

From the Benchtop to the DatacenterHPC Requirements in Life Science Research
1
HPC User Forum 2015; Norfolk, VA.

Ari E. Berman, Ph.D.
Who am I?
2
General Manager of Government Services at BioTeam
I’m a fallen scientist - Ph.D. Molecular Biology, Neuroscience, Bioinformatics
I’m an HPC/Infrastructure geek - 17 years
I help enable science!

3
BioTeam
‣ Independent consulting shop
‣ Staffed by scientists forced to learn IT, SW & HPC to get our own research done
‣ Infrastructure, Informatics, Software Development, Cross-disciplinary Assessments
‣ 13+ years bridging the “gap” between science, IT & high performance computing
‣ Our wide-ranging work is what gets us invited to speak at events like this ...

What do we do?BioTeam
4
Laboratory Knowledge

What do we do?BioTeam
4
Laboratory Knowledge
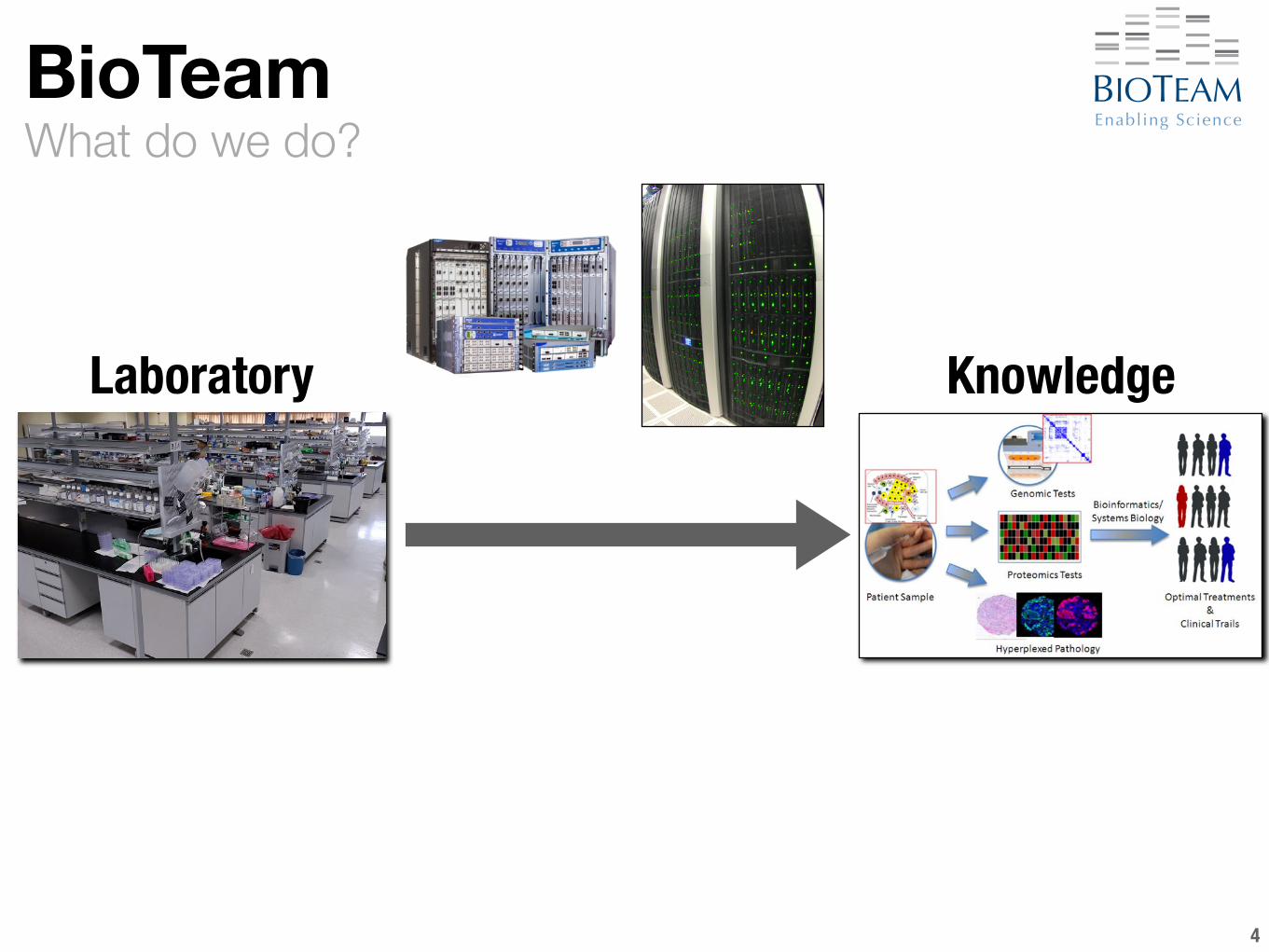
What do we do?BioTeam
4
Laboratory Knowledge
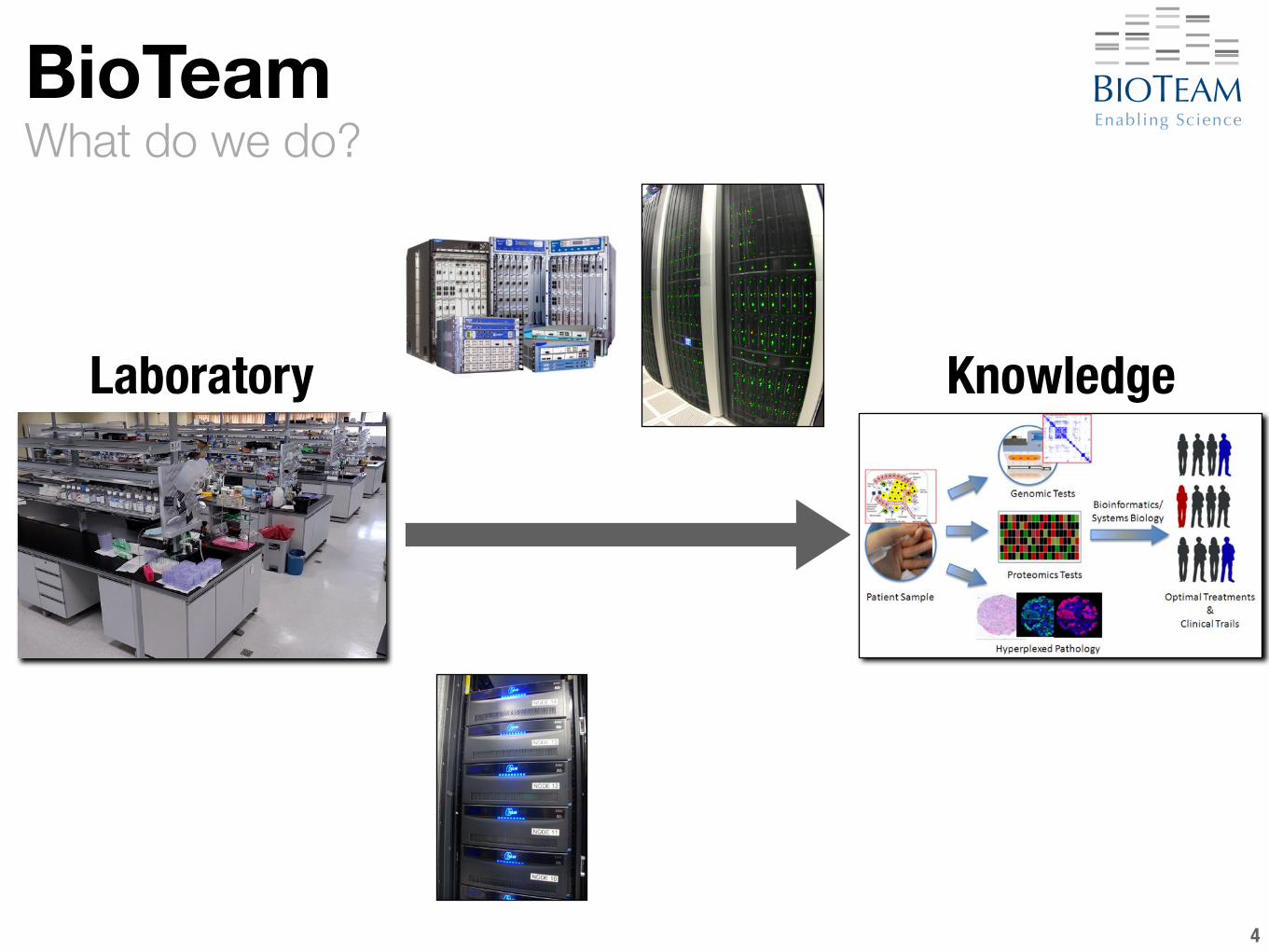
What do we do?BioTeam
4
Laboratory Knowledge

What do we do?BioTeam
4
Laboratory Knowledge

What do we do?BioTeam
4
Laboratory Knowledge

What do we do?BioTeam
4
Laboratory Knowledge
Converged Solution

What do we do?BioTeam
4
Laboratory Knowledge
Converged Solution

5
OK, so why am I here talking to you?

We have a unique perspective across much of life sciences
We’ve noticed a few things
‣ Big Data has arrived in Life Sciences
‣ Data is being generated at unprecedented rates
‣ Research and Biomedical Orgs were caught off guard
‣ IT running to catch up, limited budgets
‣ Money is tight, Orgs reluctant to invest in Bio-IT
6
25% of all Life Scientists will require HPC in 2015!

It’s being made harder by lack of support and infrastructure that works for them
Research is hard
‣ Scientists are getting frustrated
‣ Stubborn, fight for what they need
‣ They will build a cluster under their desk if it gets the job done
‣ In general they will win against IT, eventually
7

8
It’s a risky time to be doing HPC for life science

9
Big Picture / Meta Issue
‣ HUGE revolution in the rate at which lab platforms are being redesigned, improved & refreshed
‣ IT not a part of the conversation, running to catch up

Science progressing way faster than IT can refresh/change
The Central Problem Is ...
‣ Instrumentation & protocols are changing FAR FASTER than we can refresh our Research-IT & Scientific Computing infrastructure
• Bench science is changing month-to-month ... • ... while our IT infrastructure only gets refreshed every
2-7 years
‣ We have to design systems TODAY that can support unknown research requirements & workflows over many years (gulp ...)
10

11
The new normal for informatics

If IT gets it wrong ...
‣ Lost opportunity
‣ Missing capability
‣ Frustrated & very vocal scientific staff
‣ Problems in recruiting, retention, publication & product development
12

13
It’s a risky time to be doing Bio-IT
11
What are the drivers in Bio-IT today?

14
Genomics: Next Generation Sequencing (NGS)

It’s like the hard drive of life
15
The big deal about DNA
‣ DNA is the template of life
‣ DNA is read --> RNA
‣ RNA is read --> Proteins
‣ Proteins are the functional machinery that make life possible
‣ Understanding the template = understanding basis for disease

Sequencing by SynthesisHow does NGS work?
16

Reference assembly, variant callingHow does NGS work?
17

Reference assembly, variant callingHow does NGS work?
17

Reference assembly, variant callingHow does NGS work?
17

Gateway to personalized medicineThe Human Genome
‣ 3.2 Gbp
‣ 23 chromosomes
‣ ~21,000 genes
‣ Over 55M known variations
18

...and why NGS is the primary driver
19
The Problem...
‣ Sequencers are now relatively cheap and fast
‣ Some can generate a human genome in 18 hours, for $2,000
‣ Everyone is doing it
‣ Can generate 3TB of data in that time
‣ First genome took 13 years and $2.7B to complete

20
Other Methodologies Not Far Behind

High-throughput Imaging
‣ Robotics screening millions of compounds on live cells 24/7 • Not as much data as genomics in
volume, but just as complex • Data volumes in the 10’s TB/week
‣ Confocal Imaging • Scanning 100’s of tissue sections/
week, each with 10’s of scans, each with 20-40 layers and multiple florescent channels
• Data volumes in the 1’s - 10’s TB/week
21

High-power, dense detector MRI scanners in use 24/7 at large research hospitals
High-res medical imaging
‣ Creating 3D models of brains, comparing large datasets
‣ Using those models to perform detailed neurosurgery with real-time analytic feedback from supercomputer in the OR (cool stuff)
‣ Also generates 10’s of TB/week
22

23
This is a huge problem
‣ Causing a literal deluge of data, in the 10’s of Petabytes
‣ NIH generating 1.5PB of data/month
‣ First real case in life science where 100Gb networking might really be needed
‣ But, not enough storage or compute

24
But wait! There’s more!

We have them allFile & Data Types
‣ Massive text files
‣ Massive binary files
‣ Flatfile ‘databases’
‣ Spreadsheets everywhere
‣ Directories w/ 6 million files
‣ Large files: 600GB+
‣ Small files: 30kb or smaller25

Application characteristics
‣ Mostly SMP/threaded apps performance bound by IO and/or RAM
‣ Hundreds of apps, codes & toolkits
‣ 1TB - 2TB RAM “High Memory” applications (large graphs, genomic assembly)
‣ Lots of Perl/Python/R
‣ MPI is rare • Well written MPI is even rarer
‣ Few MPI apps actually benefit from expensive low-latency interconnects* • *Chemistry, modeling and structure work is
the exception
26

Up to a two line subtitle, generally used to describe the takeaway for the slide
27
HPC in Life Sciences

Don’t just build for performanceBuild for the Use Case!
‣ Building for performance is short-sighted
‣ System needs to solve problems, not create more for scientists
‣ Fun to engineer for speed, but not terribly useful in LifeSci
‣ That means: take the time to understand the use cases, and design to that. Way more fun in the long-term
28

If you have it, they will break itLife Scientists: Thugs of HPC
‣ Every kind of file you can imagine
‣ Every kind of algorithm (good, bad, ugly)
‣ Want it all, right now
‣ They keep everything
‣ Don’t want to pay for it
‣ Your health might depend on it (seriously!)
29

Compute related design patterns largely static
30
Core Compute
‣ Linux compute clusters are the baseline compute platform
‣ Mostly commodity server based - not a ton of capability SC in this space
‣ Need for capability SC is growing though - life sciences catching up
‣ Even our lab instruments know how to submit jobs to common HPC cluster schedulers

Power is the new commodityCore Compute
‣ Power efficiency is becoming a requirement as 0.5 - 1PF+ becomes commonplace (30,000+ cores)
‣ High core density in multi-server racks is key
‣ Better distribution of power
‣ Custom chassis with extreme densities are the best at power efficiency
31

New and refreshed HPC systems running many node types
Compute: Diversity in node types
‣ HPC compute resources no longer homogenous; many types and flavors now deployed in single HPC stacks
‣ Newer clusters mix-and-match to match the known use cases: • ‘Fat’ nodes with many CPU cores • ‘Thin’ nodes with super-fast CPUs • Large memory nodes (1TB - 3TB) • GPU nodes for compute and visualization • Co-processor nodes (Xeon Phi, FPGA) • Analytic nodes with SSD, FusionIO, flash
or large local disk for ‘big data’ tasks
32

New and refreshed HPC systems running many node types
Compute: Diversity in node types
‣ HPC compute resources no longer homogenous; many types and flavors now deployed in single HPC stacks
‣ Newer clusters mix-and-match to match the known use cases: • ‘Fat’ nodes with many CPU cores • ‘Thin’ nodes with super-fast CPUs • Large memory nodes (1TB - 3TB) • GPU nodes for compute and visualization • Co-processor nodes (Xeon Phi, FPGA) • Analytic nodes with SSD, FusionIO, flash
or large local disk for ‘big data’ tasks
32

New and refreshed HPC systems running many node types
Compute: Diversity in node types
‣ HPC compute resources no longer homogenous; many types and flavors now deployed in single HPC stacks
‣ Newer clusters mix-and-match to match the known use cases: • ‘Fat’ nodes with many CPU cores • ‘Thin’ nodes with super-fast CPUs • Large memory nodes (1TB - 3TB) • GPU nodes for compute and visualization • Co-processor nodes (Xeon Phi, FPGA) • Analytic nodes with SSD, FusionIO, flash
or large local disk for ‘big data’ tasks
32

Storage & Data Management
‣ Storage and network are the biggest headaches in life sciences
‣ Require connectivity to HPC, labs, and externally for data sharing
‣ Needs to be scalable: Life Sciences now well into petascale
‣ Starting to need performance, especially with medium - large HPC
33

Storage & Data Management‣ LifeSci code very I/O-bound
• Huge number of r/w calls per second • CPU utilization may be low - most of
the operations are data wrangling from disk
• Load average will be through the roof • More than a few of these will bring your
storage to its knees
‣ IOPS are critical in 2015
‣ Throughput per core: 100MB/s, ideally (1 TB/s for 10k cores!) • Not at all realistic! Lucky to get 10MB/s
on sizable systems34

35
Storage & Data Management‣ NAS = “easiest” option
• Scale Out NAS products are the mainstream standard
• Don’t deliver performance to cores
‣ Parallel & Distributed storage becoming more standard in LifeSci • GPFS: major proportion in market • Lustre: gaining ground, but worse than
GPFS with small files • Global buffers: reordering random IO • IOP Tiers: Millions of IOPS as scratch • Object stores! • Local SSDs for scratch

1Gb and 10Gb are not going to cut it with these requirements
Cluster Networking
‣ Building for IO requires very high-performance network
‣ Infiniband FDR/EDR
‣ Eliminating traditional ethernet: many benefits • High-speed network, much lower
cost (56Gb+) • IP can work with ipoverib (lose some
performance, but with LifeSci, that’s OK)
• Whole cluster can work for all job types, good IPC for simulations, etc
36

Fat tree: Scalable TopologyCluster Networking
‣ Can be built with expansion in mind: no recabling
‣ Possible to have non-blocking network; cost savings at 2:1 blocking
‣ Can build in gateways that talk IP outside the network; Mellanox VPI makes this easier
‣ Can hang data transfer nodes (DTN) off of them, use as fast data transfer point
‣ Storage at the root37

Why go to all this trouble? 10Gb is fine!Cluster Networking
‣ This is true, for now, especially in Life Sciences
‣ Faster than 10Gb doesn’t really help most bad bioinformatics code units own; but at scale, things get messy
‣ Landscape is changing: code is being optimized, datasets are still increasing in size exponentially, lab tech developing at a rate that is off the scale
‣ Have to build for the unpredictable! (Scary)38

DRMs, OS’s, and Protocols, Oh My!Software stack
‣ Distributed Resource Managers: • Still see a ton of SGE/OGS out
there • Giving away to Univa pretty
quickly: very rich feature set • slurm has a growing following,
especially with SchedMD • Torque/maui & Moab • Even still see some PBS Pro and
LSF - but rare
39

DRMs, OS’s, and Protocols, Oh My!Software stack
‣ Key Features in 2015 ‣ Resource mapping (cgroups);
map GPU to CPU ‣ Core-based scheduling ‣ Rich resource management:
threads, memory, accelerators, mixed environments
‣ Metascheduling (hybrid environments)
‣ Application aware scheduling40

DRMs, OS’s, and Protocols, Oh My!Software stack
‣ Big Data analytic frameworks ‣ Hadoop - slow to adopt, lots of
talk, very little walk: not dedicated instances - tends to live on core storage (schedulable)
‣ Database stacks: MySQL still most popular, Oracle still lives
‣ mongoDB is gaining popularity in code, but more for the savvy
‣ Heard some talk of Neo4j, but haven’t seen it in the wild
41

Networking to/from Cluster
‣ May surpass storage as our #1 infrastructure headache
‣ Why? • Petascale storage meaningless if
you can’t access/move it • Enterprise network security
usually inhibits research data flow • 10-Gig, 40-Gig and 100-Gig
networking will force significant changes elsewhere in the ‘bio-IT’ infrastructure
42

Network: ‘ScienceDMZ’
‣ Very fast “low-friction” network links and paths with security policy and enforcement specific to scientific workflows
‣ “ScienceDMZ” concept is real and necessary
‣ BioTeam will be building them in 2014 and beyond
‣ Central premise: • Legacy firewall, network and security methods architected
for “many small data flows” use cases • Not built to handle smaller #s of massive data flows
• Also very hard to deploy ‘traditional’ security gear on 10Gigabit and faster networks
‣ More details, background & documents at http://fasterdata.es.net/science-dmz/
43
Background traffic or
competing bursts
DTN traffic with wire-speed
bursts
10GE
10GE
10GE

44
Simple Science DMZ:
Image source: “The Science DMZ: Introduction & Architecture” -- esnet

45
What’s the future look like?

Also known as hybrid cloudsHybrid HPC‣ Relatively new idea
• small local footprint • large, dynamic, scalable, orchestrated
public cloud component
‣ DevOps is key to making this work
‣ High-speed network to public cloud required
‣ Software interface layer acting as the mediator between local and public resources
‣ Good for tight budgets, has to be done right to work
‣ Not many working examples yet46

Converged Infrastructure
47
The meta issue
‣ Individual technologies and their general successful use are fine
‣ Unless they all work together as a unified solution, it all means nothing
‣ Creating an end-to-end solution based on the use case (science!): converged infrastructure

Necessary for ScienceConvergence
48
Laboratory Knowledge

Necessary for ScienceConvergence
48
Laboratory Knowledge
Converged Solution

Necessary for ScienceConvergence
48
Laboratory Knowledge
Converged Solution

People matter tooConvergence
49
Laboratory Knowledge
Converged Solution

Not so distant future!Fully converged laboratories
50
Laboratory Knowledge
Converged Solution

Not so distant future!Fully converged laboratories
50
Laboratory Knowledge
Converged Solution
New Bottleneck!

Not so distant future!Fully converged laboratories
51
Laboratory

Not so distant future!Fully converged laboratories
51
Laboratory
Knowledge

52
end; Thanks!







