What’s next ?? 3.3 Protein function 10.3 Protein secondary structure predictio 17.3 Protein tertiary structure prediction 24.3 Gene expression & Gene networks 31.3 RNA structure and function 7.4 Advances in Bioinformatics
Transcript
What’s next ??
Today 3.3 Protein function 10.3 Protein secondary structure prediction 17.3 Protein tertiary structure prediction 24.3 Gene expression & Gene networks 31.3 RNA structure and function
7.4 Advances in Bioinformatics
Predicting Protein Function
proteinRNADNA
Biochemical function(molecular function)
What does it do?Kinase???Ligase???
Page 245
Function based onligand binding specificity
What (who) does it bind ??
Page 245
Function basedon biological process
What is it good for ??Amino acid metabolism?
Page 245
Function based oncellular location
DNA RNA
Page 245
Where is it active?? Nucleolus ?? Cytoplasm??
Function based oncellular location
DNA RNA
Page 245
Where is the RNA/Protein Expressed ??Brain? Testis? Where it is under expressed??
GO (gene ontology)http://www.geneontology.org/
• The GO project is aimed to develop three structured, controlled vocabularies (ontologies) that describe gene products in terms of their associated
> Database that contains a large collection of multiple sequence alignments of protein domains
Based on Profile hidden Markov Models (HMMs).
Profile HMM (Hidden Markov Model)
D16 D17 D18 D19
M16 M17 M18 M19
I16 I19I18I17
100%
100% 100%
100%
D 0.8S 0.2
P 0.4R 0.6
T 1.0 R 0.4S 0.6
X XX X
50%
50%D R T RD R T SS - - SS P T RD R T RD P T SD - - SD - - SD - - SD - - R
16 17 18 19
HMM is a probabilistic model of the MSA consisting of a number of interconnected states
Match
delete
insert
Pfam
> Database that contains a large collection of multiple sequence alignments of protein domains
Based on Profile hidden Markov Models (HMMs).
> The Pfam database is based on two distinct classes of alignments
–Seed alignments which are deemed to be accurate and used to produce Pfam A-Alignments derived by automatic clustering of SwissProt, which are less reliable and give rise to Pfam B
Physical properties of proteins
DNA binding domains have relatively high frequency of basic (positive) amino acids
M K D P A A L K R A R N T E A AR R S S R A R K L Q R M
GCN4
zif268 M E R P Y A C P V E S C D R R FS R S D E L T R H I R I H T
myoDS K V N E A F E T L K R C T S S N
P N Q R L P K V E I L R N A I R
Transmembrane proteins have a unique hydrophobicity pattern
Physical properties of proteins
Many websites are available for the analysis ofindividual proteins for example:EXPASY (ExPASy)UCSC Proteome BrowserProtoNet HUJI
The accuracy of the analysis programs are variable. Predictions based on primary amino acid sequence (such as molecular weight prediction) are likely to be more trustworthy. For many other properties (such asposttranslational modification of proteins by specific sugars), experimental evidence may be required rather than prediction algorithms.
Page 236
Knowledge Based Approach
• IDEA Find the common properties of a protein
family (or any group of proteins of interest) which are unique to the group and different
from all the other proteins. Generate a model for the group and predict
new members of the family which have similar properties.
Knowledge Based Approach
• Generate a dataset of proteins with a common function (DNA binding protein)
• Generate a control dataset • Calculate the different properties which are characteristic
of the protein family you are interested for all the proteins in the data (DNA binding proteins and the non-DNA binding proteins
• Represent each protein in a set by a vector of calculated features and build a statistical model to split the groups
Basic Steps1. Building a Model
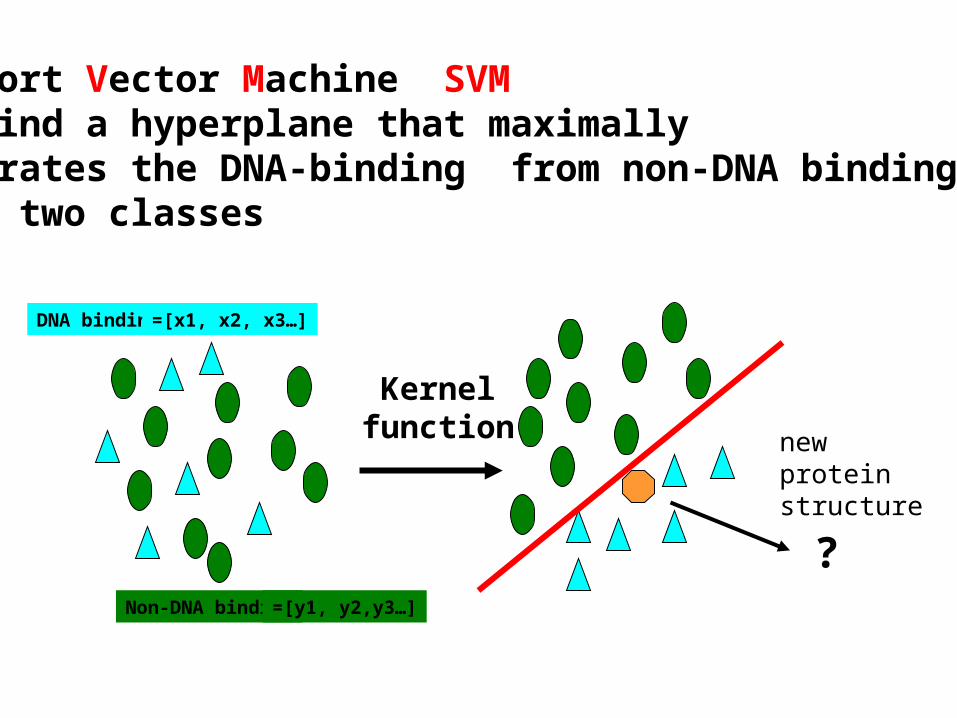
Support Vector Machine (SVM)To find a hyperplane that maximallyseparates the DNA-binding from non-DNA bindinginto two classes
Input space Feature space
Kernelfunction
?
newproteinstructure
DNA binding
Non-DNA binding
=[x1, x2, x3…]
=[y1, y2,y3…]
• Calculate the properties for a new protein
And represent them in a vector
• Predict whether the tested protein belongs to the family
Basic Steps2. Predicing the function of a new protein
Database and Tools for protein families and domains
• InterPro - Integrated Resources of Proteins Domains and Functional Sites
• Prosite – A dadabase of protein families and domain • BLOCKS - BLOCKS db • Pfam - Protein families db (HMM derived)• PRINTS - Protein Motif fingerprint db • ProDom - Protein domain db (Automatically generated) • PROTOMAP - An automatic hierarchical classification of Swiss-Prot
proteins • SBASE - SBASE domain db • SMART - Simple Modular Architecture Research Tool • TIGRFAMs - TIGR protein families db