

Feasibility of learning: the issuessolution for infinite hypothesis setsVC generalization bound (mostly lecture 5 on AMLbook.com)

The issues in learning feasibility
In the absence of noise in training data, we can be confident that the answer to issue #2 is yes
Chapter 2 of text (theory of generalization) is about issue #1
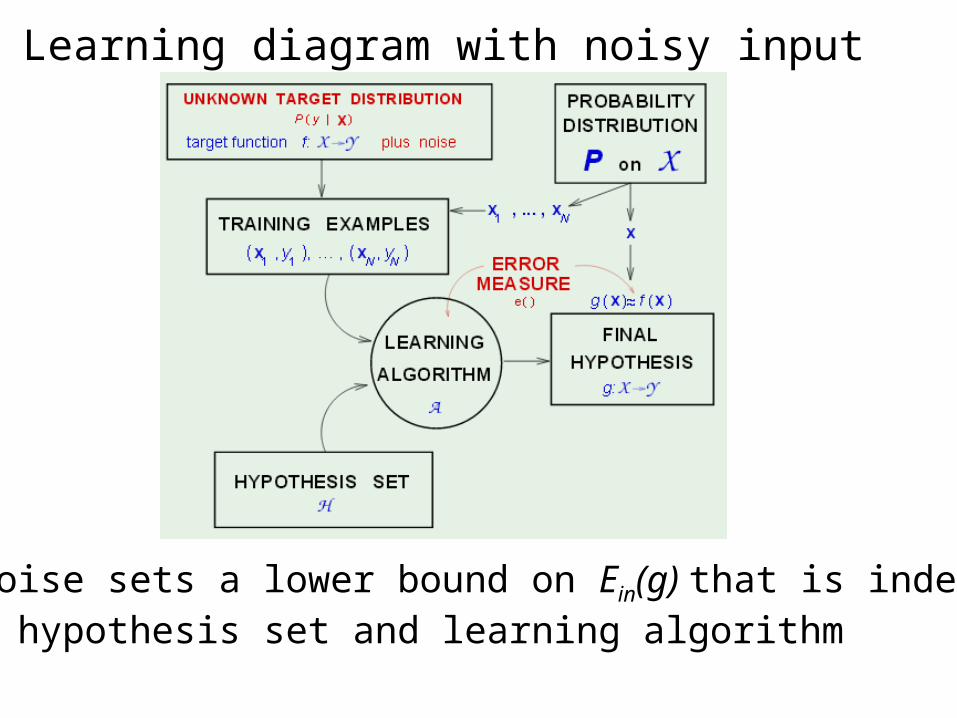
Learning diagram with noisy input
Input noise sets a lower bound on Ein(g) that is independent of both hypothesis set and learning algorithm

When noise is present, issues are coupled
Since we don’t know the lower bound on Ein(g) due to noise, reducing Ein(g) eventually becomes fitting the noise.
When we fit noise in the data Eout(g) diverges from Ein(g).Chapter 4 of text discusses this “over-fitting” problem

Hoeffding inequality says that for any selected confidence level 1-d, we can make Eout close to Etest by increasing N
By application of “union bound” we showed that the same is true for Etrain if the hypothesis set is finite

Infinite hypothesis sets operate on finite datasets
Let h be a member of an infinite hypothesis set used to train a dichotomizer.
For ever example in the training set (size N), h will predict +1 or -1
The collection of these predictions is a dichotomy (i.e division of the training set into 2 classes)
Define |H( x1, x2, … xN)| as the number of dichotomies that members of the hypothesis set H can produce for a training set of size N
Even though |H| is infinite |H( x1, x2, … xN)| < 2N, the total number of distinct dichotomies that can be produced by N prediction of +1
Hence there must be redundancy in predictions by members of H

Dichotomizier example illustrates how poor the union bound can be as an approximation to the probability of disjoint events
Since the effect on a training set of different hypotheses can be nearly the same, even identical, an alternative to the union bound is needed.

Growth function of hypothesis set H applied to training sets of size N to learn dichotomizers is the maximum number of dichotomies that can be generated by H on any set of N points in the attribute space.
mH(N) = max(|H( x1, x2, … xN)|) < 2N
Replace the union bound by a bound on the “growth function”

9Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)
Growth function mH(N) is closely related the VC dimension of H defined by:
“If there exists h Î H consistent for all 2N ways that N points can be labeled with {+1,-1} then VC(H ) = N.” We say “H can shatter N points” In terms of mH(N), dvc(H) can be defined as the largest value of N for which mH(N) = 2N

If no dataset of size k can be shattered by H, then k is a “break point” of H
If k is a break point of H, then mH(k) < 2k
Since dvc(H) can be defined as the largest value of N for which mH(N) = 2N, k= dvc(H)+1 is a break point
Break points

Review: H= 2D perceptronmH(3) = 8: no break point. Even though 3 points in line cannot be shattered, mH(3) defined as max dichotomiesfor any set of points
Every set of 4 points has 2 labeling that cannot be shattered by the 2D perceptron. k=4 is a break point. dvc(H)=3For dD perceptron dvc(H)=d+1 (see lecture 7 amlbook.com)

H = positive rays: h(x) = sign(x-a)
Hypothesis set is infinite (unlimited choices for a)
N points can divide a line into at most N+1 intervals.(If some points overlap, number will be fewer)
Each choice of the interval containing a is a dichotomy; therefore mH(N) = N+1

H = positive rays: h(x) = sign(x-a)
mH(N) = N+1mH(2) = 3 < 2k
dvc(H) = 1

H = positive internals: h(x) = +1 for all x in interval, otherwise h(x) = -1
Dichotomy depends on which of N+1 intervals endpoints fall in. If same, all samples are -1.
mH(N) = 1 + combination N+1 objects, choose 2 mH(N) = 0.5(N2 + N) +1

H = positive internals: h(x) = +1 for all x in interval, otherwise h(x) = -1
mH(N) = 0.5(N2 + N) +1mH(3) = 7 < 2k
dvc(H) = 2

1-k
1i i
N)N(Hm
Bottom line on bounding the growth function: Theorem 2.4 text p49If H has break-point k on data set size N then
k= dvc(H)+1 is a break point
VCd
1i i
N)N(Hm
which is a polynomial of degree dVC
1N)N( vcd HmBy induction can show that

Main result on learning feasibility
Existence of any break point ensures learning feasibility

From Hoeffding inequality to VC inequality

VC generalization bound
If mH(2N) is a polynomial of degree dVC then for large N W->sqrt(cln(N)/N) where c is proportional to dVC

Review: For a specific hypothesis h, Eout(h) is analogous to the population mean. Ein(h) is analogous to a sample mean
Why is this analogy not sufficient to show the feasibility of learning?

In this expression, what is the bound and what is the confidence level.
Review: By analogy with estimation of population means, when Ein = Etest

is a relationship between test-set size, N,confidence level, 1-d, and a bound on |Etest - Eout| How do we use it to find the bound for a given confidence level and test-set size?
How do we use it to find the test-set size need for given bound for a given level?
Review: When Ein = Etest

Review: How does a finite VC dimension of hypothesis set H ensure the feasibility of learning with H?
1) Replace the union bound (valid for finite H-sets) with growth function (valid of infinite H-sets)

Review: How does a finite VC dimension of hypothesis set H ensure the feasibility of learning with H?
1) Replace the union bound (valid for finite H-sets) with growth function (valid of infinite H-sets).
2) If H-set applied to a training set of size N has any break point, then growth function is a polynomial in N

Review: How does a finite VC dimension of hypothesis set H ensure the feasibility of learning with H?
1) Replace the union bound (valid for finite H-sets) with growth function (valid of infinite H-sets).
2) If H-set applied to a training set of size N has any break point, then growth function is a polynomial in N
3) k= dvc(H)+1 is a break point. 1N)N( vcd Hm

4) Since polynomials are dominated by exponentials,
d can be make arbitrarily small, regardless of the size of e, by increasing the size of N

Feasible, yes. Practical, maybe notSuppose we want e < 0.1 with 90% confidence (i.e. d = 0.1)
N
)/)2(4ln(8 NmH
)/)1ln((4(2N)8
N vcd2
1N)N( vcd Hm
We require
using
We get
Part 3 of assignment 3: Use a non-linear root-finding code to solve this implicit relationship for N with dVC=3 and 6.Compare with results in text p57.

Assignment 3 due 9-30-141) Make a table of the bounds that can be placed on the relative error in estimates of population mean m=1 based on a sample with N=100 at confidence levels 90%, 95%, and 99%
2) |Etest - Eout|< e(d,N) = sqrt(ln(2/d)/2N) Sponsor requires 98% confidence that e(d,N)=0.1. How large does N have to be to achieve this?
3) Use a non-linear root-finding code to solve this implicit relationship for N when e=0.1 and d=0.1 with dVC=3 and 6. Compare with results in text p57. Hint:
)/)1ln((4(2N)8
N vcd2
14(2N) vcd

While Hoeffding inequality for a test set (M=1) is useful in practice,
VC inequality is too conservative for practical use; nevertheless, important for showing learning feasibility.
![Learning theory: generalization and VC dimensionyifengt/courses/machine-learning/slides/lecture5... · [Slide from Eric Xing] Prototypical concept learning task oBinary classification](https://static.documents.pub/doc/80x56/5ff15fb164eb0874931f20c6/learning-theory-generalization-and-vc-yifengtcoursesmachine-learningslideslecture5.jpg)






