

Seshu Edala, Dave Schaefer, Nghia Ngo – IT Architects
November 2015
Gobblin @ Intel

2
Legal MessageTHE INFORMATION PROVIDED IN THIS PRESENTATION IS INTENDED TO BE GENERAL IN NATURE AND IS NOT SPECIFIC GUIDANCE. RECOMMENDATIONS (INCLUDING POTENTIAL COST SAVINGS) ARE BASED UPON INTEL'S EXPERIENCE AND ARE ESTIMATES ONLY. INTEL DOES NOT GUARANTEE OR WARRANT OTHERS WILL OBTAIN SIMILAR RESULTS
This presentation is for informational purposes only. INTEL MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS SUMMARY.
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
For more complete information about performance and benchmark results, visit www.intel.com/benchmarks
Intel and the Intel logo are trademarks of Intel Corporation in the U.S. and/or other countries.
* Other names and brands may be claimed as the property of others.
Copyright © 2016, Intel Corporation. All rights reserved.

Outline
Integrated Analytics Vision
Data Ingestion Challenges
Solution
What we would like to do
What we did
Challenges
Need Help
Summary
3

Integrated Analytics Vision & MissionOur Vision: Customers are empowered to easily make rapid, impactful business decisions and
uncover new revenue channels through connected data & analytics
Our Mission: Provide clean, relatable, integrated data using a consistent approach to deliver business recommendations and insights through visual and interactive usage
Transformed and
Connected Data
Raw Data Advanced
Analytics
4
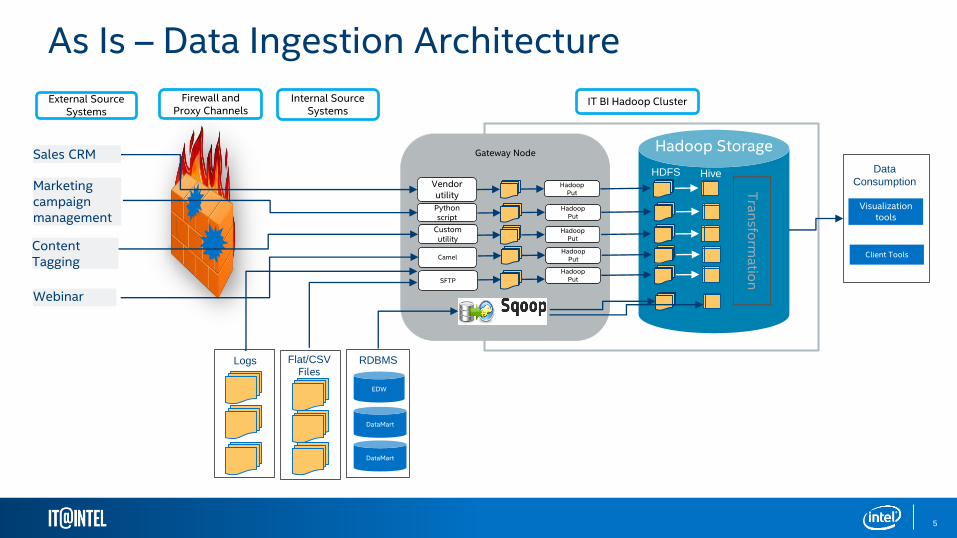
As Is – Data Ingestion Architecture
Firewall and Proxy Channels
External Source Systems
IT BI Hadoop Cluster
Gateway Node
Camel
Hadoop Storage
Internal Source Systems
Logs
DataMart
EDW
DataMart
RDBMSFlat/CSVFiles
SFTP
Vendorutility
Hadoop Put
Python script
HDFS Hive
Hadoop Put
Customutility
Hadoop Put
Hadoop Put
Hadoop Put
Data
ConsumptionTra
nsfo
rma
tion
Visualizationtools
Client Tools
Sales CRM
Marketing campaign management
Content Tagging
Webinar
5

Data Ingestion ChallengesIngesting a variety of internal/external data sources, such as enterprise data warehouse, enterprise master data, spreadsheets, social media feeds, marketing data, retailer data, etc.
This resulted in variety of challenges including:
• Individual project teams instrumenting their own methods for ingesting data from various sources and building their own data pipelines
• Operational Complexity to manage the individual pipelines
• No reusability as each project team created redundant methods/codebases for ingesting data sources
• High development cost as each team built their own data ingestion pipelines
• Inconsistency in the quality of project teams’ data ingestion codebases impacting data qualify and reliability
• Job failures resulting from data format, quality, schema evolution and availability issues
• Skillset challenges
6
No standardized reusable framework for data ingestion

Solution: Data Ingestion Architecture with Gobblin/Kite
Firewall and Proxy Channels
External Source Systems
IT BI Hadoop Cluster
Gateway Node
DataMart
EDW
DataMart
Data IngestionReusable Framework
Kafka
Validation
RestFul APIs
And many
more….
Hadoop Storage
Hive / HDFS /Hbase
Internal Source Systems
RDBMSFlat/CSVFiles
SFTPVendor
APIs
Gobblin
Inte
rface Logs
File Adapter
ConfigFiles
Alert
CSV Adapter
RDBMSJDBC Connector
Data
Consumption
Visualizationtool
Client Tools
Sales CRM
Marketing campaign management
Content tagging
Webinar
Retailer
Social media feeds
Kite
7
UI

8
What we set out to do?Functionally evaluate Gobblin for ingesting and integrating data.
Prototype a non OOB source to extract data out of an “online campaign automation provider”
Acceptance Criteria
Bulk RestAPI
Validate the correctness of data
Data Consistency from end to end
Notification, status and error logging
Ability to log kickout records
Training plan for implementation and adoption plan

9
What we did
Data Scope• 4 objects
• accounts• contacts • 9 activities • 59 custom objects
Parallel load data• Hive (not using compaction) *• HDFS (BaseDataPublisher)
Functional UI ready• Scheduling• Job History• Authoring job configurations
Functional backend ready• Enterprise scheduler• Gobblin Standalone• Gobblin Map-Reduce *Quality checking policies• Row level• Task levelEnterprise features• Alerting• Monitoring• Profiling *• Logging
* Needs more attention

10
Process Flow
Establish connection
•Authentication
•Endpoint indirection
Object Determination
•Get Object Listing
•Get Schema Definition
•Slice Schema
Create Intent
•Create Exports
Establish size boundaries
•Create Syncs
•Poll Syncs
•Slice batches
Download
•Parallel batches
Rebuild data
•Reassemble
•Schema inferencing
•Data Conversion
Data Publishing
•Hive/Impala load
•View Definition
•Quality enforcement
Parallel download and reassembly of data blocks

11
Gobblin Challenges
User Interface – Visual Execution and Evaluation
Data Routing – Complex enterprise integration patterns routing challenging to implement
public enum Result {PASSED, // The test passedFAILED // The test failed
}

12
Need Gobblin Community Help Address adoption challenges
Intake process for third-party contributions.
– New Source - “online campaign automation provider”
– Spark based ingestion candidates (parquet, avro, json, JDBC, s3) and runtime
– Kite SDK
Partnership with key big data vendors – CDH, HDP, MAPR – for internalizing Gobblin capability
– Deployment, Management, Metrics, and Lineage Integration
Implement queuing or pluggable schedulers that do not rely on PID and workdir states; better integration with enterprise schedulers.
Make Hive publishers native; versus offline compactions.
Publish documentation for user community

13
Summary
Gobblin is a robust data integration framework that meets the scale, quality, enterprise readiness imperatives expected;
However, some features like usability, enterprise integration patterns, scheduling, profiling, lineage, deployment, documentation could be improved.








