

HPCE / dt10 / 2013 / 10.1
CPU Architecture

HPCE / dt10 / 2013 / 10.2
What is computation?
• Input
• State
• Output
F(s,i) ® (s,o)
s s
i o

HPCE / dt10 / 2013 / 10.3
Input and Output = Communication
• There are many different types of IO (Input/Output)
– What constitutes IO is context dependent
• Obvious forms of “external” IO
– User input devices: mouse, keyboard, joystick
– Sensors: cameras, microphones, Kinect
– Networks: Ethernet, wifi, GSM

HPCE / dt10 / 2013 / 10.4
Input and Output = Communication
• There are many different types of IO (Input/Output)
– What constitutes IO is context dependent
• Obvious forms of “external” IO
– User input devices: mouse, keyboard, joystick
– Sensors: cameras, microphones, Kinect
– Networks: Ethernet, wifi, GSM
• Obvious forms of “internal” IO
– Read from memory, write to memory
– Read from disk, write to disk

HPCE / dt10 / 2013 / 10.5
Input and Output = Communication
• There are many different types of IO (Input/Output)
– What constitutes IO is context dependent
• Obvious forms of “external” IO
– User input devices: mouse, keyboard, joystick
– Sensors: cameras, microphones, Kinect
– Networks: Ethernet, wifi, GSM
• Obvious forms of “internal” IO
– Read from memory, write to memory
– Read from disk, write to disk
• Less obvious forms of IO
– Interrupts from external devices
– Transfers from cache to memory
Registers to cache

HPCE / dt10 / 2013 / 10.6
Transforming state
• In what ways does a computer transform state?
– Data manipulation: add, multiply, compare, xor, and, ...
– Control flow: sequencing, loops, conditionals
– Transfer of control: function calls, OS calls
– Map naturally to our idea of “instructions”

HPCE / dt10 / 2013 / 10.7
Transforming state
• In what ways does a computer transform state?
– Data manipulation: add, multiply, compare, xor, and, ...
– Control flow: sequencing, loops, conditionals
– Transfer of control: function calls, OS calls
– Map naturally to our idea of “instructions”
• But what constitutes the “state”?
– Contents of the registers (PC, Regs, Flags, StackPtr)
– Contents of registers + stack
– Contents of registers + stack + heap
– above + page-table
– above + disk contents
• When does manipulation of state become IO?

HPCE / dt10 / 2013 / 10.8
Transforming state
• In what ways does a computer transform state?
– Data manipulation: add, multiply, compare, xor, and, ...
– Control flow: sequencing, loops, conditionals
– Transfer of control: function calls, OS calls
– Map naturally to our idea of “instructions”
• But what constitutes the “state”?
– Contents of the registers (PC, Regs, Flags, StackPtr)
– Contents of registers + stack
– Contents of registers + stack + heap
– above + page-table
– above + disk contents
• When does manipulation of state become IO?

HPCE / dt10 / 2013 / 10.9
Hardware Thread (CPU core)
• An active thread of computation executing on a CPU core
– State: PC, stack pointer, flags, registers
– IO: Read and write to memory, transfer control to supervisor
• Provides very simple processing of data and control flow
– Transforming data contained in registers
– Simple control flow: sequencing, branching
– Nested control flow: function call/returns

HPCE / dt10 / 2013 / 10.10
Hardware Thread (CPU core)
• An active thread of computation executing on a CPU core
– State: PC, stack pointer, flags, registers
– IO: Read and write to memory, transfer control to supervisor
• Provides very simple processing of data and control flow
– Transforming data contained in registers
– Simple control flow: sequencing, branching
– Nested control flow: function call/returns
• Should we treat push/pop as transformation or communication?
– Does the stack constitute state of the hardware thread?
• When does a thread of execution begin and end?
• What do CPU cores do if there are no threads?

HPCE / dt10 / 2013 / 10.11
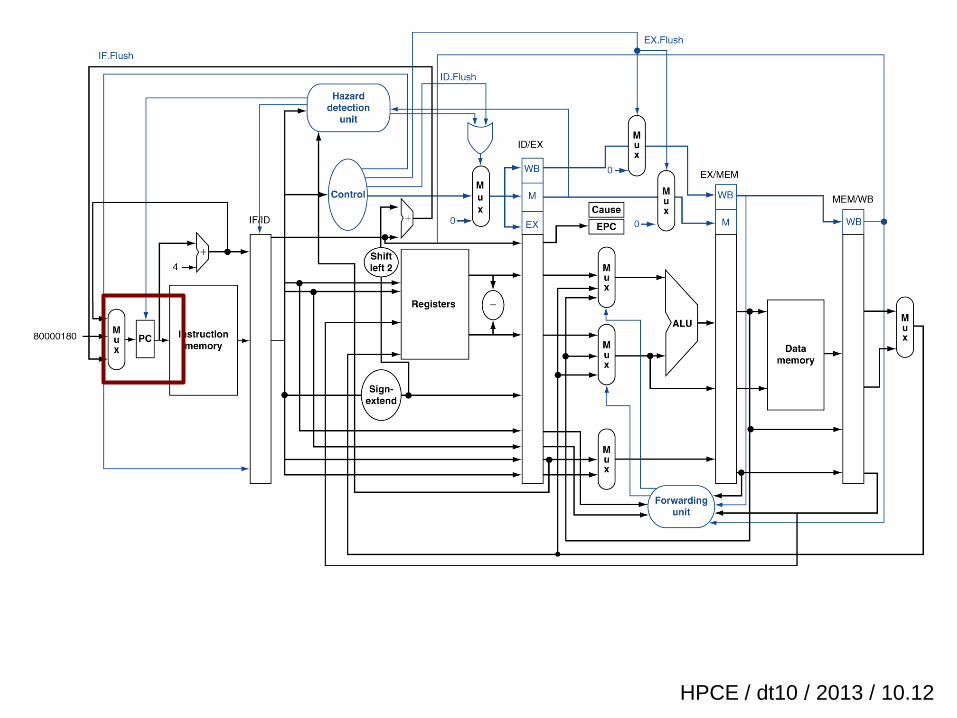
HPCE / dt10 / 2013 / 10.12
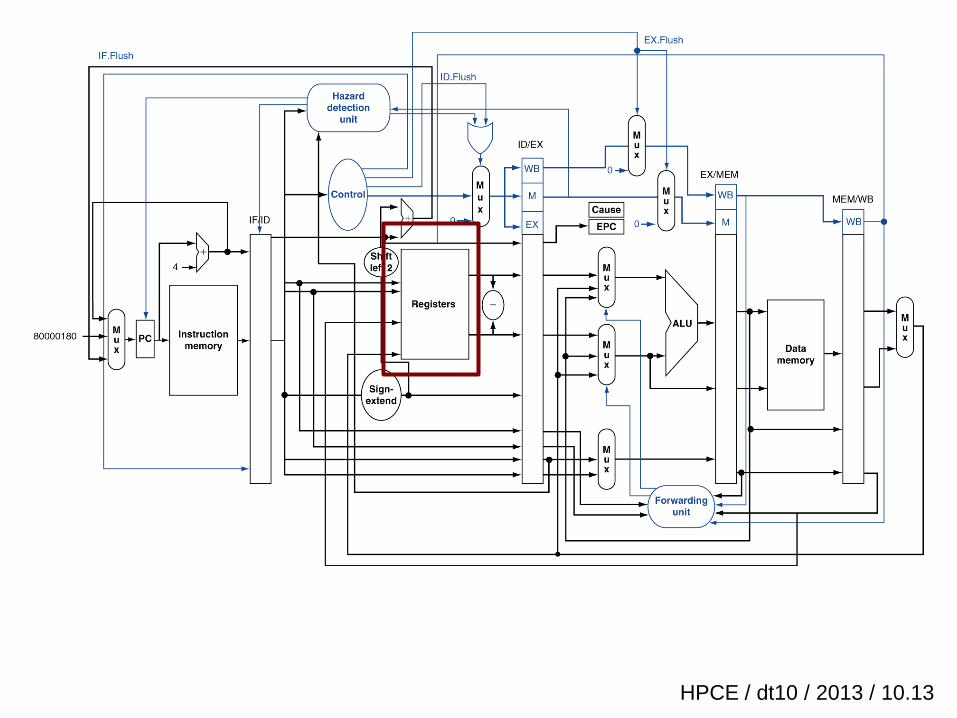
HPCE / dt10 / 2013 / 10.13

HPCE / dt10 / 2013 / 10.14

HPCE / dt10 / 2013 / 10.15

HPCE / dt10 / 2013 / 10.16
OS Thread / Kernel Thread
• A potentially active thread of computation
– May be currently assigned to a hardware thread; might be paused
– State: PC, registers, stack pointer + operating system meta-data
– IO: Access memory, call OS functions, sync with other threads
• Operating System threads have a more complicated lifecycle
– Active : currently assigned to a hardware thread and running
– Inactive : ready to run, but not assigned to a hardware thread
– Blocked : unable to run until some condition is met

HPCE / dt10 / 2013 / 10.17
OS Thread / Kernel Thread
• A potentially active thread of computation
– May be currently assigned to a hardware thread; might be paused
– State: PC, registers, stack pointer + operating system meta-data
– IO: Access memory, call OS functions, sync with other threads
• Operating System threads have a more complicated lifecycle
– Active : currently assigned to a hardware thread and running
– Inactive : ready to run, but not assigned to a hardware thread
– Blocked : unable to run until some condition is met
• Number of OS threads is limited by storage, not CPU count
– If there are more OS threads than CPUs, time-slicing will occur

HPCE / dt10 / 2013 / 10.18
Process
• A collection of OS threads and allocated OS resources
– State: state of logical threads, page table, resources
– IO: Inter-process communication, shared memory, networks, files
• A process is a unit of isolation
– Threads within a process share a single memory space
– Threads in different processes cannot communicate via memory
– Page-table: map process-relative address to physical addresses

HPCE / dt10 / 2013 / 10.19
Process
• A collection of OS threads and allocated OS resources
– State: state of logical threads, page table, resources
– IO: Inter-process communication, shared memory, networks, files
• A process is a unit of isolation
– Threads within a process share a single memory space
– Threads in different processes cannot communicate via memory
– Page-table: map process-relative address to physical addresses
• Create OS threads and processes via OS
– New OS thread: CreateThread, pthread_create
– New process: CreateProcess, exec, spawn[1]
[1] – This refers to a posix OS spawn, not a cilk spawn

HPCE / dt10 / 2013 / 10.20
Scheduling OS Threads to Cores
• What causes a HW thread to switch OS threads?
– Interrupts: an external factor causes an interrupt handler to run
– Pre-emption: OS decides another thread should have a chance
• Usually originates in some form of recurring interrupt timer
– Exceptions: thread tries an operation that can’t be handled
• Benign exception: page fault (need to swap in page from disk)
• Error: invalid page fault, invalid instruction, divide by zero
– IO: the thread asks the OS to perform some service
• e.g. Read/write to a file or socket
– Synchronisation: the thread waits for a signal from another thread
• Process of changing threads is a context switch

HPCE / dt10 / 2013 / 10.21
The Context Switch: Explicit Steps
• Must schedule a different OS thread to a hardware thread
1. Suspend execution of the current hardware thread
2. Copy the hardware thread state into the OS thread state
3. Retrieve the next OS thread
4. Copy the new OS thread’s state to the hardware thread
5. Resume execution of the hardware thread

HPCE / dt10 / 2013 / 10.22
The Context Switch: Explicit Steps
• Must schedule a different OS thread to a hardware thread
1. Suspend execution of the current hardware thread
2. Copy the hardware thread state into the OS thread state
3. Retrieve the next OS thread
4. Copy the new OS thread’s state to the hardware thread
5. Resume execution of the hardware thread
• Different cost if switching between processes
– Thread context switch: save and restore registers
– Process context switch: save and restore page-table info too

HPCE / dt10 / 2013 / 10.23
The Context Switch: Hidden Costs
• Threads collect some amount of “local” data while executing
– Instruction Cache
– Data Cache
– Branch Predictor
– Branch-Target Buffer
– Translation Lookaside Buffer
– Virtual pages mapped to physical memory

HPCE / dt10 / 2013 / 10.24
The Context Switch: Hidden Costs
• Threads collect some amount of “local” data while executing
– Instruction Cache
– Data Cache
– Branch Predictor
– Branch-Target Buffer
– Translation Lookaside Buffer
– Virtual pages mapped to physical memory
• Data may be shared within processes or specific to OS thread
– Data Cache : threads have different stacks
– Instruction Cache : threads often execute the same code

HPCE / dt10 / 2013 / 10.25
The Context Switch: Hidden Costs
• Threads collect some amount of “local” data while executing
– Instruction Cache
– Data Cache
– Branch Predictor
– Branch-Target Buffer
– Translation Lookaside Buffer
– Virtual pages mapped to physical memory
• Data may be shared within processes or specific to OS thread
– Data Cache : threads have different stacks
– Instruction Cache : threads often execute the same code
• Local data needed in cache is the working set of a thread

HPCE / dt10 / 2013 / 10.26
The Advance of Caches
• Memory is an abstraction layer
– “Read from this address”
– “Write to this address”
– Used to be physical reality
Registers
ALU
Memory

HPCE / dt10 / 2013 / 10.27
The Advance of Caches
• Memory is an abstraction layer
– “Read from this address”
– “Write to this address”
– Used to be physical reality
• Cache hierarchy creates zones
– Inner: low-latency, high bandwidth
– Outer: high capacity, cheap
Registers
ALU
Memory
L1 Cache

HPCE / dt10 / 2013 / 10.28
The Advance of Caches
• Memory is an abstraction layer
– “Read from this address”
– “Write to this address”
– Used to be physical reality
• Cache hierarchy creates zones
– Inner: low-latency, high bandwidth
– Outer: high capacity, cheap
• Actual memory is very far away
– Very big, but very slow
– We are hitting the memory wall
L2 Cache
Registers
ALU
Memory
L1 Cache
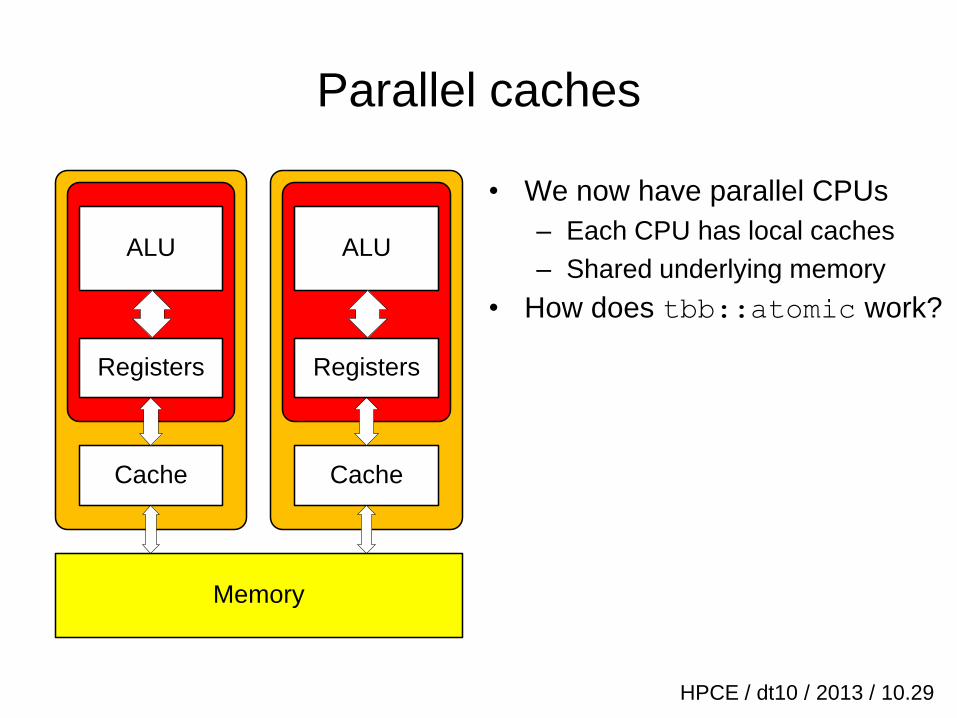
HPCE / dt10 / 2013 / 10.29
Parallel caches
• We now have parallel CPUs
– Each CPU has local caches
– Shared underlying memory
• How does tbb::atomic work?
Cache Cache
Registers
ALU
Memory
Registers
ALU

HPCE / dt10 / 2013 / 10.30
Parallel caches
• We now have parallel CPUs
– Each CPU has local caches
– Shared underlying memory
• CPUs connect via caches
– Memory is too dumb
• Same data in many caches
– e.g. shared read-only data
• What about writes?
– Lazy consistency
• Atomics: cache coherence
– Only one CPU can modify
atomic data at a time
Cache Cache
Registers
ALU
Memory
Registers
ALU

HPCE / dt10 / 2013 / 10.31
Atomics through locking
• Multiple processors are connected through caches
CPU-0
CPU-1
$-0
$-1 $-3
$-2 CPU-2
CPU-3

HPCE / dt10 / 2013 / 10.32
Atomics through locking
• Multiple processors are connected through caches
– Identical data may be found in multiple caches
...
...
...
x=3 ...
x=3 ...
...

HPCE / dt10 / 2013 / 10.33
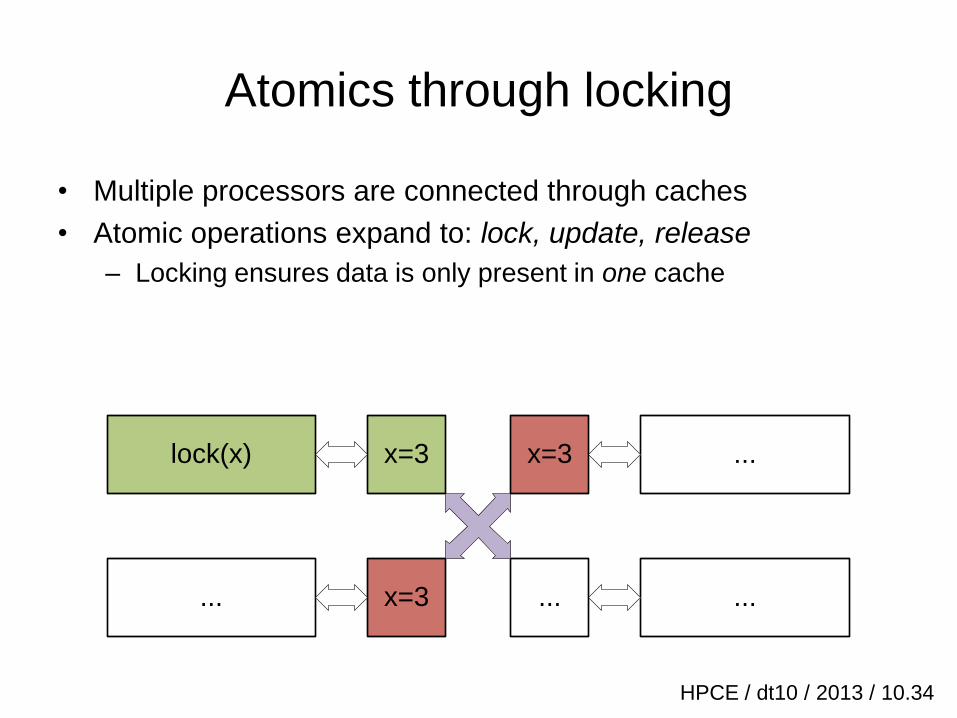
Atomics through locking
• Multiple processors are connected through caches
– Identical data may be found in multiple caches
– Atomic operations expand into a sequence of smaller operations
y = x++;
...
...
x=3 ...
x=3 ...
...
HPCE / dt10 / 2013 / 10.34
Atomics through locking
• Multiple processors are connected through caches
• Atomic operations expand to: lock, update, release
– Locking ensures data is only present in one cache
lock(x)
...
x=3
x=3 ...
x=3 ...
...
HPCE / dt10 / 2013 / 10.35
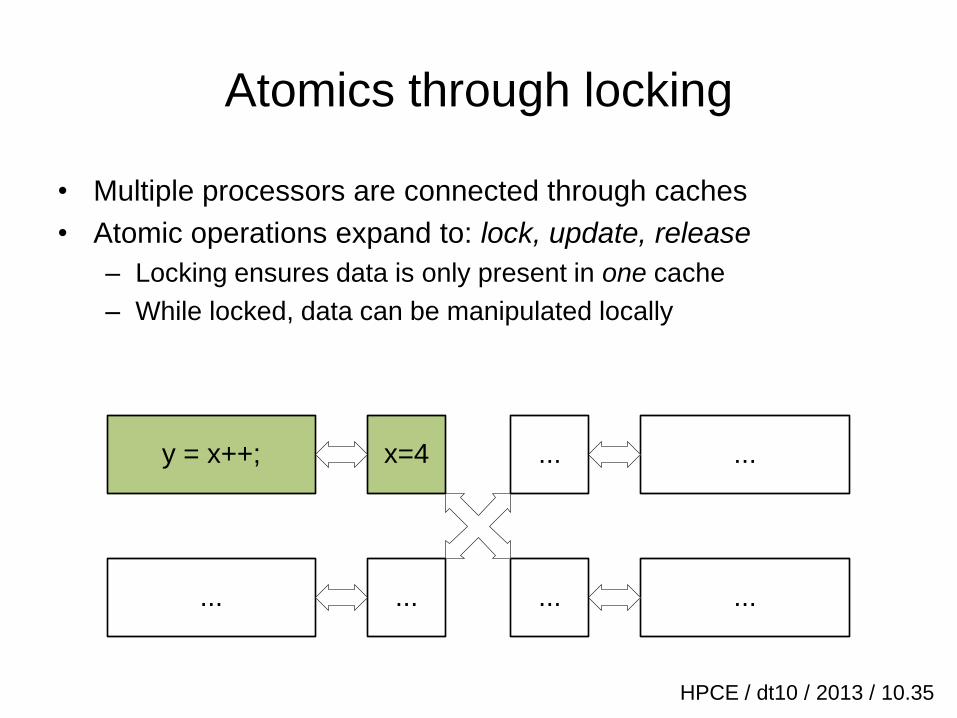
Atomics through locking
• Multiple processors are connected through caches
• Atomic operations expand to: lock, update, release
– Locking ensures data is only present in one cache
– While locked, data can be manipulated locally
y = x++;
...
x=4
... ...
... ...
...

HPCE / dt10 / 2013 / 10.36
Atomics through locking
• Multiple processors are connected through caches
• Atomic operations expand to: lock, update, release
– Locking ensures data is only present in one cache
– While locked, data can be manipulated locally
– Other CPUs can read the data once it is released
release(x)
...
x=4
... ...
... ...
...

HPCE / dt10 / 2013 / 10.37
Atomics through locking
• Multiple processors are connected through caches
• Atomic operations expand to: lock, update, release
• Problem occurs if two CPUs want to modify same memory
– Only one lock will succeed
...
lock(x)
x=4
... ...
x=4 lock(x)
...

HPCE / dt10 / 2013 / 10.38
Atomics through locking
• Multiple processors are connected through caches
• Atomic operations expand to: lock, update, release
• Problem occurs if two CPUs want to modify same memory
– Only one lock will succeed
– Other CPU will block until it can acquire a lock
...
lock(x)
...
... ...
x=4 y = x++;
...

HPCE / dt10 / 2013 / 10.39
Potential Problems with Atomic Operations
• Lock contention : CPUs fight to lock the same location
– Assume CPU performs atomic with probability p per cycle
– Given n processors, probably of conflict per cycle is ~1-(1-p)n
– But eventually progress will be made

HPCE / dt10 / 2013 / 10.40
Potential Problems with Atomic Operations
• Lock contention : CPUs fight to lock the same location
– Assume CPU performs atomic with probability p per cycle
– Given n processors, probably of conflict per cycle is ~1-(1-p)n
– But eventually progress will be made
• Cache thrashing: Locking a variable evicts entire cache line
– Memory traffic increases even if conflicts don’t occur
– Still need to move data from cache to cache

HPCE / dt10 / 2013 / 10.41
Potential Problems with Atomic Operations
• Lock contention : CPUs fight to lock the same location
– Assume CPU performs atomic with probability p per cycle
– Given n processors, probably of conflict per cycle is ~1-(1-p)n
– But eventually progress will be made
• Cache thrashing: Locking a variable evicts entire cache line
– Memory traffic increases even if conflicts don’t occur
– Still need to move data from cache to cache
• General guidelines for use:
– atomic ops should be a low percentage of total instructions
try to ensure that each atomic only lives in one cache

HPCE / dt10 / 2013 / 10.42
Cache Warmth
• Warm cache: working set for a thread is currently in caches
– Thread has been running for a while and fetched working set
– Thread was recently scheduled and data is still in the cache
– The previous thread shared part of the working set

HPCE / dt10 / 2013 / 10.43
Cache Warmth
• Warm cache: working set for a thread is currently in caches
– Thread has been running for a while and fetched working set
– Thread was recently scheduled and data is still in the cache
– The previous thread shared part of the working set
• Cold cache: working set is not in caches
– Process/thread is starting up, so data has not been fetched yet
– Thread has not been scheduled in a long time
– Previously scheduled thread has evicted working set

HPCE / dt10 / 2013 / 10.44
Cache Warmth
• Warm cache: working set for a thread is currently in caches
– Thread has been running for a while and fetched working set
– Thread was recently scheduled and data is still in the cache
– The previous thread shared part of the working set
• Cold cache: working set is not in caches
– Process/thread is starting up, so data has not been fetched yet
– Thread has not been scheduled in a long time
– Previously scheduled thread has evicted working set
• A hot cache is possible: all requests serviced from cache
– Difficult to achieve; thread must have tiny working set
– Sometimes possible with compute-bound work
HPCE / dt10 / 2013 / 10.45
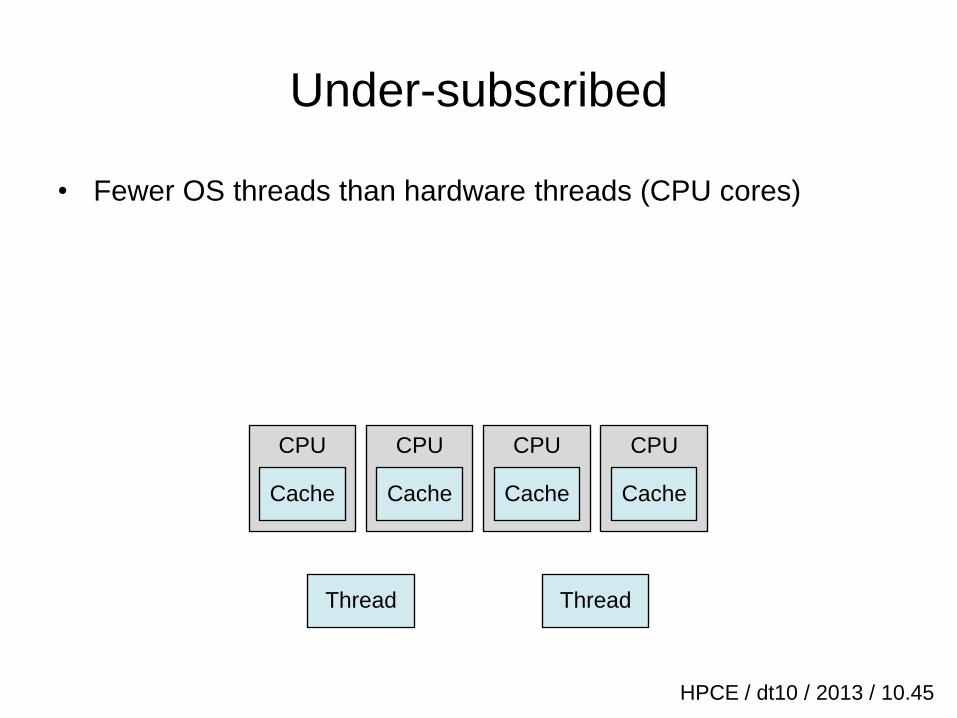
Under-subscribed
• Fewer OS threads than hardware threads (CPU cores)
CPU
Cache
Thread Thread
CPU
Cache
CPU
Cache
CPU
Cache
HPCE / dt10 / 2013 / 10.46
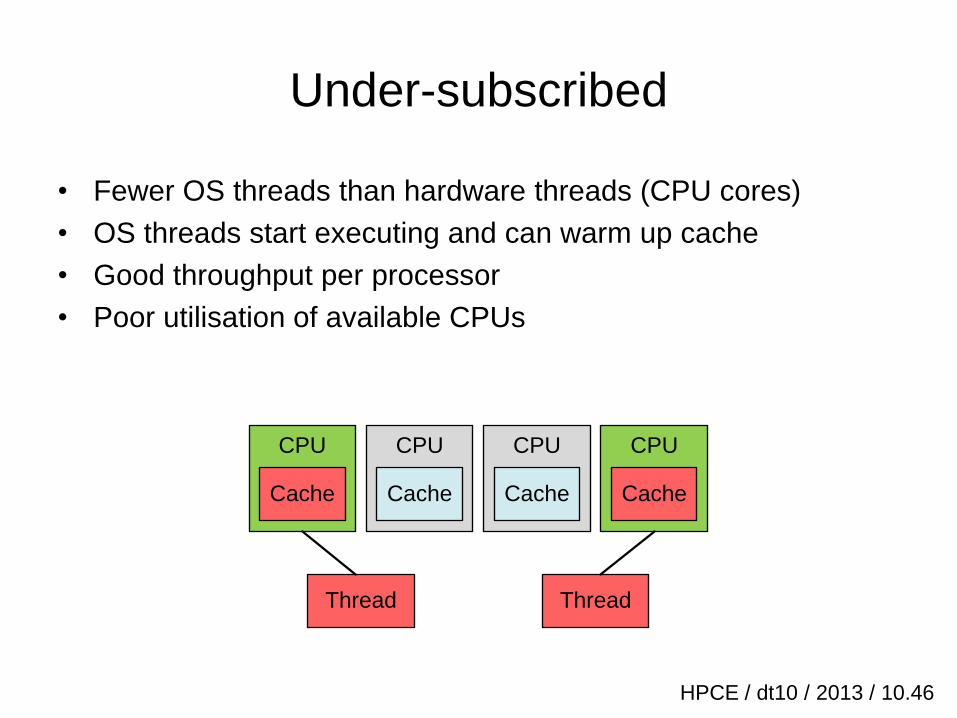
Under-subscribed
• Fewer OS threads than hardware threads (CPU cores)
• OS threads start executing and can warm up cache
• Good throughput per processor
• Poor utilisation of available CPUs
CPU
Cache
Thread Thread
CPU
Cache
CPU
Cache
CPU
Cache
HPCE / dt10 / 2013 / 10.47
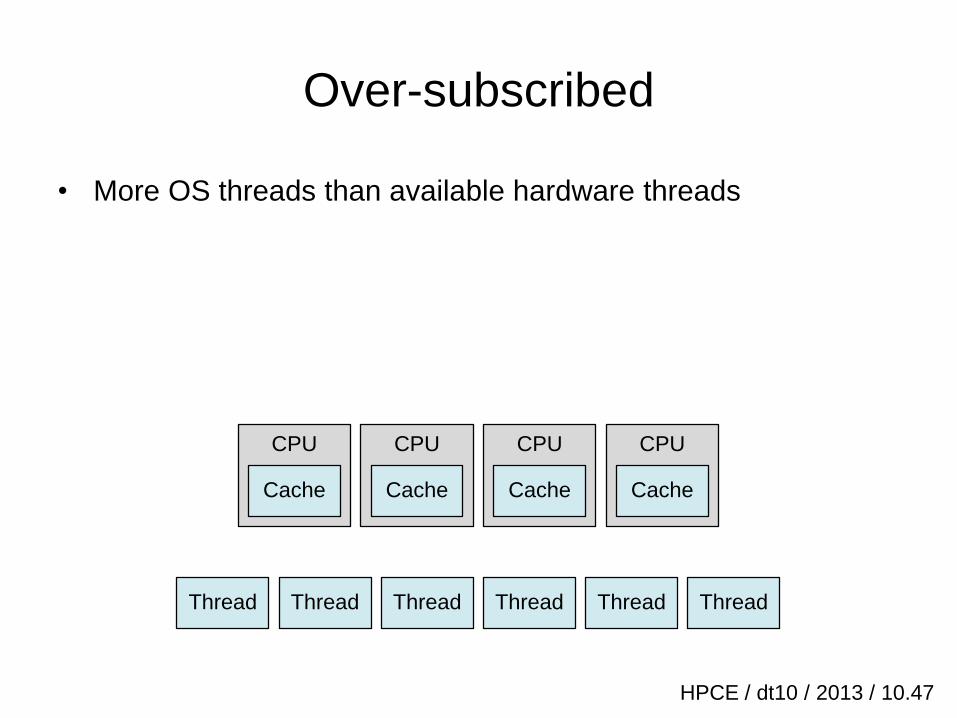
Over-subscribed
• More OS threads than available hardware threads
CPU
Cache
CPU
Cache
CPU
Cache
CPU
Cache
ThreadThreadThread Thread ThreadThread

HPCE / dt10 / 2013 / 10.48
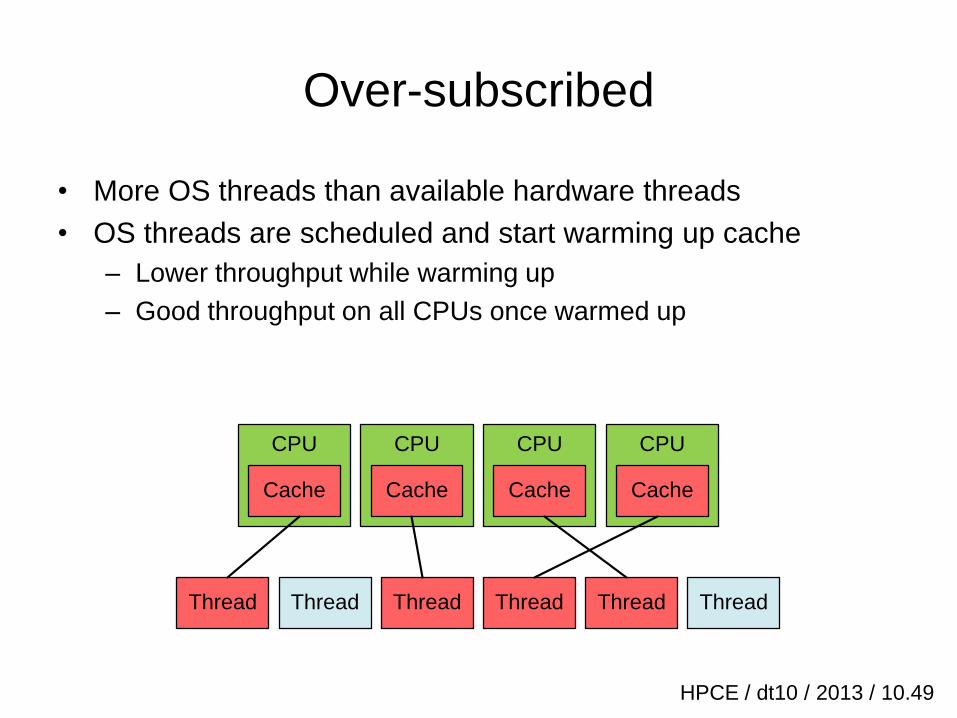
Over-subscribed
• More OS threads than available hardware threads
• OS threads are scheduled and start warming up cache
– Lower throughput while warming up
CPU
Cache
CPU
Cache
CPU
Cache
CPU
Cache
ThreadThreadThread Thread ThreadThread
HPCE / dt10 / 2013 / 10.49
Over-subscribed
• More OS threads than available hardware threads
• OS threads are scheduled and start warming up cache
– Lower throughput while warming up
– Good throughput on all CPUs once warmed up
CPU
Cache
CPU
Cache
CPU
Cache
CPU
Cache
ThreadThreadThread Thread ThreadThread

HPCE / dt10 / 2013 / 10.50
Over-subscribed
• More OS threads than available hardware threads
• OS threads are scheduled and start warming up cache
• Eventually OS decides to pre-emptively schedule
– New threads are completely cold
– Previous threads start to cool down
CPU
Cache
CPU
Cache
CPU
Cache
CPU
Cache
ThreadThreadThread Thread ThreadThread

HPCE / dt10 / 2013 / 10.51
Over-subscribed
• More OS threads than available hardware threads
• OS threads are scheduled and start warming up cache
• Eventually OS decides to pre-emptively schedule
– New threads are completely cold
– Previous threads start to cool down
– New threads start to warm cache but have lower throughput
CPU
Cache
CPU
Cache
CPU
Cache
CPU
Cache
ThreadThreadThread Thread ThreadThread

HPCE / dt10 / 2013 / 10.52
Over-subscribed
• More OS threads than available hardware threads
• OS threads are scheduled and start warming up cache
• Eventually OS decides to pre-emptively schedule
• OS decides to reschedule again
– Will evict the longest running threads... which have hottest cache
CPU
Cache
CPU
Cache
CPU
Cache
CPU
Cache
ThreadThreadThread Thread ThreadThread

HPCE / dt10 / 2013 / 10.53
Well-subscribed
• Same number of OS threads as hardware threads
CPU
Cache
ThreadThread Thread Thread
CPU
Cache
CPU
Cache
CPU
Cache

HPCE / dt10 / 2013 / 10.54
Well-subscribed
• Same number of OS threads as hardware threads
CPU
Cache
ThreadThread Thread Thread
CPU
Cache
CPU
Cache
CPU
Cache

HPCE / dt10 / 2013 / 10.55
Well-subscribed
• Same number of OS threads as hardware threads
• Good throughput per processor
• Good utilisation of all processors
CPU
Cache
ThreadThread Thread Thread
CPU
Cache
CPU
Cache
CPU
Cache

HPCE / dt10 / 2013 / 10.56
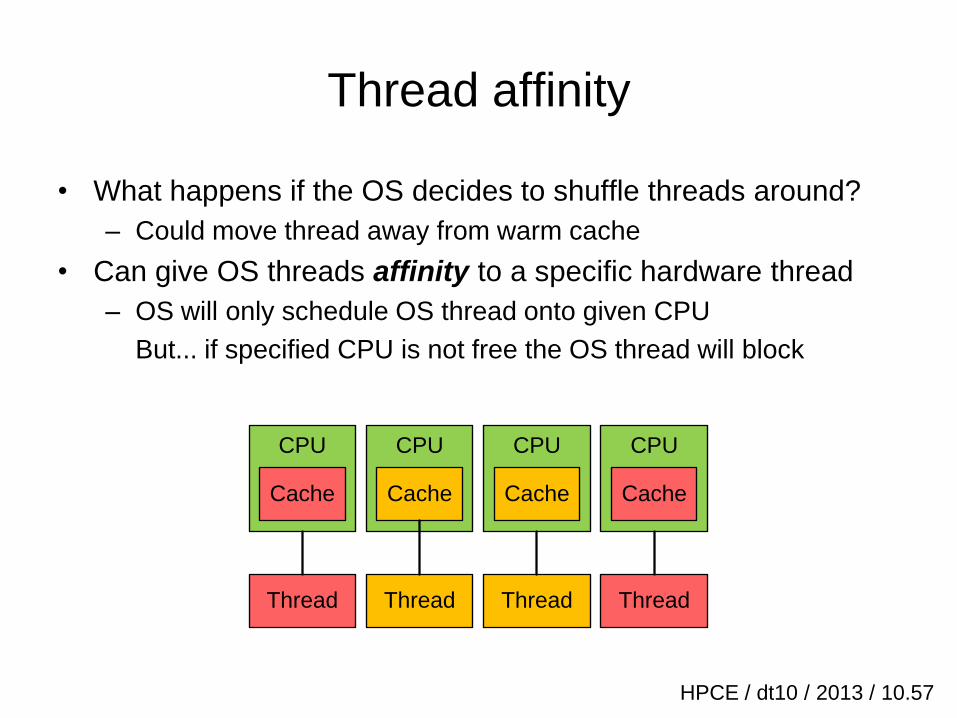
Thread affinity
• What happens if the OS decides to shuffle threads around?
– Could move thread away from warm cache
CPU
Cache
ThreadThread Thread Thread
CPU
Cache
CPU
Cache
CPU
Cache
HPCE / dt10 / 2013 / 10.57
Thread affinity
• What happens if the OS decides to shuffle threads around?
– Could move thread away from warm cache
• Can give OS threads affinity to a specific hardware thread
– OS will only schedule OS thread onto given CPU
But... if specified CPU is not free the OS thread will block
CPU
Cache
ThreadThread Thread Thread
CPU
Cache
CPU
Cache
CPU
Cache

HPCE / dt10 / 2013 / 10.58
Managing threads
• Ideal situation: one OS thread per HW thread, fixed affinity
– Difficult to manage by directly controlling threads
– Managing affinity is tricky, easy to deadlock or under-utilise

HPCE / dt10 / 2013 / 10.59
Managing threads
• Ideal situation: one OS thread per HW thread, fixed affinity
– Difficult to manage by directly controlling threads
– Managing affinity is tricky, easy to deadlock or under-utilise
• Solution: task-based scheduling interface
– Create work-load of small tasks which are not bound to a thread
– Task scheduler gives tasks to OS threads as they become idle
– Manages affinity so tasks stay on the same thread

HPCE / dt10 / 2013 / 10.60
Managing threads
• Ideal situation: one OS thread per HW thread, fixed affinity
– Difficult to manage by directly controlling threads
– Managing affinity is tricky, easy to deadlock or under-utilise
• Solution: task-based scheduling interface
– Create work-load of small tasks which are not bound to a thread
– Task scheduler gives tasks to OS threads as they become idle
– Manages affinity so tasks stay on the same thread
• Why does work-stealing work so well?

HPCE / dt10 / 2013 / 10.61
Data movement and Communication
• Moving data between cache levels is implicit communication
– We will shortly see explicit communication with GPUs
• Communication within a CPU has significant costs
– Latency : how long a CPU must wait before getting data
– Bandwidth : sustained transfer rate between memory and CPU
– Energy : moving bits around a chip takes lots of energy

HPCE / dt10 / 2013 / 10.62
Data movement and Communication
• Moving data between cache levels is implicit communication
– We will shortly see explicit communication with GPUs
• Communication within a CPU has significant costs
– Latency : how long a CPU must wait before getting data
– Bandwidth : sustained transfer rate between memory and CPU
– Energy : moving bits around a chip takes lots of energy
• Organise computation to minimise communication
– Avoid shared read-write memory regions and atomic operations
Work in task-private variables; only merge results at the end

HPCE / dt10 / 2013 / 10.63
What about actual computation?
• Sometimes moving data around is the computation
– Graph analysis algorithms: very little actual calculation
• More often communication is simply enabling calculation
– Numeric computation: move data to the ALUs to do maths
– Compilation/analysis: move data to the ALUs to control branching

HPCE / dt10 / 2013 / 10.64
What about actual computation?
• Sometimes moving data around is the computation
– Graph analysis algorithms: very little actual calculation
• More often communication is simply enabling calculation
– Numeric computation: move data to the ALUs to do maths
– Compilation/analysis: move data to the ALUs to control branching
• Assume data is already close to the ALUs
– What metrics should we be trying to optimise?
– Often the metrics are instruction throughput and cost of work
– Throughput: instructions per second per what?
– Cost of work: cost of what per work?

HPCE / dt10 / 2013 / 10.65 Source: Borkar et. al., http://dl.acm.org/citation.cfm?id=1941487.1941507

HPCE / dt10 / 2013 / 10.66
Evolution of metrics
• 60s-70s: very little silicon, so let’s just make it fit
– Metric: operations / sec / area
– Re-use components for maximum functionality with fixed area

HPCE / dt10 / 2013 / 10.67
Evolution of metrics
• 60s-70s: very little silicon, so let’s just make it fit
– Metric: operations / sec / area
– Re-use components for maximum functionality with fixed area
• 80s-90s: Moore’s Law is king; burn area and power for speed
– Metric: operations / sec / dollar
– How much does a chip cost vs the throughput it achieves
– Huge amounts of area spent on instruction scheduling

HPCE / dt10 / 2013 / 10.68
Evolution of metrics
• 60s-70s: very little silicon, so let’s just make it fit
– Metric: operations / sec / area
– Re-use components for maximum functionality with fixed area
• 80s-90s: Moore’s Law is king; burn area and power for speed
– Metric: operations / sec / dollar
– How much does a chip cost vs the throughput it achieves
– Huge amounts of area spent on instruction scheduling
• 00s: Moore’s Law still working; cooling is an issue
– Metric: operations / sec / (joule or dollar)
Silicon is getting cheap, power is getting expensive

HPCE / dt10 / 2013 / 10.69
Evolution of metrics
• 60s-70s: very little silicon, so let’s just make it fit
– Metric: operations / sec / area
– Re-use components for maximum functionality with fixed area
• 80s-90s: Moore’s Law is king; burn area and power for speed
– Metric: operations / sec / dollar
– How much does a chip cost vs the throughput it achieves
– Huge amounts of area spent on instruction scheduling
• 00s: Moore’s Law still working; cooling is an issue
– Metric: operations / sec / (joule or dollar)
Silicon is getting cheap, power is getting expensive
• 10s+: Moore’s law looking dubious; power is a massive issue
Metric: operations / sec / joule

HPCE / dt10 / 2013 / 10.70
Optimising for Cost of Work
• Cost of work applies to both sequential and parallel code
– Sequential code: reduce overhead per sequential operation
– Parallel code: eventually parallel code reduces to sequential

HPCE / dt10 / 2013 / 10.71
Optimising for Cost of Work
• Cost of work applies to both sequential and parallel code
– Sequential code: reduce overhead per sequential operation
– Parallel code: eventually parallel code reduces to sequential
• Super-scalar CPU: optimise for cost of work in cycles
– Standard CPU with PC: each instruction costs one cycle
Super-scalar: use fancy logic to issue many instructions per cycle
– Requires large amounts of area and power: always active

HPCE / dt10 / 2013 / 10.72
Optimising for Cost of Work
• Cost of work applies to both sequential and parallel code
– Sequential code: reduce overhead per sequential operation
– Parallel code: eventually parallel code reduces to sequential
• Super-scalar CPU: optimise for cost of work in cycles
– Standard CPU with PC: each instruction costs one cycle
Super-scalar: use fancy logic to issue many instructions per cycle
– Requires large amounts of area and power: always active
SIMD & VLIW: optimise for cost of work in cycles and power
– SIMD: Single Instruction Multiple Data
VLIW: Very Long Instruction Word
– Add additional functional units: only cost power if they are used







