

1
Indrek Vainu & Hendrik Luuk
ML applied to text and image in chat bots

2
Transform customer service into a truly competitive advantage
Utilize AI to automate, personalizeand scale business processes

3
Chat bots are intelligent robots. They are able toinfer what you want.
As a result, they respond with appropriate actions. They operate autonomously i.e. without
human supervision.
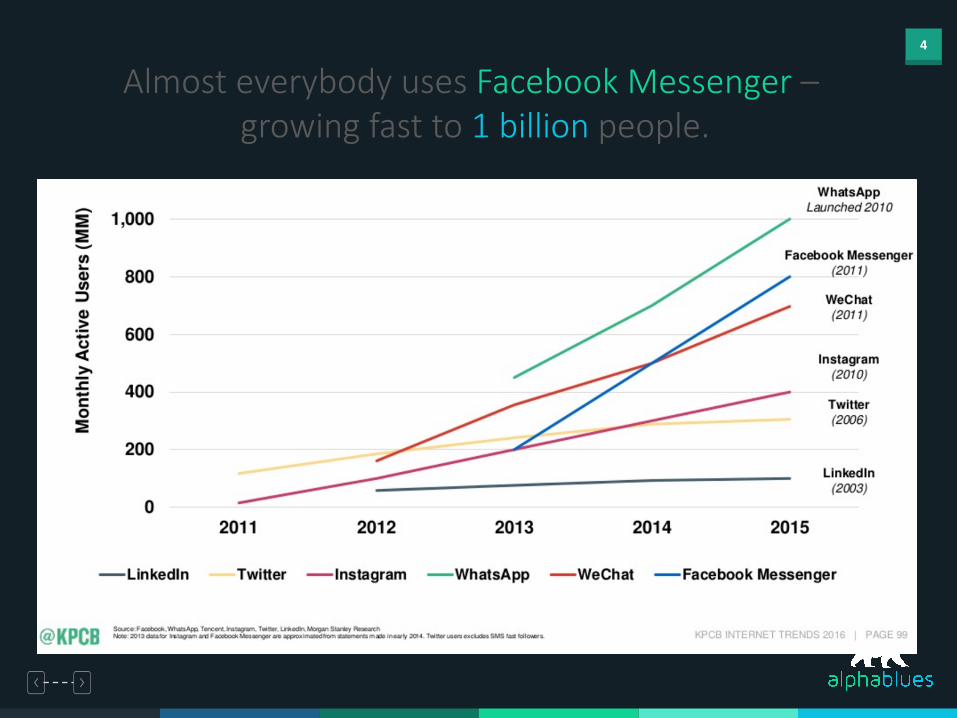
4
Almost everybody uses Facebook Messenger –growing fast to 1 billion people.
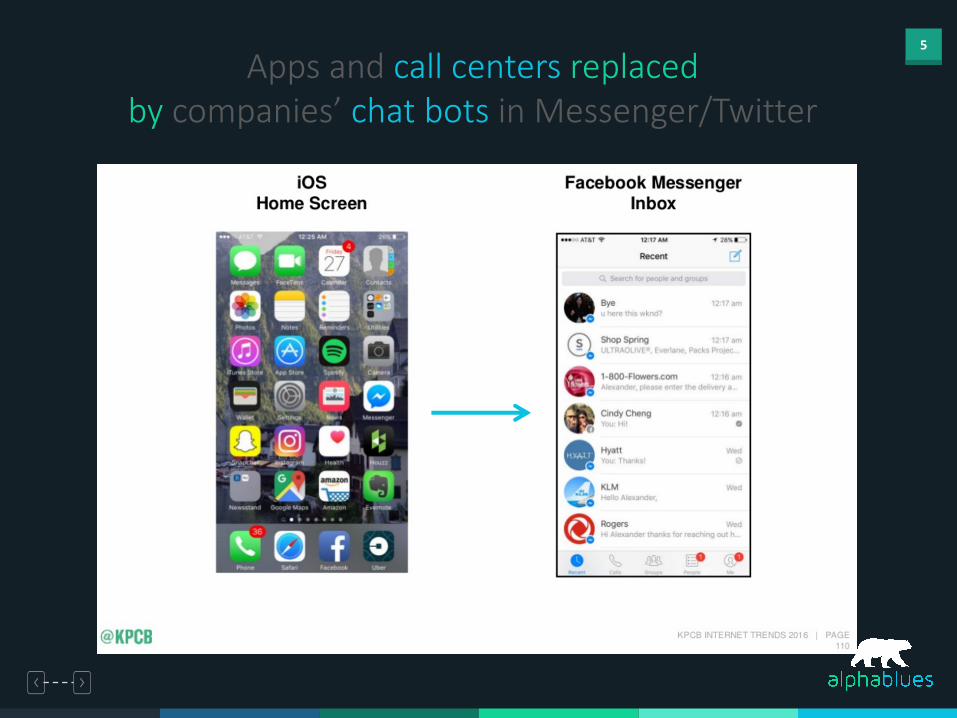
5
Apps and call centers replaced by companies’ chat bots in Messenger/Twitter
6

7
Short Bio
• >15y of programming, >10y research lab
• neuroscience PhD (2009, UT)
• Published papers in bioinformatics, neuroanatomy, general
linguistics
• full-stack engineer + data scientist
• ML expertise
• RoR, javascript, R, C++, python

8
Applications of ML
• Image similarity
• Video encoding and reconstruction
• Intent prediction from text
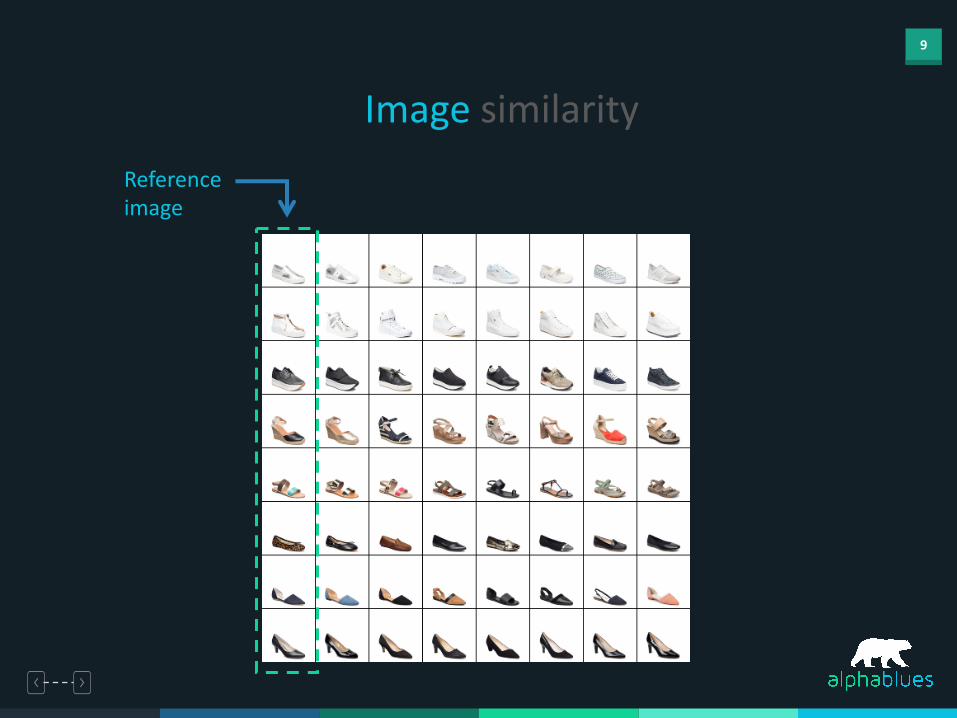
9
Image similarityReference image
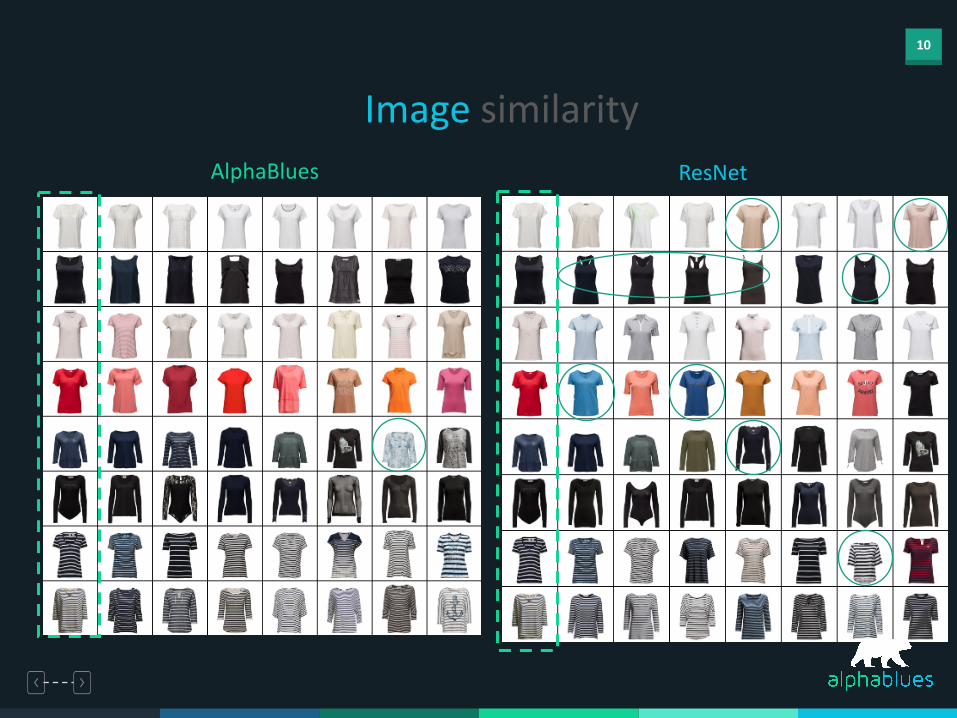
10
Image similarityAlphaBlues ResNet

11
Improved cost function for reconstruction
• Autoencoder (AE) combined with Generative Adversarial Net
(GAN) is good at forming latent representations for accurate
reconstruction of image content
Autoencoding beyond pixels using a learned similarity metrichttps://arxiv.org/pdf/1512.09300.pdf
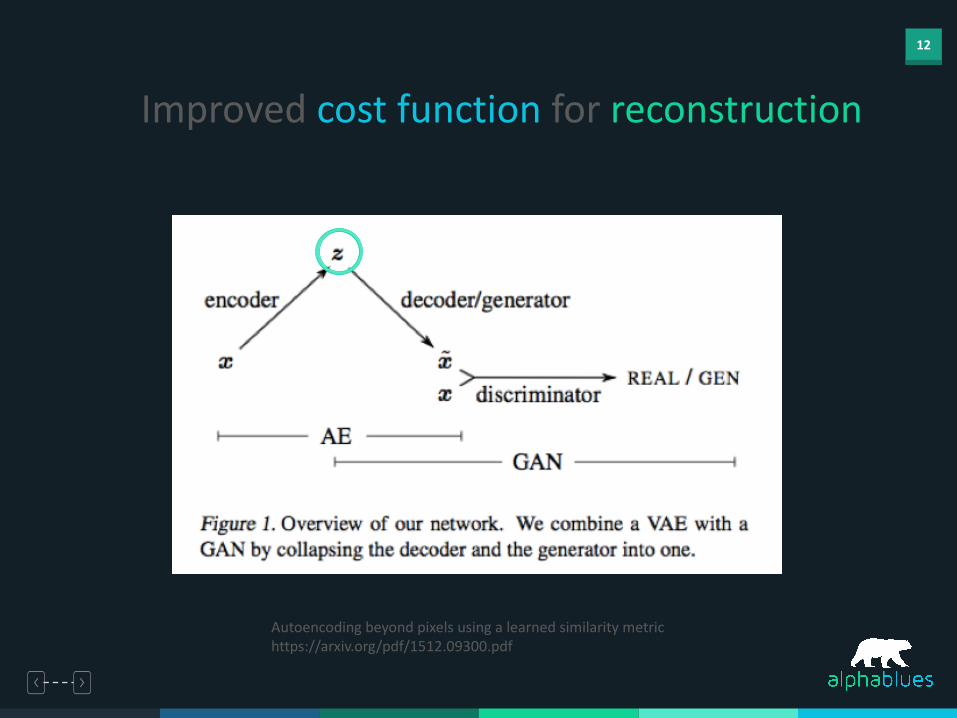
12
Improved cost function for reconstruction
Autoencoding beyond pixels using a learned similarity metrichttps://arxiv.org/pdf/1512.09300.pdf

13
Improved cost function for reconstruction
Autoencoding beyond pixels using a learned similarity metrichttps://arxiv.org/pdf/1512.09300.pdf

14
Improved cost function for reconstruction
Autoencoding beyond pixels using a learned similarity metrichttps://arxiv.org/pdf/1512.09300.pdf

15
Improved cost function for reconstruction
Autoencoding beyond pixels using a learned similarity metrichttps://arxiv.org/pdf/1512.09300.pdf

16
Improved cost function for reconstruction
Autoencoding beyond pixels using a learned similarity metrichttps://arxiv.org/pdf/1512.09300.pdf

17
Improved cost function for reconstruction
Autoencoding beyond pixels using a learned similarity metrichttps://arxiv.org/pdf/1512.09300.pdf
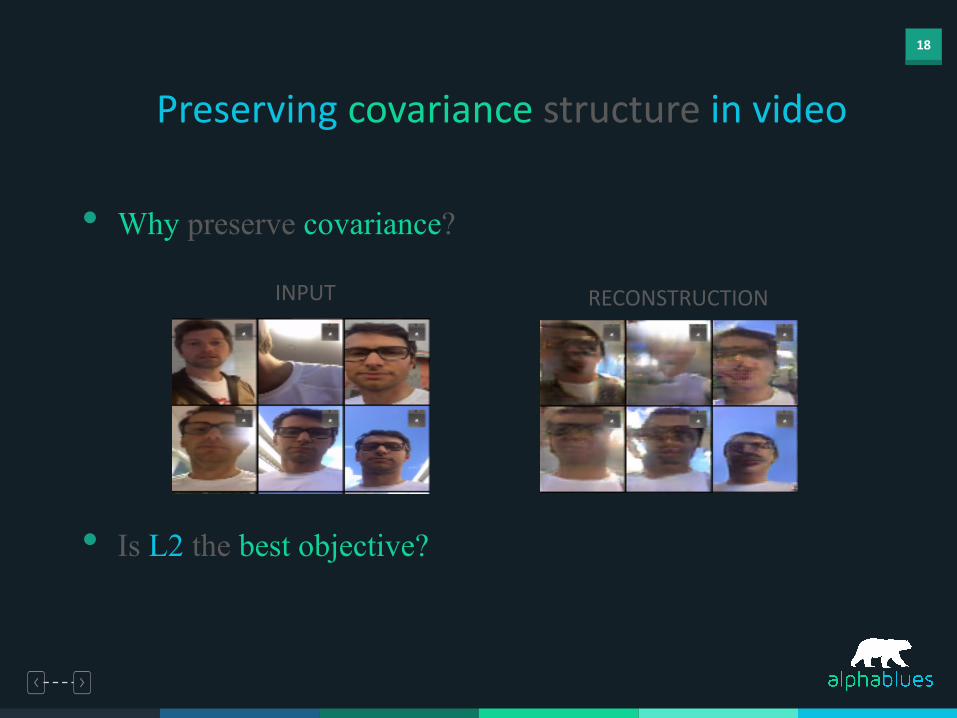
18
Preserving covariance structure in video
• Why preserve covariance?
• Is L2 the best objective?
INPUT RECONSTRUCTION

19
Preserving covariance structure
• L2-norm (Euclidean distance)
• Covariance-based alternative
L2 = sum((x-‐y)2)dL2x = 2 * (x-‐y)
CovCost = sum((x*xT – y*yT)2)dCovCostx = sum(4 * x * (x*xT – y*yT), 1)
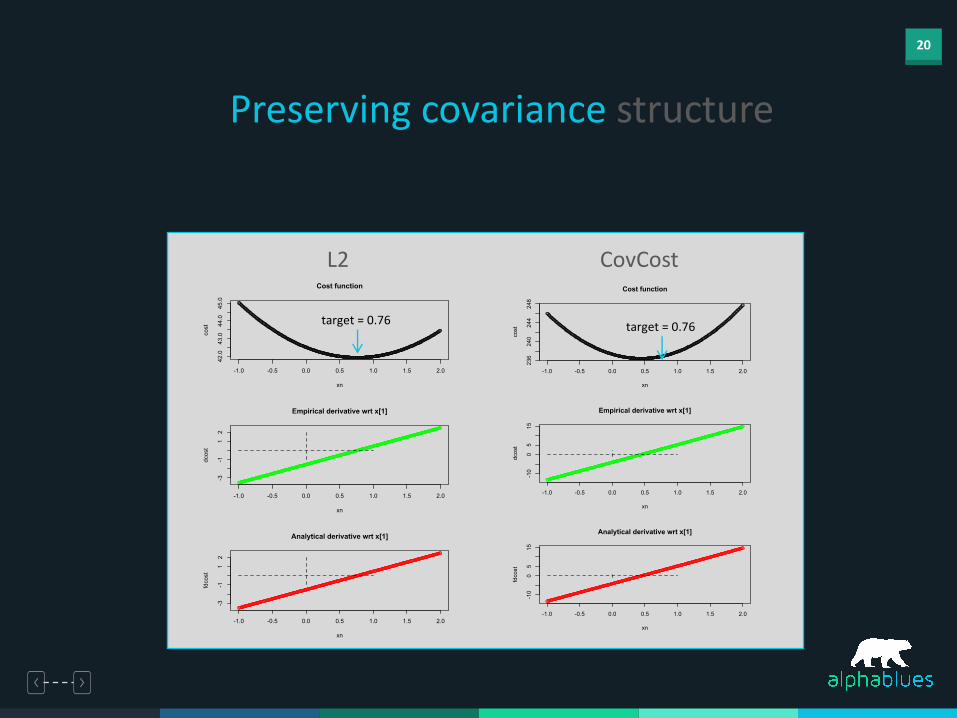
20
Preserving covariance structure
L2 CovCost
-1.0 -0.5 0.0 0.5 1.0 1.5 2.0
42.0
43.0
44.0
45.0
Cost function
xn
cost
-1.0 -0.5 0.0 0.5 1.0 1.5 2.0
-3-1
12
Empirical derivative wrt x[1]
xn
dcost
-1.0 -0.5 0.0 0.5 1.0 1.5 2.0
-3-1
12
Analytical derivative wrt x[1]
xn
fdcost
-1.0 -0.5 0.0 0.5 1.0 1.5 2.0
236
240
244
248
Cost function
xn
cost
-1.0 -0.5 0.0 0.5 1.0 1.5 2.0
-10
05
15
Empirical derivative wrt x[1]
xndcost
-1.0 -0.5 0.0 0.5 1.0 1.5 2.0
-10
05
15Analytical derivative wrt x[1]
xn
fdcost
target = 0.76 target = 0.76
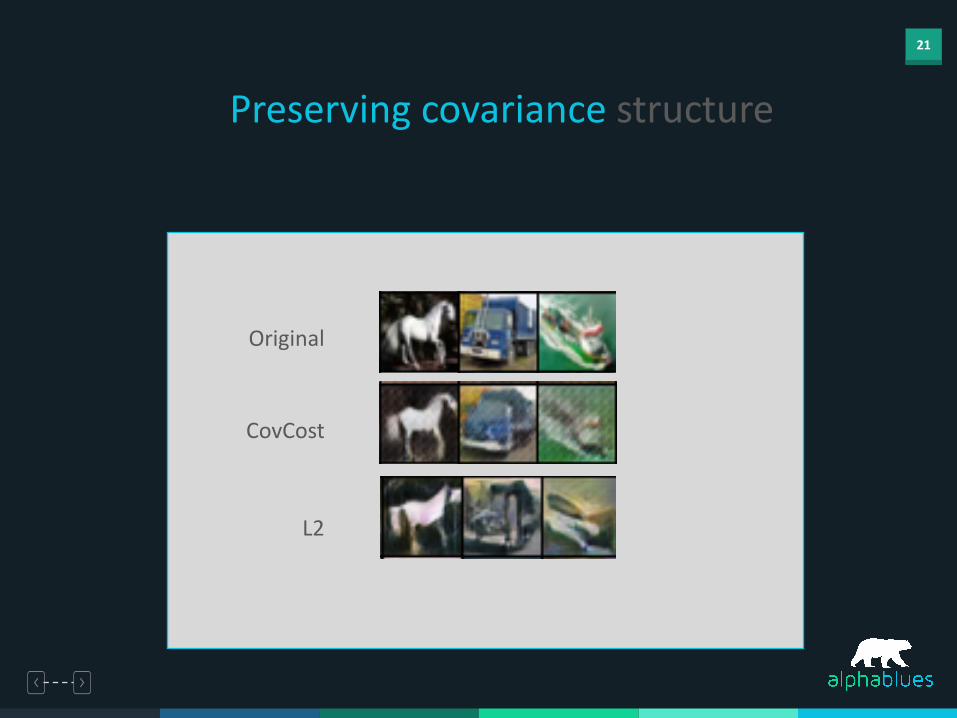
21
Preserving covariance structure
Original
CovCost
L2
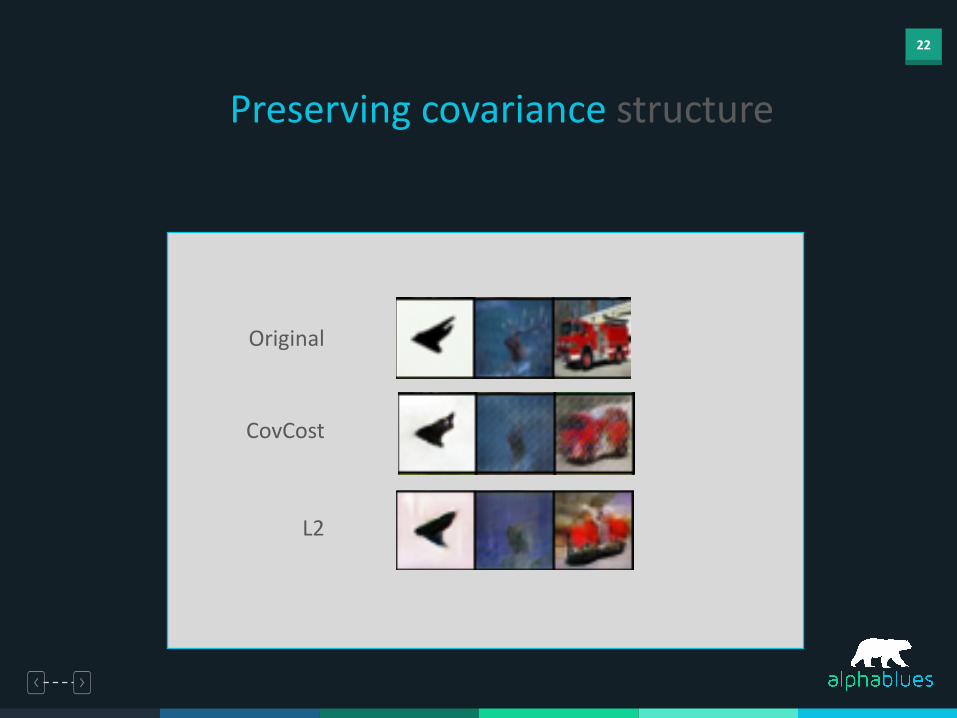
22
Preserving covariance structure
Original
CovCost
L2
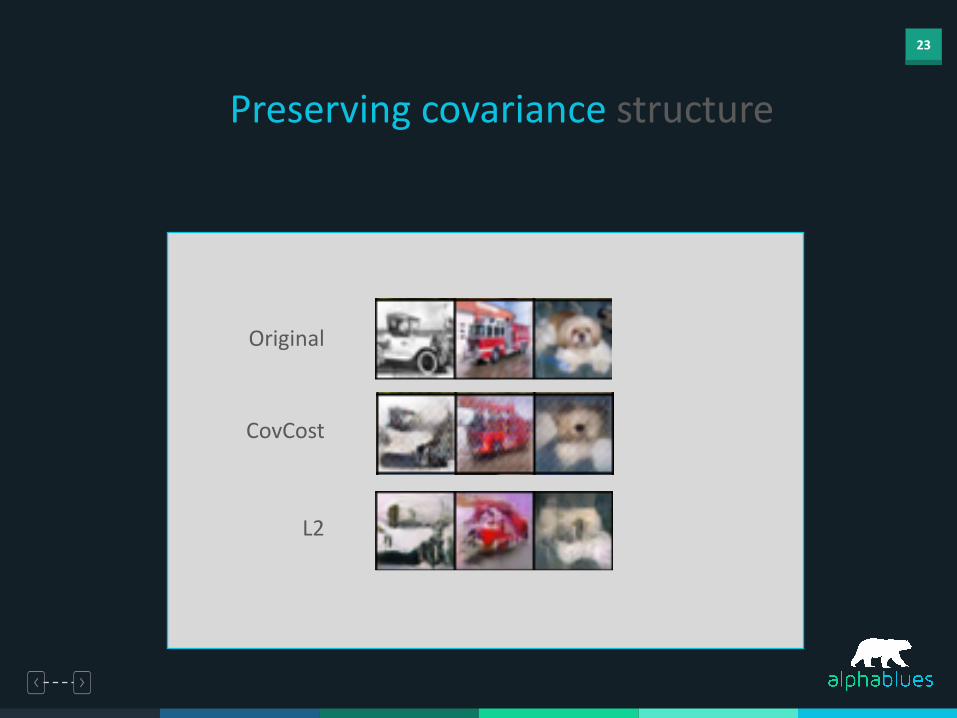
23
Preserving covariance structure
Original
CovCost
L2
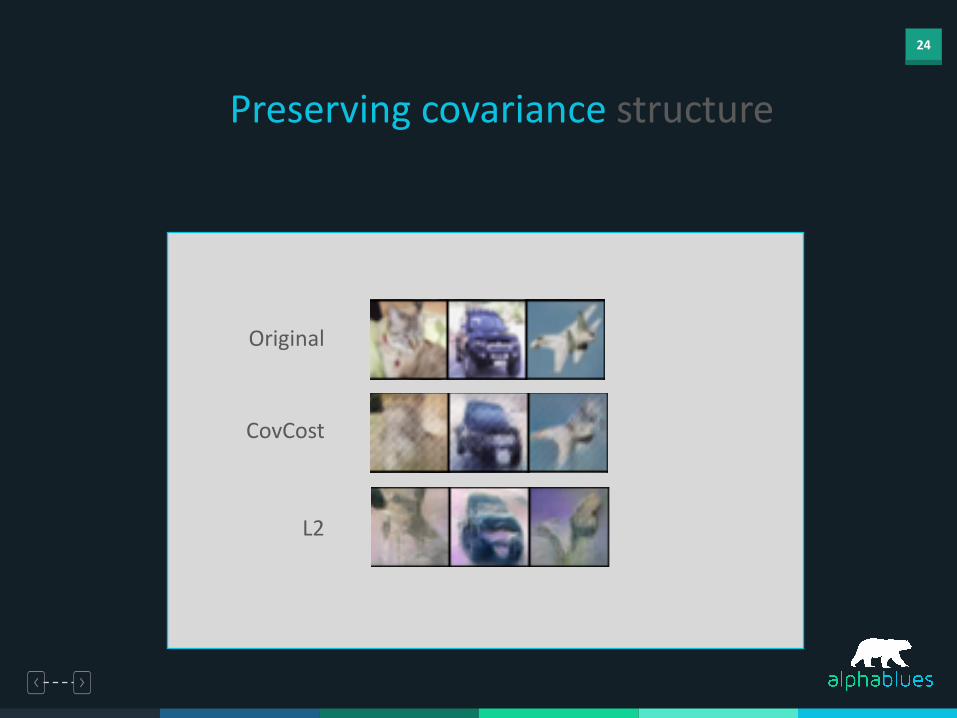
24
Preserving covariance structure
Original
CovCost
L2

25
Create your own objective function
• intuition à equation
• Minimize the difference between prediction and target
• L(f(X), Y) à real number
• X – input
• f(X) – output from the model
• Y – target
• L – objective function
26
Create your own objective function
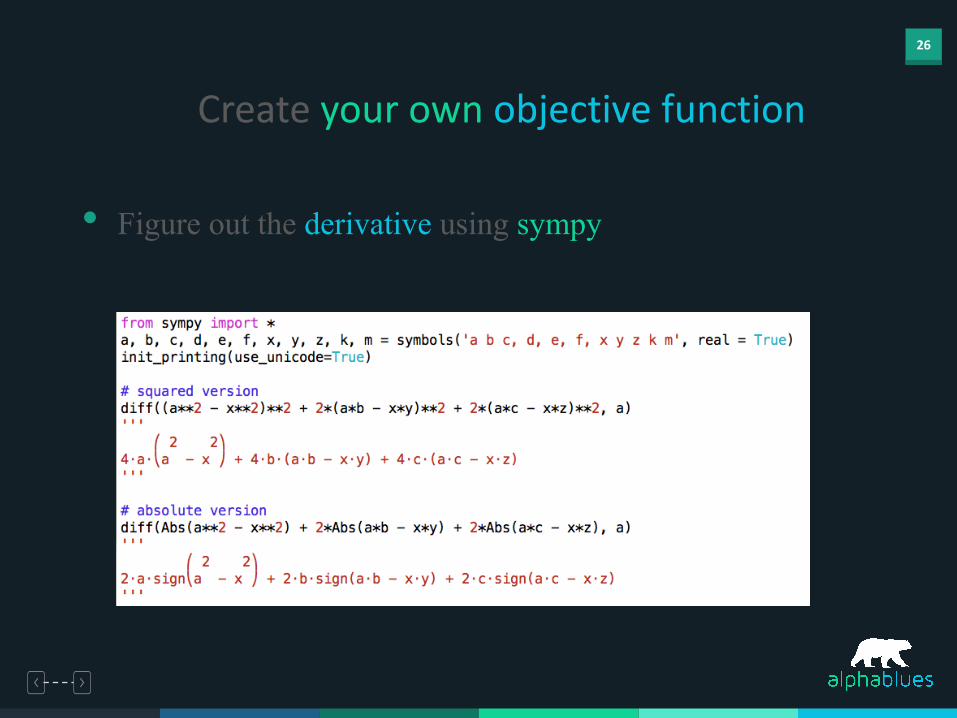
• Figure out the derivative using sympy
27
Create your own objective function
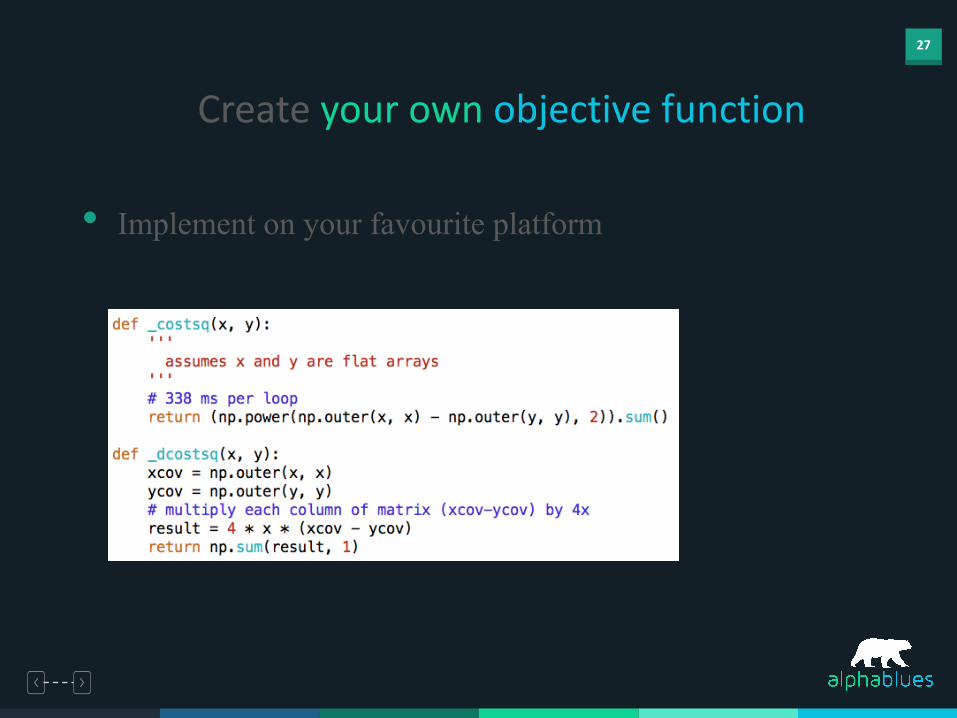
• Implement on your favourite platform
28
Create your own objective function
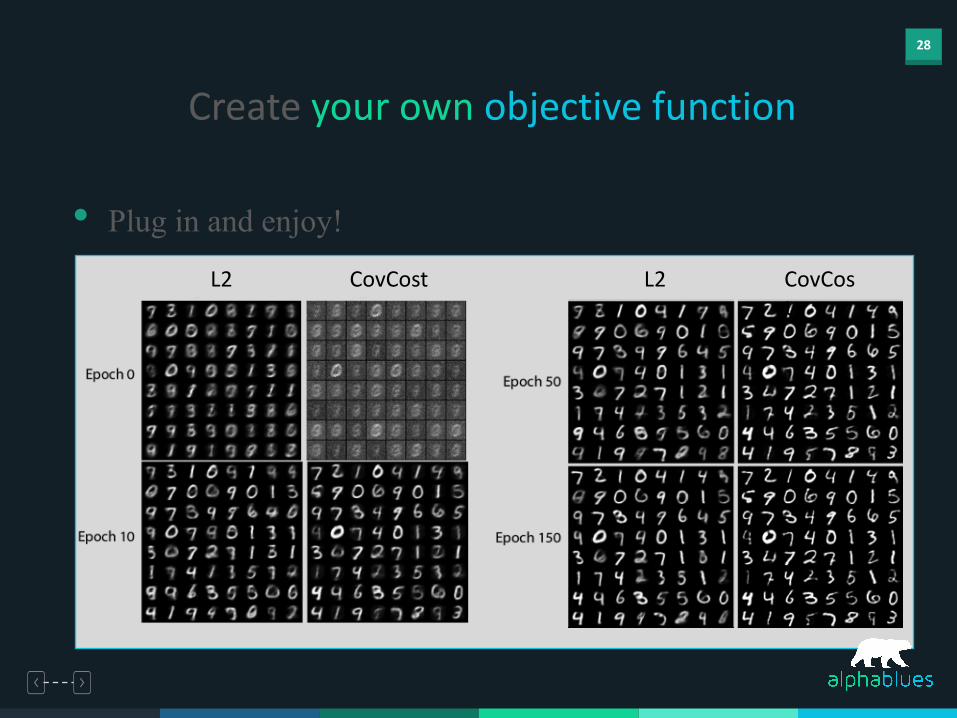
• Plug in and enjoy!
CovCost CovCost
L2 L2
29
Create your own objective function
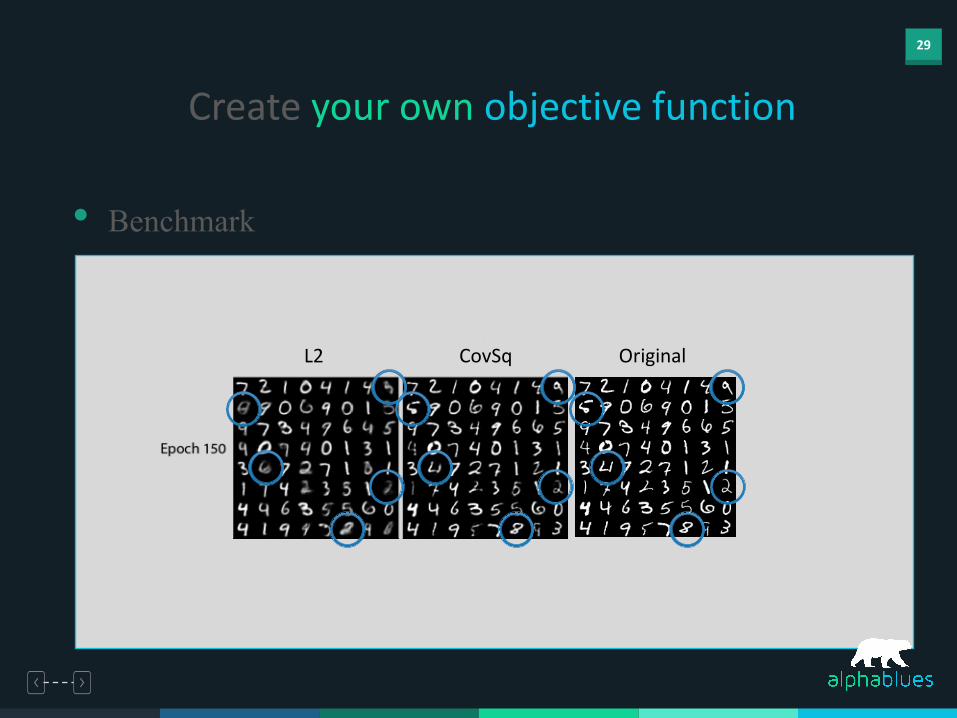
• Benchmark
CovSq OriginalL2

30
Create your own objective function
• Finally, optimize.
O(n2)
O(1002)
28x28 pixels 28x28 pixels
31
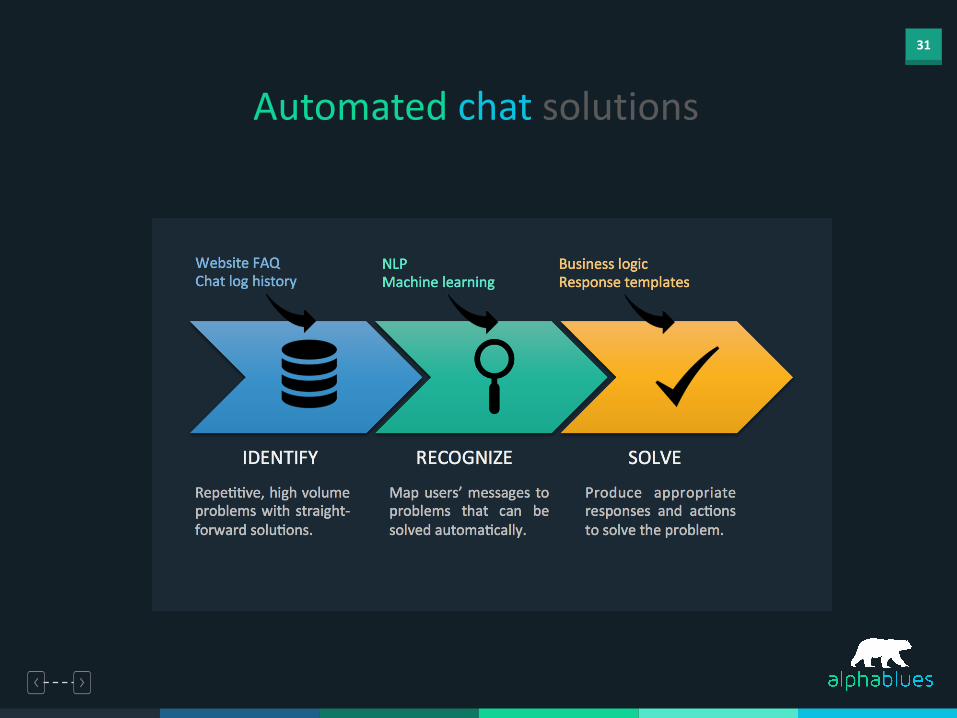
Automated chat solutions
32
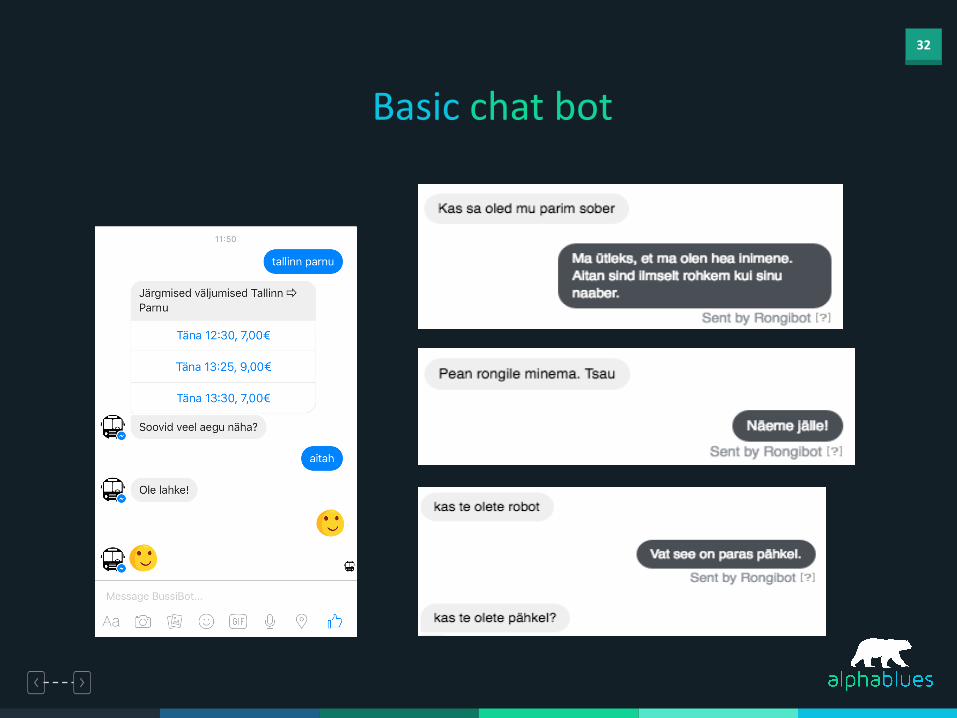
Basic chat bot
33
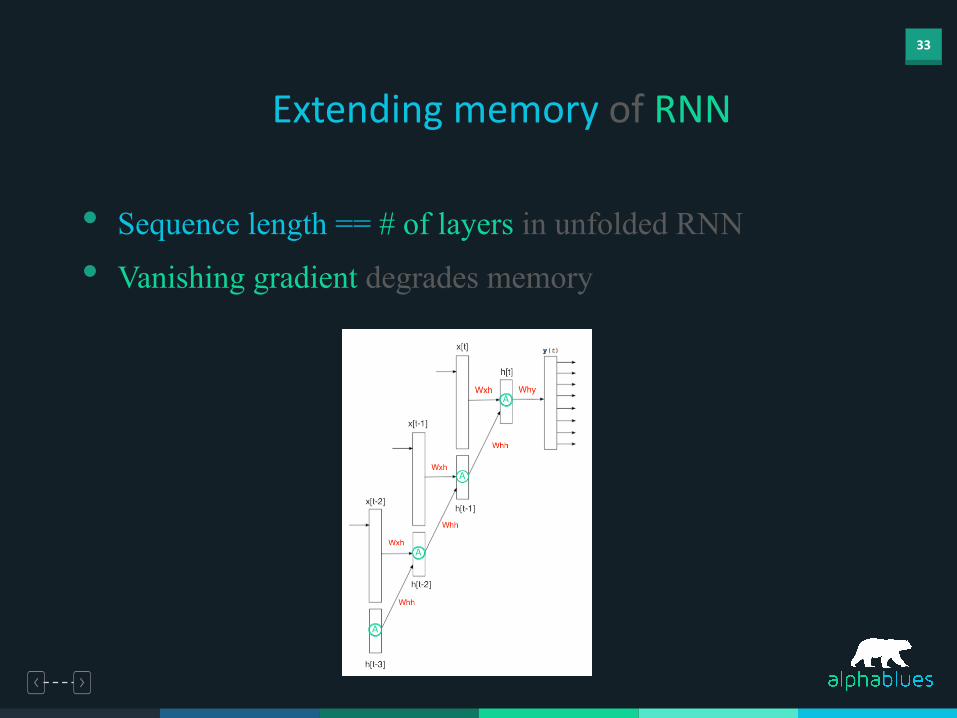
Extending memory of RNN
• Sequence length == # of layers in unfolded RNN
• Vanishing gradient degrades memory
A
A
A
A

34
Extending memory of RNN
• What is a good activation function?
• little saturation (mostly non-zero gradient)
• mean activation 0 (faster convergence)
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shifthttps://arxiv.org/pdf/1502.03167.pdf
FAST AND ACCURATE DEEP NETWORK LEARNING BY EXPONENTIAL LINEAR UNITS (ELUS) https://arxiv.org/pdf/1511.07289.pdf
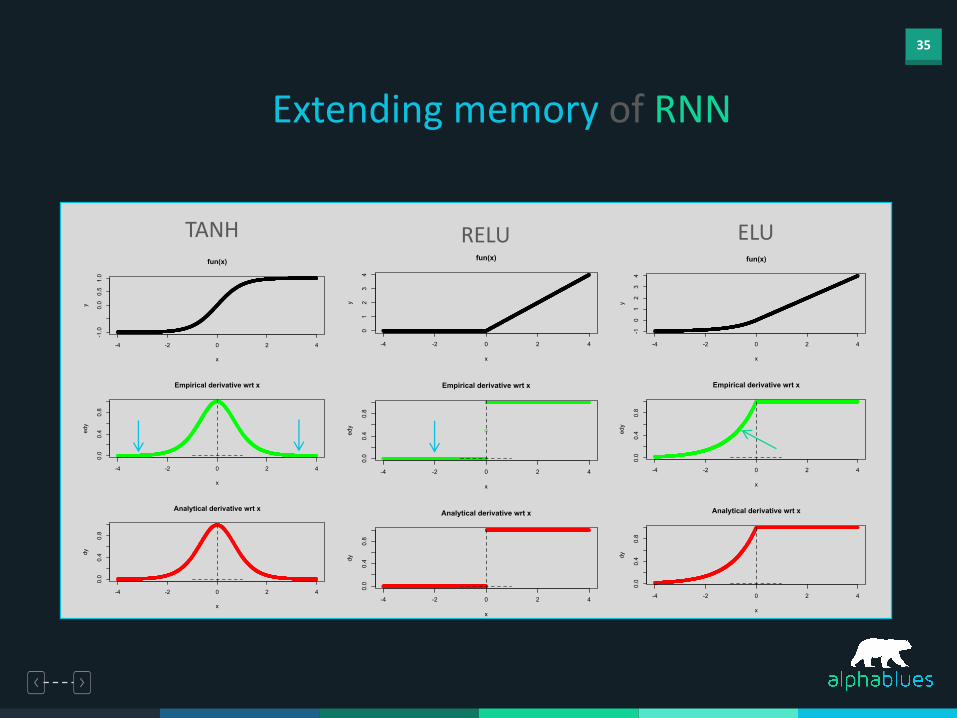
35
Extending memory of RNN
-4 -2 0 2 4
-1.0
0.00.51.0
fun(x)
x
y
-4 -2 0 2 4
0.0
0.4
0.8
Empirical derivative wrt x
x
edy
-4 -2 0 2 4
0.0
0.4
0.8
Analytical derivative wrt x
x
dy
TANH ELU
-4 -2 0 2 4
-10
12
34
fun(x)
x
y
-4 -2 0 2 4
0.0
0.4
0.8
Empirical derivative wrt x
x
edy
-4 -2 0 2 4
0.0
0.4
0.8
Analytical derivative wrt x
x
dy
-4 -2 0 2 4
01
23
4
fun(x)
xy
-4 -2 0 2 4
0.0
0.4
0.8
Empirical derivative wrt x
x
edy
-4 -2 0 2 4
0.0
0.4
0.8
Analytical derivative wrt x
x
dy
RELU
36
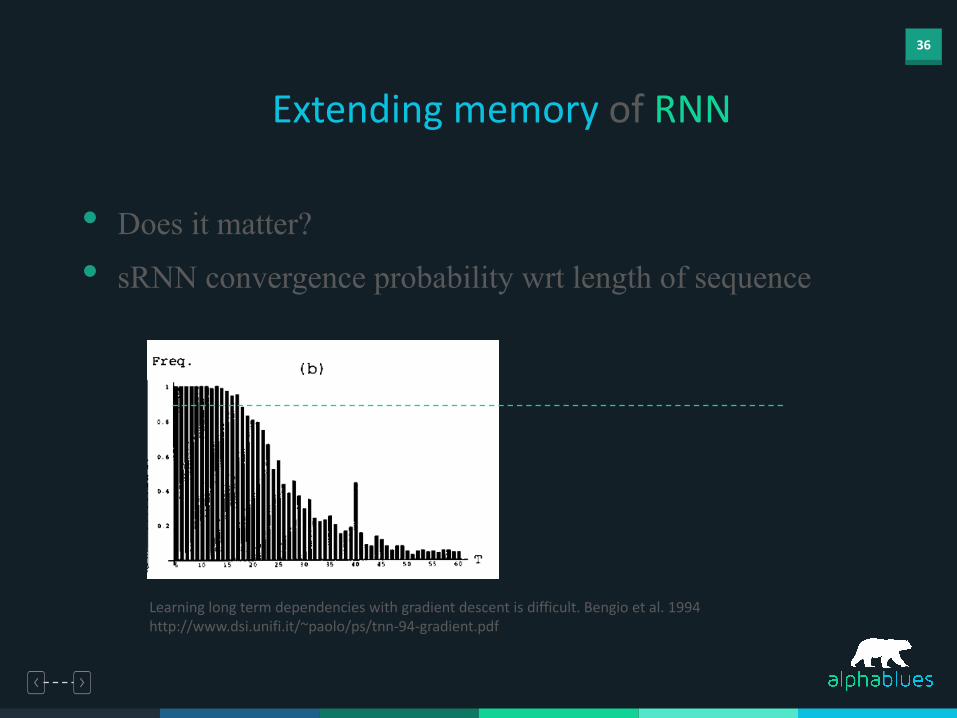
Extending memory of RNN
• Does it matter?
• sRNN convergence probability wrt length of sequence
Learning long term dependencies with gradient descent is difficult. Bengio et al. 1994http://www.dsi.unifi.it/~paolo/ps/tnn-‐94-‐gradient.pdf








