

BulStem: Design and Evaluation of Inflectional Stemmer for Bulgarian
Preslav [email protected]
EECS, University of California at Berkeley
Presented by:
Svetlin Nakov, [email protected], Sofia University

Stemming overview
Purpose: normalise the word variants by converting them to a corresponding stem
Usually limited to suffix stripping only does not cope with prefixes address both inflectional and derivational morphology
Proved beneficial for: Information retrieval (30-40%, Krovetz; 1-3%, Hull) French, Dutch, Latin, Slovene, Russian, Ukrainian etc.
Snowball project (run by Porter) C and Java implementations of Porter-like algorithms languages: English, French, Spanish, Portuguese, Italian,
German, Dutch, Swedish, Norwegian, Danish, Russian and Finnish.

Related work A very simple stemmer:
1) “-ies” → “-y” (not applied, if “-eies” or “-aies”)
2) “-es” → “-e” (not applied, if “-aes”, “-ees” or “-oes”)
3) “-s” → “-” (not applied, if “-ss” or “-us”)
Types of algorithms: Rule-based
Dawson - 1,200 rules, Lovins – 294, Paice/Husk – 115, Porter – 60.
N-gram – no stem is produced Successor variety – corpus-based approach – observes distinct
letters following a particular prefix Dictionary lookup –finds directly the stem

Related work (cont.)
More sophisticated algorithms: KSTEM – Krovetz
Combines a set of rules and dictionary lookup
Xu & Croft – corpus-based approach
Slavonic languages: Highly inflectional Stemming is not easier than full morphological analysis
Russian stemmers Porter adapted to Russian, Snowball project Stemka:
For Russian Later adapted for Ukrainian

Stemka
Machine-learning approach Training is performed on a large text that is
morphologically analysed A set of rules are extracted:
A suffix to remove given a 2-letter left context
The least frequent rules are discarded Extracted rules are applied for stemming the target text
If several rules apply to a word, all possible stems are returned, e.g.
начина|ющ|ий|ся

BulStem: Bulgarian stemmer
Addressed as a machine-learning task
Uses large morphological dictionary of Bulgarian Created at the Linguistic Modeling Laboratory, CLPOI-BAS (for
contacts: Elena Paskaleva) Rich in morphological information Contains 889,665 word forms (59,670 lemmas) Encoded in DELAF format Each line contains a word form, the corresponding lemma and
some morphological information
отбран,отбера.Г+С+Т:Psотбран,отбран.ПРИ:sотбрана,отбера.Г+С+Т:Psfотбрана,отбран.ПРИ:sfотбрана,отбрана.С+Ж:sотбраната,отбера.Г+С+Т:Psfdотбраната,отбран.ПРИ:sfdотбраната,отбрана.С+Ж:sd

BulStem: The purpose
Assign the same stem to all inflected forms for a given combination of lemma and its POS.
For the previous example: we want the following groups (Г: verb select, ПРИ: adj. selected, С: noun defense):
1. отбера.Г+С+Т: отбера отберат отбере отберели отберем отберете отбереш отбереше отбери отберял отберяла отберяло отберях отберяха отберяхме отберяхте отбра отбрал отбрала отбралата отбрали отбралите отбралия отбралият отбрало отбралото отбран отбрана отбраната отбрани отбраните отбрания отбраният отбрано отбраното отбрах отбраха отбрахме отбрахте
2. отбран.ПРИ: отбран отбрана отбраната отбрани отбраните отбрания отбраният отбрано отбраното
3. отбрана.С+Ж: отбрана отбраната отбрани отбраните отбрано

TrainingFind stem for each group: e.g. отб, отбран and отбран
Contextual rule for each inflected form
Go through the dictionary and find removal rules & frequency
Drop the most infrequent ones
Build a removal rules (e.g. -раният changes to -ран)
вания ==> ван 2587ване ==> ван 2548ванията ==> ван 2524ването ==> ван 2524остите ==> ост 2259ости ==> ост 2259ост ==> ост 2247остта ==> ост 2238ява ==> ява 1632яваше ==> ява 1631
Stemming is done by applying the longest compatible rule that would produce a stem with at least one vowel

Example
Example text (from www.mediapool.bg):
Има първи вероятен случай на атипична пневмония в България, съобщи министърът на здравеопазването Божидар Финков. Става дума за 33 годишен пациент, който на 16 април е пристигнал в България след продължителен престой в Торонто, Канада, където вече са регистрирани 19 смъртни случая вследствие на тежкия остър респираторен синдром (ТОРС). Точната диагнозата обаче не може да бъде установена в България и пробите ще бъдат изпратени за изследване в Световната здравна организация (СЗО).
After stemming (left context 3, min rule frequency 2):
има първ вероят случа на атипич пневмони в българи, съобщ минист на здравеопазван божидар финков. став дум за 33 годиш пациент, който на 16 април е пристигн в българи след продължител престо в торонт, канад, където вече са регистрира 19 смърт случа вследстви на теж ост респиратор синдром (торс). точ диагноз обаче не може да бъде установ в българи и проб ще бъдат изпрат за изследван в светов здрав организаци (сзо).

BulStem: Evaluation of Dictionary Accuracy
By increasing the context size we obtain better precision but lower coverage
The minimum frequency parameter can vary for different context size
COVERAGE ERROR context size
min frequency
rules count dictionary raw text
UNDER stemming
OVER stemming
“Overall”
1 1 6693 98.13% 72.18% 11.95% 27.86% 39.81% 1 2 5033 98.13% 72.16% 16.37% 24.11% 40.48% 1 5 3966 98.13% 72.16% 16.17% 23.47% 39.64% 1 10 3095 98.13% 72.16% 15.28% 20.74% 36.02% 1 20 2238 98.11% 70.86% 13.41% 20.13% 33.54% 2 1 30755 97.62% 62.14% 9.09% 18.57% 27.66% 2 2 22199 97.58% 61.89% 9.00% 17.93% 26.93% 2 5 14455 97.27% 60.70% 9.27% 16.71% 25.98% 2 10 9528 96.48% 57.93% 10.40% 15.36% 25.76% 3 1 93066 94.65% 43.76% 9.66% 12.92% 22.58% 3 2 56797 93.25% 40.85% 10.89% 10.28% 21.17% 3 5 26890 88.82% 35.58% 15.31% 8.15% 23.46%

Category Size %Agriculture& Forestry 12 9.45%Culture 33 25.98%Defence 15 11.81%Sport 67 52.76%TOTAL 127 100.00%
We used the k-nearest-neighbour classifier (kNN)
We used LSA to calculate the proximity between texts
Collection of 127 news articles from Bulgarian on-line sources:
BulStem: Evaluation of Text Categorisation Accuracy
BulStem: Evaluation of Text Categorisation Accuracy (cont.)
LWF GWFLSAdim.
STOP-WORDS KEPT STOP-WORDS REMOVED
raw stem 2:1 stem 3:1 lemma raw stem 2:1 stem 3:1 lemma
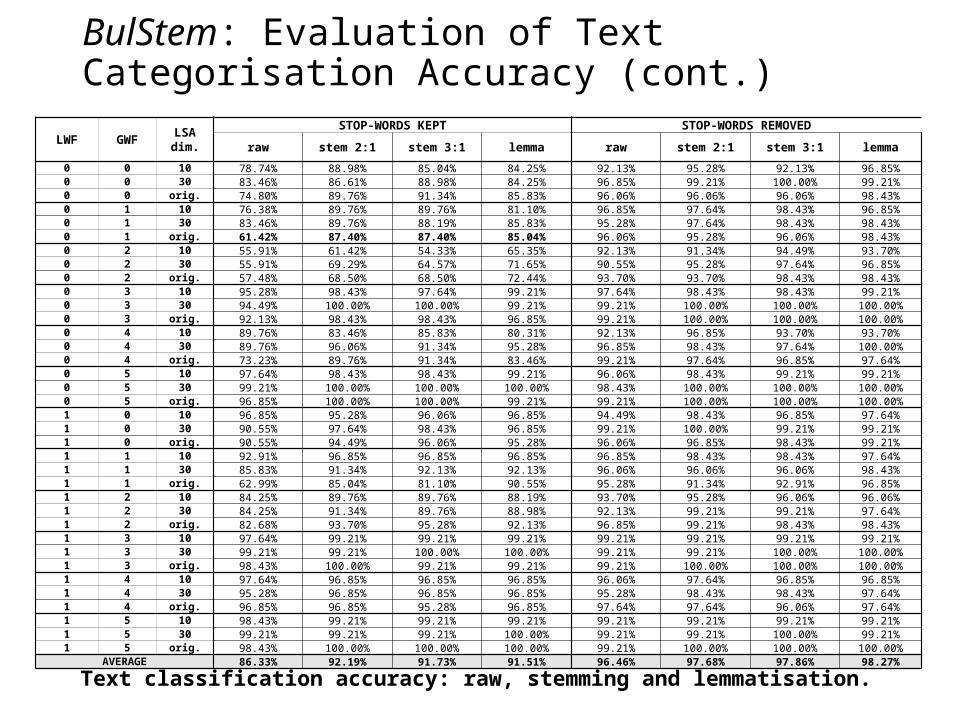
0 0 10 78.74% 88.98% 85.04% 84.25% 92.13% 95.28% 92.13% 96.85%0 0 30 83.46% 86.61% 88.98% 84.25% 96.85% 99.21% 100.00% 99.21%0 0 orig. 74.80% 89.76% 91.34% 85.83% 96.06% 96.06% 96.06% 98.43%0 1 10 76.38% 89.76% 89.76% 81.10% 96.85% 97.64% 98.43% 96.85%0 1 30 83.46% 89.76% 88.19% 85.83% 95.28% 97.64% 98.43% 98.43%0 1 orig. 61.42% 87.40% 87.40% 85.04% 96.06% 95.28% 96.06% 98.43%0 2 10 55.91% 61.42% 54.33% 65.35% 92.13% 91.34% 94.49% 93.70%0 2 30 55.91% 69.29% 64.57% 71.65% 90.55% 95.28% 97.64% 96.85%0 2 orig. 57.48% 68.50% 68.50% 72.44% 93.70% 93.70% 98.43% 98.43%0 3 10 95.28% 98.43% 97.64% 99.21% 97.64% 98.43% 98.43% 99.21%0 3 30 94.49% 100.00% 100.00% 99.21% 99.21% 100.00% 100.00% 100.00%0 3 orig. 92.13% 98.43% 98.43% 96.85% 99.21% 100.00% 100.00% 100.00%0 4 10 89.76% 83.46% 85.83% 80.31% 92.13% 96.85% 93.70% 93.70%0 4 30 89.76% 96.06% 91.34% 95.28% 96.85% 98.43% 97.64% 100.00%0 4 orig. 73.23% 89.76% 91.34% 83.46% 99.21% 97.64% 96.85% 97.64%0 5 10 97.64% 98.43% 98.43% 99.21% 96.06% 98.43% 99.21% 99.21%0 5 30 99.21% 100.00% 100.00% 100.00% 98.43% 100.00% 100.00% 100.00%0 5 orig. 96.85% 100.00% 100.00% 99.21% 99.21% 100.00% 100.00% 100.00%1 0 10 96.85% 95.28% 96.06% 96.85% 94.49% 98.43% 96.85% 97.64%1 0 30 90.55% 97.64% 98.43% 96.85% 99.21% 100.00% 99.21% 99.21%1 0 orig. 90.55% 94.49% 96.06% 95.28% 96.06% 96.85% 98.43% 99.21%1 1 10 92.91% 96.85% 96.85% 96.85% 96.85% 98.43% 98.43% 97.64%1 1 30 85.83% 91.34% 92.13% 92.13% 96.06% 96.06% 96.06% 98.43%1 1 orig. 62.99% 85.04% 81.10% 90.55% 95.28% 91.34% 92.91% 96.85%1 2 10 84.25% 89.76% 89.76% 88.19% 93.70% 95.28% 96.06% 96.06%1 2 30 84.25% 91.34% 89.76% 88.98% 92.13% 99.21% 99.21% 97.64%1 2 orig. 82.68% 93.70% 95.28% 92.13% 96.85% 99.21% 98.43% 98.43%1 3 10 97.64% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21%1 3 30 99.21% 99.21% 100.00% 100.00% 99.21% 99.21% 100.00% 100.00%1 3 orig. 98.43% 100.00% 99.21% 99.21% 99.21% 100.00% 100.00% 100.00%1 4 10 97.64% 96.85% 96.85% 96.85% 96.06% 97.64% 96.85% 96.85%1 4 30 95.28% 96.85% 96.85% 96.85% 95.28% 98.43% 98.43% 97.64%1 4 orig. 96.85% 96.85% 95.28% 96.85% 97.64% 97.64% 96.06% 97.64%1 5 10 98.43% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21%1 5 30 99.21% 99.21% 99.21% 100.00% 99.21% 99.21% 100.00% 99.21%1 5 orig. 98.43% 100.00% 100.00% 100.00% 99.21% 100.00% 100.00% 100.00%
AVERAGE 86.33% 92.19% 91.73% 91.51% 96.46% 97.68% 97.86% 98.27%
Text classification accuracy: raw, stemming and lemmatisation.

BulStem: Evaluation of Text Categorisation Accuracy (cont.)
Text classification: stemming parameters evaluation (no stop-words)
LWF GWF SVD 1:1 1:2 1:5 1:10 1:20 2:1 2:2 2:5 2:10 3:1 3:2 3:30 0 10 96.85% 92.91% 92.91% 95.28% 93.70% 88.98% 93.70% 92.91% 92.91% 85.04% 92.91% 92.91%0 0 30 99.21% 99.21% 98.43% 98.43% 99.21% 86.61% 93.70% 99.21% 99.21% 88.98% 100.00% 99.21%0 0 orig. 96.06% 94.49% 95.28% 96.06% 96.06% 89.76% 85.83% 97.64% 98.43% 91.34% 95.28% 95.28%0 1 10 98.43% 98.43% 98.43% 98.43% 98.43% 89.76% 94.49% 99.21% 98.43% 89.76% 97.64% 97.64%0 1 30 96.85% 95.28% 96.06% 97.64% 97.64% 89.76% 94.49% 97.64% 97.64% 88.19% 96.85% 97.64%0 1 orig. 93.70% 92.91% 94.49% 96.06% 96.06% 87.40% 81.10% 97.64% 98.43% 87.40% 96.06% 95.28%0 2 10 92.13% 92.91% 95.28% 93.70% 94.49% 61.42% 71.65% 94.49% 92.13% 54.33% 93.70% 93.70%0 2 30 88.98% 97.64% 96.85% 96.85% 97.64% 69.29% 81.89% 98.43% 97.64% 64.57% 98.43% 98.43%0 2 orig. 90.55% 91.34% 94.49% 96.06% 98.43% 68.50% 74.80% 99.21% 96.85% 68.50% 98.43% 96.85%0 3 10 98.43% 98.43% 98.43% 98.43% 98.43% 98.43% 98.43% 98.43% 98.43% 97.64% 98.43% 98.43%0 3 30 100.00% 100.00% 99.21% 100.00% 100.00% 100.00% 100.00% 99.21% 100.00% 100.00% 100.00% 100.00%0 3 orig. 100.00% 100.00% 100.00% 100.00% 100.00% 98.43% 99.21% 100.00% 100.00% 98.43% 100.00% 100.00%0 4 10 92.91% 96.06% 96.06% 96.85% 92.91% 83.46% 94.49% 95.28% 94.49% 85.83% 92.13% 92.91%0 4 30 98.43% 98.43% 98.43% 98.43% 98.43% 96.06% 97.64% 97.64% 96.85% 91.34% 99.21% 98.43%0 4 orig. 96.85% 96.85% 96.85% 98.43% 98.43% 89.76% 91.34% 97.64% 96.85% 91.34% 97.64% 97.64%0 5 10 99.21% 98.43% 99.21% 99.21% 99.21% 98.43% 98.43% 97.64% 98.43% 98.43% 98.43% 98.43%0 5 30 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 99.21% 100.00% 100.00% 100.00% 100.00%0 5 orig. 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00%1 0 10 97.64% 97.64% 97.64% 97.64% 97.64% 95.28% 96.06% 97.64% 98.43% 96.06% 97.64% 96.06%1 0 30 98.43% 99.21% 99.21% 100.00% 100.00% 97.64% 97.64% 98.43% 98.43% 98.43% 98.43% 98.43%1 0 orig. 97.64% 96.85% 97.64% 96.85% 97.64% 94.49% 98.43% 96.85% 97.64% 96.06% 96.85% 96.06%1 1 10 97.64% 98.43% 98.43% 98.43% 98.43% 96.85% 97.64% 97.64% 97.64% 96.85% 98.43% 98.43%1 1 30 96.06% 95.28% 96.06% 96.06% 96.06% 91.34% 94.49% 96.06% 94.49% 92.13% 96.06% 96.85%1 1 orig. 92.91% 90.55% 92.13% 91.34% 91.34% 85.04% 92.91% 90.55% 90.55% 81.10% 89.76% 89.76%1 2 10 96.06% 95.28% 95.28% 96.06% 95.28% 89.76% 93.70% 96.06% 95.28% 89.76% 96.06% 94.49%1 2 30 97.64% 99.21% 100.00% 99.21% 100.00% 91.34% 95.28% 100.00% 100.00% 89.76% 100.00% 100.00%1 2 orig. 99.21% 97.64% 99.21% 97.64% 98.43% 93.70% 89.76% 99.21% 99.21% 95.28% 99.21% 99.21%1 3 10 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 98.43%1 3 30 99.21% 99.21% 99.21% 99.21% 100.00% 99.21% 100.00% 99.21% 98.43% 100.00% 100.00% 99.21%1 3 orig. 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 99.21% 100.00% 100.00%1 4 10 96.85% 98.43% 98.43% 98.43% 97.64% 96.85% 96.85% 96.85% 96.85% 96.85% 96.85% 96.85%1 4 30 97.64% 97.64% 99.21% 98.43% 98.43% 96.85% 96.85% 98.43% 97.64% 96.85% 98.43% 97.64%1 4 orig. 99.21% 97.64% 97.64% 97.64% 97.64% 96.85% 96.85% 96.85% 96.85% 95.28% 96.06% 96.85%1 5 10 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 99.21%1 5 30 99.21% 99.21% 99.21% 99.21% 99.21% 99.21% 100.00% 99.21% 99.21% 99.21% 99.21% 99.21%1 5 orig. 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00% 100.00%
AVERAGE (above) 97.29% 97.33% 97.73% 97.90% 97.92% 92.19% 94.34% 97.86% 97.66% 91.73% 97.68% 97.49%ERROR (Table 1) 39.81% 40.48% 39.64% 36.02% 33.54% 27.66% 26.93% 25.98% 25.76% 22.58% 21.17% 23.46%UNDER (Table 1) 11.95% 16.37% 16.17% 15.28% 13.41% 9.09% 9.00% 9.27% 10.40% 9.66% 10.89% 15.31%OVER (Table 1) 27.86% 24.11% 23.47% 20.74% 20.13% 18.57% 17.93% 16.71% 15.36% 12.92% 10.28% 8.15%

Discussion
Applying BulStem for text categorisationStemming and lemmatisation are almost
equally good for BulgarianRaw text is generally worseWhen stop-words are kept stemming is slightly
better that lemmatization
Problems with BulStemSome word forms are obtained by modifying
not only the end of the word, e.g. “отбера” and “отбран” and this causes over-stemming
Homographs cause the stemmer to produce the same stem for words that are not related, e.g. “отбрана” (defense) и “отбрана” (selected)

Future work
Handling POS dependent homographsPOS taggerPOS guesser
Try other stemming techniques, compare to:Porter-like algorithms (with a set of rules)Dictionary-based (e.g. following Krovetz)Successor variety N-gramHybrid model
Try BulStem approach for other Balkan and European languages

Questions?







