

Storytelling: BigQuery - past, present and future
Mobile Campaign Analytics | Retargeting | Unbiased Attribution
Nir Rubinstein - Chief Architect. [email protected]

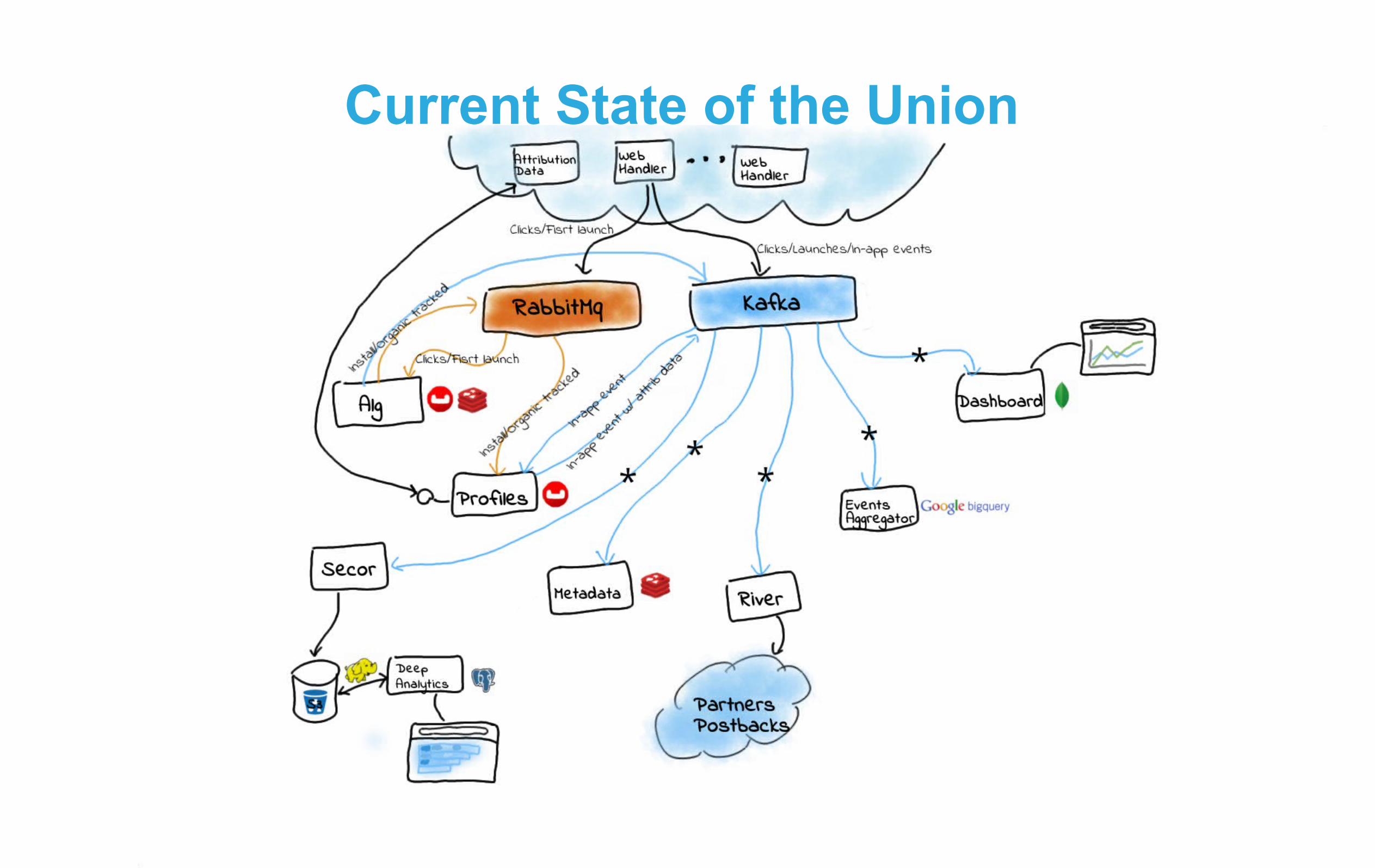
State of the union – 2012
Tech stack:
• Small, semi-isolated python services
• Communication via Redis' pub/sub
• Main DB is CouchDB
• Not a whole lot going on...

State of the union – 2012, cont'd
The problem:
• A really big raw(!) report is being served by CouchDB
• Data in CouchDB is being generated via a View
• The entire DB is on hold while a view is generated
• Pissed off client
What do we do???

The Quick Solution
Google Bigquery
• Hosted solution – we don't have to manage it
• Based on Google's BigTable whitepaper
• Columnar storage DB
• Really easy to start working with...

The Modeling Problem
Is there one?• Data in Bigquery is divided into:
● Projects● Datasets● Tables
How to split the data?Is performance constant?
How am I charged?

The Modeling Problem
The naive approach:
One Project
One Dataset
Multiple Tables
Hundred of thousands of rows a month

The Modeling Problem

The Modeling Problem
What are the limitations?
• Cannot change the schema of a table once created
• Cannot update table data
• Cannot delete table data
Essentially – forward writing only!

The Modeling Problem
How we tackled these “issues”?
• One global “Project” that drives our Raw Reports
• New Datasets are created every 30 days - business and cost limitations
• Tables in the datasets are versioned!
Current State of the Union

The Cost Problem
Is there a problem?
• Storage is very cheap, querying is expansive
• Querying is billed by the amount of data scanned. Bigquery is a columnar DB which means that every column that participates in the query is read from beginning to end
• Once tables start storing a lot of data, even simple queries with very few columns will be expensive

Cost Optimizations
• We're processing 8B daily events. Out of those, a few hundred millions are written into Bigquery – only meaningful data.
• We've created a unified schema to prevent table version issues
• Tables can be query optimized via Table Decorators to limit the time range of queried data
• Tables will be named with dates in them in order to support Table Wildcard queries in order to reduce the cost

The “Cost” of Cost Optimizations
• Performance (querying multiple tables)
• Over engineering (inserting to and maintaining multiple tables)
• Storage is cheap, but querying is costly. Since querying does a full column scan, there's a debate whether we should store the entire data or parts of it.

The Future
What are we waiting for?
Custom partitioning functions!!!

Thank You!(We're hiring)






