

Google Tech Talk.Containers: What, Why and HowGoogle Cloud Innovation
Dr. Eric BrewerVP of InfrastructureApril 27, 2015

Google confidential │ Do not distribute

Google confidential │ Do not distribute

Google confidential │ Do not distribute

Google confidential │ Do not distribute
Management MobileDeveloper Tools
Compute
Networking
Big Data
Storage

Google confidential │ Do not distribute
“Cloud Native” ApplicationsMiddle of a great transition• unlimited “ethereal” resources in the Cloud• an environment of services not machines• thinking in APIs and co-designed services• high availability offered and expected
(this is how Google already works internally)

Google confidential │ Do not distribute
Google has been developing and using containers to manage our applications for over 10 years.
Images by Connie Zhou
2B launched per week● simplifies management● performance isolation● efficiency

Google confidential │ Do not distribute Google confidential │ Do not distribute
What are containers?

Google confidential │ Do not distribute
VMs vs. Containers
Physical Processor
Virtual Processor
Operating System
Libraries
User Code PrivateCopy
Shared
Virtual Machines
Physical Processor
Virtual Processor
Operating System
Libraries
User Code
Containers
ISA
syscall
Containers: less overhead, enable more “magic”

Google confidential │ Do not distribute
Merging Two Kinds of ContainersDocker• It’s about packaging• Control:
• packages• versions• (some config)
• Layered file system• => Prod matches testing
Linux Containers• It’s about isolation
… performance isolation• not security isolation
… use VMs for that• Manage CPUs, memory,
bandwidth, …• Nested groups

Google confidential │ Do not distribute
Google Platform Layering
Infrastructure: Machines
App Engine: Language-based
Containers: Process-based
GCE
Kubernetes
GKE
GAE
Easy to use,Flexible

Google confidential │ Do not distribute Google confidential │ Do not distribute
Why do we use them?

Google confidential │ Do not distribute
Why ContainersEase of development:
• User makes jobs based on containers; we schedule those jobs for them• They don’t worry about machines or the OS
Utilization (much more efficient)• We pack many containers per machine• Mix or live services and batch workloads• Batch fills in the “holes”
Ease of Operation: fewer staff per job• E.g. all jobs use latest security patches• More shared code among projects (shared services and code)

Google confidential │ Do not distribute Google confidential │ Do not distribute
How do we use them?

Google confidential │ Do not distribute
Services ModelEach app lives in an environment of shared services
• storage, monitoring, logging• master election, deployment, testing
Services are updated independently• Multiple versions running at a time
• Required for “canary” testing -- deploy new version a little bit• => Need version numbers
• Usually new versions are backward compatible• Sometimes not => must eventually update ALL clients• Running multiple versions gives clients some time to update

Google confidential │ Do not distribute
Borg Scheduler
Borg is our primary scheduler for the last 10 years• Schedules over a single very large cluster (10,000+ machines)• Starts, moves, restarts container-based jobs• Also handles some logging, monitoring• Users don’t worry about where their jobs run
Recent paper on Borg:
https://research.google.com/pubs/pub43438.html

Google confidential │ Do not distribute
Kubernetes
• Container orchestrator • Runs Docker containers• Supports multiple cloud and bare-metal environments• Inspired and informed by Google’s experiences and
internal systems• Open source, written in Go
Manage applications, not machines
κυβερνήτης: Greek for “pilot” or “helmsman of a ship” the open source cluster manager from Google

Google confidential │ Do not distribute
Kubernetes: Higher level of Abstraction
Don’t Worry About• OS details• Packages — no conflicts• Machine sizes (much)• Mixing languages• Port conflicts
Think About• Composition of services• Load-balancing• Names of services• State management• Monitoring and Logging• Upgrading

Google confidential │ Do not distribute
Kubernetes Partners

Google confidential │ Do not distribute
Open sourced in June 2014
Google launched Google Container Engine (GKE)• Full managed and hosted Kubernetes• https://cloud.google.com/container-engine/
Roadmap:• https://github.com/GoogleCloudPlatform/kubernetes/blob/master/docs/roadmap.md
Working towards v1.0 over next few months• Key use cases: Redis, Memcache, MySQL, Mongo, Cassandra
Kubernetes Status & Plans

Google confidential │ Do not distribute
Evolution is the Real ValueApps Structured as Independent Microservices● Encapsulated state with APIs (like “objects”)● Mixture of languages● Mixture of teams
Services are Abstract● A “Service” is just a long-lived abstract name● Varied implementations over time (versions)● Kubernetes routes to the right implementation

Google confidential │ Do not distribute
Pod
/data
Containers:• Handle package dependencies• Different versions, same machine• No “DLL hell”
Managing Dependencies
python 3.4.2glibc 2.21
MyService
python 2.7.9glibc 2.19
MySQL Pods:• Co-locate containers• Shared volumes• IP address, independent port space• Unit of deployment, migration

Google confidential │ Do not distribute
Dependencies: Services
Services:• Replicated pods
• Source pod is a template• Auto-restart member pods• Abstract name (DNS)• IP address for the service
• in addition to the members• Load balancing among replicas
Load Balancer
Service IP

Google confidential │ Do not distribute
Example: Rolling Upgrade with Labels
Servers:
Labels:frontend
v1.2
frontend
v1.2
frontend
v1.2
frontend
v1.2
frontend
v1.3
frontend
v1.3
frontend
v1.3
frontend
v1.3
frontend
Replication Controller
replicas: 4
v1.2
Replication Controller
replicas: 1
v1.3
replicas: 3 replicas: 2replicas: 3replicas: 2replicas: 1 replicas: 4replicas: 0

Google confidential │ Do not distribute
SummaryA new path for Cloud Native applications:• Collection of independent (micro) services• Each service evolves on its own
• Scale as needed• Update as needed• Mix versions as needed
• Pods are a building block• Template for service members• Group containers and volumes• Dedicated IP and thus port space
• Containers simplify deployment

Latest Google Innovation

2012 20132002 2004 2006 2008 2010
Cloud Dataflow
History of Big Data at GoogleWhy Cloud Dataflow?
MapReduce
GFS Big Table
Dremel
Pregel
Flume
Colossus
SpannerMillWheel

Time to answer some Big Data questions
1M Devices
16.6K Events/sec
43B Events/month
518B Events/year
What was the average viewing time over the
past 7 days, compared to the last year?
How many active viewers did I have in the
last minute?
How many sales were made in the last
hour due to advertising conversion?

“One” approach
1M Devices
16.6K Events/sec
43B Events/month
518B Events/month
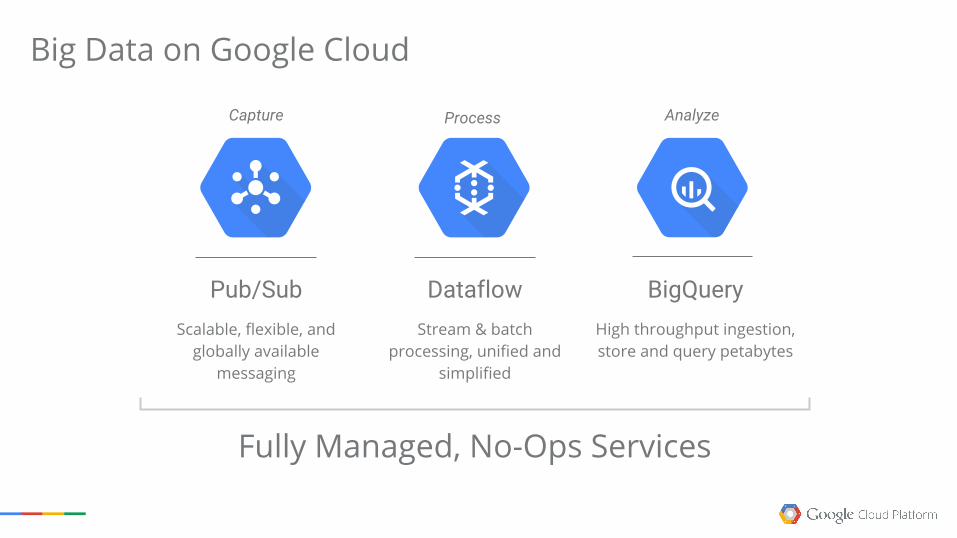
Big Data on Google Cloud
BigQueryHigh throughput ingestion, store and query petabytes
DataflowStream & batch
processing, unified and simplified
Pub/SubScalable, flexible, and
globally available messaging
Fully Managed, No-Ops Services
Capture Process Analyze

Cloud Dataflow
Cloud Dataflow is a collection of SDKs for
building batch or streaming parallelized
data processing pipelines.
Cloud Dataflow is a fully managed & elastic service
for executing optimized parallelized data processing
pipelines.

Benefits of Cloud Dataflow
❯ No Ops - truly elastic data processing for the cloud• On demand resource allocation w/intelligent auto-scaling• Automated worker optimization
❯ Unified model for batch & stream based processing • Flexible I/O support• Fine grained correctness primitives
❯ Open sourced SDK @ github• Java 7 today @ /GoogleCloudPlatform/DataflowJavaSDK• Python 2 in progress• Scala @/darkjh/scalaflow & /jhlch/scala-dataflow-dsl• Spark runner@ /cloudera/spark-dataflow• Flink runner @ /dataArtisans/flink-dataflow

Optimizing Your Time To Answer
More time to dig into your data
Programming
Resource provisioning
Performance tuning
Monitoring
ReliabilityDeployment & configuration
Handling Growing Scale
Utilization improvements
Data Processing with Cloud DataflowTypical Data Processing
Programming

• Movement
• Filtering
• Enrichment
• Shaping
• Reduction
• Batch computation
• Continuous computation
• Composition
• External orchestration
• Simulation
Where might you use Cloud Dataflow?
AnalysisETL Orchestration

The tension and polarity of Big Data
AccuracySpeed
Cost control Complexity
Time to answer

Let’s build something
1M Devices
16.6K Events/sec
43B Events/month
518B Events/month
Cloud Pub/Sub Cloud Dataflow BigQuery
How many active viewers did I have in the last minute?

Let’s build something
1M Devices
16.6K Events/sec
43B Events/month
518B Events/month
Cloud Dataflow BigQuery
How many active viewers did I have in the last minute?

Let’s build something
1M Devices
16.6K Events/sec
43B Events/month
518B Events/month
Cloud Dataflow
How many active viewers did I have in the last minute?
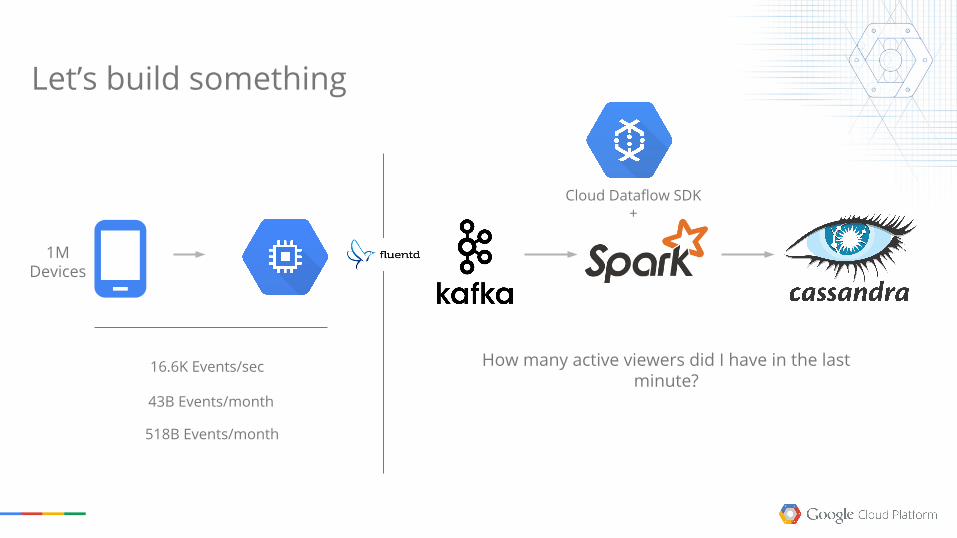
Let’s build something
1M Devices
16.6K Events/sec
43B Events/month
518B Events/month
Cloud Dataflow SDK+
How many active viewers did I have in the last minute?

Thank you!http://cloud.google.com







