33
WRF Performance Optimization Targeting Intel Multicore and Manycore Architectures Samm Elliott Mentor – Davide Del Vento
| Date post: | 30-Dec-2015 |
| Category: |
Documents |
| Upload: | bryan-wilkerson |
| View: | 244 times |
| Download: | 3 times |

WRF Performance Optimization Targeting Intel Multicore
and Manycore Architectures
Samm ElliottMentor – Davide Del Vento

2
The WRF ModelThe Weather Research and
Forecasting (WRF) Model is a mesoscale numerical weather prediction system designed for both atmospheric research and operational forecasting needs.
Used by over 30,000 Scientists around the world.
Any Optimizations that can be made will make a significant impact on the WRF community as a whole.

3
Stampede Supercomputer
6400 Nodes(Dell PowerEdge C8220)
Two CPU’s Per Node(Intel Xeon E5-2680 Processors Per Node)
32 GB Memory Per Node
1-2 Coprocessors Per Node(Intel Xeon Phi SE10P)

4
Intel Xeon vs Xeon Phi Architecture
Xeon E5 2680 CPU
8 Cores
2-Way Hyperthreading
256 Bit Vector Registers
2.7 GHz
32 KB L1
256 KB L2
20 MB Shared L3
32 GB Main Memory
Xeon Phi SE10P Coprocessor
61 Cores
4-Way Hyperthreading (2 Hardware Threads Per
Core)
512 Bit Vector Registers
1.1 GHz
32 KB L1
512 KB L2
No L3 Cache
8 GB Main Memory

5
Intro: WRF Gets Good Performance on Xeon Phi!
Memory Limitations

6
Standard MPI Implementation Strong Scaling
Compute Bound MPI Bound
High EfficiencySlow Time to Solution
Low EfficiencyFast Time to Solution

7
MPI Tile Decomposition

8
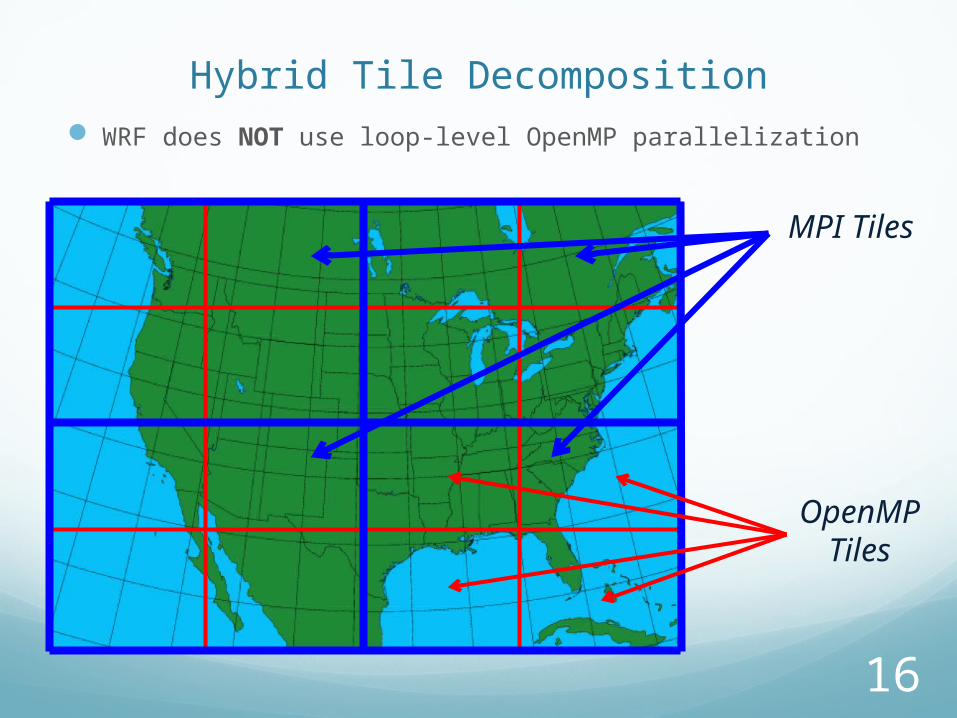
Hybrid Tile Decomposition
MPI Tiles
OpenMP Tiles
WRF does NOT use loop-level OpenMP parallelization

9
MPI vs. Hybrid Parallelization
What do we expect?
MPI Only Hybrid
Less Halo Layer Communication (White Arrows) Less MPI Overhead and Therefore Faster!
10
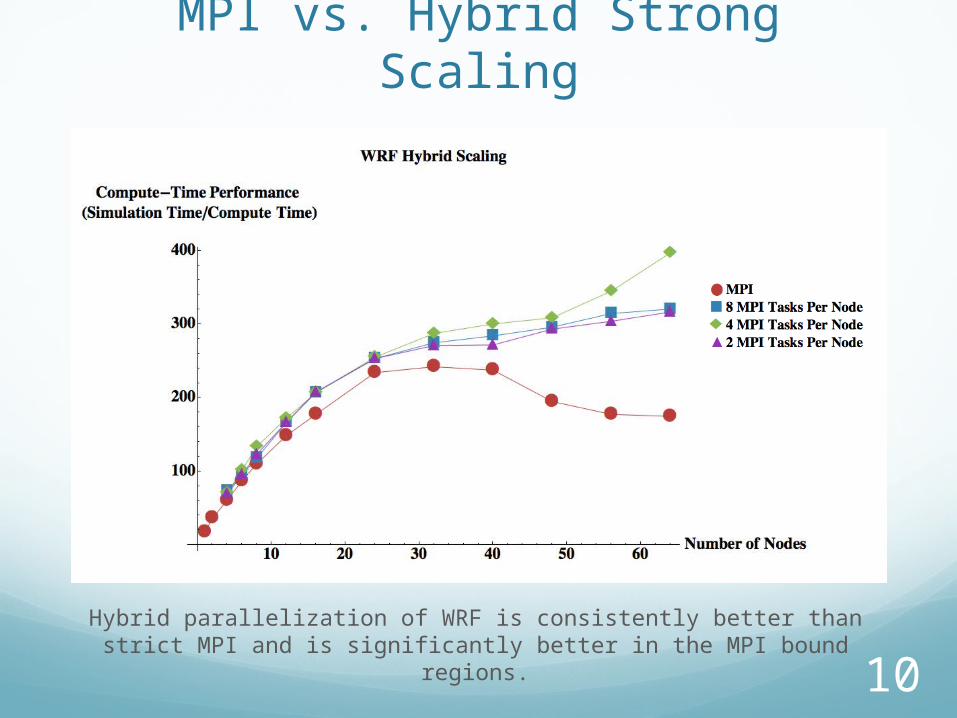
MPI vs. Hybrid Strong Scaling
Hybrid parallelization of WRF is consistently better than strict MPI and is significantly better in the MPI bound regions.
11
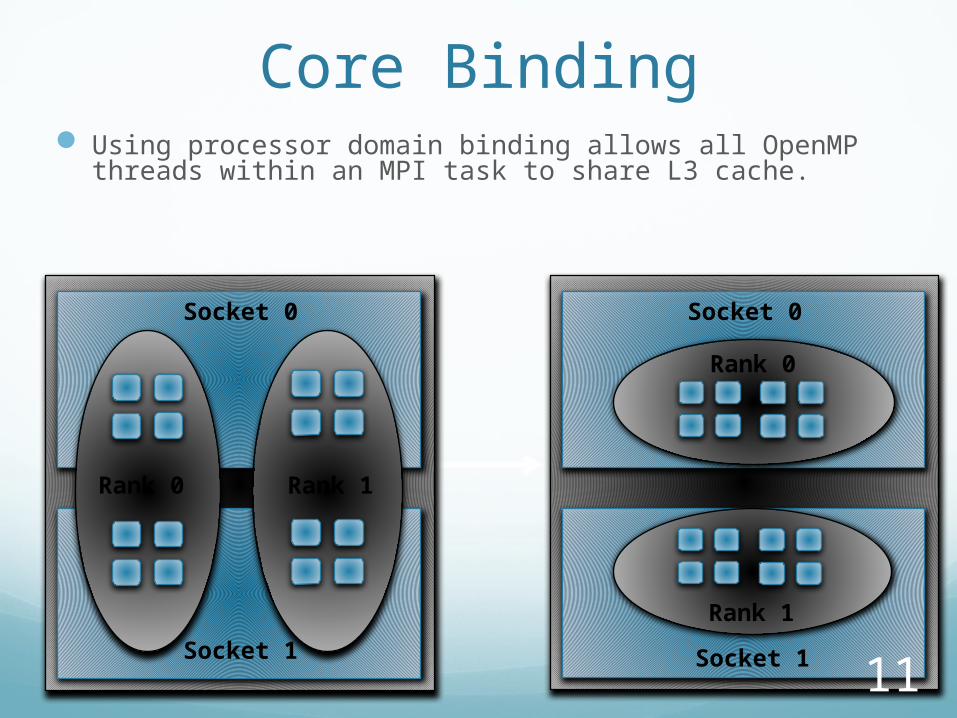
Core Binding Using processor domain binding allows all OpenMP threads
within an MPI task to share L3 cache.
Socket 0
Socket 1
Rank 0 Rank 1
Socket 0
Socket 1
Rank 0
Rank 1
12
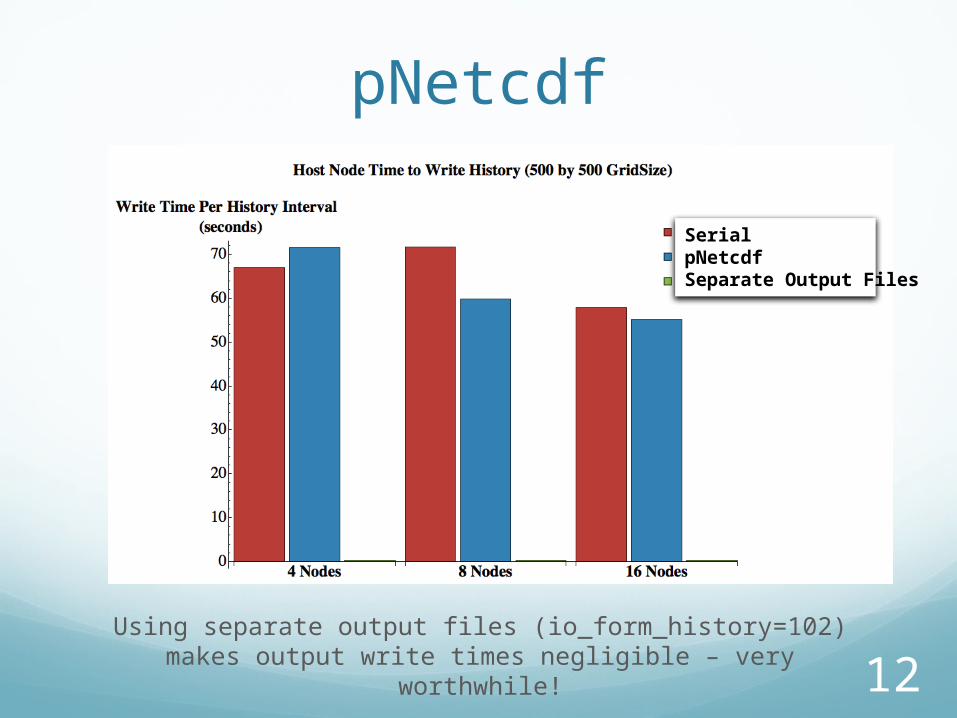
pNetcdf
Using separate output files (io_form_history=102) makes output write times negligible – very worthwhile!
SerialpNetcdfSeparate Output Files
13
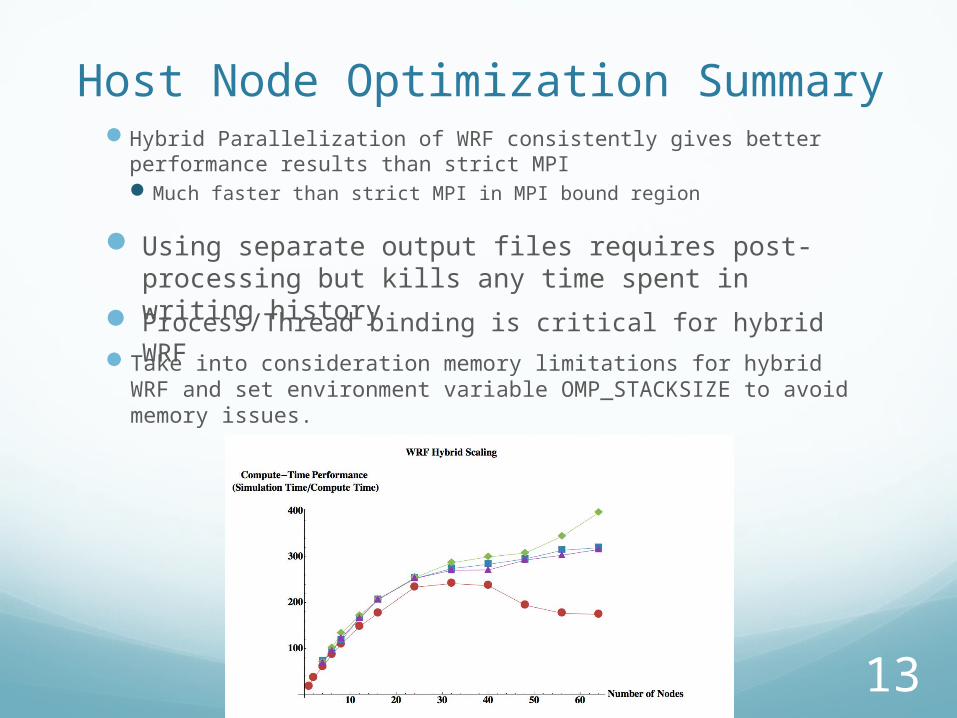
Host Node Optimization Summary Hybrid Parallelization of WRF consistently gives better
performance results than strict MPI Much faster than strict MPI in MPI bound region
Using separate output files requires post-processing but kills any time spent in writing history
Process/Thread binding is critical for hybrid WRF
Take into consideration memory limitations for hybrid WRF and set environment variable OMP_STACKSIZE to avoid memory issues.

14
Xeon Phi IO
SerialpNetcdfSeparate Output Files
15
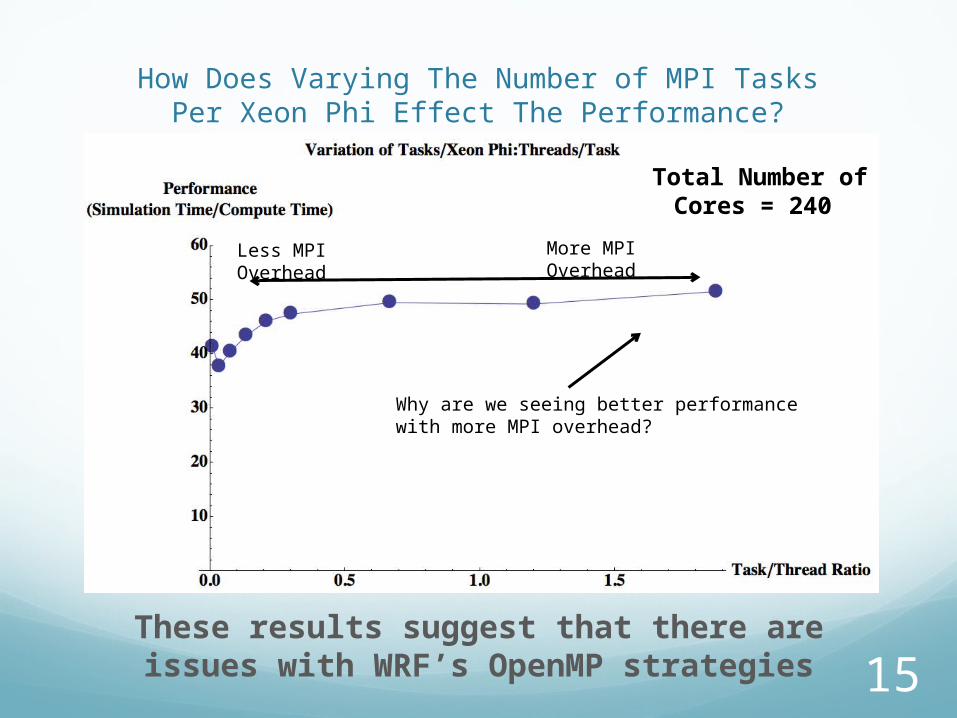
How Does Varying The Number of MPI Tasks Per Xeon Phi Effect The Performance?
These results suggest that there are issues with WRF’s OpenMP strategies
More MPI Overhead
Less MPI Overhead
Why are we seeing better performance with more MPI overhead?
Total Number of Cores = 240
16
Hybrid Tile Decomposition
MPI Tiles
OpenMP Tiles
WRF does NOT use loop-level OpenMP parallelization

17
Open MP ImbalancingTwo types of Imbalancing:
1. Number of OpenMP Tiles > Number of OpenMP Threads
2. OpenMP Tiles are Different Sizes
Default Tiling Issue:When number of threads is equal to any multiple
of the number of MPI tile rows

18
Example – 10 x 10 grid run with 2 MPI tasks and 8 OpenMP threads per MPI task
OpenMP Imbalance Type 1:
MPI Rank 0
MPI Rank 1Threads #1 and #2 compute 2 OpenMP tiles each
(twice as much work as other threads + context switch overhead)

19
OpenMP Imbalance Type 2:
Example – 4 MPI Tasks, 4 OpenMP Threads Per Task
MPI Rank 0
MPI Rank 2
MPI Rank 1
MPI Rank 3
Thread #4 computes twice as many grid cells as all other threads!

20
OpenMP Good BalancingExample: 8 by 8 grid run with 2 MPI Tasks and 8 OpenMP
threads per task
MPI Rank 0
MPI Rank 1
The logical tiling would be a 2 by 4 OpenMP tiling but WRF does a 3 by 4 creating an unnecessary imbalance
I was able to resolve this issue and will be fixed in the next version of WRF
21
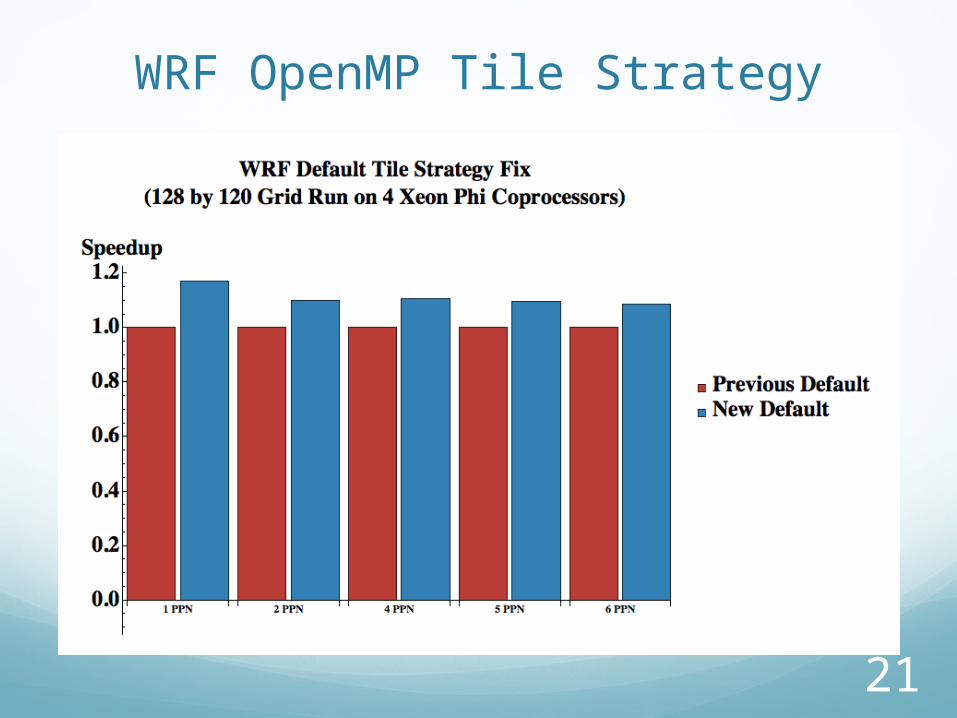
WRF OpenMP Tile Strategy

22
What is an Optimal WRF Case For Xeon Phi?
a
Xeon Phi Approaches Xeon Performance for Large Workload/Core
Xeon Phi – Initial Scaling
23
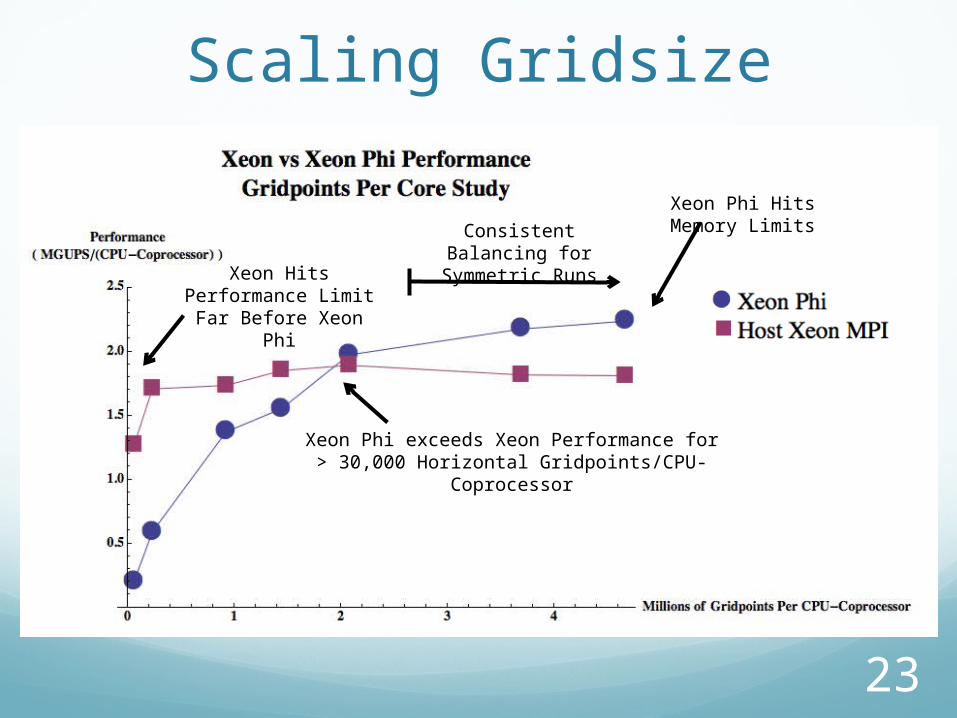
Scaling Gridsize
Xeon Phi exceeds Xeon Performance for> 30,000 Horizontal Gridpoints/CPU-Coprocessor
Xeon Hits Performance Limit Far Before Xeon Phi
Consistent Balancing for Symmetric Runs
Xeon Phi Hits Memory Limits

24
Xeon Phi Optimization Summary:The Good
Xeon Phi can be more efficient than host CPU’s in extreme high efficiency/slow time to solution region
For highly efficient workloads, due to low MPI overhead and constant efficiency it is possible to have well balanced symmetric CPU-Coprocessor WRF runs that are significantly more efficient than running on either homogeneous architecture

25
Xeon Phi Optimization Summary:The Bad
WRF strong scaling performance is significantly less than host node CPU runs.
WRF tiling strategies are not well optimized for manycore architectures
WRF/Fortran’s array allocation strategies result in much larger memory requirements and limit workloads that otherwise would have high efficiency on Xeon Phi

26
Although Xeon Phi could be used for highly efficient WRF simulations, finding the correct:1. problem sizes
2. task-thread ratios
3. tile decompositions and
4. workload per core
5. while taking into consideration memory limitations
makes Xeon Phi extremely impractical for the vast majority of WRF users.
Xeon Phi Optimization Summary:The Ugly

27
Why is it Important to Continue Researching WRF on Xeon Phi?
Core counts will continue to increase for future HPC architectures – This will require better hybrid strategies for our models.
Xeon Phi is very representative of these architectures and is a tool for exposing various issues that otherwise may not be noticed until further down the road.

28
Future WorkCreate better MPI+OpenMP tile strategies for
low workload per core simulations
Better understand performance issues with heap allocation and overall memory access patterns
Assess any other concerns that may hinder WRF performance on future multicore/manycore architectures

29
Acknowledgements Davide Del Vento – Mentor
Dave Gill – WRF Help
Srinath Vadlamani – Xeon Phi/Profiling
Mimi Hughes – WRF
XSEDE/Stampede – Project Supercomputer Usage
SIParCS/Rich Loft – Internship Opportunity
Thank you all for giving me so much help throughout this process. I am extremely thankful for my experience here at NCAR!

30
Questions?

31
Memory Issues For Small Core Counts
Ensure OMP_STACKSIZE is set correctly(default may be set much lower than
necessary)
Memory use by WRF variables is multiplied by the number of threads per MPI task. Not much of an issue for small number of threads per task

32
Memory Issues For Small Core Counts
Memory use by WRF variables is multiplied by the number of threads per MPI task.
Temporary Solution: Force heap array allocation (-heap-array) Extremely slow in compute-bound regions (“speeddown”
proportional to number of threads per task) Potential Culprits:
Cache Coherency? Repeated temporary array allocation?

33
Forcing Heap Array Allocation

















