

CMLCML
Heap Data Management for Limited Local Memory
(LLM) Multicore Processors
Ke Bai, Aviral ShrivastavaCompiler Micro-architecture Lab
CMLCML
From multi- to many-core processors
• Simpler design and verification– Reuse the cores
• Can improve performance without much increase in power
– Each core can run at a lower frequency
• Tackle thermal and reliability problems at core granularity
IBM XCell 8i GeForce 9800 GT
Tilera TILE64
04/19/20232
http://www.public.asu.edu/~ashriva6/cml

CMLCML
Memory Scaling Challenge
• In Chip Multi Processors (CMPs) , caches provide the illusion of a large unified memory– Bring required data from wherever into the
cache– Make sure that the application gets the latest
copy of the data• Caches consume too much power
– 44% power, and greater than 34 % area• Cache coherency protocols do not scale
well– Intel 48-core Single Cloud-on-a-Chip, and
Intel 80-core processors have non-coherent caches
arm925%
SysCtl3%
CP 152%
BIU8%
PATagRAM1%
Clocks4%
Other4%
D MMU5%
D Cache19%
I Cache25%
I MMU4%
Intel 80 core chip
Strong ARM 1100
04/19/20233 http://www.public.asu.edu/~ashriva6/cml

CML
PPE
Element Interconnect Bus (EIB)
Off-chip Global Memory
PPE: Power Processor ElementSPE: Synergistic Processor ElementLS: Local Store
SPE 0 SPE 2
SPE 5
SPE 4
SPE 3SPE 1
SPE 6
LS
SPU
Limited Local Memory Architecture
• Cores have small local memories (scratch pad)– Core can only access local memory– Accesses to global memory through explicit DMAs in the program
• E.g. IBM Cell architecture, which is in Sony PS3.
SPE 7
04/19/20234
http://www.public.asu.edu/~ashriva6/cml

CMLCML
LLM Programming• Thread based programming, MPI like communication
#include<libspe2.h>
extern spe_program_handle_t hello_spu;
int main(void){int speid, status;
speid (&hello_spu);
}
Main Core
<spu_mfcio.h>
int main(speid, argp){printf("Hello world!\n");} Local
Core<spu_mfcio.h>
int main(speid, argp){printf("Hello world!\n");} Local
Core
<spu_mfcio.h>
int main(speid, argp){printf("Hello world!\n");} Local
Core<spu_mfcio.h>
int main(speid, argp){printf("Hello world!\n");} Local
Core
<spu_mfcio.h>
int main(speid, argp){printf("Hello world!\n");} Local
Core<spu_mfcio.h>
int main(speid, argp){printf("Hello world!\n");} Local
Core
= spe_create_thread
• Extremely power-efficient computation– If all code and data fit into the local memory of the cores
04/19/20235 http://www.public.asu.edu/~ashriva6/cml

CMLCML
What if thread data is too large?
32 KB
32 KB
24 KB
24 KB
24 KB
Two threads with 32 KB memory each
Three cores with 24 KB memory each
2. Manage data to execute in limited memory of core– Easier and portable
Two Options1. Repartition and re-parallelize the application
– Can be counter-intuitive and hard
04/19/20236 http://www.public.asu.edu/~ashriva6/cml

CML
Managing data
Local Memory Aware Code
Original Code
int global;
f1(){ int a,b; global = a + b;
f2(); }
int global;
f1(){ int a,b; DMA.fetch(global) global = a + b; DMA.writeback(global) DMA.fetch(f2) f2();}
04/19/20237 http://www.public.asu.edu/~ashriva6/cml

CML
Heap Data Management• All code and data need to be managed
– Stack, heap, code and global• This paper focuses on heap data management
– Heap data management is difficult• Heap size is dynamic, while the size of code and global
data are statically known• Heap data size can be unbounded
– Cell programming manual suggests “Use heap data at your own risk”.
• Restricting heap usage is restrictive for programmers
main() { for (i=0; i<N; i++) { item[i] = malloc(sizeof(Item)); } F1();}
code
global
stack
heap
heapheap
stack
04/19/20238 http://www.public.asu.edu/~ashriva6/cml

CMLCML
Outline of the talk• Motivation
• Related works on heap data management
• Our Approach of Heap Data Management
• Experiments
04/19/20239 http://www.public.asu.edu/~ashriva6/cml

CMLCML
Related Works• Local memories in each core are similar to SPMs• Extensive works are proposed for SPM
– Stack: Udayakumaran2006,Dominguez2005, Kannan2009– Global: Avissar2002, Gao2005, Kandemir2002, Steinke2002– Code: Janapsatya2006, Egger2006, Angiolini2004, Pabalkar2008– Heap: Dominguez2005, Mcllroy2008
ARM SPM
Global Memory
DMA
ARM Memory Architecture
SPE LLM
Global Memory
DMA
IBM Cell Memory Architecture
direct access
SPM is for Optimization SPM is Essential
04/19/202310 http://www.public.asu.edu/~ashriva6/cml

CMLCML
Our Approach
malloc2malloc1
Heap Size = 32bytessizeof(student)=16bytes
HP
Local Memory Global Memory
GM_HP
typedef struct{ int id; float score;}Student;
main() { for (i=0; i<N; i++) { student[i] = malloc( sizeof(Student) ); } for (i=0; i<N; i++) { student[i].id = i; }}
malloc3
• mymalloc()—May need to evict older heap
objects to global memory—It may need to allocate more
global memory
• malloc()— allocates space in local
memory
04/19/202311 http://www.public.asu.edu/~ashriva6/cml
CMLCML
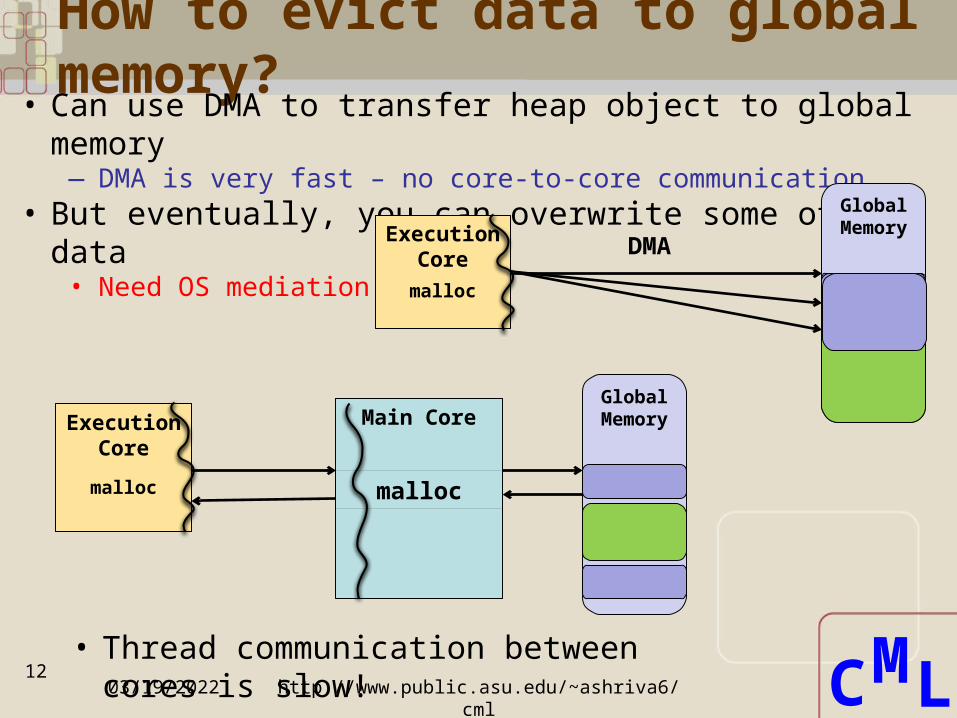
How to evict data to global memory?
• Can use DMA to transfer heap object to global memory— DMA is very fast – no core-to-core communication
• But eventually, you can overwrite some other data• Need OS mediation
Execution Core
malloc
Main Core
malloc
Global Memory
Execution Core
malloc
Global Memory
DMA
• Thread communication between cores is slow!04/19/2023
12http://www.public.asu.edu/~ashriva6/cml
CMLCML
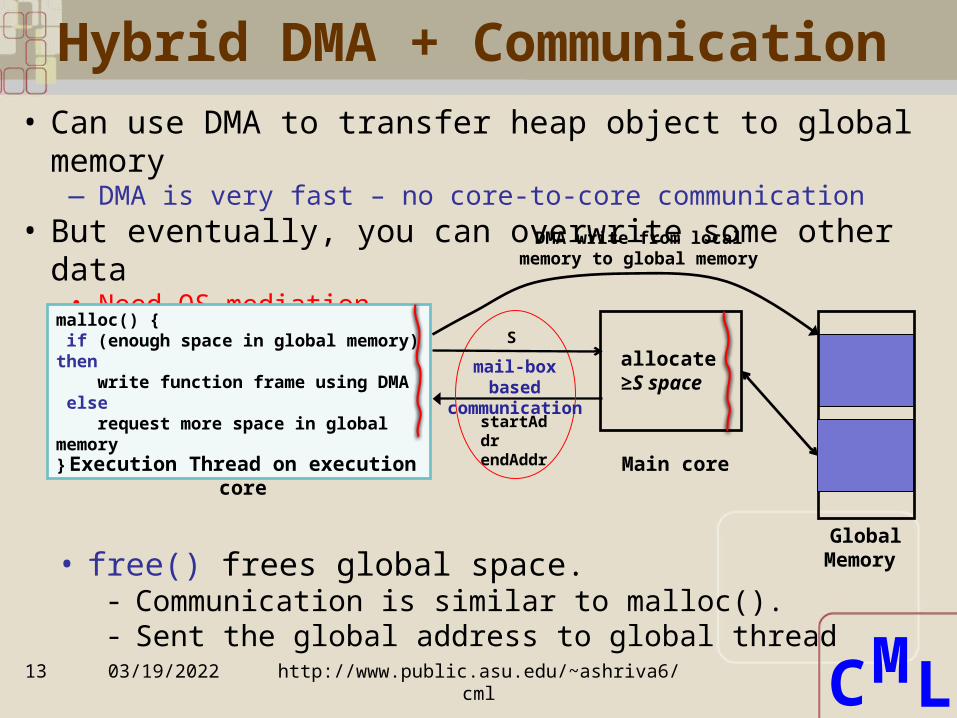
Hybrid DMA + Communication
• Can use DMA to transfer heap object to global memory— DMA is very fast – no core-to-core communication
• But eventually, you can overwrite some other data• Need OS mediation
malloc() { if (enough space in global memory) then write function frame using DMA else request more space in global memory}Execution Thread on execution
core
S
startAddr endAddr
mail-box based
communication
Global Memory
allocate ≥S space
DMA write from local memory to global
memory
• free() frees global space.- Communication is similar to malloc().- Sent the global address to global thread
Main core
04/19/202313 http://www.public.asu.edu/~ashriva6/cml

CMLCML
Address Translation Functions
• Mapping from SPU address to global address is one to many.
– Cannot easily find global address from SPU address• All heap accesses must happen through global addresses
main() { for (i=0; i<N; i++) { student[i] = malloc( sizeof(Student) ); } for (i=0; i<N; i++) { student[i].id = i; }}
malloc2malloc1
Heap Size = 32bytessizeof(student)=16bytes
HP
Local Memory Global Memory
GM_HP
malloc3
student[i] = p2s(student[i]);
student[i] = s2p(student[i]);
• p2s() will translate the global address to spu address– Make sure the heap object is in the local memory
• s2p() will translate the spu address to global address
04/19/202314 http://www.public.asu.edu/~ashriva6/cmlMore details in the paper

CML
Heap Management API
typedef struct{ int id; float score;}Student;
main() {for (i=0; i<N; i++) { student[i] = malloc(sizeof(Student)); student[i].id = i; }}
malloc()• allocate space in
local memory and global memory and return global addr
free()• free space in the
global memoryp2s()• Assures heap
variable exists in the local memory and uses spuAddr.
s2p() • Translate the
spuAddr back to ppuAddr.
• Code with Heap
Management
• Original Code
typedef struct{ int id; float score;}Student;
main() {for (i=0; i<N; i++) { student[i] = malloc(sizeof(Student)); student[i].id = i; }}
student[i] = p2s(student[i]);student[i] = s2p(student[i]);
Our approach provides an illusion of unlimited space in the local memory!
04/19/2023 15http://www.public.asu.edu/~ashriva6/cml

CMLCML
Experimental Setup
• Sony PlayStation 3 running a Fedora Core 9 Linux
• MiBench Benchmark Suite and other possible applications
http://www.public.asu.edu/~kbai3/publications.html
• The runtimes are measured with spu_decrementer() for SPE and _mftb() for the PPE provided with IBM Cell SDK 3.1
04/19/202316 http://www.public.asu.edu/~ashriva6/cml

CMLCML
Unrestricted Heap Size
1 10 100
1000
1000
0
1000
001000
10000
100000
1000000
10000000
100000000
1000000000
10000000000
no-management
number of nodes in rbTree
Runti
me(u
s)
N>6800Program crashes!!!
Runtimes are comparable
04/19/202317 http://www.public.asu.edu/~ashriva6/cml

CMLCML
4 16 64 256
1024
4096
1638
41000
10000100000
100000010000000
1000000001000000000 DFS
dijkstra
fft
fft_inverse
MST
rbTree
stringsearch
Log o
f R
unti
me(u
s)
Heap size (bytes)
Larger Heap Space Lower Runtime
04/19/202318 http://www.public.asu.edu/~ashriva6/cml
CMLCML
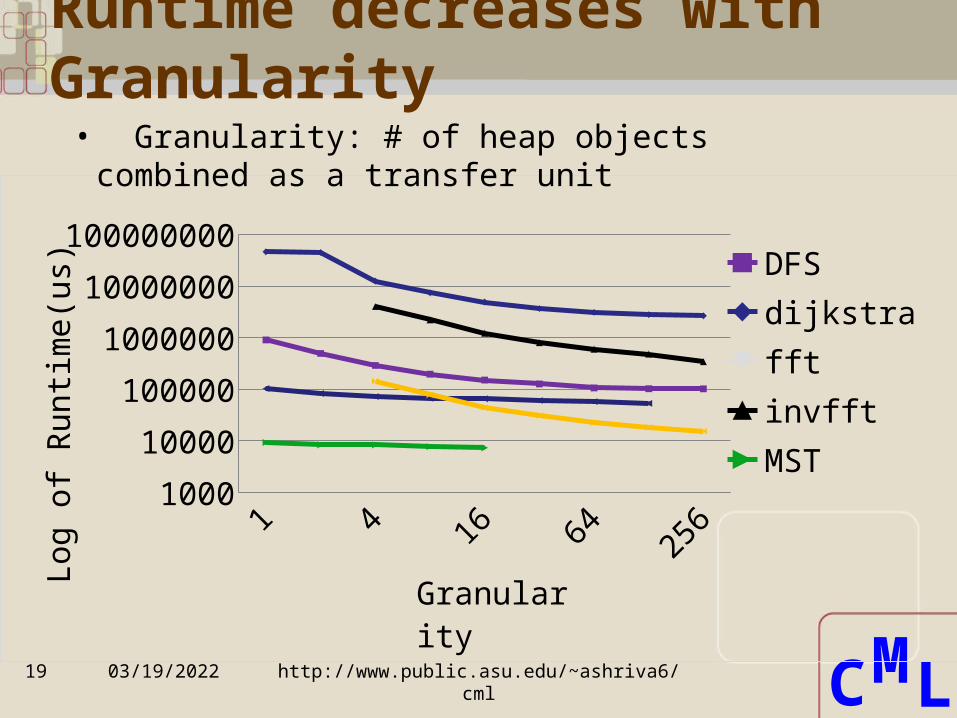
Runtime decreases with Granularity
1 2 4 8 16 32 64 128
256
1000
10000
100000
1000000
10000000
100000000DFSdijkstrafftinvfftMSTrbTree
Log o
f R
unti
me(u
s)
Granularity
• Granularity: # of heap objects combined as a transfer unit
04/19/202319 http://www.public.asu.edu/~ashriva6/cml
CMLCML
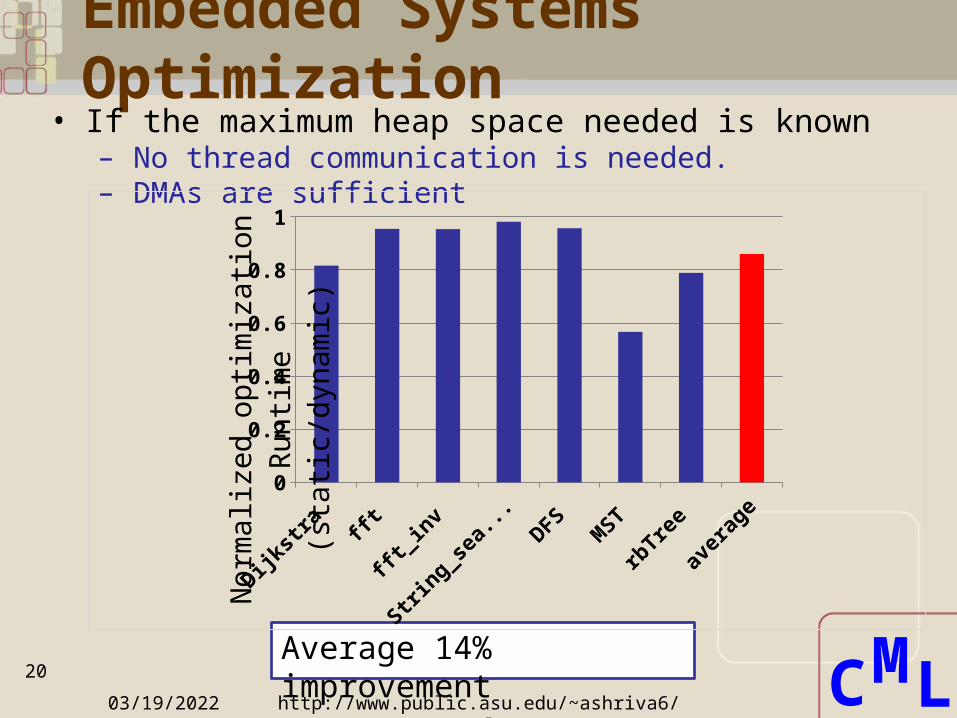
Embedded Systems Optimization
• If the maximum heap space needed is known– No thread communication is needed. – DMAs are sufficient
Average 14% improvement
Dijkst
ra
fft
fft_in
v
Strin
g_se
arch
DFS
MST
rbTr
ee
aver
age
0
0.2
0.4
0.6
0.8
1N
orm
aliz
ed o
ptim
izati
on R
untim
e(s
tatic
/dyn
amic
)
04/19/2023
20
http://www.public.asu.edu/~ashriva6/cml
CMLCML
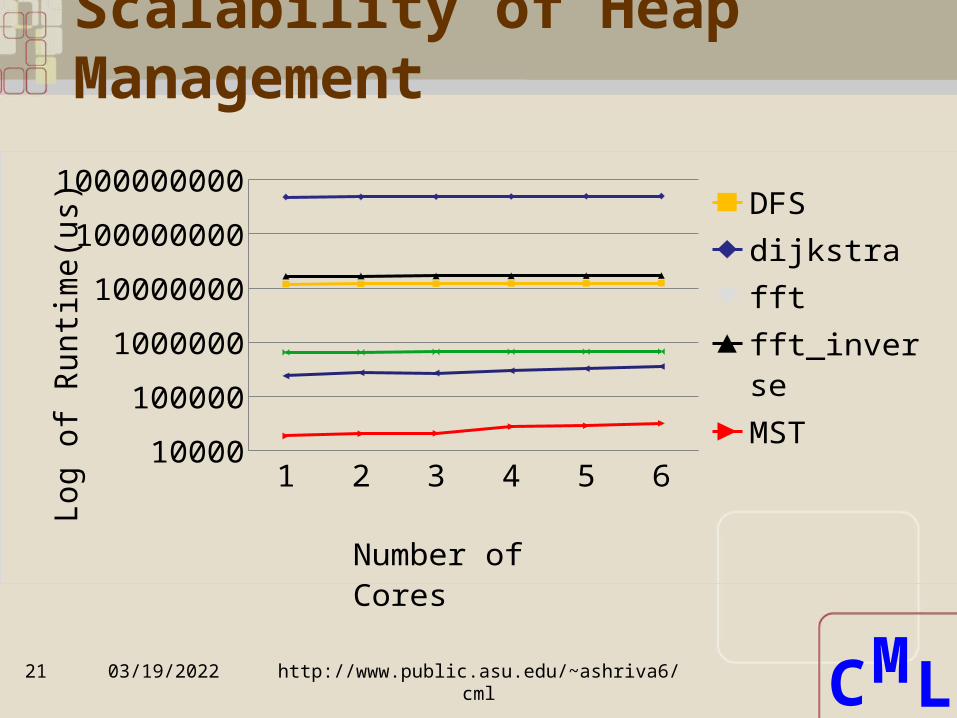
Scalability of Heap Management
1 2 3 4 5 610000
100000
1000000
10000000
100000000
1000000000DFS
dijkstra
fft
fft_inverse
MST
rbTree
Log o
f R
unti
me(u
s)
Number of Cores
04/19/202321 http://www.public.asu.edu/~ashriva6/cml

CMLCML
Summary• Moving from multi-core to many-core systems• Scaling the memory architecture is a major challenge• Limited Local Memory architectures are promising• Code and data should be managed if they can not fit in the
limited local memory• We propose a heap data management scheme
– Manage any size of heap data in a constant space in local memory– It’s automatable, then can increase productivity of programmers– It’s scalable for different number of cores– Overhead ~ 4-20%
• Comparison with software cache– Does not support pointer– One SW cache for one data type– Cannot optimize any further
04/19/202322 http://www.public.asu.edu/~ashriva6/cml







