What is missing? Reasons that ideal effectiveness hard to achieve: 1. Users’ inability to describe queries precisely. 2. Document representation loses information. 3. Same term may have multiple meanings and different terms may have similar meanings. 4. Similarity function used not be good enough. 5. Importance/weight of a term in representing a document and query may be inaccurate.
Transcript
What is missing?
Reasons that ideal effectiveness hard to achieve:
1. Users’ inability to describe queries precisely.
2. Document representation loses information.
3. Same term may have multiple meanings and different terms may have similar meanings.
4. Similarity function used not be good enough.
5. Importance/weight of a term in representing a document and query may be inaccurate.
Latent Semantic Indexing Classic IR might lead to poor retrieval due to:
unrelated documents might be included in the answer set relevant documents that do not contain at least one index
term are not retrieved Reasoning: retrieval based on index terms is vague and
noisy The user information need is more related to concepts
and ideas than to index terms A document that shares concepts with another document
known to be relevant might be of interest
Latent Semantic Indexing Creates modified vector space Captures transitive co-occurrence
information If docs A & B don’t share any words, with
each other, but both share lots of words with doc C, then A & B will be considered similar
Handles polysemy (adam’s apple) & synonymy
Simulates query expansion and document clustering (sort of)
A motivating example
Suppose we have keywords Car, automobile, driver, elephant
We want queries on car to also get docs about drivers, but not about elephants Need to realize that driver and car are
related while elephant is not When you scrunch down the dimensions,
small differences get glossed over, and you get the desired behavior
Everything You Always Wanted to Know About LSI, and More
=
=
mxnA
mxrU
rxrD
rxnVT
Terms
Documents
=
=
mxn
Âk
mxkUk
kxkDk
kxnVT
k
Terms
Documents
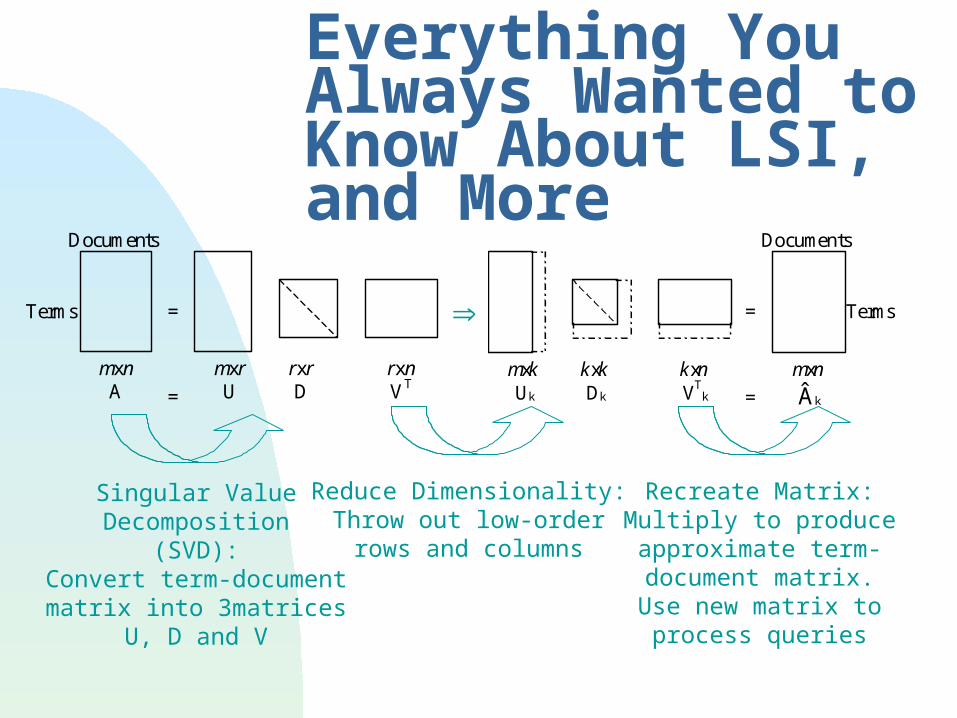
Singular ValueDecomposition
(SVD):Convert term-document
matrix into 3matricesU, D and V
Reduce Dimensionality:Throw out low-order
rows and columns
Recreate Matrix:Multiply to produceapproximate term-document matrix.Use new matrix to
process queries
Latent Semantic Indexing
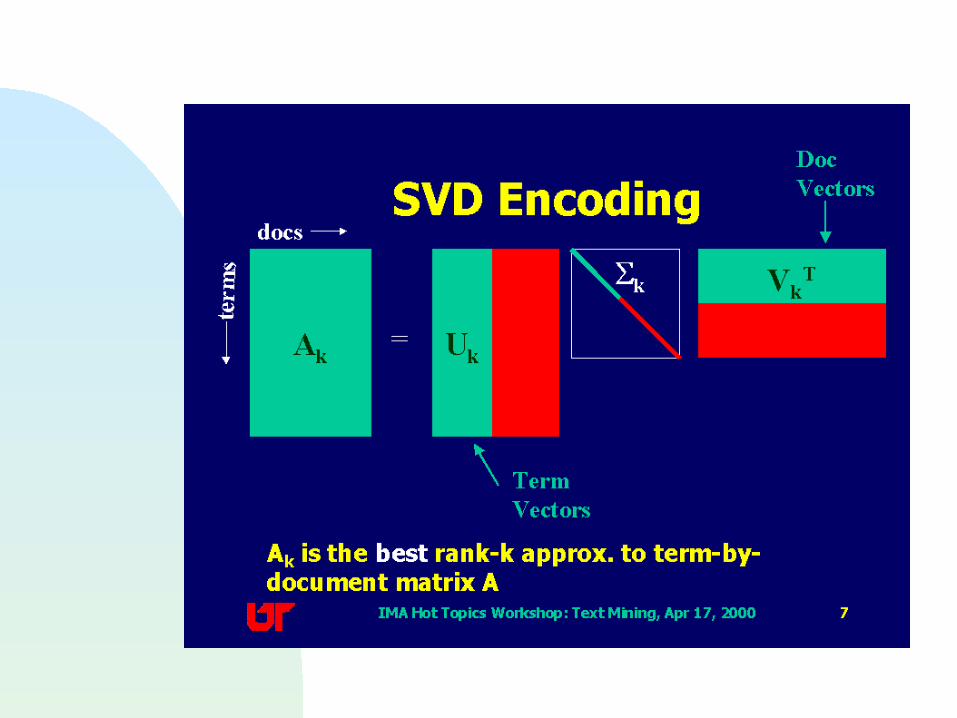
The matrix (Mij) can be decomposed into 3 matrices (singular value decomposition) as follows: (Mij) = (U) (S) (V)t
(U) is the matrix of eigenvectors derived from (M)(M)t
(V)t is the matrix of eigenvectors derived from (M)t(M) (S) is an r x r diagonal matrix of singular values
• r = min(t,N) that is, the rank of (Mij)• Singular values are the positive square roots of the eigen
values of (M)(M)t (also (M)t(M))
For the special case where M is a square matrix, S is the diagonal eigen value matrix, and K and D are eigen vector matrices
K and S are
orthogonal
matrices
Latent Semantic Indexing
The key idea is to map documents and queries into a lower dimensional space (i.e., composed of higher level concepts which are in fewer number than the index terms)
Retrieval in this reduced concept space might be superior to retrieval in the space of index terms
Latent Semantic Indexing In the matrix (S), select only the k largest singular values Keep the corresponding columns in (U) and (V)t
The resultant matrix is called (M)k and is given by (M)k = (U)k (S)k (D)t
k
where k, k < r, is the dimensionality of the concept space The parameter k should be
large enough to allow fitting the characteristics of the data small enough to filter out the non-relevant representational
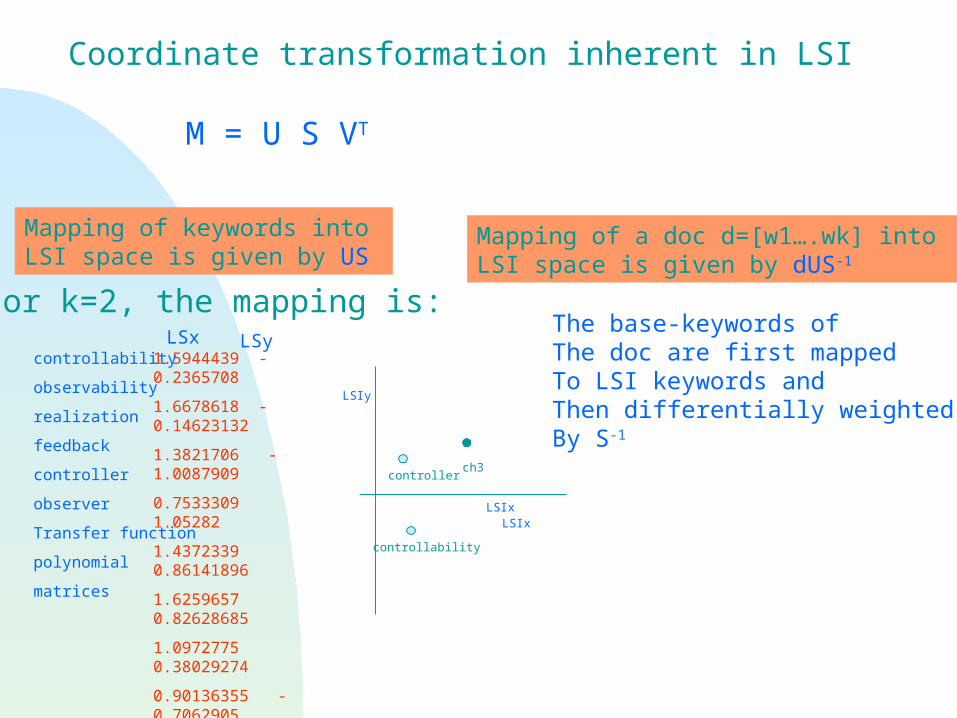
Mapping of a doc d=[w1….wk] into LSI space is given by dUS-1
The base-keywords ofThe doc are first mapped To LSI keywords and Then differentially weightedBy S-1
ch3
Medline data from Berry’s paper
Querying To query for feedback controller, the query vector would be q = [0 0 0 1 1 0 0 0 0]' (' indicates transpose),
since feedback and controller are the 4-th and 5-th terms in the index, and no other terms are selected. Let q be the query vector. Then the document-space vector corresponding to q is given by: q'*U2*inv(S2) = Dq
For the feedback controller query vector, the result is: Dq = 0.1376 0.3678
To find the best document match, we compare the Dq vector against all the document vectors in the 2-dimensional V2 space. The document vector that is nearest in direction to Dq is the best match. The cosine values for the eight document vectors and the query vector are: -0.3747 0.9671 0.1735 -0.9413 0.0851 0.9642 -0.7265 -0.3805
Latent Ranking (a la text) The user query can be modelled as a pseudo-document in
the original (M) matrix Assume the query is modelled as the document numbered
0 in the (M) matrix The matrix (M)t(M)s
quantifies the relantionship between any two documents in the reduced concept space
The first row of this matrix provides the rank of all the documents with regard to the user query (represented as the document numbered 0)
s Ineffici
ent w
ay
Folding docs -Convert new documents into LSI space using the dUS-1 method
Folding terms -find the vectors for new terms as weighted sum of the docs in which they occur
Practical Issues: How often do you re-compute SVD when terms or documents are added to the collection? --Folding is a cheaper solution but will worsen quality over time
Summary of LSI
Latent semantic indexing provides an interesting conceptualization of the IR problem
No stemming needed, spelling errors tolerated Can do true conceptual retrieval
Retrieval of documents that do not share any keywords with the query!