

Decision MakingDecision Makingin Robots and Autonomous in Robots and Autonomous
AgentsAgents
The Markov Decision Process (MDP) model
Subramanian RamamoorthySchool of Informatics
25 January, 2013

In the MAB Model…
• We were in a single casino and the only decision is to pull from a set of n arms– except perhaps in the very last slides, exactly one state!
We asked the following,• What if there is more than one state?• So, in this state space, what is the effect of the distribution of
payout changing based on how you pull arms? • What happens if you only obtain a net reward corresponding
to a long sequence of arm pulls (at the end)?
25/01/2013 2

Decision Making Agent-Environment Interface
Agent and environment interact at discrete time steps : t 0,1, 2, Agent observes state at step t : st S
produces action at step t : at A(st )
gets resulting reward : rt 1 and resulting next state : st1
t
. . . st art +1 st +1
t +1art +2 st +2
t +2art +3 st +3
. . .t +3a
25/01/2013 3

Markov Decision Processes
• A model of the agent-environment system• Markov property = history doesn’t matter, only current state• If state and action sets are finite, it is a finite MDP. • To define a finite MDP, you need to give:
– state and action sets– one-step “dynamics” defined by transition probabilities:
– reward probabilities:
Ps s a Pr st1 s st s,at a for all s, s S, a A(s).
Rs s a E rt1 st s,at a,st1 s for all s, s S, a A(s).
25/01/2013 4

Recycling Robot
An Example Finite MDP
• At each step, robot has to decide whether it should (1) actively search for a can, (2) wait for someone to bring it a can, or (3) go to home base and recharge.
• Searching is better but runs down the battery; if runs out of power while searching, has to be rescued (which is bad).
• Decisions made on basis of current energy level: high, low.
• Reward = number of cans collected
25/01/2013 5
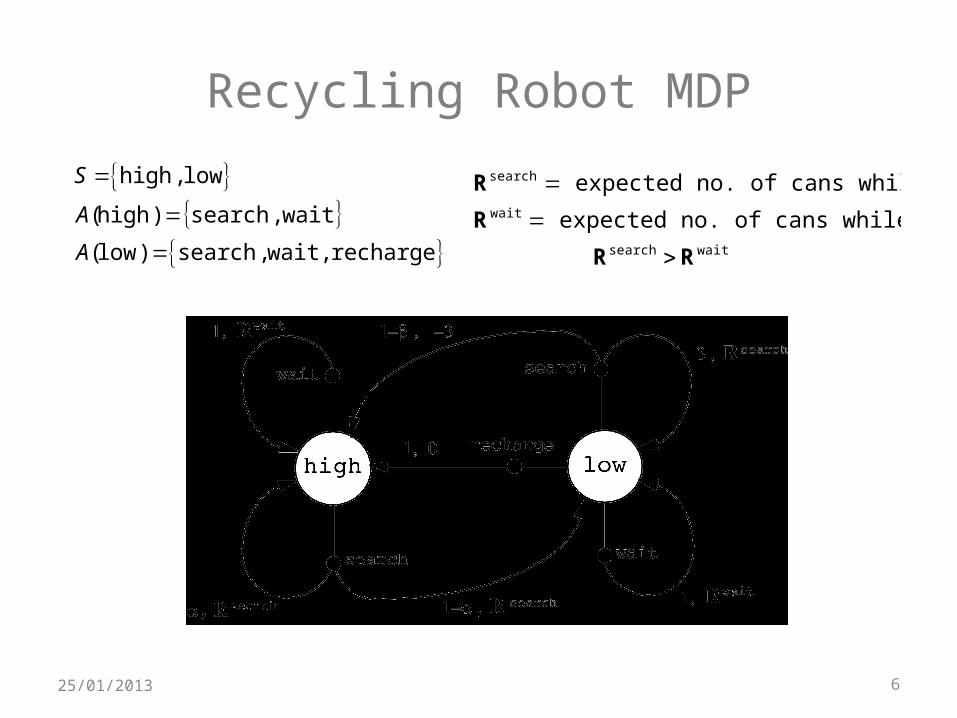
Recycling Robot MDP
S high,low A(high) search, wait A(low) search,wait, recharge
Rsearch expected no. of cans while searching
Rwait expected no. of cans while waiting
Rsearch Rwait
25/01/2013 6

Enumerated In Tabular Form
25/01/2013 7
If you were given this much, what can you say aboutthe behaviour (over time) of the system?

A Very Brief Primer on Markov Chains and Decisions
A model, as originally developed in Operations Research/Stochastic Control theory
25/01/2013 8

Stochastic Processes
• A stochastic process is an indexed collection of random variables .– e.g., collection of weekly demands for a product
• One type: At a particular time t, labelled by integers, system is found in exactly one of a finite number of mutually exclusive and exhaustive categories or states, labelled by integers too
• Process could be imbedded in that time points correspond to occurrence of specific events (or time may be equi-spaced)
• Random variables may depend on others, e.g.,
25/01/2013 9

Markov Chains
• The stochastic process is said to have a Markovian property if
• Markovian probability means that the conditional probability of a future event given any past events and current state, is independent of past states and depends only on present
• The conditional probabilities are transition probabilities,
• These are stationary if time invariant, called pij,
25/01/2013 10

Markov Chains
• Looking forward in time, n-step transition probabilities, pij(n)
• One can write a transition matrix,
• A stochastic process is a finite-state Markov chain if it has,– Finite number of states– Markovian property– Stationary transition probabilities– A set of initial probabilities P{X0 = i} for all i
25/01/2013 11

Markov Chains
• n-step transition probabilities can be obtained from 1-step transition probabilities recursively (Chapman-Kolmogorov)
• We can get this via the matrix too
• First Passage Time: number of transitions to go from i to j for the first time– If i = j, this is the recurrence time– In general, this itself is a random variable
25/01/2013 12
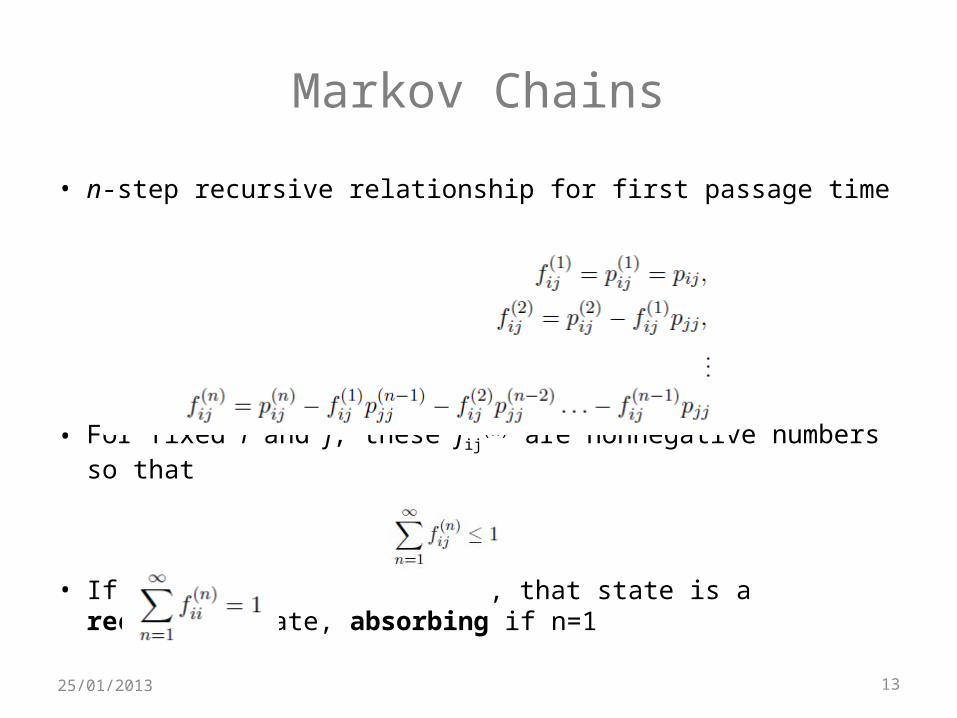
Markov Chains
• n-step recursive relationship for first passage time
• For fixed i and j, these fij(n) are nonnegative numbers so that
• If, , that state is a recurrent state, absorbing if n=1
25/01/2013 13

Markov Chains: Long-Run Properties
Consider the 8-step transition matrix of the inventory example:
Interesting property: probability of being in state j after 8 weeks appears independent of initial level of inventory.
• For an irreducible ergodic Markov chain, one has limiting probability
Reciprocal gives yourecurrence time jj
25/01/2013 14

Markov Decision Model
• Consider the following application: machine maintenance• A factory has a machine that deteriorates rapidly in quality and
output and is inspected periodically, e.g., daily• Inspection declares the machine to be in four possible states:
– 0: Good as new– 1: Operable, minor deterioration– 2: Operable, major deterioration– 3: Inoperable
• Let Xt denote this observed state– evolves according to some “law of motion”, so it is a stochastic process– Furthermore, assume it is a finite state Markov chain
25/01/2013 15

Markov Decision Model
• Transition matrix is based on the following:
• Once the machine goes inoperable, it stays there until repairs– If no repairs, eventually, it reaches this state which is absorbing!
• Repair is an action – a very simple maintenance policy.– e.g., machine from from state 3 to state 0
25/01/2013 16

Markov Decision Model
• There are costs as system evolves:– State 0: cost 0– State 1: cost 1000– State 2: cost 3000
• Replacement cost, taking state 3 to 0, is 4000 (and lost production of 2000), so cost = 6000
• The modified transition probabilities are:
25/01/2013 17

Markov Decision Model
• Simple question: What is the average cost of this maintenance policy?
• Compute the steady state probabilities:
• (Long run) expected average cost per day,
25/01/2013 18
How?

Markov Decision Model
• Consider a slightly more elaborate policy:– Repair when inoperable or needing major repairs, replace
• Transition matrix now changes a little bit• Permit one more thing: overhaul
– Go back to minor repairs state (1) for the next time step– Not possible if truly inoperable, but can go from major to minor
• Key point about the system behaviour. It evolves according to– “Laws of motion”– Sequence of decisions made (actions from {1: none,2:overhaul,3: replace})
• Stochastic process is now defined in terms of {Xt} and {t}
– Policy, R, is a rule for making decisions• Could use all history, although popular choice is (current) state-based
25/01/2013 19

Markov Decision Model
• There is a space of potential policies, e.g.,
• Each policy defines a transition matrix, e.g., for Rb
Which policy is best?Need costs….
25/01/2013 20
00

Markov Decision Model
• Cik = expected cost incurred during next transition if system is in state i and decision k is made
• The long run average expected cost for each policy may be computed using
State Dec. 1 2 3
0 0 4 6
1 1 4 6
2 3 4 6
3 ∞ ∞ 6
Rb is best
25/01/2013 21

Markov Decision Processes
Solution using Dynamic Programming(*some notation changes upcoming)
25/01/2013 22

The RL Problem
Main Elements:• States, s• Actions, a• State transition dynamics -
often, stochastic & unknown• Reward (r) process - possibly
stochastic
Objective: Policy t(s,a)– probability distribution over
actions given current state
AssumptionAssumption::Environment defines Environment defines a finite-state MDPa finite-state MDP
25/01/2013 23

Back to Our Recycling Robot MDP
S high,low A(high) search, wait A(low) search,wait, recharge
Rsearch expected no. of cans while searching
Rwait expected no. of cans while waiting
Rsearch Rwait
25/01/2013 24

Given an enumeration of transitions and corresponding costs/rewards, what is the best sequence of actions?
We want to maximize the criterion:
So, what must one do?
25/01/2013 25
01
kkt
kt rR
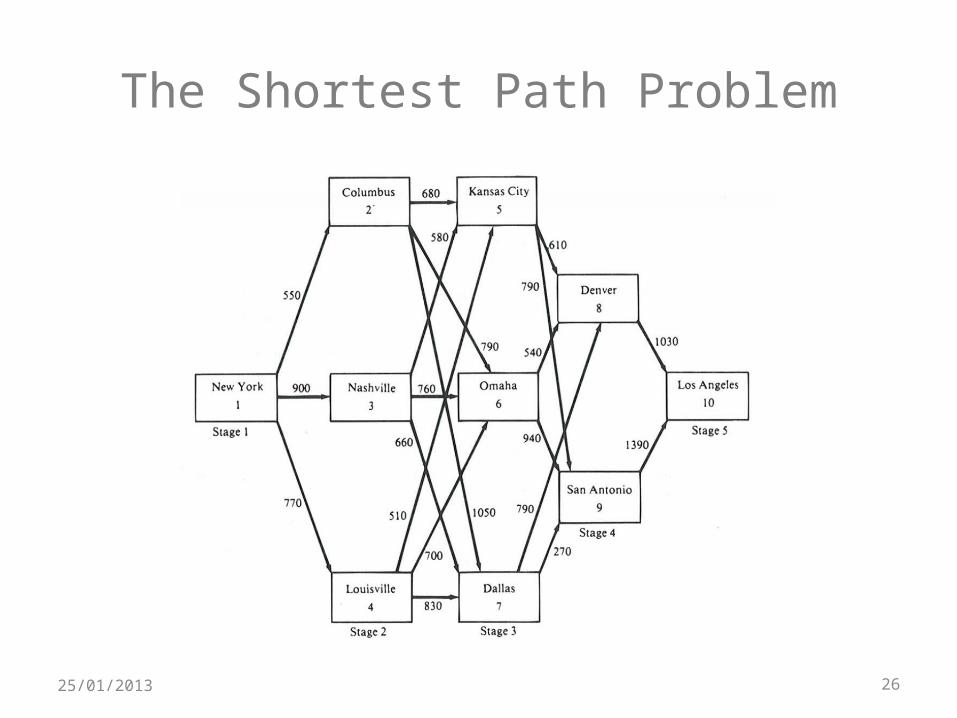
The Shortest Path Problem
25/01/2013 26
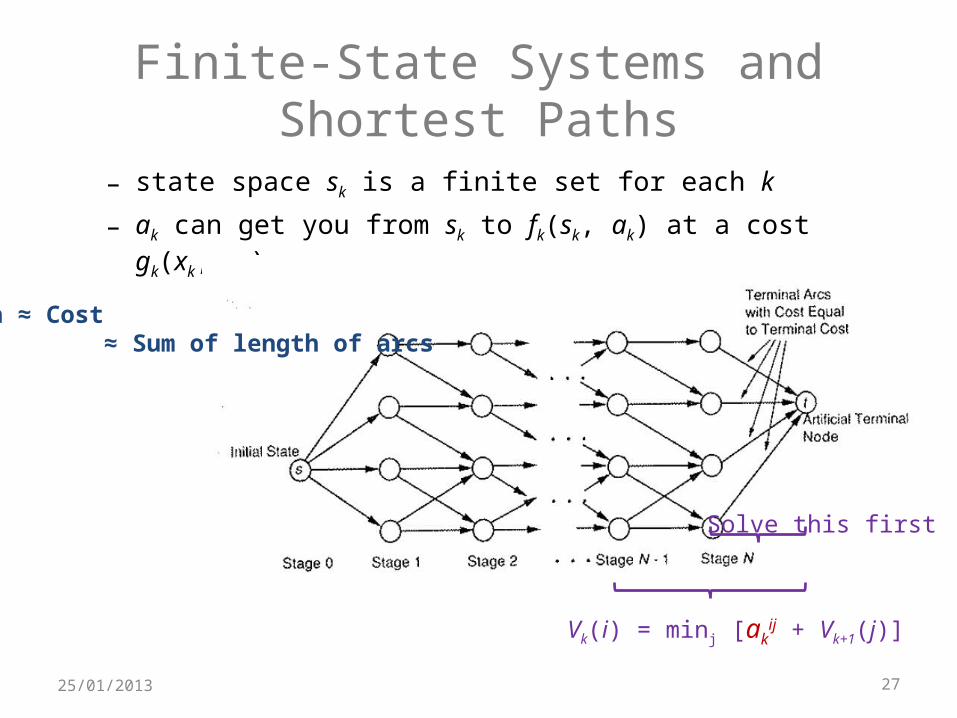
Finite-State Systems and Shortest Paths
– state space sk is a finite set for each k
– ak can get you from sk to fk(sk, ak) at a cost gk(xk, uk)
25/01/2013 27
Length ≈ Cost ≈ Sum of length of arcs
Solve this first
Vk(i) = minj [akij + Vk+1(j)]

Value Functions
State - value function for policy :
V (s) E Rt st s E krt k 1 st sk 0
Action - value function for policy :
Q (s, a) E Rt st s, at a E krtk1 st s,at ak0
• The value of a state is the expected return starting from that state; depends on the agent’s policy:
• The value of taking an action in a state under policy is the expected return starting from that state, taking that action, and thereafter following :
25/01/2013 28

Recursive Equation for Value
Rt rt1 rt2 2rt3 3rt4
rt1 rt2 rt3 2rt4 rt1 Rt1
The basic idea:
So: sssVrE
ssREsV
ttt
tt
11
)(
25/01/2013 29

Optimality in MDPs – Bellman Equation
25/01/2013 30

Policy Evaluation
How to compute V(s) for an arbitrary policy ? (Prediction problem)
For a given MDP, this yields a system of simultaneous equations– as many unknowns as states (BIG, |SS| linear system!)
Solve iteratively, with a sequence of value functions,
3/02/2012 31

Policy Improvement
Does it make sense to deviate from (s) at any state (following the policy everywhere else)? Let us for now assume deterministic (s)
- Policy Improvement Theorem [Howard/Blackwell]
3/02/2012 32

Computing Better Policies
Starting with an arbitrary policy, we’d like to approach truly optimal policies. So, we compute new policies using the following,
Are we restricted to deterministic policies? No.With stochastic policies,
3/02/2012 33

Grid-World Example
25/01/2013 34
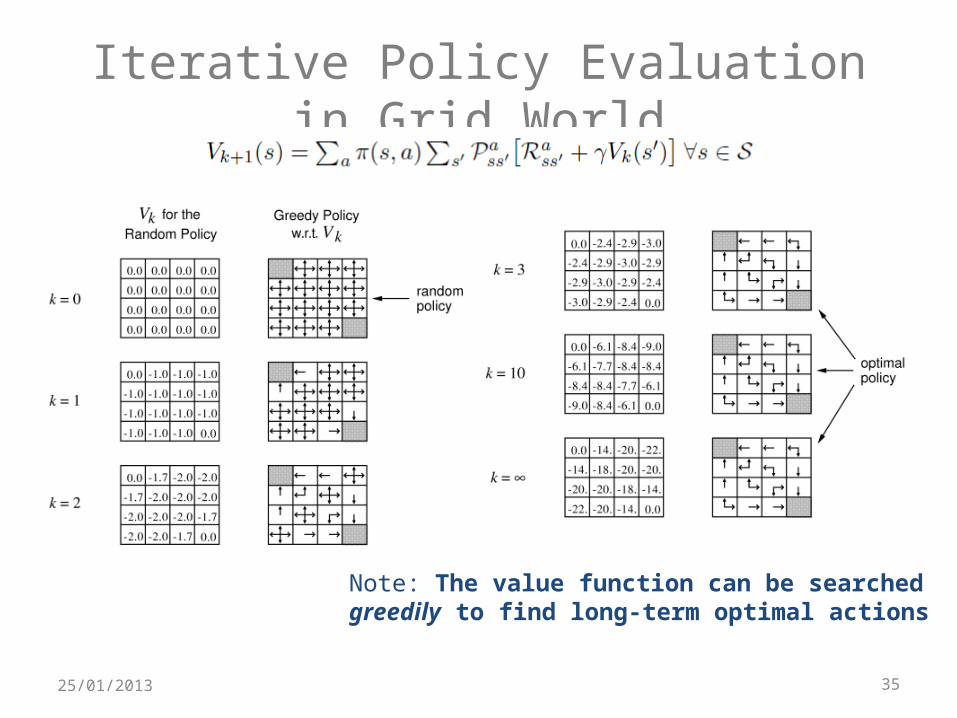
Iterative Policy Evaluation in Grid World
Note: The value function can be searchedgreedily to find long-term optimal actions
25/01/2013 35







