

General Purpose Node-to-Network Interface
in Scalable Multiprocessors
CS 258, Spring 99
David E. Culler
Computer Science Division
U.C. Berkeley
3/12/99 CS258 S99 2
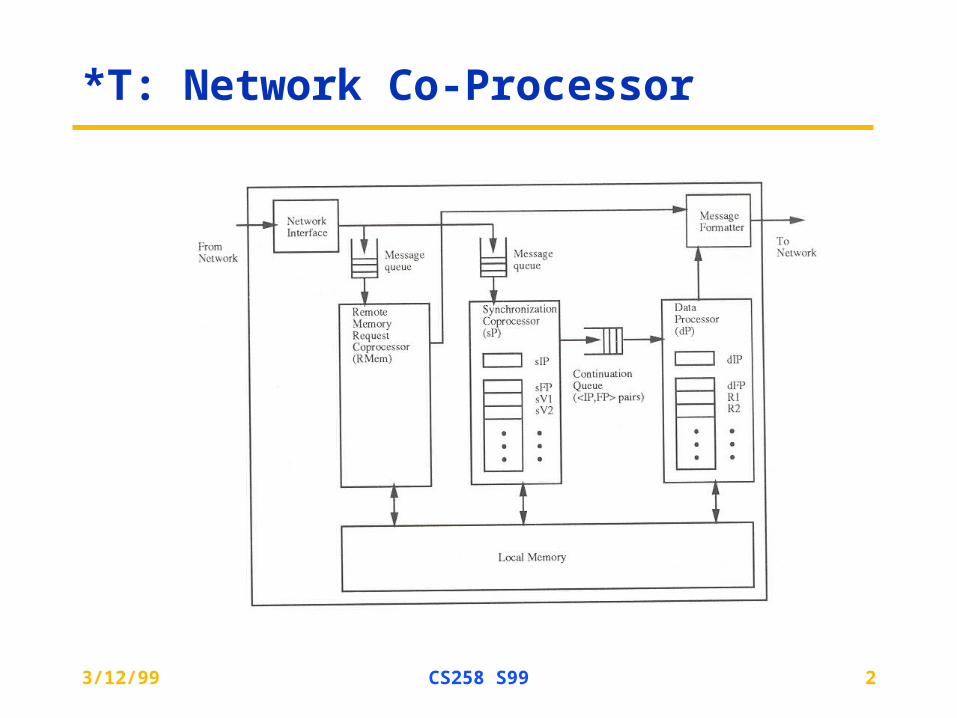
*T: Network Co-Processor

3/12/99 CS258 S99 3
iWARP: Systolic Computation
• Nodes integrate communication with computation on systolic basis
• Msg data direct to register
• Stream into memory
Interface unit
Host
3/12/99 CS258 S99 4
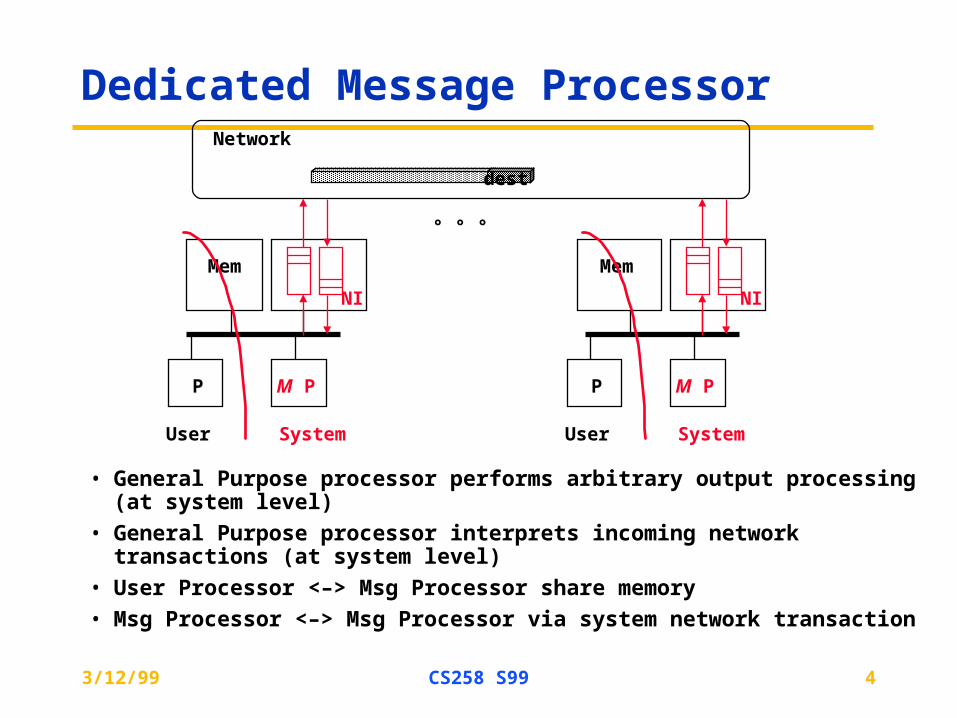
Dedicated Message Processor
• General Purpose processor performs arbitrary output processing (at system level)
• General Purpose processor interprets incoming network transactions (at system level)
• User Processor <–> Msg Processor share memory
• Msg Processor <–> Msg Processor via system network transaction
Network
° ° °
dest
Mem
P M P
NI
User System
Mem
P M P
NI
User System
3/12/99 CS258 S99 5
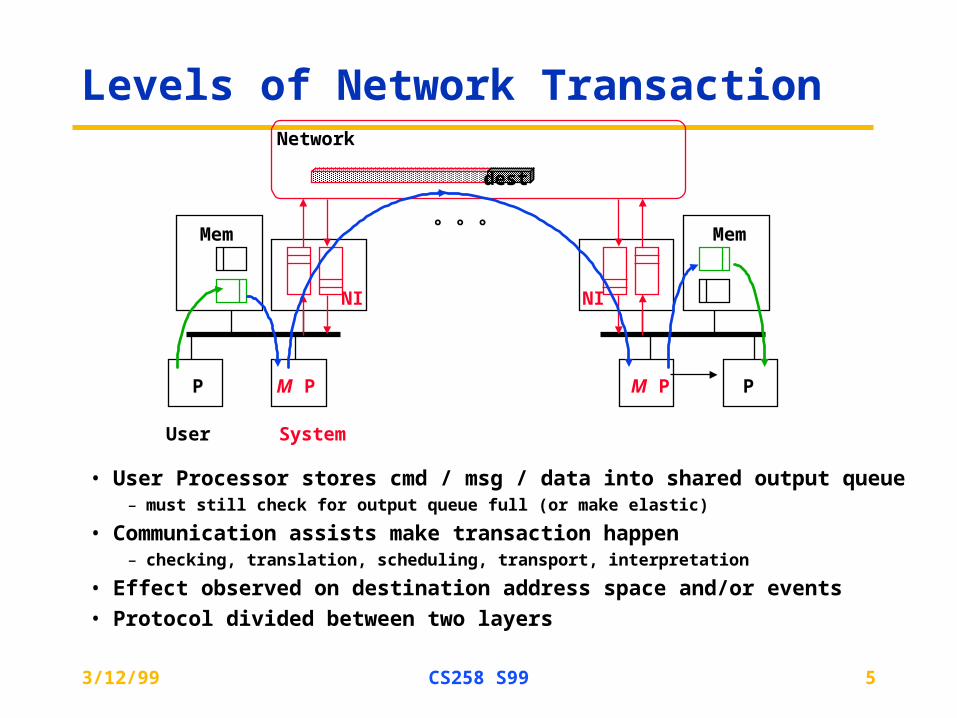
Levels of Network Transaction
• User Processor stores cmd / msg / data into shared output queue– must still check for output queue full (or make elastic)
• Communication assists make transaction happen– checking, translation, scheduling, transport, interpretation
• Effect observed on destination address space and/or events
• Protocol divided between two layers
Network
° ° °
dest
Mem
P M P
NI
User System
Mem
PM P
NI

3/12/99 CS258 S99 6
Example: Intel Paragon
Network
° ° ° Mem
P M P
NIi860xp50 MHz16 KB $4-way32B BlockMESI
sDMArDMA
64400 MB/s
$ $
16 175 MB/s Duplex
I/ONodes
rteMP handler
Var dataEOP
I/ONodes
Service
Devices
Devices
2048 B
3/12/99 CS258 S99 7
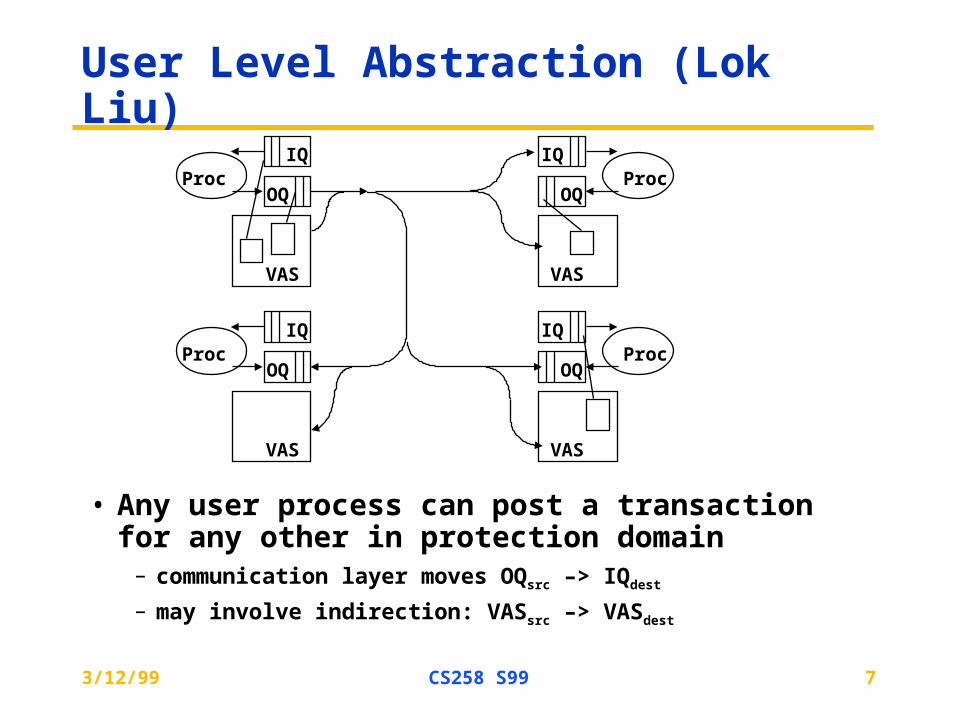
User Level Abstraction (Lok Liu)
• Any user process can post a transaction for any other in protection domain
– communication layer moves OQsrc –> IQdest
– may involve indirection: VASsrc –> VASdest
ProcOQ
IQ
VAS
ProcOQ
IQ
VAS
ProcOQ
IQ
VAS
ProcOQ
IQ
VAS
3/12/99 CS258 S99 8
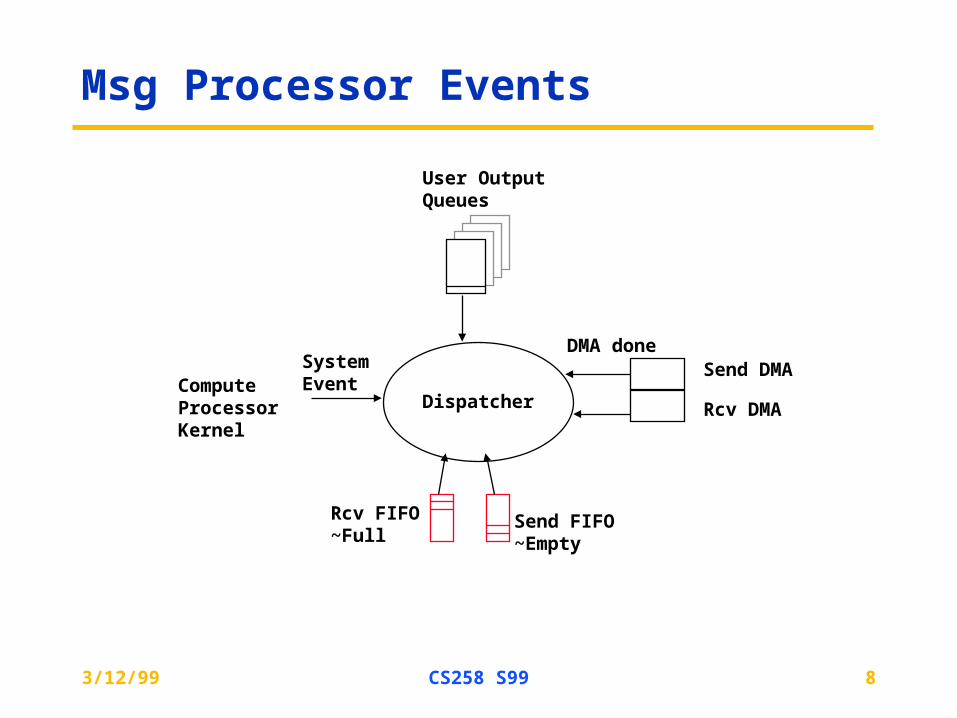
Msg Processor Events
Dispatcher
User OutputQueues
Send FIFO~Empty
Rcv FIFO~Full
Send DMA
Rcv DMA
DMA done
ComputeProcessorKernel
SystemEvent
3/12/99 CS258 S99 9
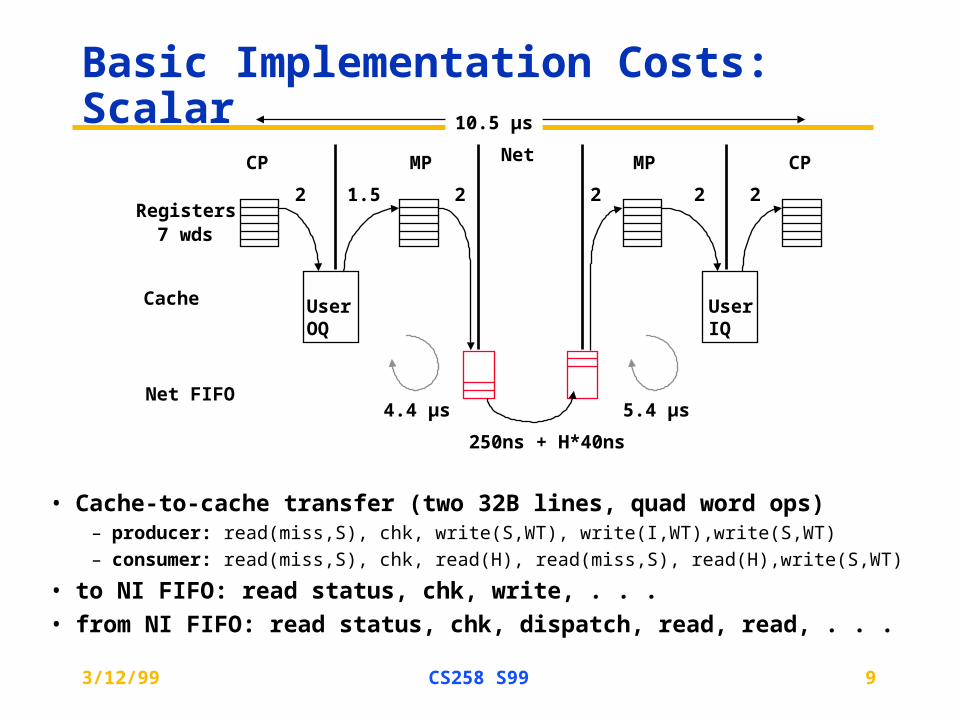
Basic Implementation Costs: Scalar
• Cache-to-cache transfer (two 32B lines, quad word ops)– producer: read(miss,S), chk, write(S,WT), write(I,WT),write(S,WT)
– consumer: read(miss,S), chk, read(H), read(miss,S), read(H),write(S,WT)
• to NI FIFO: read status, chk, write, . . .
• from NI FIFO: read status, chk, dispatch, read, read, . . .
CP
User OQ
MP
Registers
Cache
Net FIFO
UserIQ
MP CP Net
2 1.5 2
4.4 µs 5.4 µs
10.5 µs
7 wds
2 2 2
250ns + H*40ns

3/12/99 CS258 S99 10
Virtual DMA -> Virtual DMA
• Send MP segments into 8K pages and does VA –> PA
• Recv MP reassembles, does dispatch and VA –> PA per page
CP
User OQ
MP
Registers
Cache
Net FIFO
UserIQ
MP CP Net
2 1.5 2
7 wds
2 2 2
Memory
sDMA
hdr
rDMA
MP
20482048
400 MB/s
175 MB/s
400 MB/s
3/12/99 CS258 S99 11
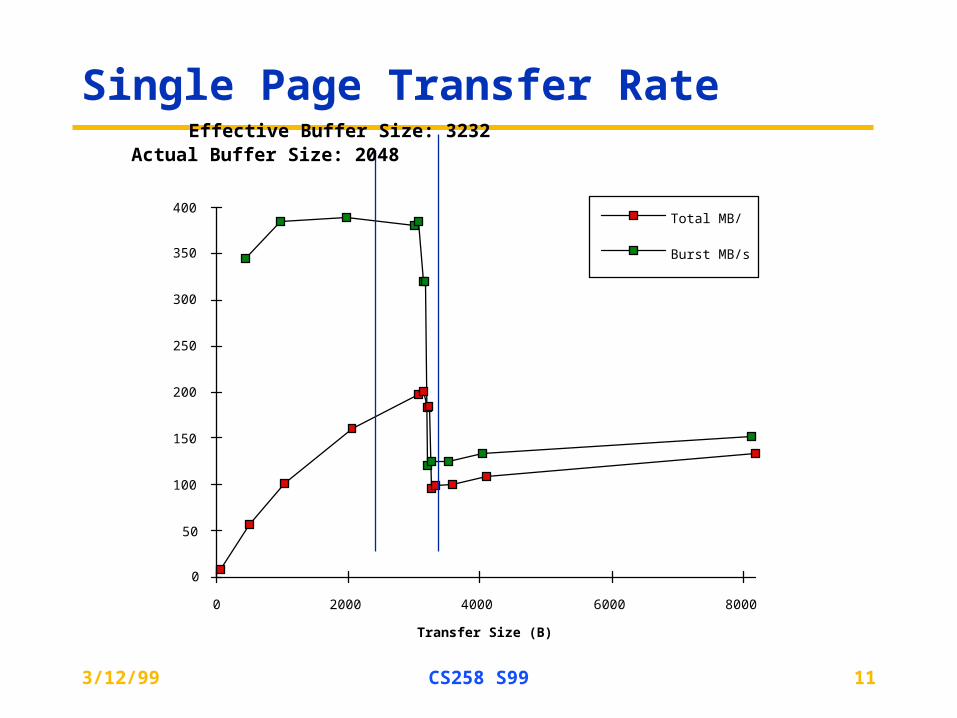
Single Page Transfer Rate
Transfer Size (B)
MB
/s
0
50
100
150
200
250
300
350
400
0 2000 4000 6000 8000
Total MB/s
Burst MB/s
Actual Buffer Size: 2048Effective Buffer Size: 3232

3/12/99 CS258 S99 12
Msg Processor Assessment
• Concurrency Intensive– Need to keep inbound flows moving while outbound flows stalled
– Large transfers segmented
• Reduces overhead but adds latency
User OutputQueues
Send FIFO~Empty
Rcv FIFO~Full
Send DMA
Rcv DMA
DMA done
ComputeProcessorKernel
SystemEvent
User InputQueues
VAS
Dispatcher

3/12/99 CS258 S99 13
Case Study: Meiko CS2 Concept
• Circuit-switched Network Transaction– source-dest circuit held open for request response
– limited cmd set executed directly on NI
• Dedicated communication processor for each step in flow
Network
Dest
P P
Mem Mem
Pout Pin Preply
Pcmd V P Pevent
Pout Pin Preply
Pcmd V P Pevent
3/12/99 CS258 S99 14
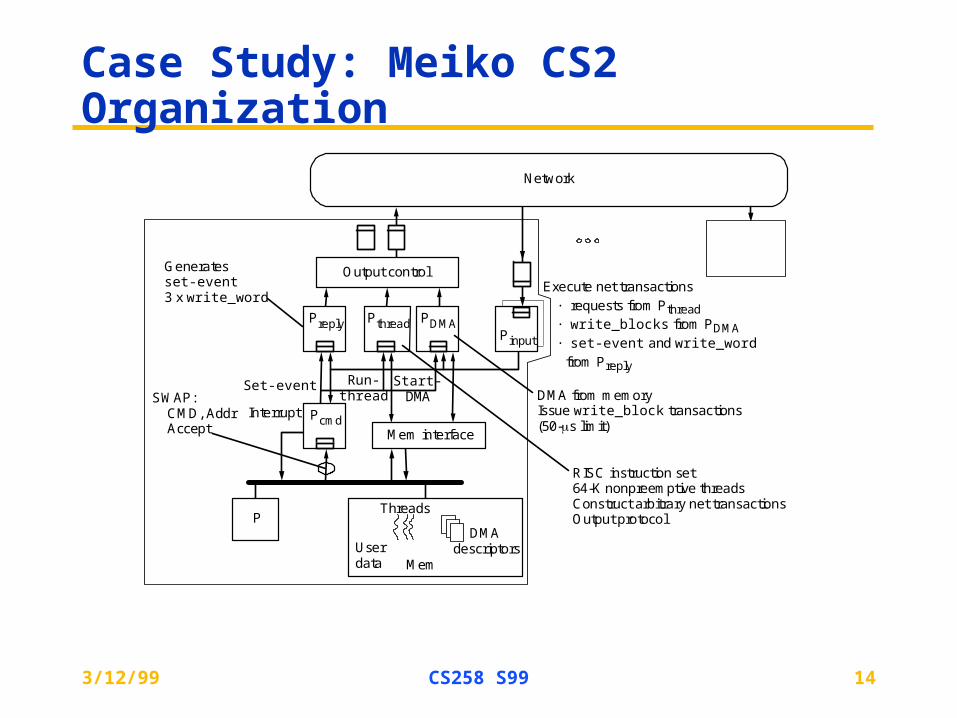
Case Study: Meiko CS2 Organization
Set-event
Generatesset-event3 x write_word
SWAP:CMD, AddrAccept
Interrupt
Run-thread
Start-DMA
Pinput
P
Mem interface
Threads
DMAdescriptorsUser
data Mem
Output controlExecute net transactions
· requests from Pthread· write_blocks from PDMA· set-event and write_word
from Preply
DMA from memoryIssue write_block transactions(50-s limit)
RISC instruction set64-K nonpreemptive threadsConstruct arbitrary net transactionsOutput protocol
Preply
Pcmd
Pthread PDMA
Network
3/12/99 CS258 S99 15
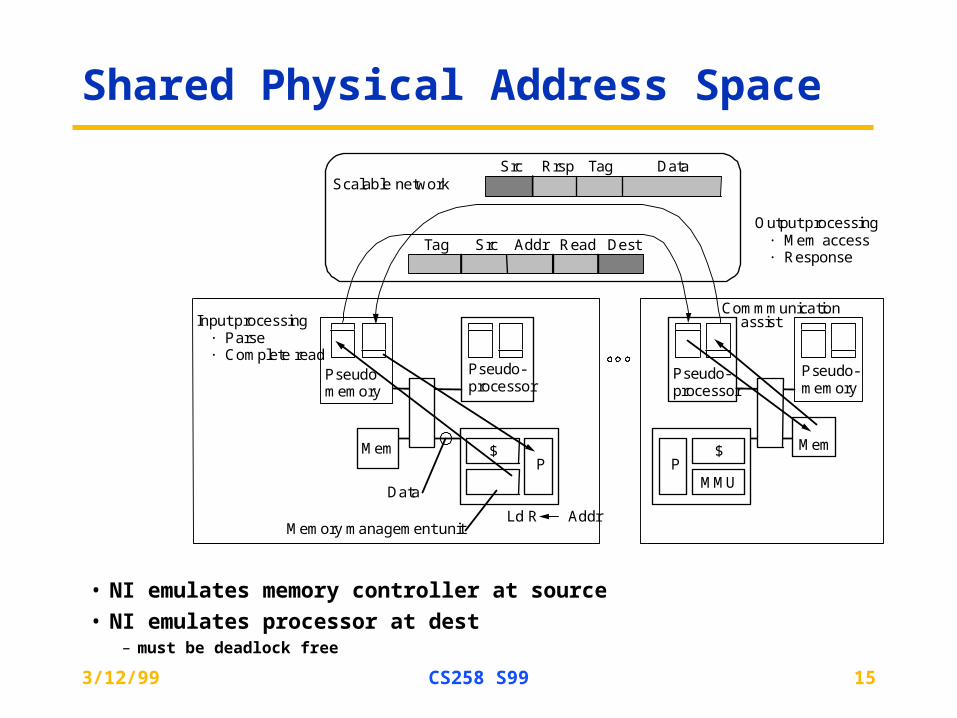
Shared Physical Address Space
• NI emulates memory controller at source
• NI emulates processor at dest– must be deadlock free
Scalable network
P$
Memory management unit
Data
Ld R Addr
Pseudomemory
Pseudo-processor
DestReadAddrSrcTag
DataTagRrspSrc
Output processing· Mem access· Response
CommmunicationInput processing
· Parse· Complete read
P$
MMU
Mem
Pseudo-memory
Pseudo-processor
Mem
assist
3/12/99 CS258 S99 16
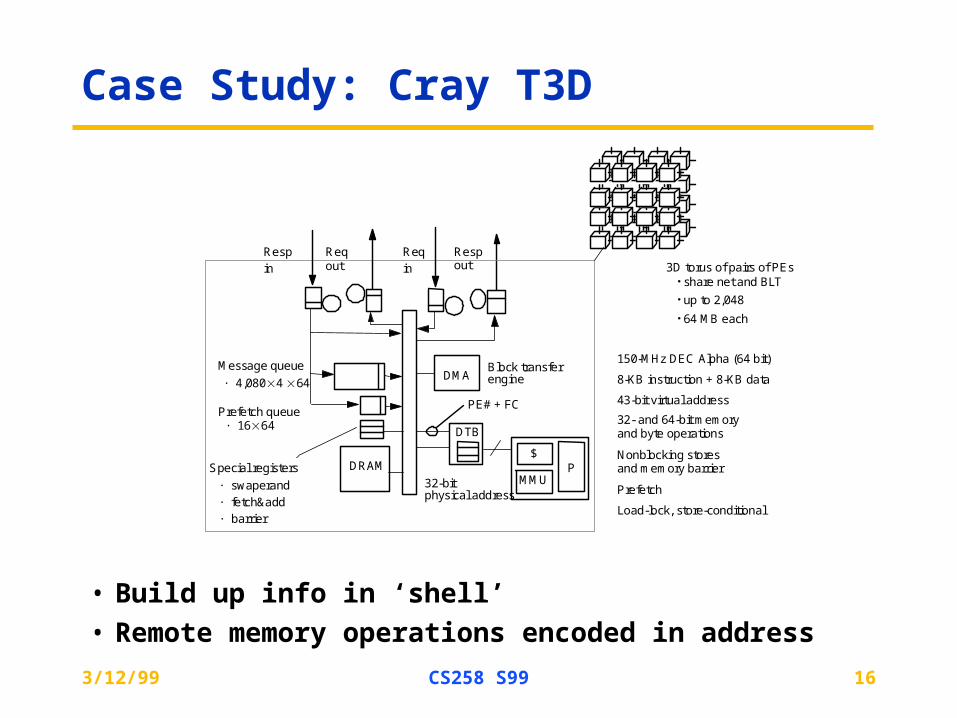
Case Study: Cray T3D
• Build up info in ‘shell’
• Remote memory operations encoded in address
DRAM
Reqout
P$
MMU
150-MHz DEC Alpha (64 bit)
8-KB instruction + 8-KB data
43-bit virtual address
Prefetch
Load-lock, store-conditional
32-bit
DTB
Prefetch queue· 16 64
Message queue
· 4,080 4 64
Special registers
· swaperand · fetch&add · barrier
PE# + FC
DMA
Resp
in 3D torus of pairs of PEs· share net and BLT
· up to 2,048
· 64 MB each
Req
in
Respout
Block transfer
32- and 64-bit memory and byte operations
Nonblocking stores and memory barrier
engine
physical address

3/12/99 CS258 S99 17
Case Study: NOW
• General purpose processor embedded in NIC
L2 $
Bus adapterSBUS (25 MHz)Mem
UltraSparc
s DMA
Host DMA
SRAM
Myrinet
X-bar
r DMA
Bus interface
Mainprocessor
LinkInterface
160-MB/sbidirectionallinks
MyricomLanai NIC(37.5-MHz processor,256-MB SRAM3 DMA units)
Eight-portwormholeswitches
3/12/99 CS258 S99 18
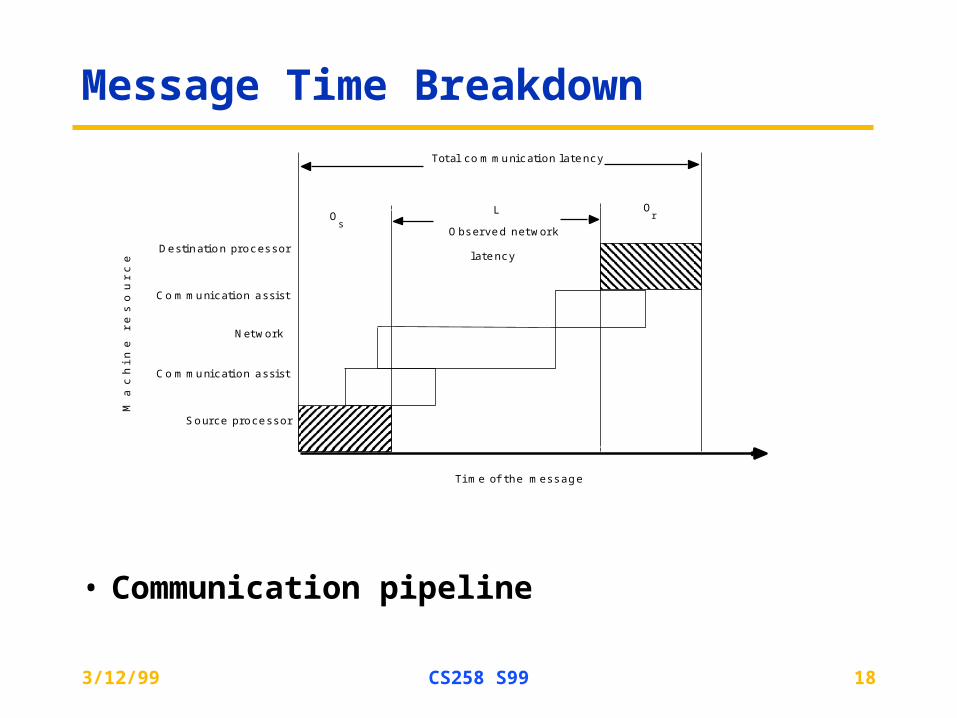
Message Time Breakdown
• Communication pipeline
Ma
ch
ine
r
es
ou
rc
e
T im e o f th e m e s s ag e
S o u rce p ro ce sso r
C o m m u n ic a tion a ss is t
D e s tin a t io n p ro c es so r
To ta l co m m u n ic a tion la te nc y
O bs e rve d ne tw o r k
la te nc y
C o m m u n ic a tion a ss is t
N e tw o rk
Os
OrL

3/12/99 CS258 S99 19
Message Time Comparison
Mic
rose
cond
s
CM
-5
Par
ago
n
Mei
ko C
S-2
NO
W U
ltra
T3
D
CM
-5
Par
ago
n
Mei
ko C
S-2
NO
W U
ltra
T3
D
0
2
4
6
8
10
12
14
Processing overhead,receiving side (Or)
Processing overhead,sending side (Os)
Communicationlatency (L)
Time per message, pipelinedsequence of request-response operations (g)
3/12/99 CS258 S99 20
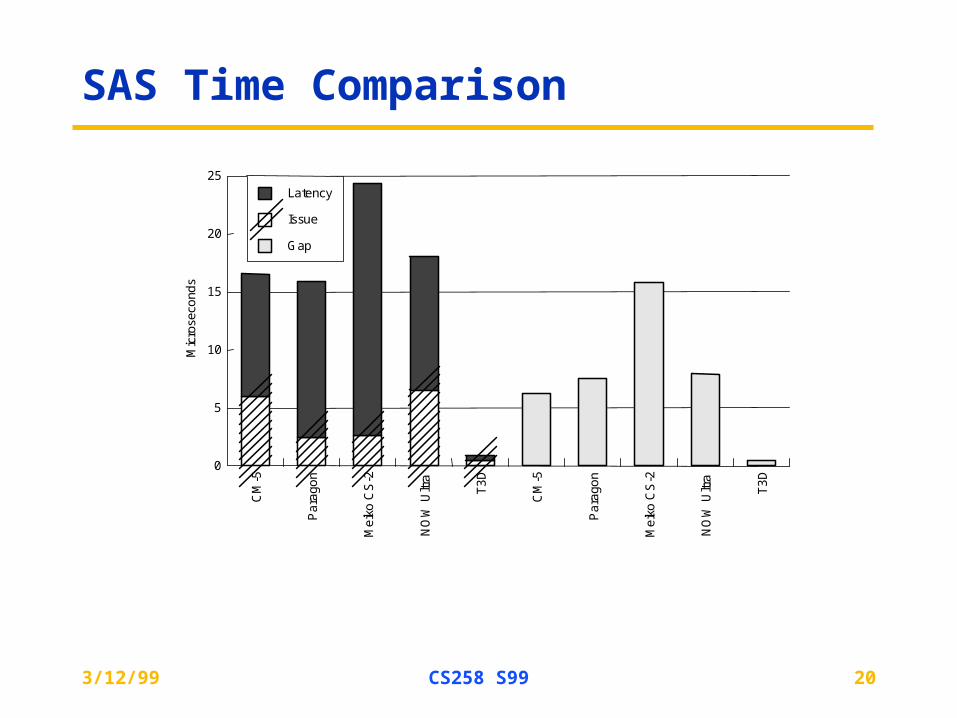
SAS Time Comparison
Mic
rose
cond
s
CM
-5
Pa
rago
n
Me
iko
CS
-2
NO
W U
ltra
T3
D
CM
-5
Pa
rago
n
Me
iko
CS
-2
NO
W U
ltra
T3
D
0
5
10
15
20
25
Gap
Issue
Latency
3/12/99 CS258 S99 21
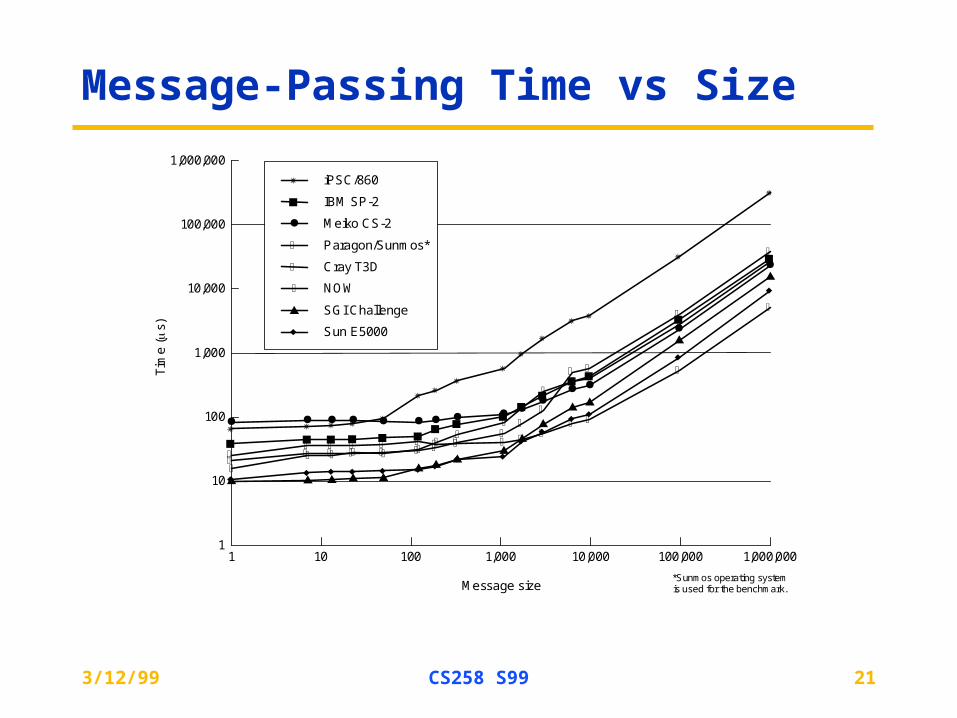
Message-Passing Time vs Size
Tim
e (
s)
1 10 100 1,000
Message size
10,000 100,000 1,000,000
*Sunmos operating systemis used for the benchmark.
1
10
100
1,000
10,000
100,000
1,000,000
iPSC/860
IBM SP-2
Meiko CS-2
Paragon/Sunmos*
Cray T3D
SGI Challenge
NOW
Sun E5000

3/12/99 CS258 S99 22
Message-Passing Bandwidth vs Size
1 10 100 1,000
Message size
10,000 100,000 1,000,0000
20
40
60
80
100
120
140
160
180B
and
wid
th (
MB
/s)
iPSC/860
IBM SP-2
Meiko CS-2
Paragon/Sunmos
Cray T3D
SGI Challenge
NOW
Sun E6000
3/12/99 CS258 S99 23
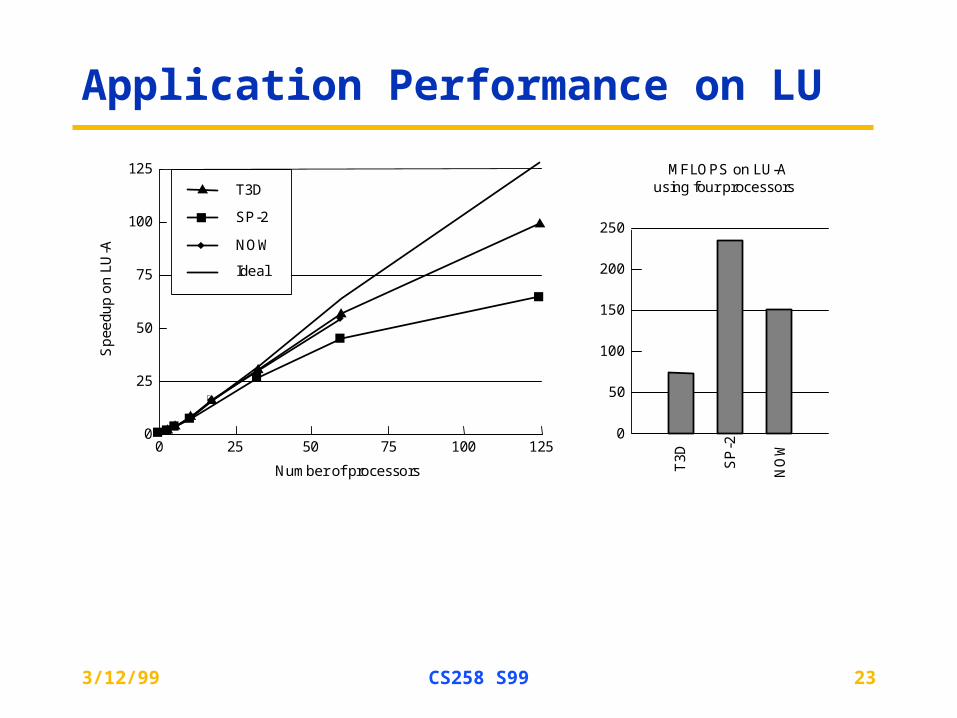
Application Performance on LUS
pee
dup
on
LU
-A
0 25 50 75 100 125
T3D
SP
-2
NO
W
0
25
50
75
100
125
NOW
SP-2
Ideal
T3D
0
50
100
150
200
250
MFLOPS on LU-Ausing four processors
Number of processors
3/12/99 CS258 S99 24
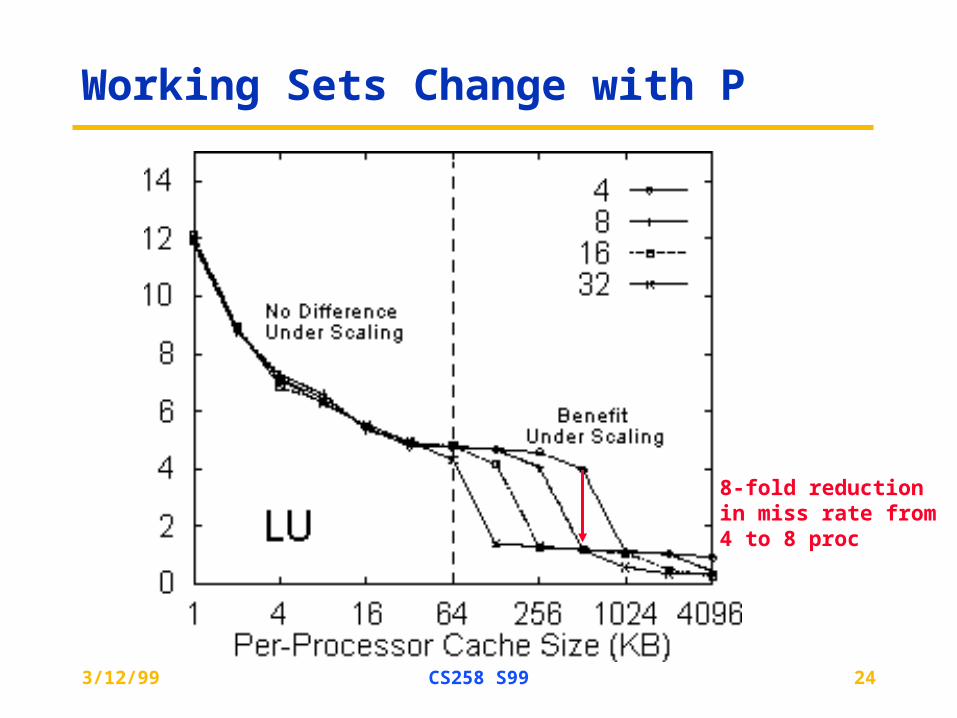
Working Sets Change with P
8-fold reductionin miss rate from4 to 8 proc

3/12/99 CS258 S99 25
Application Performance on BT
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
Sp
eedu
p o
n B
T-A NOW
Ideal
SP-2
T3D
BT MFLOPSusing 25
processors
Number of processors
0
200
400
600
800
1,000
1,200
1,400
T3D
SP
-2
NO
W
3/12/99 CS258 S99 26
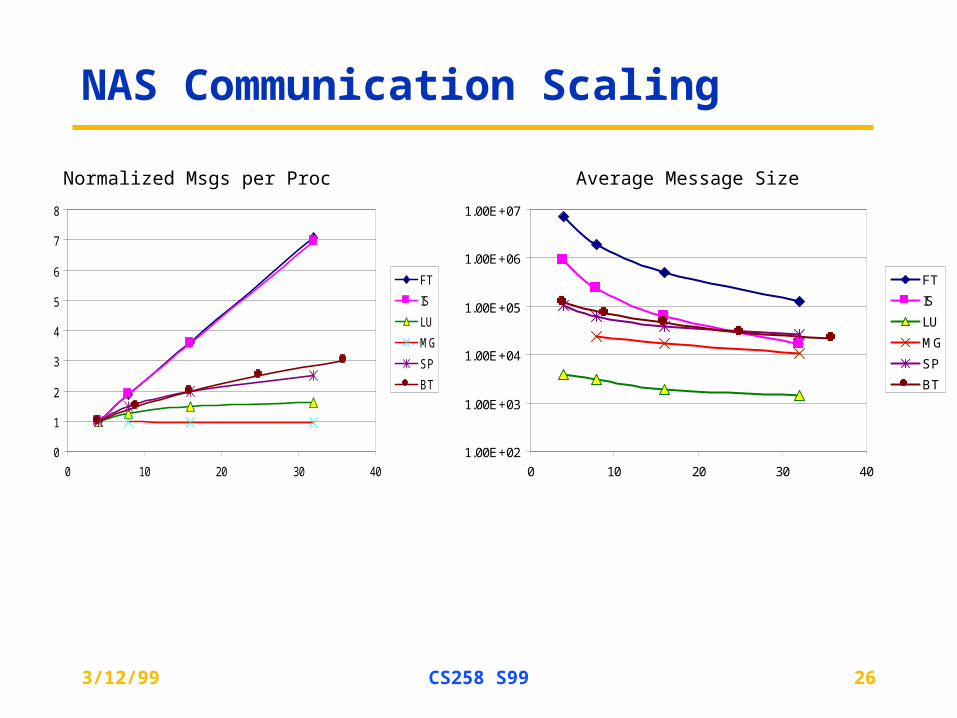
NAS Communication Scaling
1.00E+02
1.00E+03
1.00E+04
1.00E+05
1.00E+06
1.00E+07
0 10 20 30 40
FT
IS
LU
MG
SP
BT
0
1
2
3
4
5
6
7
8
0 10 20 30 40
FT
IS
LU
MG
SP
BT
Normalized Msgs per Proc Average Message Size
3/12/99 CS258 S99 27
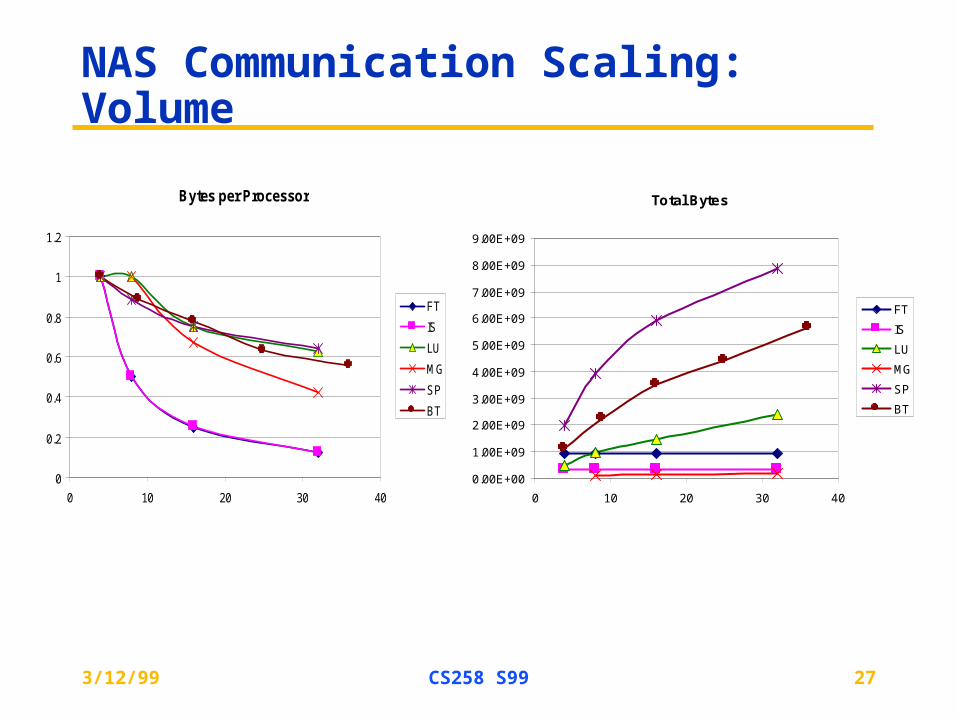
NAS Communication Scaling: Volume
Bytes per Processor
0
0.2
0.4
0.6
0.8
1
1.2
0 10 20 30 40
FT
IS
LU
MG
SP
BT
Total Bytes
0.00E+00
1.00E+09
2.00E+09
3.00E+09
4.00E+09
5.00E+09
6.00E+09
7.00E+09
8.00E+09
9.00E+09
0 10 20 30 40
FT
IS
LU
MG
SP
BT
3/12/99 CS258 S99 28
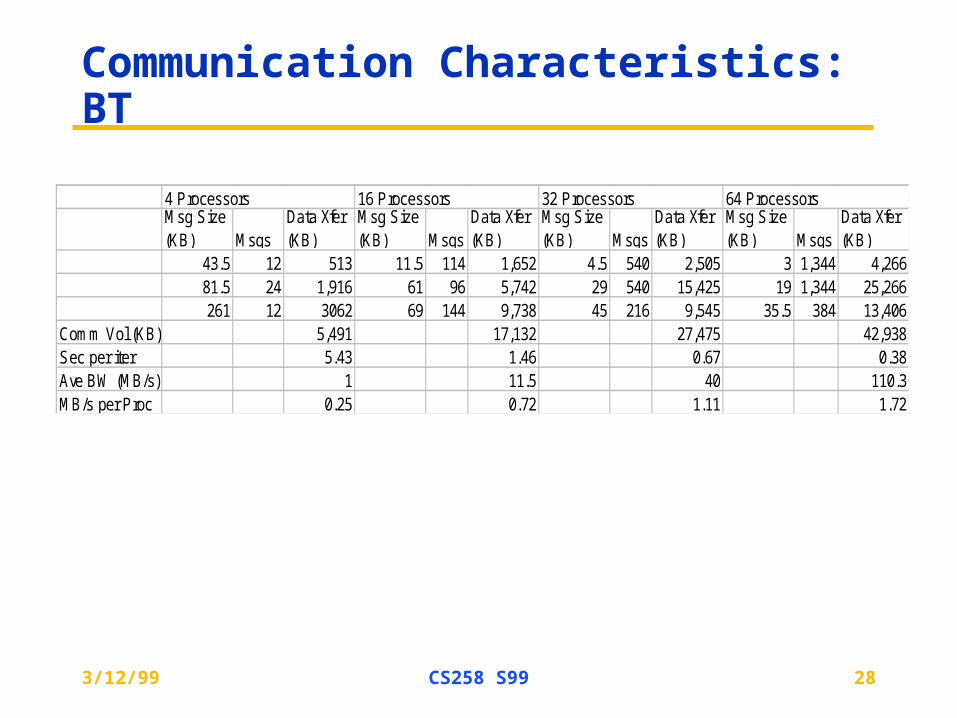
Communication Characteristics: BT
Msg Size (KB) Msgs
Data Xfer (KB)
Msg Size (KB) Msgs
Data Xfer (KB)
Msg Size (KB) Msgs
Data Xfer (KB)
Msg Size (KB) Msgs
Data Xfer (KB)
43.5 12 513 11.5 114 1,652 4.5 540 2,505 3 1,344 4,26681.5 24 1,916 61 96 5,742 29 540 15,425 19 1,344 25,266261 12 3062 69 144 9,738 45 216 9,545 35.5 384 13,406
Comm Vol (KB) 5,491 17,132 27,475 42,938Sec per iter 5.43 1.46 0.67 0.38Ave BW (MB/s) 1 11.5 40 110.3MB/s per Proc 0.25 0.72 1.11 1.72
64 Processors4 Processors 16 Processors 32 Processors
3/12/99 CS258 S99 29
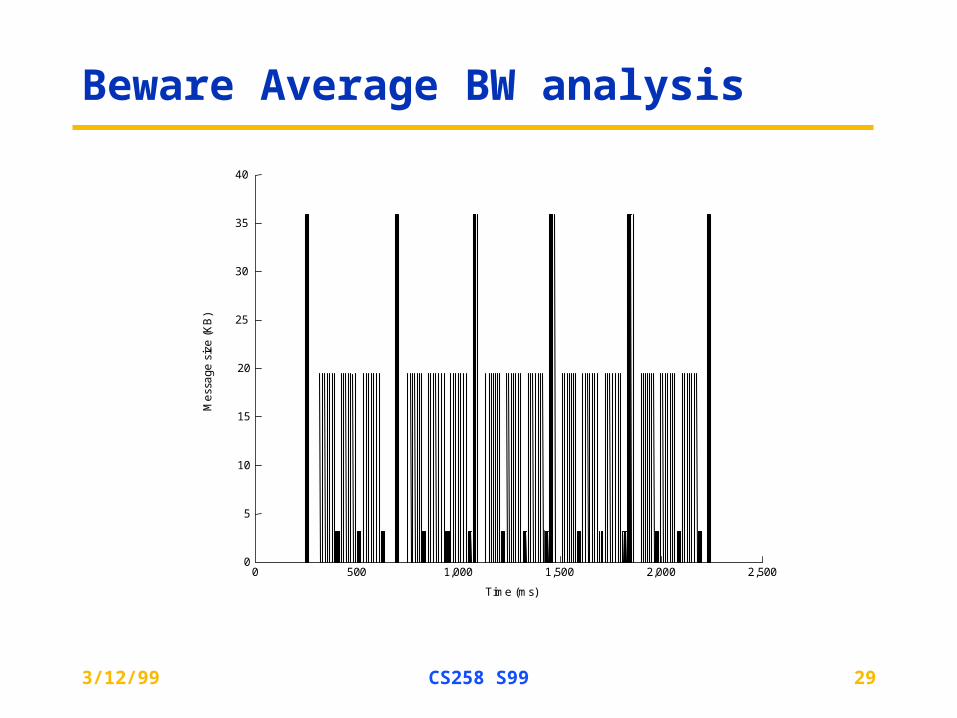
Beware Average BW analysis
0 500 1,000 1,500 2,000 2,5000
5
10
15
20
25
30
35
40
Me
ssa
ge s
ize
(KB
)
Time (ms)
3/12/99 CS258 S99 30
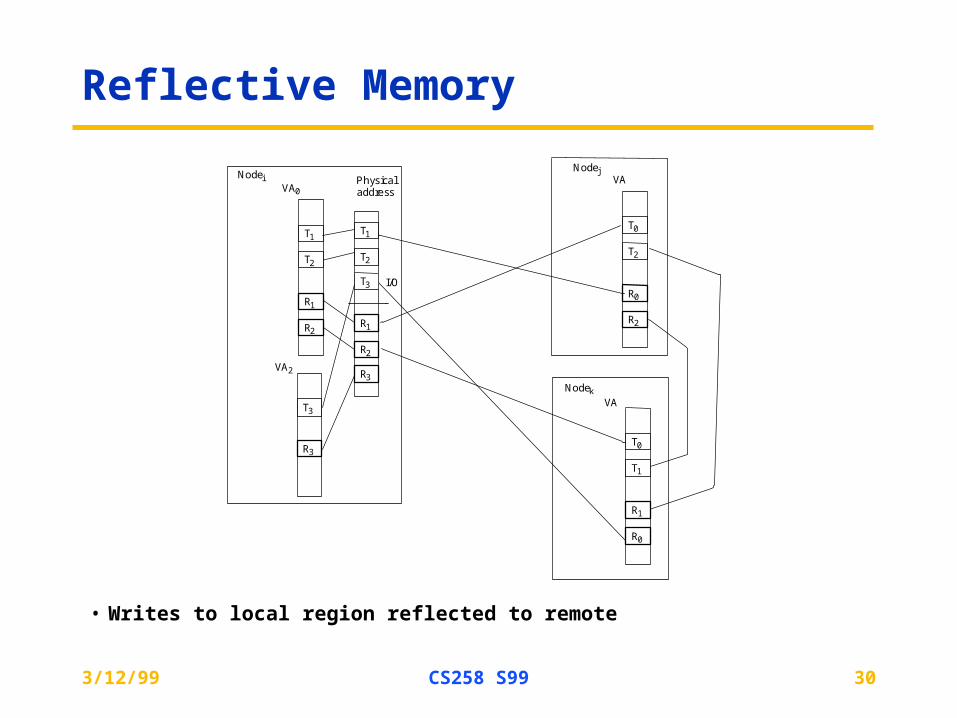
Reflective Memory
• Writes to local region reflected to remote
T1
T2
R1
R2
T3
R3
VA0
VA2
Nodei
T0
T2
R0
R2
VANodej
T0
T1
R1
R0
VA
Nodek
T1
T2
T3
R1
R2
R3
Physicaladdress
I/O
3/12/99 CS258 S99 31
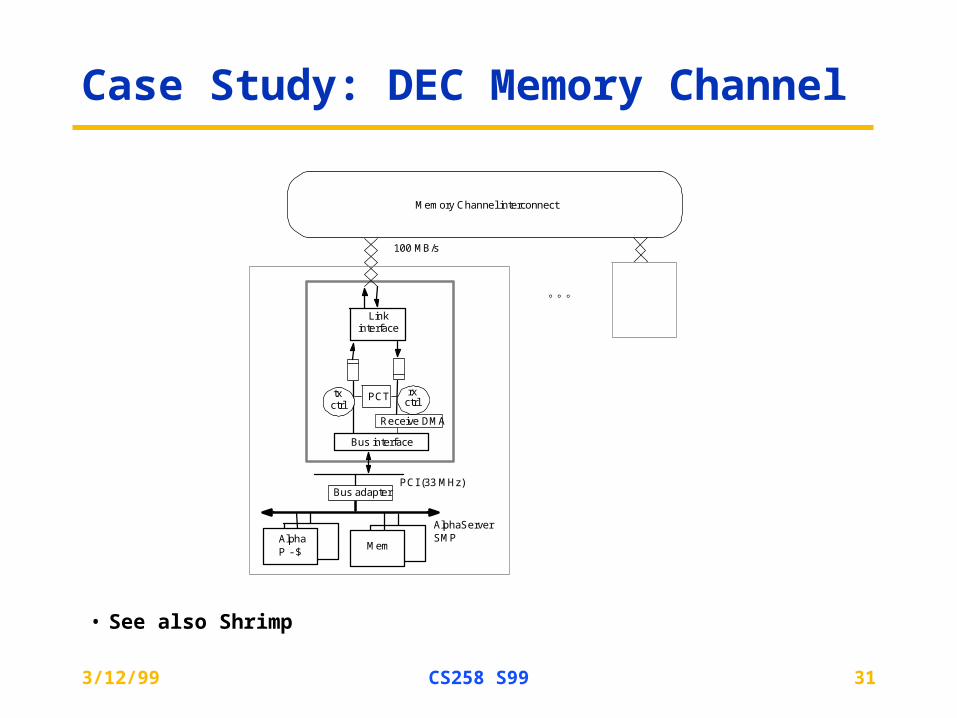
Case Study: DEC Memory Channel
• See also Shrimp
PCI (33 MHz)
Receive DMA
Bus interface
PCTtxctrl
rxctrl
AlphaServerSMP
Memory Channel interconnect
100 MB/s
Linkinterface
Bus adapter
MemAlphaP - $

3/12/99 CS258 S99 32
Scalable Synchronization Operations
• Messages: point-to-point synchronization
• Build all-to-all as trees
• Recall: sophisticated locks reduced contention by spinning on separate locations
– caching brought them local
– test&test&set, ticket-lock, array lock
» O(p) space
• Problem: with array lock location determined by arrival order => not likely to be local
• Solution: queue-lock– build distributed linked-list, each spins on local node

3/12/99 CS258 S99 33
Queue Locks
• Head holds lock; Each points to next waiter
• Shared pointer to tail
• Acquire– swap (fetch&store) tail with node address, chain in prev
• Release– signal next
– compare&swap plus check to reset tail
LA
LB
A
LC
B
A
LC
B
LC
(a) (b) (c)
(d)
(e)
3/12/99 CS258 S99 34
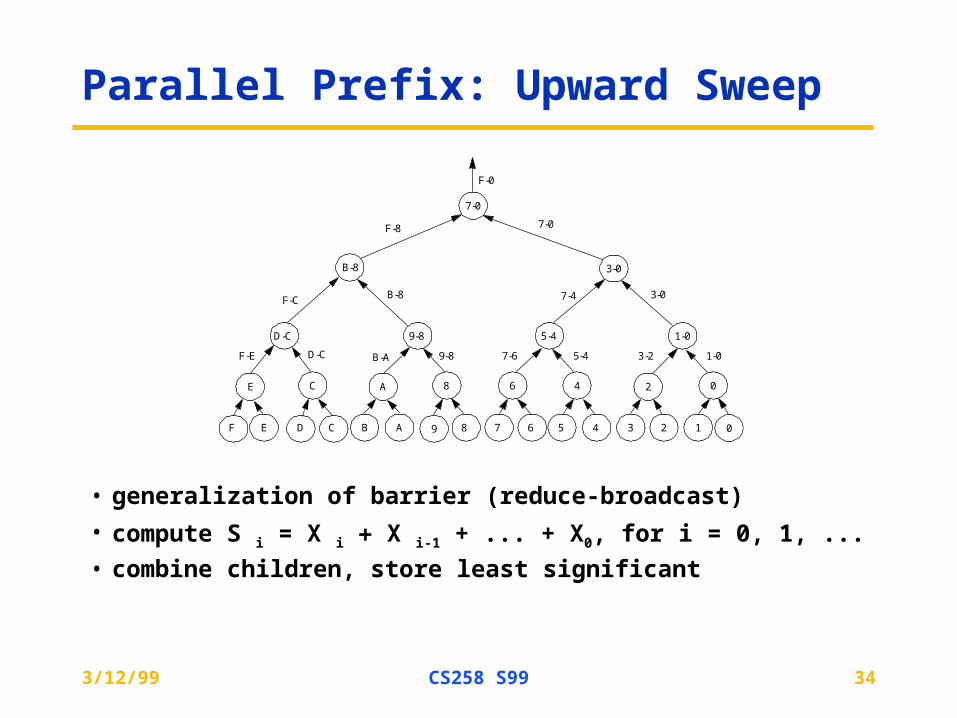
Parallel Prefix: Upward Sweep
• generalization of barrier (reduce-broadcast)
• compute S i = X i X i-1 + ... + X0, for i = 0, 1, ...
• combine children, store least significant
0123456789ABCDEF
1-03-25-47-69-8B-AD-CF-E
3-07-4B-8F-C
F-8 7-0
F-0
02468ACE
1-05-49-8D-C
3-0B-8
7-0

3/12/99 CS258 S99 35
Downward Sweep of parallel Prefix
• Least branch send to most sig child
• when receive from above– send to least significant
– combine with stored and send result to most sign
0123456789ABCDEF
02468ACE
1-05-49-8D-C
3-0
B-8
7-0
7-0
B-0 7-0
D-0 B-0 7-09-0
E-0 D-0 C-0 B-0 A-0 9-0 8-0 7-0 6-0 5-0 4-0 3-0 2-0 1-0 0
3-05-0 1-0
3-0







