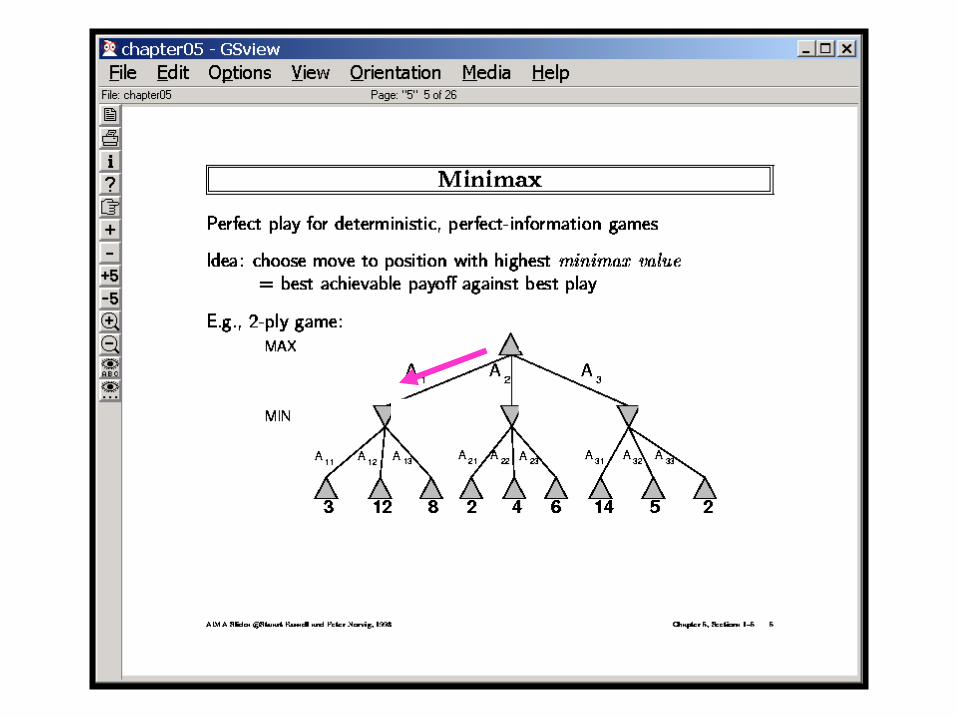
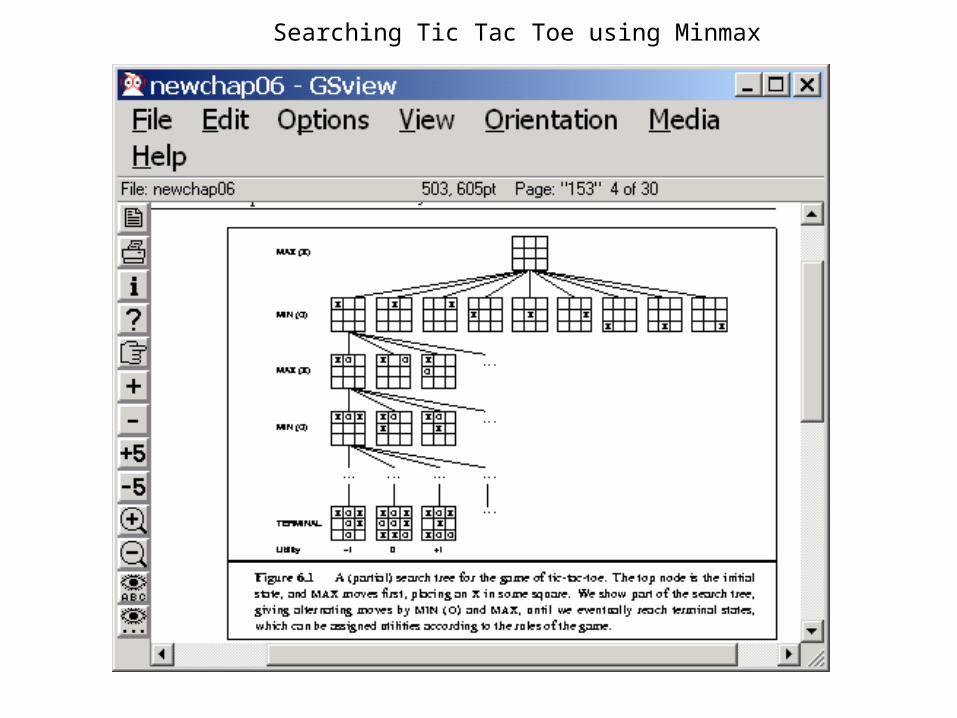
Searching Tic Tac Toe using Minmax

Evaluation Functions: TicTacToe
If win for Max +inftyIf lose for Max -inftyIf draw for Max 0Else # rows/cols/diags open for Max - #rows/cols/diags open for Min

What depth should we go to? --Deeper the better (but why?)
Should we go to uniform depth? --Go deeper in branches where the game is in a flux (backed up values are changing fast) [Called “Quiescence” ]
Can we avoid the horizon effect?

Why is “deeper” better?
• Possible reasons– Taking mins/maxes of the evaluation values of
the leaf nodes improves their collective accuracy
– Going deeper makes the agent notice “traps” thus significantly improving the evaluation accuracy
• All evaluation functions first check for termination states before computing the non-terminal evaluation

2
<= 2
Cut
14
<= 14
5
<= 5
2
<= 2
•Whenever a node gets its “true” value, its parent’s bound gets updated
•When all children of a node have been evaluated (or a cut off occurs below that node), the current bound of that node is its true value
•Two types of cutoffs:
•If a min node n has bound <=k, and a max ancestor of n, say m, has a bound >=j, then cutoff occurs as long as j >=k
•If a max node n has bound >=k, and a min ancestor of n, say m, has a bound <=j, then cutoff occurs as long as j<=k
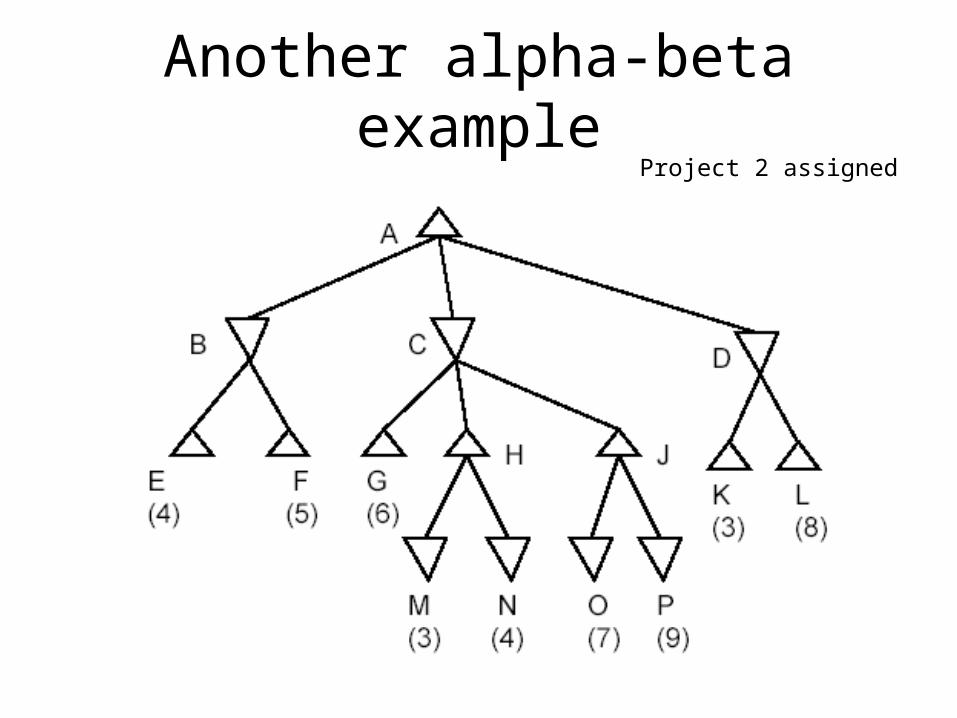
Another alpha-beta exampleProject 2 assigned
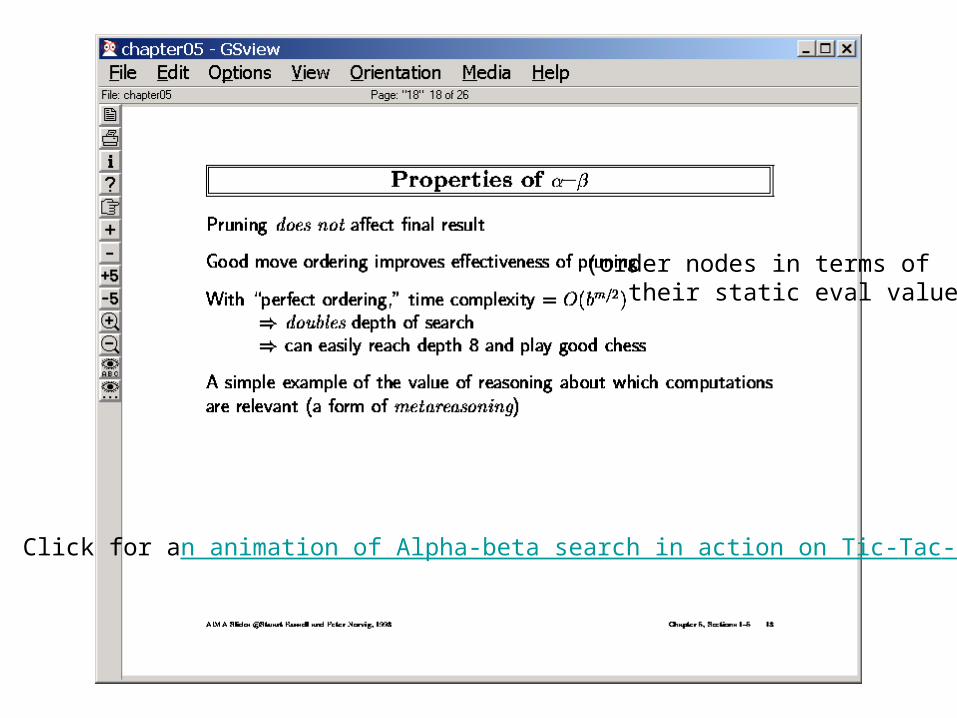
Click for an animation of Alpha-beta search in action on Tic-Tac-Toe
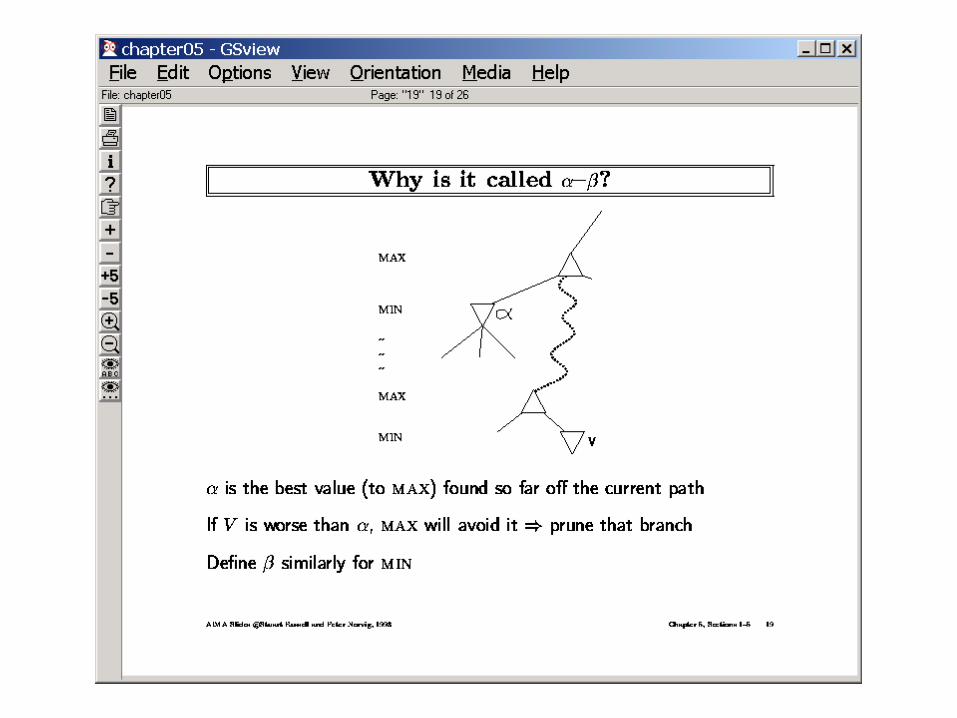
(order nodes in terms of their static eval values)

Multi-player Games
Everyone maximizes their utility --How does this compare to 2-player games? (Max’s utility is negative of Min’s)

Expecti-Max

















