


Deep neural networks have enabled major advances in machine learning and AI
Computer vision
Language translation
Speech recognition
Question answering
And more…
Problem: DNNs are challenging to serve and deploy in large-scale online services
Convolutional Neural Networks
2
ht-1 ht ht+1
xt-1 xt xt+1
ht-1 ht ht+1
yt-1 yt yt+1
Recurrent Neural Networks

DNN Processing Units
EFFICIENCY
3
FLEXIBILITY
Soft DPU(FPGA)
Contro
l Unit
(CU)
Registers
Arithmeti
c Logic
Unit
(ALU)
CPUs GPUsASICsHard
DPU
Cerebras
Google TPU
Graphcore
Groq
Intel Nervana
Movidius
Wave Computing
Etc.
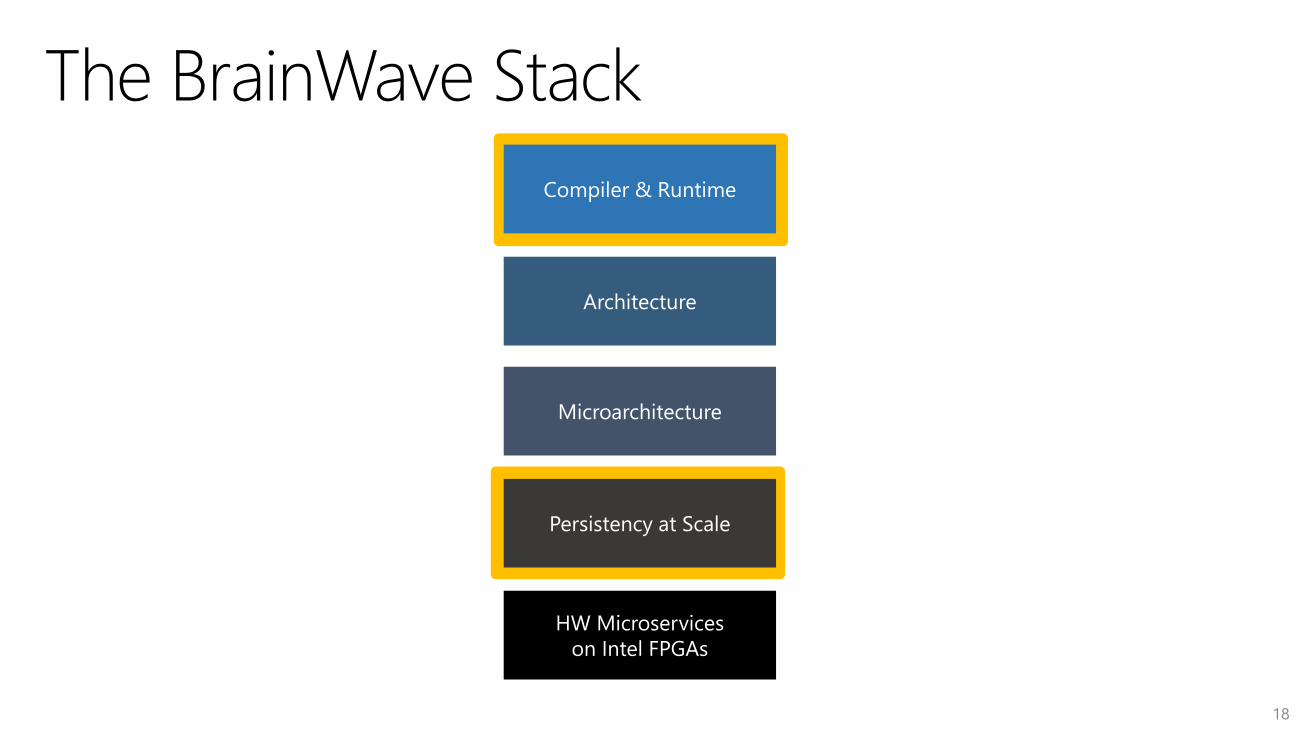
MS BrainWave
Baidu SDA
Deephi Tech
ESE
Teradeep
Etc.

FPGAs ideal for adapting to rapidly evolving ML
CNNs, LSTMs, MLPs, reinforcement learning, feature extraction, decision trees, etc.
Inference-optimized numerical precision
Exploit sparsity, deep compression for larger, faster models
Excellent inference performance at low batch sizes
Ultra-low latency serving on modern DNNs
>10X lower than CPUs and GPUs
Scale to many FPGAs in single DNN service
Performance
Flexibility
Scale
Microsoft has the world’s largest cloud investment in FPGAs
Multiple Exa-Ops of aggregate AI capacity
BrainWave runs on Microsoft’s scale infrastructure
4

F F F
L0
L1
F F F
L0
Pretrained DNN Model
in CNTK, etc.
Scalable DNN Hardware
Microservice
BrainWave
Soft DPU
Instr Decoder
& Control
Neural FU
A Scalable FPGA-powered DNN Serving Platform
5
Network switches
FPGAs
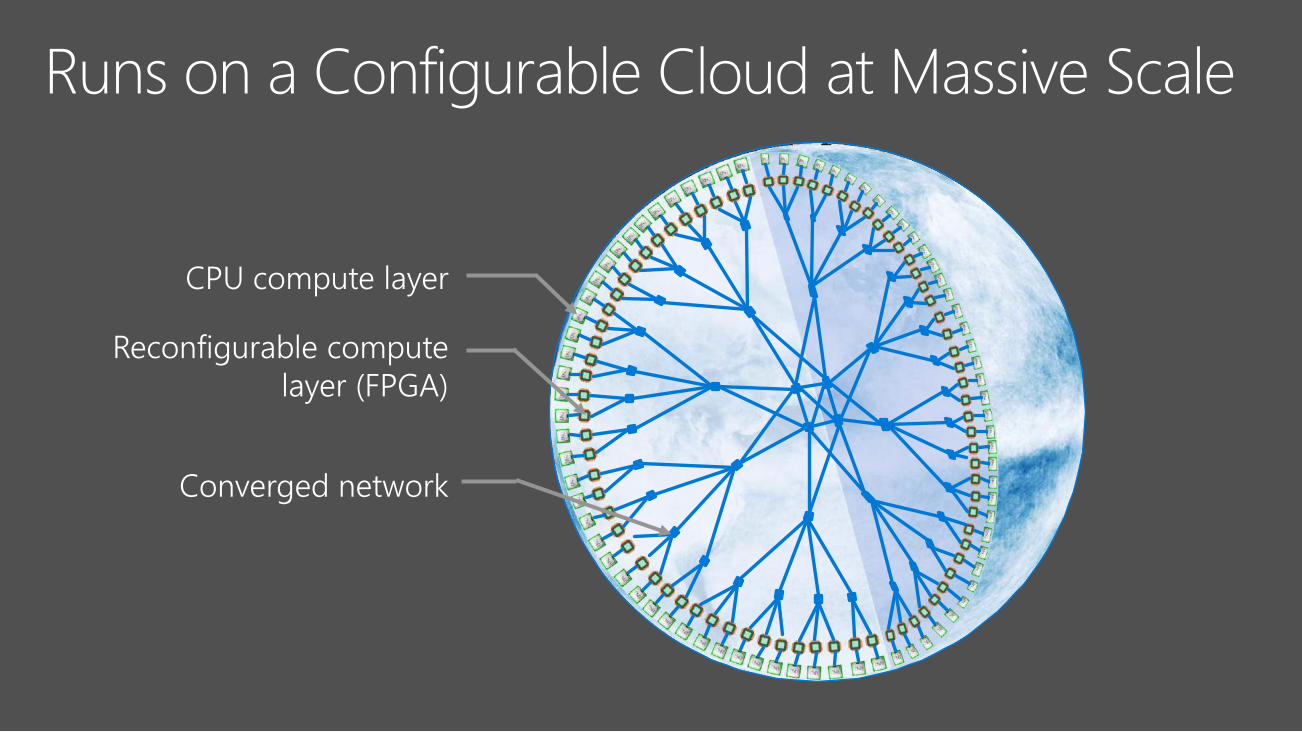
CPU compute layer
Reconfigurable compute
layer (FPGA)
Converged network

Sub-millisecond FPGA compute latencies at batch 1
7

8

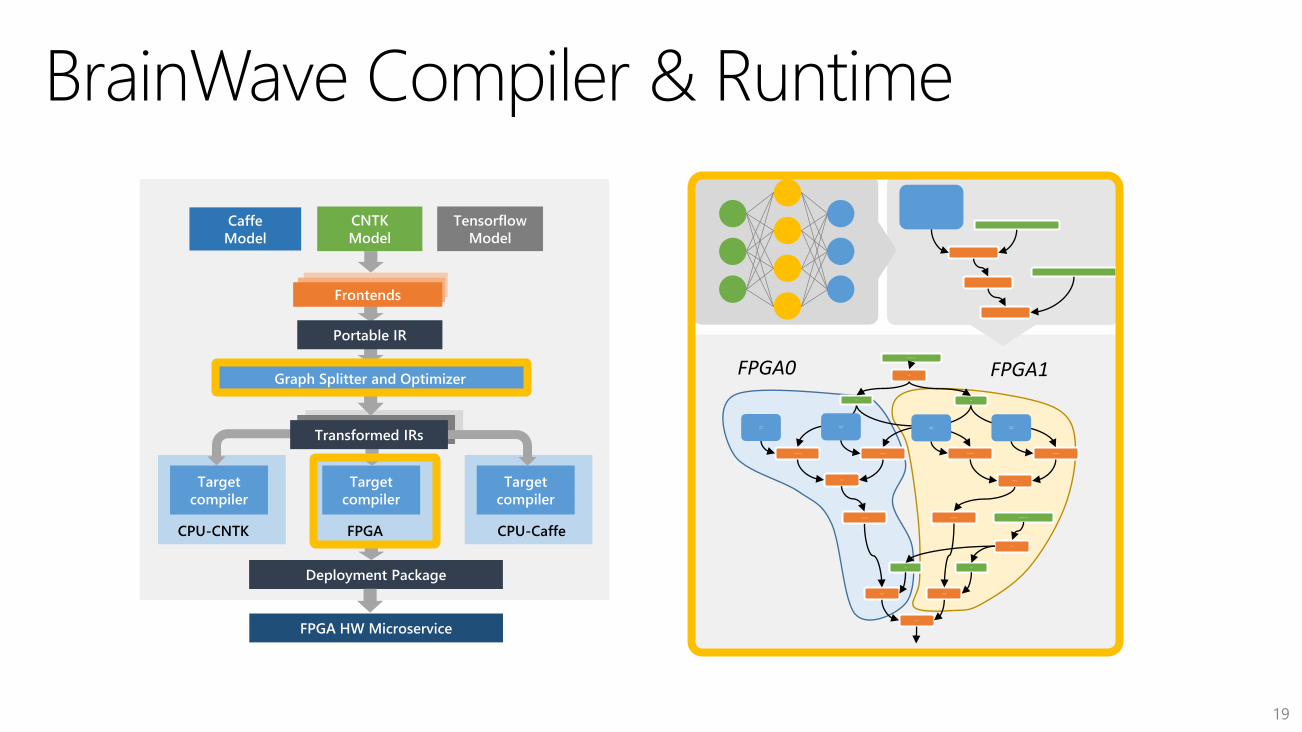
A framework-neutral federated compiler and runtime for
compiling pretrained DNN models to soft DPUs
9

A framework-neutral federated compiler and runtime for
compiling pretrained DNN models to soft DPUs
Adaptive ISA for narrow precision DNN inference
Flexible and extensible to support fast-changing AI algorithms
10

A framework-neutral federated compiler and runtime for
compiling pretrained DNN models to soft DPUs
Adaptive ISA for narrow precision DNN inference
Flexible and extensible to support fast-changing AI algorithms
BrainWave Soft DPU microarchitecture
Highly optimized for narrow precision and low batch
11

A framework-neutral federated compiler and runtime for
compiling pretrained DNN models to soft DPUs
Adaptive ISA for narrow precision DNN inference
Flexible and extensible to support fast-changing AI algorithms
BrainWave Soft DPU microarchitecture
Highly optimized for narrow precision and low batch
Persist model parameters entirely in FPGA on-chip memories
Support large models by scaling across many FPGAs
12

A framework-neutral federated compiler and runtime for
compiling pretrained DNN models to soft DPUs
Adaptive ISA for narrow precision DNN inference
Flexible and extensible to support fast-changing AI algorithms
BrainWave Soft DPU microarchitecture
Highly optimized for narrow precision and low batch
Persist model parameters entirely in FPGA on-chip memories
Support large models by scaling across many FPGAs
Intel FPGAs deployed at scale with HW microservices
[MICRO’16]
13

14

15[ISCA’14, HotChips’14, MICRO’16]

WCS Gen4.1 Blade with NIC and Catapult FPGA
Catapult v2 Mezzanine card
16[ISCA’14, HotChips’14, MICRO’16]
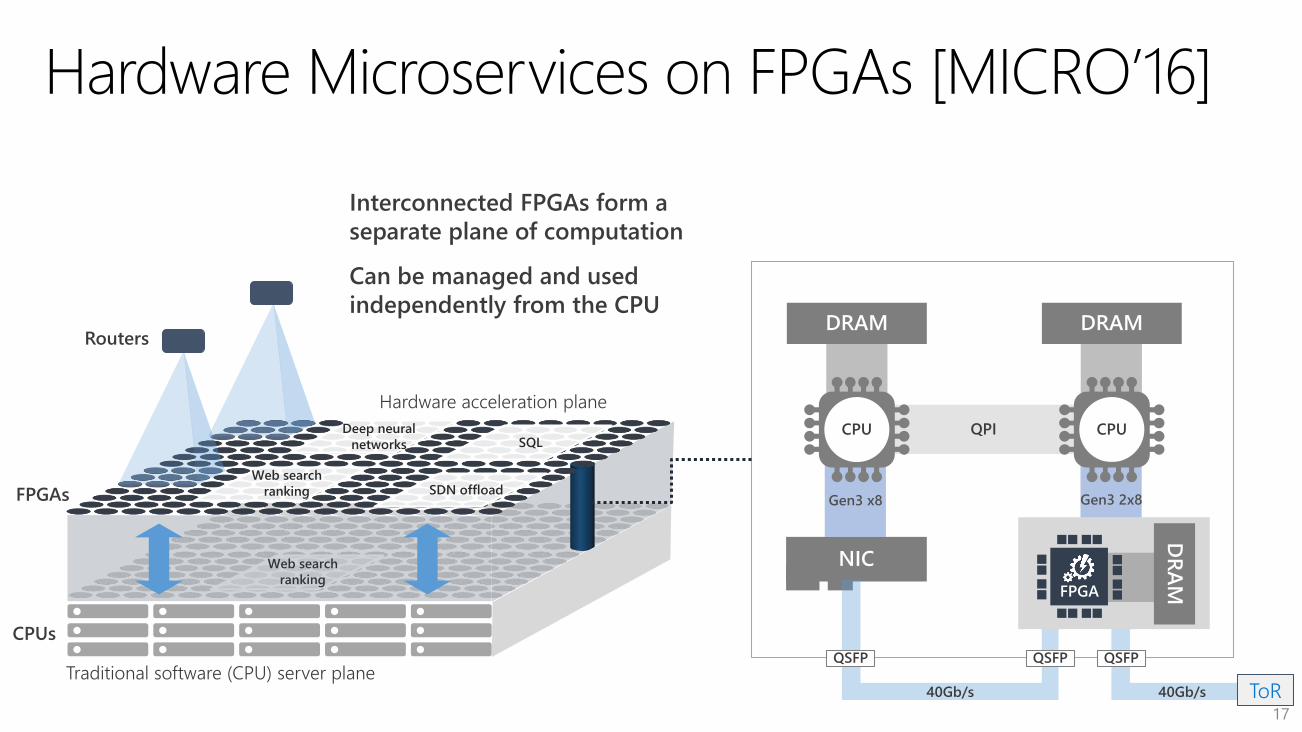
Web search
ranking
Traditional software (CPU) server plane
QPICPU
QSFP
40Gb/s ToR
FPGA
CPU
40Gb/s
QSFP QSFP
Hardware acceleration plane
Interconnected FPGAs form a
separate plane of computation
Can be managed and used
independently from the CPU
Web search
ranking
Deep neural
networks
SDN offload
SQL
17
CPUs
FPGAs
Routers
18
FPGA0 FPGA1
Add500
1000-dim Vector
1000-dim Vector
Split
500x500Matrix
MatMul500
500x500Matrix
MatMul500 MatMul500 MatMul500
500x500Matrix
Add500Add500
Sigmoid500 Sigmoid500
Split
Add500
500 500
Concat
500 500
500x500Matrix
19
Target
compiler
FPGA
Target
compiler
CPU-CNTK
Frontends
Portable IR
Target
compiler
CPU-Caffe
Transformed IRs
Graph Splitter and Optimizer
Deployment Package
Caffe
Model
FPGA HW Microservice
CNTK
Model
Tensorflow
Model

20
=
O(N2) data
O(N2) compute
Input activation
Output pre-activation
N weight kernels
O(N3) data
O(N4K2) compute
=

21
=
O(N2) data
O(N2) compute
Input activation
Output pre-activation
O(N3) data
O(N4K2) compute
=

FPGA2xCPU
Model Parameters
Initialized in DRAM
22

FPGA2xCPU
23
Model Parameters
Initialized in DRAM

Batch Size
Hardware
Utilization
(%)
24
FPGA

Batch Size
Latency
at 99th
Maximum
Allowed
Latency
Batch Size
Hardware
Utilization
(%)
Batching improves HW utilization but increases latency
25

Batch Size
Latency
at 99th
Maximum
Allowed
Latency
Batch Size
Hardware
Utilization
(%)
26
Batching improves HW utilization but increases latency
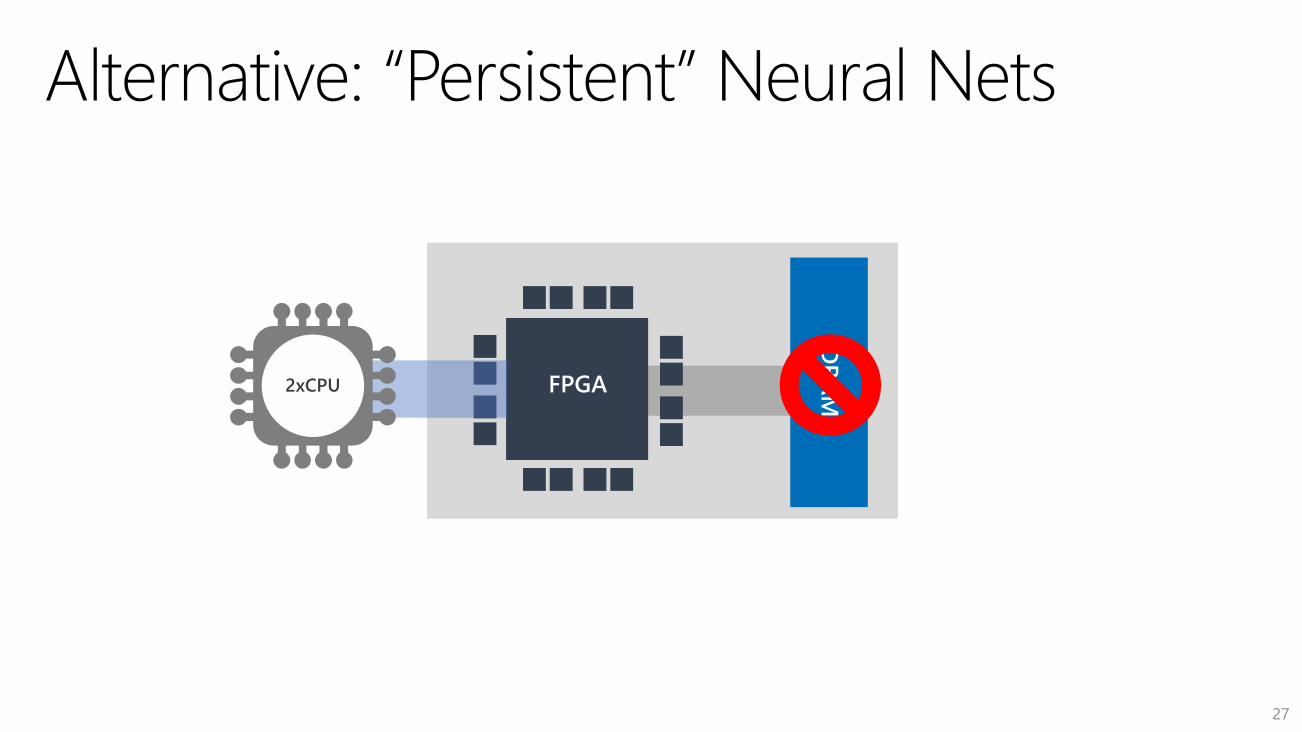
FPGA2xCPU
27

2xCPU
Observations
28

2xCPU
29
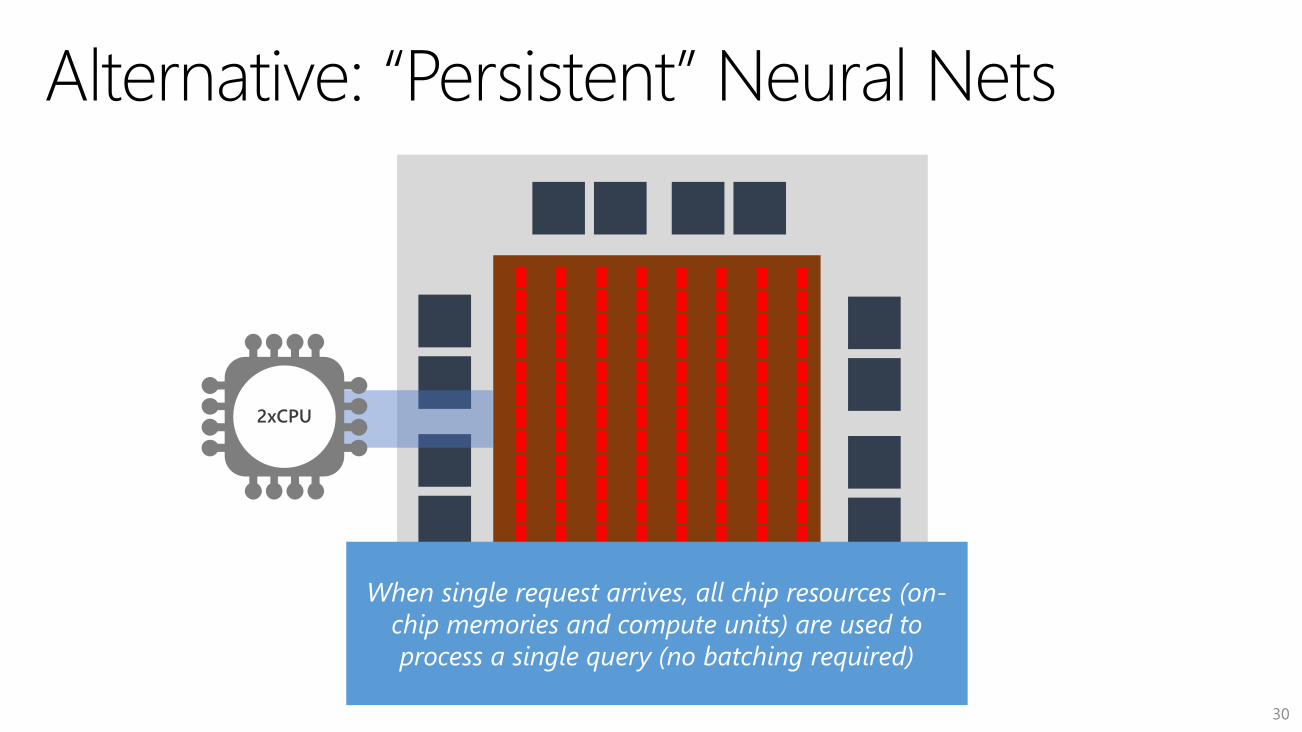
2xCPU
30

31

32

2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
33
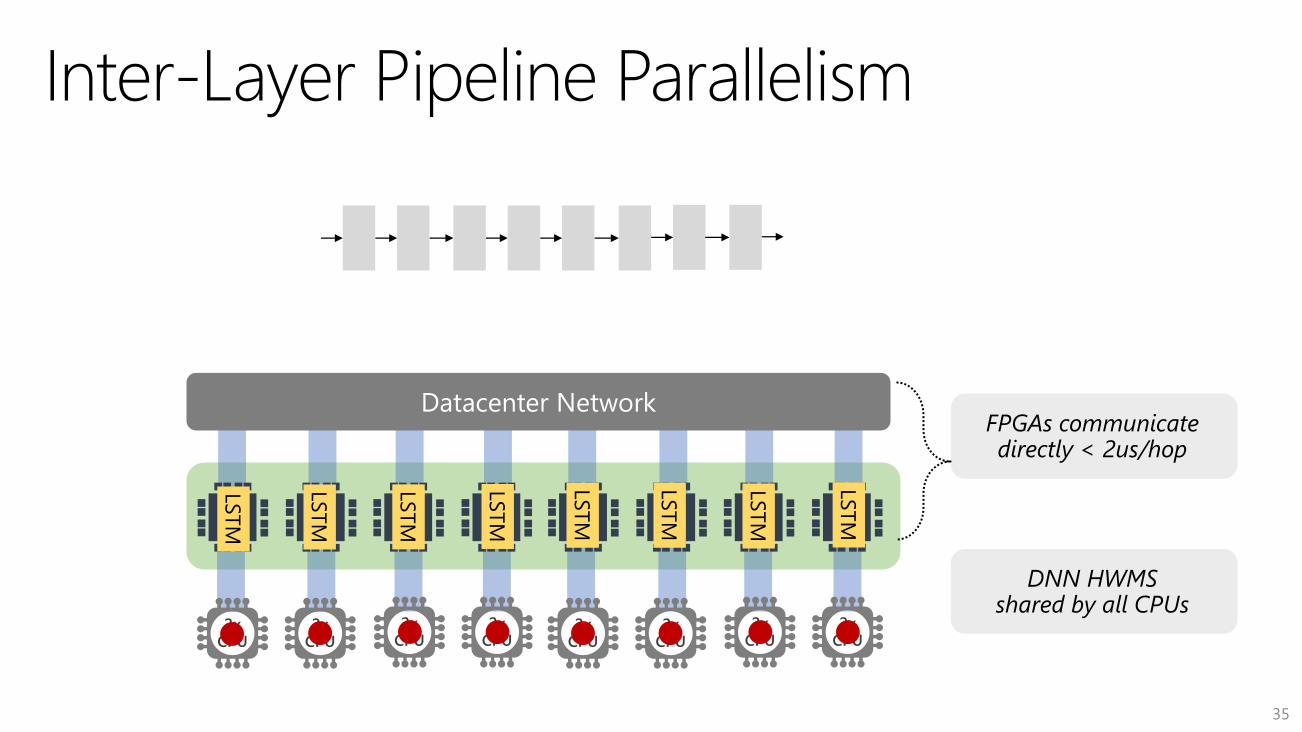
LSTM
LSTM
LSTM
LSTM
LSTM
LSTM
LSTM
LSTM

2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
34
LSTM
LSTM
LSTM
LSTM
LSTM
LSTM
LSTM
LSTM
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
35
LSTM
LSTM
LSTM
LSTM
LSTM
LSTM
LSTM
LSTM
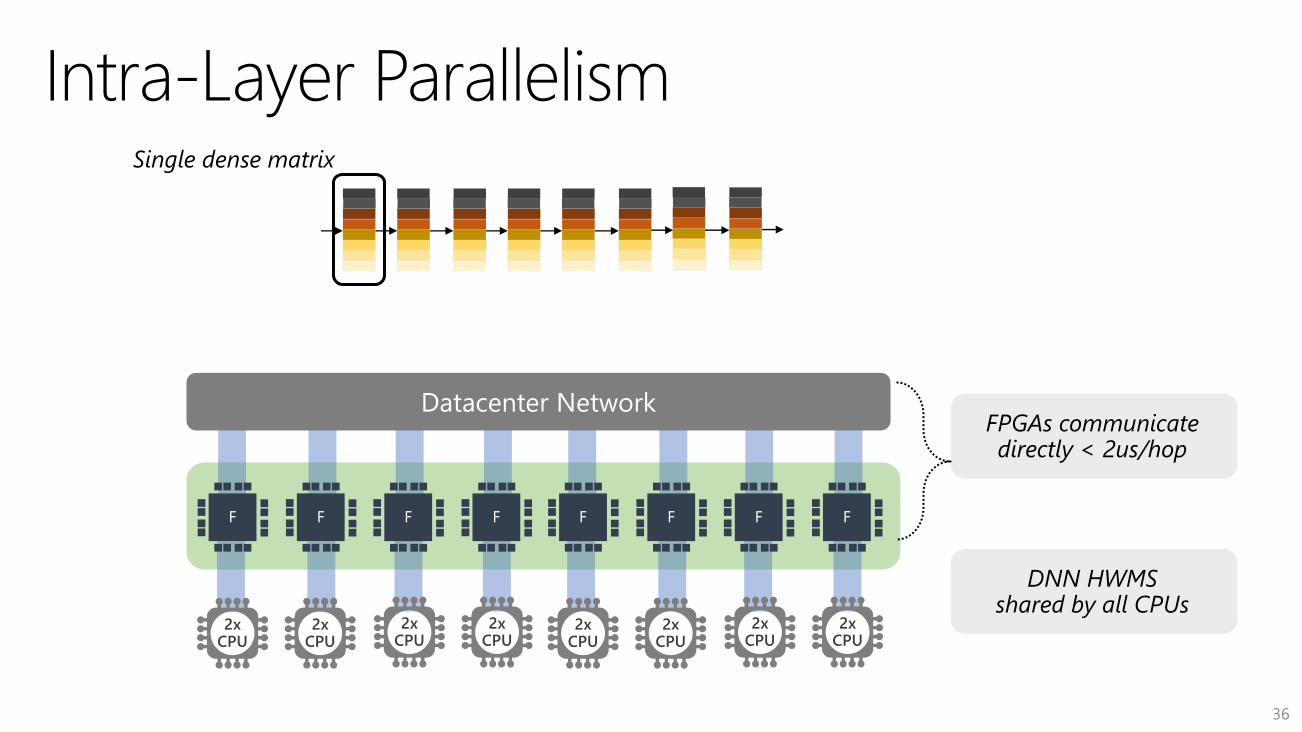
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
36

2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
2xCPU
37

38

Core Features
• Proprietary parameterizable narrow precision
format wrapped in float16 interfaces
FPGA
Matrix
Vector
Unit
39

40
Neural Functional Unit
VRF
Instruction Decoder
TA
TA
TA
TA
TA
Matrix-Vector Unit Convert to msft-fp
Convert to float16
MultifunctionUnit
xbar x
A
+ VRF
VRF
MultifunctionUnit
xbar x
+ VRF
VRF
Tensor Manager
Matrix Memory Manager
Vector Memory Manager
DRAM
x
A
+
Activation
Multiply
Add/Sub
Legend
Memory
Tensor data
Instructions
Commands
TA Tensor Arbiter
Input Message Processor
Control Processor
Output Message Processor
A
Kernel
Matrix Vector Multiply
VRFMatrix RF
+
Kernel
Matrix Vector Multiply
VRFMatrix RF
Kernel
Matrix Vector Multiply
VRFMatrix RF
Net
wo
rk IF
C
...

Features Matrix Row 1
Matrix Row 2
Matrix Row N
Float16 Input
Tensor
+
+
×
×+
×
×+
+
×
×+
×
×+
41
Float16 Output
Tensor

FPGA MVU Kernel
42
+
+
×
×+
×
×+
+
×
×+
×
×+

43
1.4
2.0
2.7
4.5
0.0
1.0
2.0
3.0
4.0
5.0
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz

1.4
2.0
2.7
4.5
0.0
1.0
2.0
3.0
4.0
5.0
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
44
0
10
20
30
40
50
60
70
80
90
100
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
Stratix 10 280 @ 500MHz

1.4
2.0
2.7
4.5
0.0
1.0
2.0
3.0
4.0
5.0
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
45
12
0
10
20
30
40
50
60
70
80
90
100
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
Stratix 10 280 @ 500MHz
1.4
2.0
2.7
4.5
0.0
1.0
2.0
3.0
4.0
5.0
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
46
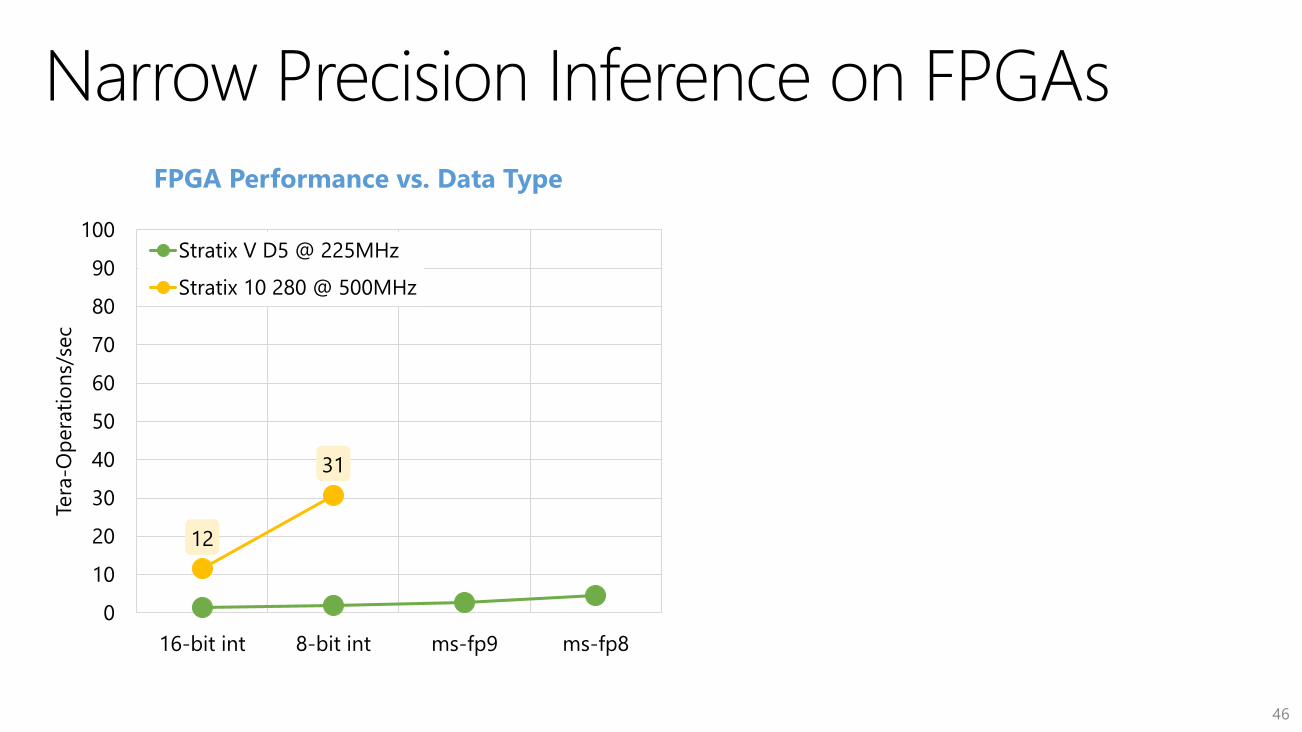
12
31
0
10
20
30
40
50
60
70
80
90
100
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
Stratix 10 280 @ 500MHz

1.4
2.0
2.7
4.5
0.0
1.0
2.0
3.0
4.0
5.0
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
47
12
31
65
0
10
20
30
40
50
60
70
80
90
100
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
Stratix 10 280 @ 500MHz
1.4
2.0
2.7
4.5
0.0
1.0
2.0
3.0
4.0
5.0
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
48
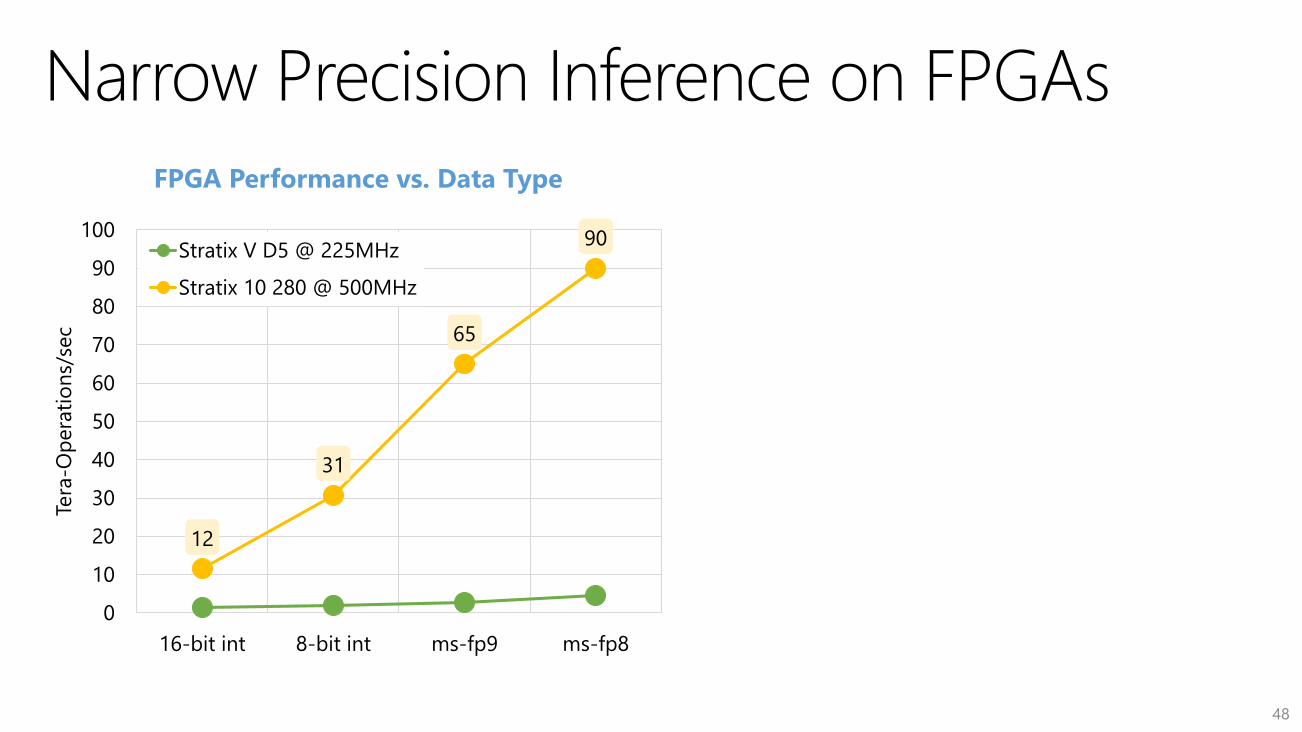
12
31
65
90
0
10
20
30
40
50
60
70
80
90
100
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
Stratix 10 280 @ 500MHz
1.4
2.0
2.7
4.5
0.0
1.0
2.0
3.0
4.0
5.0
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
49
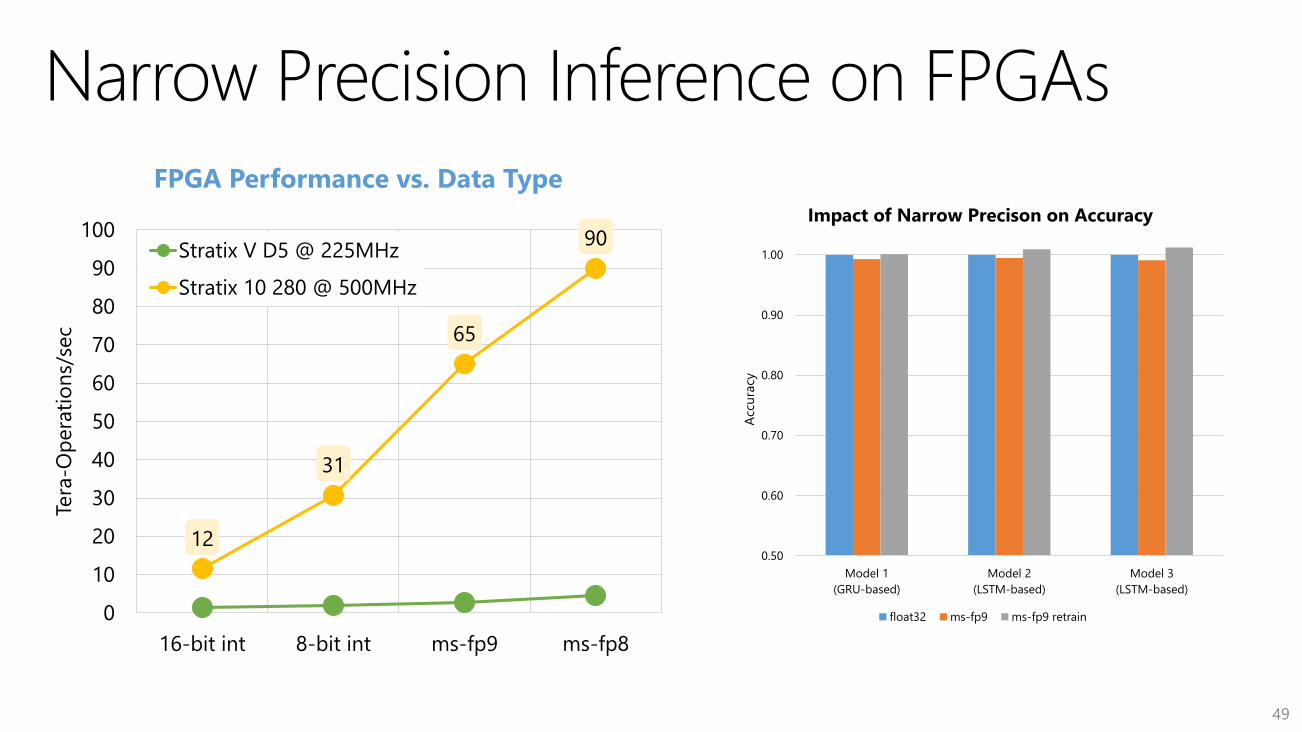
12
31
65
90
0
10
20
30
40
50
60
70
80
90
100
16-bit int 8-bit int ms-fp9 ms-fp8
Tera
-Op
era
tio
ns/
sec
FPGA Performance vs. Data Type
Stratix V D5 @ 225MHz
Stratix 10 280 @ 500MHz
0.50
0.60
0.70
0.80
0.90
1.00
Model 1
(GRU-based)
Model 2
(LSTM-based)
Model 3
(LSTM-based)
Acc
ura
cy
Impact of Narrow Precison on Accuracy
float32 ms-fp9 ms-fp9 retrain

15T
40T
65T
90T
0
10
20
30
40
50
60
70
80
90
100
Arria 10 1150
ms-fp9
Stratix 10 280
Early Silicon
ms-fp9
Stratix 10 280
Production Silicon
ms-fp9
Stratix 10 280
Production Silicon
ms-fp8
Peak T
hro
ug
hp
ut
(Tera
-Op
era
tio
ns/
sec)
Single FPGA BrainWave Soft DPU Performance
50
Arria 10 1150 (20nm)
ms-fp9
316K ALMs (74%)
1442 DSPs (95%)
2,564 M20Ks (95%)
160 GOPS/W
Stratix 10 280 Early Silicon (14nm)
ms-fp9
858K ALMs (92%)
5,760 DSPs (100%)
8,151 M20Ks (70%)
320 GOPS/W 720 GOPS/W (production)

Stay tuned for
announcements about
external availability.
Microsoft BrainWave is a powerful platform for an accelerated AI cloud
Runs on Microsoft’s hyperscale infrastructure with FPGAs
Achieves excellent performance at low batch sizes via persistency and narrow precision
Adaptable to precision and changes in future AI algorithms
BrainWave running on Hardware Microservices will push the boundary of what is possible to deploy in the cloud
Deeper/larger CNNs for more accurate computer vision
Higher dimensional RNNs toward human-like natural language processing
State-of-the-art speech
And much more…

52







