Roelof Pieters “ZeroShot Learning Through CrossModal Transfer” 20 February 2015 Deep Learning Reading Group Richard Socher, Milind Ganjoo, Hamsa Sridhar, Osbert Bastani, Christopher D. Manning, Andrew Y. Ng http://arxiv.org/abs/1301.3666 @graphific ICLR 2013 http://papers.nips.cc/… NIPS 2013 Review of http://www.csc.kth.se/~roelof/
Transcript
Roelof Pieters
“Zero-‐Shot Learning Through Cross-‐Modal Transfer”
20 February 2015 Deep Learning Reading Group
Richard Socher, Milind Ganjoo, Hamsa Sridhar, Osbert Bastani, Christopher D. Manning, Andrew Y. Ng
“a zero-shot model that can predict both seen and unseen classes”
Zero-Shot Learning Through Cross-Modal TransferRichard Socher, Milind Ganjoo, Hamsa Sridhar, Osbert Bastani, Christopher D. Manning, Andrew Y. Ng, ICLR 2013
Core (novel) Idea:
Key Ideas• Semantic word vector representations:
• Allows transfer of knowledge between modalities
• Even when these representations are learned in an unsupervised way
• Bayesian framework:
1. Differentiate between unseen/seen classes
2. From points on the semantic manifold of trained classes
3. Allows combining both zero-shot and seen classification into one framework[ Ø-shot + 1-shot = “multi-shot” :) ]
Visual-Semantic Word Space• Word vectors capture distributional similarities
from a large, unsupervised text corpus. [Word vectors create a semantic space] (Huang et al. 2012)
• Images are mapped into a semantic space of words that is learned by a neural network model (Coates & Ng 2011; Coates et al. 2011)
• By learning an image mapping into this space, the word vectors get implicitly grounded by the visual modality, allowing us to give prototypical instances for various word (Socher et al. 2013, this paper)
• Word vectors capture distributional similarities from a large, unsupervised text corpus. [Word vectors create a semantic space] (Huang et al. 2012)
• Images are mapped into a semantic space of words that is learned by a neural network model (Coates & Ng 2011; Coates et al. 2011)
• By learning an image mapping into this space, the word vectors get implicitly grounded by the visual modality, allowing us to give prototypical instances for various word (Socher et al. 2013, this paper)
Visual-Semantic Word SpaceSemantic Space
Visual-Semantic Word SpaceSemantic Space
E. H. Huang, R. Socher, C. D. Manning, and A. Y. Ng. Improving Word Representations via Global Context and Multiple Word Prototypes. In ACL, 2012
• (Socher et al. 2013) uses pre-trained (50-d) word vectors of (Huang et al. 2012):
“You shall know a word by the company it keeps” (J. R. Firth 1957)
One of the most successful ideas of modern statistical NLP!
these words represent banking
Distributed Semantics (short recap)
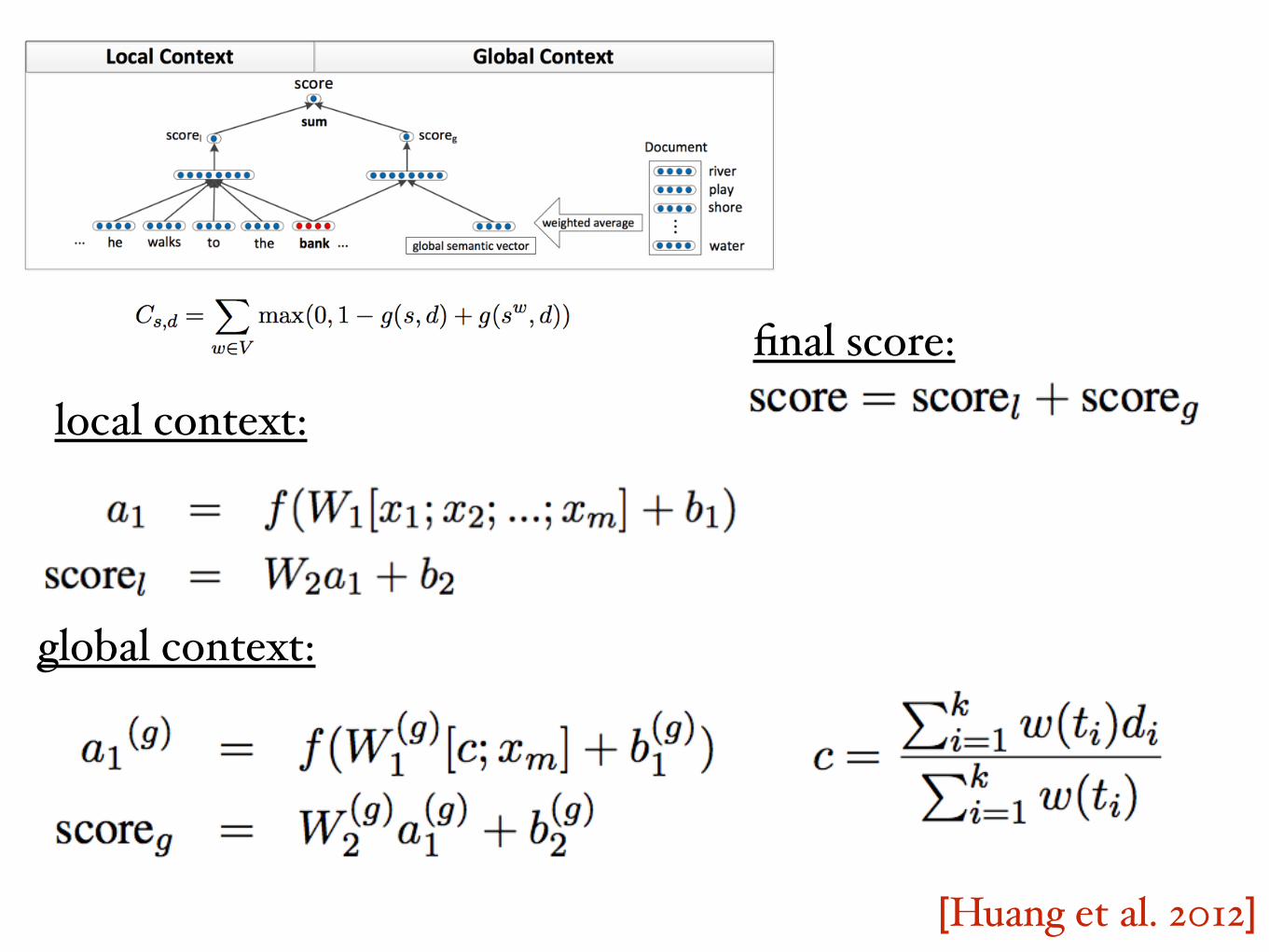
[Huang et al. 2012]
[Huang et al. 2012]
local context:
global context:
final score:
[Huang et al. 2012]
activation of the hidden layer with h hidden nodes
1st layer weights
2th layer weights
1st layer bias
2th layer bias
local context scoring function
element-wise activation function (ie tanh)
concatenation of the m word embeddings representing sequence s
activation of the hidden layer with h(g) hidden nodes
1st layer weights
2th layer weights
1st layer bias
2th layer bias
concatenation of the weighted average document vector and the vector of the last word in s
weighting function that captures the importance of word ti in the document (tf-idf)
global context scoring function
document(s) as ordered list of word embeddings
weighted average of all word vectors in a document
• Word vectors capture distributional similarities from a large, unsupervised text corpus. [Word vectors create a semantic space] (Huang et al. 2012)
• Images are mapped into a semantic space of words that is learned by a neural network model (Coates & Ng 2011; Coates et al. 2011)
• By learning an image mapping into this space, the word vectors get implicitly grounded by the visual modality, allowing us to give prototypical instances for various word (Socher et al. 2013, this paper)
Visual-Semantic Word SpaceSemantic Space
• Word vectors capture distributional similarities from a large, unsupervised text corpus. [Word vectors create a semantic space] (Huang et al. 2012)
• Images are mapped into a semantic space of words that is learned by a neural network model (Coates & Ng 2011; Coates et al. 2011)
• By learning an image mapping into this space, the word vectors get implicitly grounded by the visual modality, allowing us to give prototypical instances for various word (Socher et al. 2013, this paper)
Visual-Semantic Word SpaceSemantic Space
Image Features
Image Feature Learning
• high level description: extract random patches, extract features from sub-patches, pool features, train liner classifier to predict labels
• = fast simple algorithms with the correct parameters work as well as complex, slow algorithms
[Coates et al. 2011 (used by Coates & Ng 2011)]
• Word vectors capture distributional similarities from a large, unsupervised text corpus. [Word vectors create a semantic space] (Huang et al. 2012)
• Images are mapped into a semantic space of words that is learned by a neural network model (Coates & Ng 2011; Coates et al. 2011)
• By learning an image mapping into this space, the word vectors get implicitly grounded by the visual modality, allowing us to give prototypical instances for various word (Socher et al. 2013, this paper)
Visual-Semantic Word SpaceSemantic Space
Image Features
• Word vectors capture distributional similarities from a large, unsupervised text corpus. [Word vectors create a semantic space] (Huang et al. 2012)
• Images are mapped into a semantic space of words that is learned by a neural network model (Coates & Ng 2011; Coates et al. 2011)
• By learning an image mapping into this space, the word vectors get implicitly grounded by the visual modality, allowing us to give prototypical instances for various word (Socher et al. 2013, this paper)
Visual-Semantic Word SpaceSemantic Space
Visual-Semantic Space
Image Features
[this paper, Socher et al. 2013]
Visual-Semantic Space
Projecting Images into Visual Space
Objective function(s):
[Socher et al. 2013]
training images
set of word vectors seen/unseen visual classes
mapped to the word vector (class name)
Projecting Images into Visual Space
Objective function(s):
[Socher et al. 2013]
training images
set of word vectors seen/unseen visual classes
mapped to the word vector (class name)
T-SNE visualization of the semantic word space [Socher et al. 2013]
[Socher et al. 2013]
Projecting Images into Visual Space
Mapped points of seen classes:
(Outlier Detection)
Predicting class y:
binary visibility random variable
probability of an image being in an unseen class
Treshold T:
[Socher et al. 2013]
Projecting Images into Visual Space(Outlier Detection)
binary visibility random variable
probability of an image being in an unseen class
known class prediction:
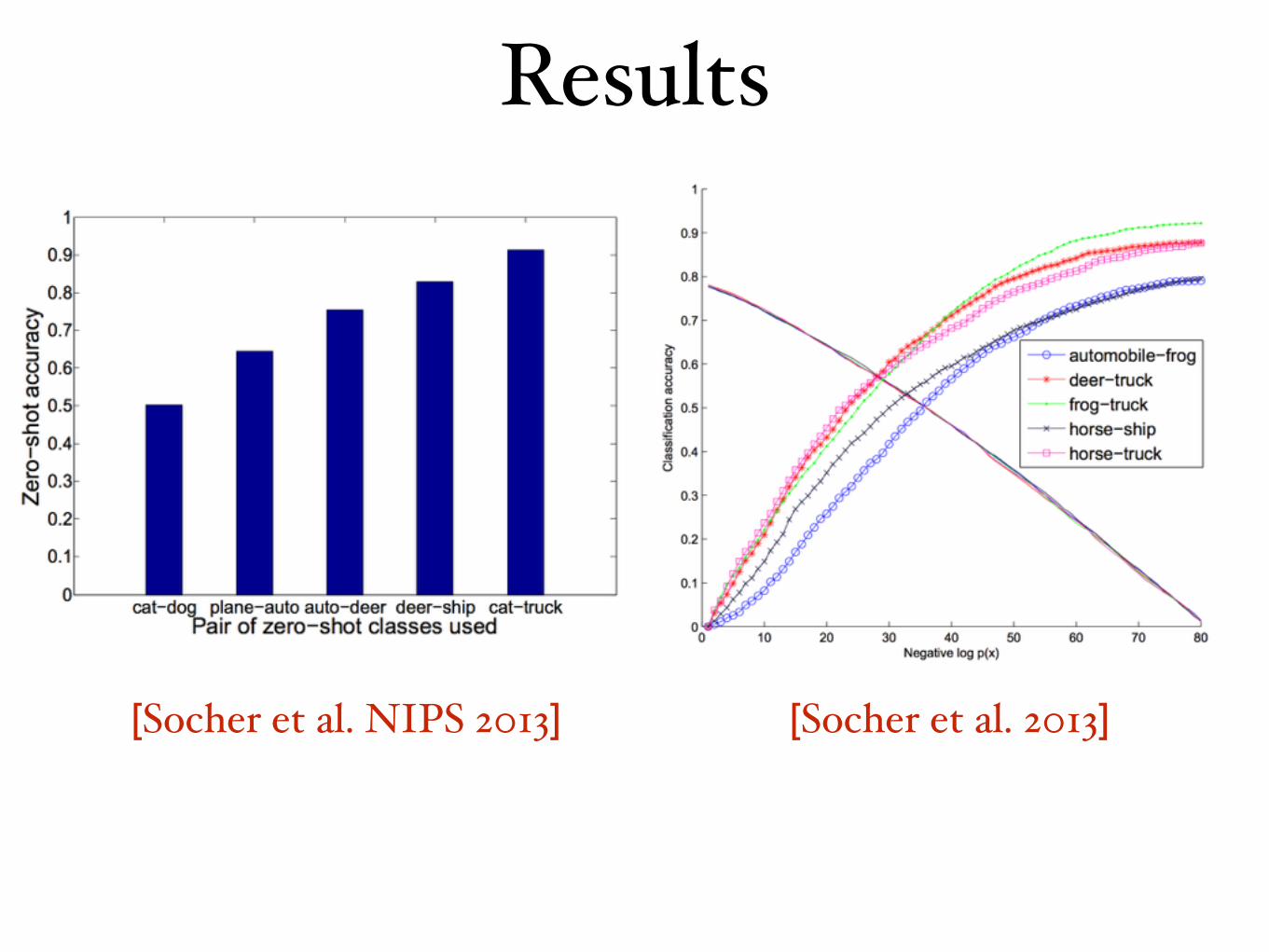
[Socher et al. 2013][Socher et al. NIPS 2013]
Results
Main ContributionsZero-shot learning
• Good classification of (pairs of) unseen classes can be achieved based on learned representations for these classes
• => as opposed to hand designed representations
• => extends (Lampert 2009; Guo-Jun 2011) [Manual defined visual/semantic attributes to classify unseen classes]
Main Contributions“Multi”-shot learning
• Deal with both seen and unseen classes: Allows combining both zero-shot and seen classification into one framework: [ Ø-shot + 1-shot = “multi-shot” :) ]
• Assumption: unseen classes as outliers
• Major weakness:drop from 80% to 70% for 15%-30% accuracy (on particular classes)
• => extends (Lampert 2009; Palatucci 2009) [manual defined representations, limited to zero-shot classes], using outlier detection
• => extends (Weston et al. 2010) (joint embedding images and labels through linear mapping) [linear mapping only, so cant generalise to new classes: 1-shot], using outlier detection
Main ContributionsKnowledge-Transfer
• Allows transfer of knowledge between modalities, within multimodal embeddings
• Allows for unsupervised matching
• => extends (Socher & Fei-Fei 2012) (kernelized canonical correlation analysis) [still require small amount of training data for each class: 1-shot]
• => extends (Salakhutdinov et al. 2012) (learn low-level image features followed by a probabilistic model to transfer knowledge) [also limited to 1-shot classes]
Bibliography• C. H. Lampert, H. Nickisch, and S. Harmeling. Learning to
Detect Unseen Object Classes by Between-Class Attribute Transfer. In CVPR, 2009
• M. Palatucci, D. Pomerleau, G. Hinton, and T. Mitchell. Zero-shot learning with semantic output codes. In NIPS, 2009
• Guo-Jun Qi, C. Aggarwal, Y. Rui, Q. Tian, S. Chang, and T. Huang. Towards cross-category knowledge propagation for learning visual concepts. In CVPR, 2011
• R. Socher and L. Fei-Fei. Connecting modalities: Semi-supervised segmentation and annotation of images using unaligned text corpora. In CVPR, 2010
• E. H. Huang, R. Socher, C. D. Manning, and A. Y. Ng. Improving Word Representations via Global Context and Multiple Word Prototypes. In ACL, 2012
Bibliography• A. Coates and A. Ng. The Importance of Encoding Versus
Training with Sparse Coding and Vector Quantization. In ICML, 2011.
• Coates, Adam, Lee, Honlak, and Ng, Andrew Y. An analysis of single-layer networks in unsupervised feature learning. In International Conference on AI and Statistics, 2011.
• A. Torralba R. Salakhutdinov, J. Tenenbaum. Learning to learn with compound hierarchical-deep models. In NIPS, 2012.
• J. Weston, S. Bengio1, and N. Usunier. Large Scale Image Annotation: Learning to Rank with Joint Word-Image Embeddings. In Machine Learning, 81 (1):21-35, 2010

































![Learning Aligned Cross-Modal Representations from Weakly ...cmplaces.csail.mit.edu/content/paper.pdfOne-Shot/Zero-Shot Learning: One-shot learning techniques [10] have been developed](https://static.documents.pub/doc/80x56/5f85e49ca1d3a8189b46dba7/learning-aligned-cross-modal-representations-from-weakly-one-shotzero-shot.jpg)





![Task-Driven Modular Networks for Zero-Shot Compositional ... · Compositional zero-shot learning (CZSL) is a special case of zero-shot learning (ZSL) [21,13]. In ZSL the learner observes](https://static.documents.pub/doc/80x56/5eb8d2d73e42c7454216139e/task-driven-modular-networks-for-zero-shot-compositional-compositional-zero-shot.jpg)





