

1
Aditya P. Mathur
Head and Professor
Department of Computer Science,
Purdue University
ABB, SwedenMonday April 7, 2008
Towards a Radically New Theory of Software Reliability

2
Reliability
Probability of failure free operation in a given environment over a
given time.
Mean Time To Failure (MTTF)
Mean Time To Disruption (MTTD)
Mean Time To Restore (MTTR)

3
Claim
Existing theories of software reliability simplify the
problem to the extent that they (almost) maximize the
uncertainty associated with the estimated software
reliability.

4
Operational profile
Probability distribution of usage of features and/or scenarios.
Captures the usage pattern with respect to a class of customers.

5
Reliability estimation
Operationalprofile
Random or semi-random Test generation
Test execution Failure/Defect data collection
Reliability estimation [Uncertainty evaluation?]
Decision process

6
Issues: Operational profile
Variable. Becomes known only after customers have access to the product. Is a stochastic process…a moving target!
Random test generation requires an oracle. Hence is generally limited to specific outcomes, e.g. crash, hang.
What about an operational profile with impulse? This creates a non-differentiable probability function of the time-to-failure.

7
Issues: Failure data
Should we analyze the failures?
If yes then after the cause is removed then the reliability estimate is invalid.
If the cause is not removed because the failure is a “minor incident” then the reliability estimate corresponds to irrelevant incidents.

8
Issues: Failure rate
“That is, the failure rate, when unambiguously defined, does not have a physical reality; rather, it is a technical device, whose sole purpose is to convey the engineer’s personal opinion about the life characteristic of software.”
Nozer Singpurwalla, “The failure rate of software: does it exists?”, IEEE Transactions on Reliability, vol. 44, no.
3,1995.

9
Issues: Model selection
Rarely does a model fit the failure data.
Model selection becomes a problem. 200 models to choose from? New ones keep arriving!
Markov chain models suffer from a lack of estimate of transition probabilities.
To compute these probabilities, you need to execute the application.
During execution you obtain failure data. Then why proceed further with the model?

10
Issues: Markovian models
Markov chain models suffer from a lack of estimate of transition probabilities.
To compute these probabilities, you need to execute the application.
During execution you obtain failure data. Then why proceed further with the model?
C1
C3
C212
13 32
21
12 + 13=1

11
Issues: Assumptions
Software does not degrade over time; memory leak is not degradation and is not a random process; a new version is a different piece of software.
Reliability estimate varies with operational profile. Different customers see different reliability.
Can we not have a reliability estimate that is independent of operational profile?
Can we not advertise quality based on metric that are a true representation of reliability..not with respect to a subset of features but over the entire set of features?

12
Estimating Uncertainty
Estimates of software reliability must the associated with uncertainty. But how to quantify uncertainty?
Entropy based approach [Katerina et al. 2002] Moments based approach [Katerina et al. 2003] Monte Carlo approach [Katerina et al. 2003] Bayesian approach [Dai et al. 2007]

13
Estimating Uncertainty
Basic idea:
Model the parameters as random variables. Use statistical (e.g. moments) or Simulation approaches to
estimate variance.
Problem: Does not correlate with likely faulty components in the program
under test.
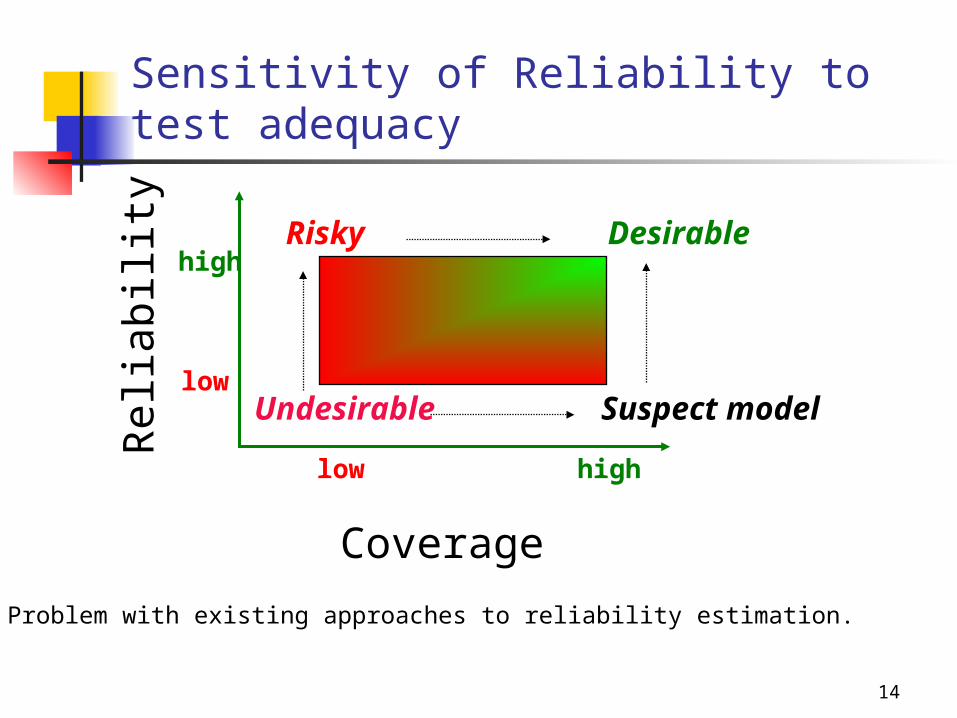
14
Sensitivity of Reliability to test adequacy
Coverage
low
low
high
high
Desirable
Suspect modelUndesirable
Risky
Rel
iabi
lity
Problem with existing approaches to reliability estimation.

15
Basis for an alternate approach
Why not develop a theory based on coverage of testable items and test adequacy?
Testable items: Variables, statements,conditions, loops, data flows, methods, classes, etc.
Pros: Errors hide in testable items.
Cons: Coverage of testable items is inadequate. Is it a good predictor of reliability?
Yes, but only when used carefully. Let us see what happens when coverage is not used or not used carefully.
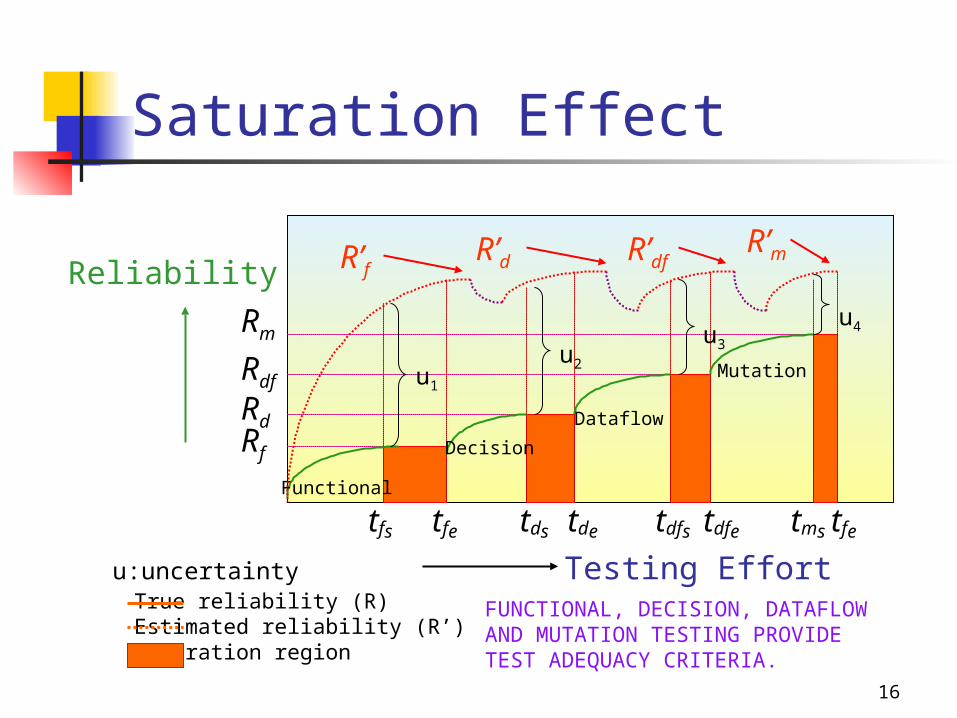
16
Saturation Effect
FUNCTIONAL, DECISION, DATAFLOWAND MUTATION TESTING PROVIDETEST ADEQUACY CRITERIA.
Reliability
Testing EffortTrue reliability (R)Estimated reliability (R’)Saturation region
Mutation
Dataflow
Decision
Functional
RmRdfRdRf
R’f R’d R’df R’m
tfs tfe tds tde tdfs tdfe tms tfeu:uncertainty
u1
u2
u3
u4
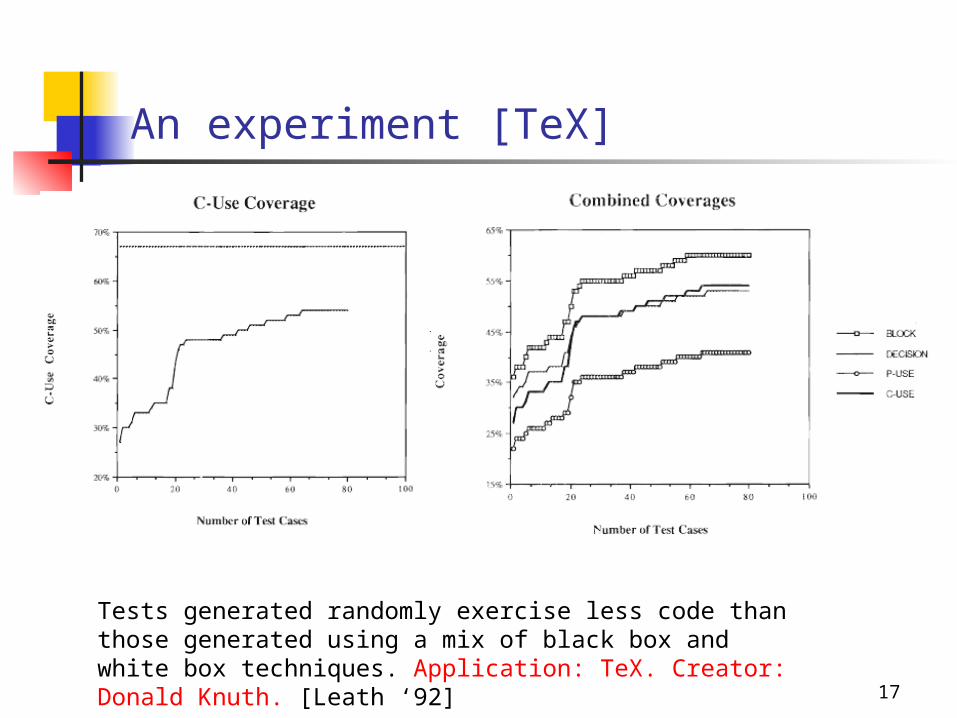
17
An experiment [TeX]
Tests generated randomly exercise less code than those generated using a mix of black box and white box techniques. Application: TeX. Creator: Donald Knuth. [Leath ‘92]

18
An experiment [sort utility]
UNIX sort utility [DelFrate et al. 1995]

19
An experiment [coverage-reliability correlations]
Unix utilities and space application [Garg 1995. MS Thesis]

20
Modeling an application
OSComponent
Component
Component
Interactions
Component
Component
Component
Interactions
Component
Component
Component
Interactions
……….

21
Reliability of a component
R(f)= (covered/total), 0<<1.
Reliability, probability of correct operation, of function f based on a given finite set of testable items.
Issue: How to compute ?
Approach: High correlation between coverage metrics and failures has been established via empirical studies. Such studies could provide estimate of and its variance for different sets of testable items.

22
Reliability of a subsystem
R(C)= g(R(f1), R(f2), ..R(fn), R(I))
C={f1, f2,..fn} is a collection of components that collaborate with each other to provide services.
Issue 1: How to compute R(I), reliability of component interactions?
Issue 2: What is g ?
Issue 3: Theory of systems reliability creates problems when (a) components are in a loop and (b) are dependent on each other.

23
Scalability
Is the component based approach scalable?
Powerful coverage measures lead to better reliability estimates whereas measurement of coverage becomes increasingly difficult as more powerful criteria are used.
Solution: Use component based, incremental, approach. Estimate reliability bottom-up. No need to measure coverage of components whose reliability is known.

24
Next steps
Develop component based theory of reliability.
Do experimentation with large systems to investigate the applicability of the their and its effectiveness in predicting and estimating various reliability metrics.
Base the new theory on existing work in software testing and reliability.

25
The Future
Apple Confidence: 0.999
Level 0: 1.0
Level 1: 0.9999
Level 2: 0.98
Boxed and embedded software with independently variableLevels of Confidence.
Mackie Confidence: 0.99
Level 0: 1.0
Level 1: 0.9999

26
Select References
F. Del Frate, P. Garg, A. P. Mathur, and A. Pasquini. On the Correlation Between Code Coverage and Software Reliability, Proceedings of the Sixth International Symposium on Software Reliability Engineering, IEEE Press,Toulouse, France, pp 124-132, October 24-27, 1995
S. Krishnamurthy and A. P. Mathur. On the Estimation of Reliability of a Software System Using Reliabilities of its Components, Proceedings of the 8th International Symposium on Software Reliability Estimation, Albuquerque, New Mexico, November 1997.
M. H. Chen. A. P. Mathur, and V. J. Rego. A Case Study To Investigate Sensitivity Of Reliability Estimates To Errors In The Operational Profile, Proceedings of the Fifth International Symposium on Software Reliability Engineering, IEEE Computer Society Press, Monterey, California, November 6-9, 1994, pp 276-281.
Katerina Goseva–Popstojanova and Sunil Kamavaram. Assessing Uncertainty in Reliability of Component–Based Software. Proceedings of the 14th International Symposium on Software Reliability Engineering (ISSRE’03), 2003.
Yuan-Shun Dai and Min Xie and Quan Long and Szu-Hui Ng. Uncertainty Analysis in Software Reliability Modeling by Bayesian Analysis with Maximum-Entropy Principle, IEEE Trans. Softw. Eng.,V 33, No. 11, 2007, pp 781--795.
P. Garg. On code coverage and software reliability. MS Thesis. Department of Computer
Science, Purdue University. May 1995.







