

1
Automated Searching of Polynucleotide Sequences
Michael P. WoodwardSupervisory Patent Examiner - Art Unit 1631
571 272 [email protected]
John L. LeGuyaderSupervisory Patent Examiner - Art Unit 1635
571 272 [email protected]

2
Standard Databases
• GenEMBL .rge
• N_Genseq .rng
• Issued_Patents_NA .rni
• EST .rst
• Published_Applications_NA .rnpb

3
Databases at Time of Allowability
• Pending_Patents_NA_Main .rnpm
• Pending_Patents_NA_New .rnpn

4
Types of Nucleotide Sequence Searching
• Standard (cDNA)
• Oligomer
• Length Limited Oligomer
• Score over Length

5
Types of Nucleotide Sequence Searching
• Standard (cDNA)– useful for finding full length hits– the query sequence is typically the full length of
the SEQ ID NO:– the search parameters are the default parameters-
Gap Opening Penalty & Gap Extension Penalty of 10
– standard suite of NA databases are searched– normally 45 results and the top fifteen alignments
are provided, however, additional results and alignments can be provided.

6
Standard (cDNA) search
• Fragments and genomic sequences are often difficult to find
• Fragments are buried in the hit list• The presence of introns in the
database sequence results in low scores.

7
Types of Nucleotide Sequence Searching
• Standard Oligomer – finds longest matching hits
– mismatches not tolerated in region of hit
match
• Length Limited Oligomer– returns database hits within length range
requested– mismatches not tolerated in region of hit
match

8
Standard Oligomer Searching
• Only provides the longest oligomer present in the sequence
• A thorough search of fragments requires multiple searches
• Can be an effective way of finding genomic sequences

9
Standard Oligomer Searching
• the search parameters are the default parameters-Gap Opening Penalty & Gap Extension Penalty of 60-mismatches not tolerated
• Consequently inefficient means of finding small sequences, and with <100% in correspondence

10
Claim 1
• An isolated polynucleotide comprising SEQ. ID. No: 1.

11
Searching Claim 1
• A standard search looking for full length hits is performed.

12
0001 CGGCTCGTATGTTGTGTGGAATTGTGAGCGGATAACAATTTCACACAGGAAACAGATGG 00602031 CGGCTCGTATGTTGTGTGGAATTGTGAGCGGATAACAATTTCACACAGG---CAGATGG 2090
Standard (cDNA) search result

13
Claim 2
• An isolated polynucleotide comprising at least 15 contiguous nucleotides of SEQ. ID. No: 1.

14
Searching Claim 2
• An standard oligomer search is performed with an oligomer length of 15 nucleotides set as the lower limit for a hit.

15
Oligomer Search Results
Standard Oligomer
CAAATGCAGGCCCCCGGACCTCCCTGCTCCTGGCTTTCGCCCTGCTCTGCCTGCCCTGG
Query CCCTGCTCCTGGCTTTCGCCCTGCTCTGCCTGCCCTGG 0060
Database CCCTGCTCCTGGCTTTCGCCCTGCTCTGCCTGCCCTGG 2500
Length Limited Oligomer
CAAATGCAGGCCCCCGGACCTCCCTGCTCCTGGCTTTCGCCCTGCTCTGCCTGCCCTGG
Query CCCTGCTCCTGGCTTTCGCCCTGCTCTGCCTGCCCTGG 0060
Database CCCTGCTCCTGGCTTTCGCCCTGCTCTGCCTGCCCTGG 0039

16
Claim 3
• An isolated polynucleotide comprising a polynucleotide encoding a polypeptide of SEQ ID No: 2.
• (SEQ ID No: 2 is an Amino Acid (AA) sequence)

17
Searching Claim 3
• Seq ID No: 2 is searched against the Polypeptide databases and it is “back translated” and searched against the polynucleotide databases.

18
Claim 4
• An isolated polynucleotide comprising a polynucleotide with at least 90% identity to SEQ ID No: 1.

19
Searching Claim 4
• A standard search looking for full length hits is performed.
• Hits having at least 90% identity will appear in the results.

20
Claim 5
• An isolated polynucleotide comprising a polynucleotide which hybridizes under stringent conditions to SEQ ID No: 1.

21
Searching Claim 5
• A standard oligomer search is performed as well as a standard search.

22
Searching Small Nucleotide Sequences
John L. LeGuyader

23
Types of Small Nucleotide Sequences Claimed
• Fragments• Complements/Antisense• Primers/Probes• Oligonucleotides/Oligomers• Antisense/RNAi/Triplex/Ribozymes (inhibitory)
• Accessible Target/Region within Nucleic Acids• Aptamers• Nucleic Acid Binding Domains• Immunostimulatory CpG Sequences

24
Small Nucleotide Sequences Claimed as Sense or Antisense?
• What is being claimed? – Requesting the correct sequence search starts
with interpreting what is being claimed
• Complementary Sequences– DNA to DNA: C to G– DNA to RNA: A to U
• Matching Sequences– A to A– U to U
• DNA, RNA, Chimeric• cDNA, Message (mRNA), Genomic DNA

25
Impact of Sequence Identity and Length
• Size and Identity Matter• Complements/Matches
• 100% correspondence• Mismatches
- Varying Degrees of Percent Identity
• Gaps- Insertion or Deletions- Gap Extensions
• Wild Cards• % Query Match value approximates identity
• Adjustment of search parameters (e.g. Smith-Waterman Gap values) influences % Query Match value

26
Types of Nucleotide Sequence Searching
• Standard Search (cDNA)• Oligomer
– finds database hits with longest regions of matching residues
– mismatches not tolerated in region of hit match
• Length Limited Oligomer– returns database hits within requested length
range– mismatches not tolerated in region of hit match
• Score Over Length – finds mismatched sequence database hits based
on requested length and identity range

27
Why doesn’t a standard search of the cDNA provide an adequate search of fragments?
• Long length sequence hits with many matches and mismatches score higher and appear first on the hit list, compared to short sequences having high correspondence– lots of regional local similarity in a long sequence
scores higher than a 10-mer with 100% identity
• Consequence – small sequences, of 100% identity or less, are
buried tens of thousands of hits down the hit list– most small sequence hits effectively lost– especially for hits with <100% correspondence

28
Why doesn’t a standard search of the cDNA provide an adequate search of fragments?
• Fragments and types of sequence searches– Standard Search (cDNA): fragment hits
buried– oligomer: fragment hits buried– searching multiple fragments: millions of
hits and alignments to consider
• Each fragment of a specified sequence and length requires a separate search

29
Standard Oligomer Searching
• Won’t provide thorough search of fragments since longer hits score higher on hit table
• Smaller size hits lost, effectively not seen• Does not tolerate mismatches in region of
matches • Consequently inefficient means of finding
small sequences, and with <100% in correspondence
• Better suited to finding long sequences

30
Length Limited Oligomer Searching
• Sequence request needs to set size limit consistent with the size range being claimed
• Does not tolerate mismatches in region of matches
• Consequently inefficient means of finding small sequences with <100% in correspondence
• Better suited to finding small sequences with 100% correspondence

31
Score Over Length Searching
• Small oligos with <100% correspondence– within requested length and identity (>60%) range
• Manual manipulation of first 65,000 hits – necessitates 2+ additional hrs. of searcher’s time– does not include computer search time
• Calculation– Hit Score divided by Hit Length– for first 65,000 hits of table
• Hits then sorted by Score/Length value • First 65,000 hits likely to contain small length
sequence hits down to 60% identity

32
Searching Small Sequences: Example
Consider the following claim:
• An oligonucleotide consisting of 8 to 20 nucleotides which specifically hybridizes to a nucleic acid coding for mud loach growth hormone (Seq. Id. No. X).
• The specification teaches that oligonucleotides which specifically hybridize need not have 100% sequence correspondence.

33
Mud Loach Growth Hormone cDNA
• 670 nucleotides long• 630 nucleotides in the coding region• 210 amino acids

34
Standard Search GenBank Hit Table Against cDNA
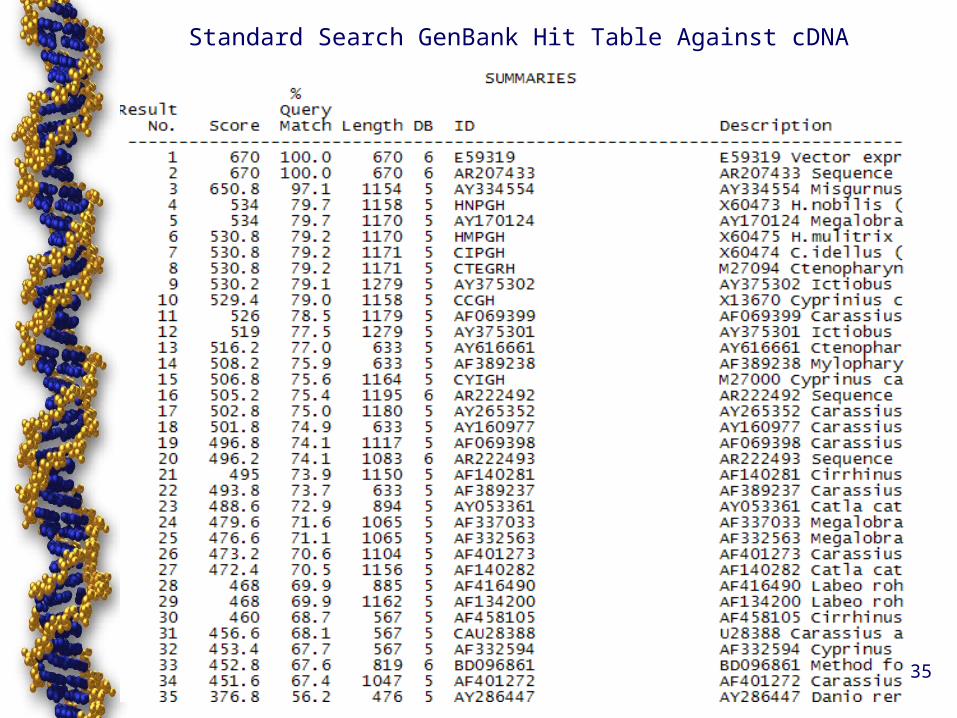
35
Standard Search GenBank Hit Table Against cDNA

36
Standard Search GenBank Alignments Against cDNA

37
Standard Search GenBank Alignments Against cDNA

38
Oligomer Search GenBank Hit Table Against cDNA
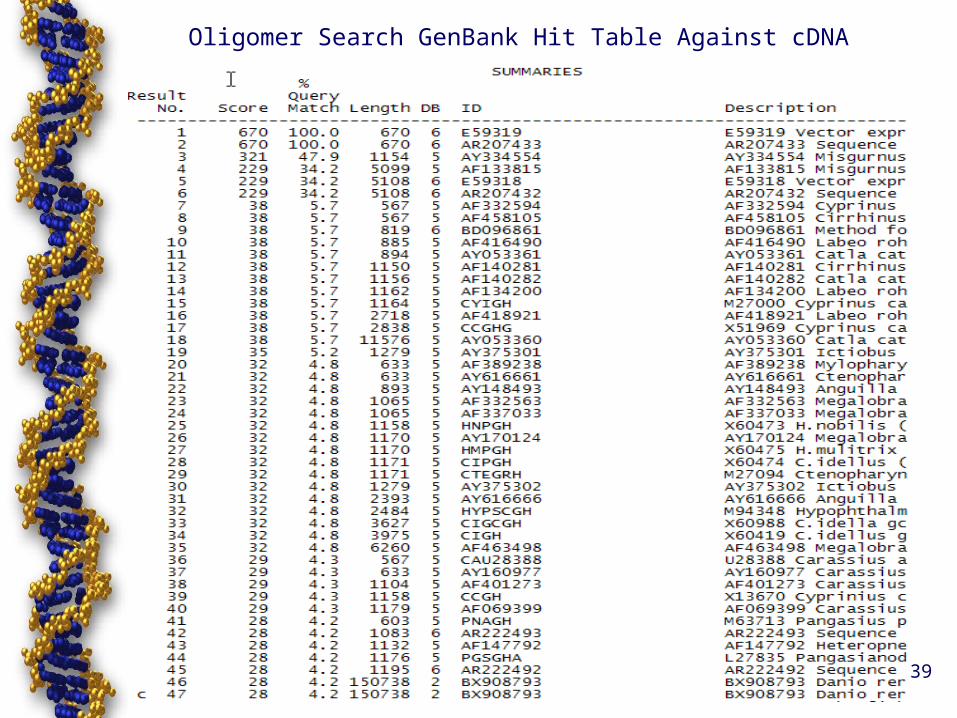
39
Oligomer Search GenBank Hit Table Against cDNA

40
Oligomer Search GenBank Alignments Against cDNA

41
Oligomer Search GenBank Alignments Against cDNA

42
Length-Limited (8 to 20) Oligomer Search GenBank Hit Table cDNA

43
Length-Limited (8 to 20) Oligomer Search GenBank Hit Table cDNA

44
Length-Limited (8 to 20) Oligomer Search GenBank Alignments cDNA

45
Score/Length GenBank Hit Table Against cDNA: 8-20-mers down to 80%

46
Score/Length GenBank Hit Table Against cDNA: 8-20-mers down to 80%

47
Score/Length Alignments Against cDNA: 8-20-mers down to 80%

48
Score/Length Alignments Against cDNA: 8-20-mers down to 80%

49
QUESTIONS?
Michael P. WoodwardSupervisory Patent Examiner - Art Unit 1631
571 272 [email protected]
John L. LeGuyaderSupervisory Patent Examiner - Art Unit 1635
571 272 [email protected]







