

Huaping Luo
Oct 2016
NVIDIA DEEP LEARNING PLATFORM

2
PC INTERNETWinTel, Yahoo!1 billion PC users
AI & IOTDeep Learning, GPU100s of billions of devices
MOBILE-CLOUDiPhone, Amazon AWS2.5 billion mobile users
1995 2005 2015
A NEW ERA OF COMPUTING
“ It’s clear we’re moving from a mobile first to an AI-first world ”Sundar Pichai, Google CEO

3
Artificial IntelligenceComputer GraphicsGPU Computing
NVIDIA“THE AI COMPUTING COMPANY”

4
TESLA ACCELERATED COMPUTING PLATFORMFocused on Co-Design for Accelerated Data Center
ProductiveProgrammingModel & Tools
Expert Co-Design
Accessibility
APPLICATION
MIDDLEWARE
SYS SW
LARGE SYSTEMS
PROCESSOR
Fast GPUEngineered for High Throughput
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
5.5
2008 2010 2012 2014 2016
NVIDIA GPU x86 CPUTFLOPS
M2090M1060
K20
K80
Fast GPU+
Strong CPU
P100

5
TEN YEARS OF GPU COMPUTING
2006 2008 2012 20162010 2014
Fermi: World’s First HPC GPU
Oak Ridge Deploys World’s Fastest Supercomputer w/ GPUs
World’s First Atomic Model of HIV Capsid
GPU-Trained AI Machine Beats World Champion in Go
Stanford Builds AI Machine using GPUs
World’s First 3-D Mapping of Human Genome
CUDA Launched
World’s First GPU Top500 System
Google Outperforms Humans in ImageNet
Discovered How H1N1 Mutates to Resist Drugs
AlexNet beats expert code by huge margin using GPUs

6
AI IS EVERYWHERE
“Find where I parked my car” “Find the bag I just saw in this magazine”
“What movie should I watch next?”

7
TOUCHING OUR LIVES
Bringing grandmother closer to family by bridging language barrier
Predicting sick baby’s vitals like heart rate, blood pressure, survival rate
Enabling the blind to “see” their surrounding, read emotions on faces

8
FUELING ALL INDUSTRIES
Increasing public safety with smart video surveillance at airports & malls
Providing intelligent services in hotels, banks and stores
Separating weeds as it harvests, reduces chemical usage by 90%

9
Device
TESLA GPU DEEP LEARNING PLATFORM
TRAINING
DIGITS Training System
Deep Learning Frameworks
Tesla P100, DGX1
DATACENTER INFERENCING
DeepStream SDK
TensorRT
Tesla P40 & P4

10
Device
TESLA GPU DEEP LEARNING PLATFORM
TRAINING DATACENTER INFERENCING
Training: comparing to Kepler GPU in 2013 using Caffe, Inference: comparing img/sec/watt to CPU: Intel E5-2697v4 using AlexNet
65Xin 3 years
Tesla P100
40Xvs CPU
Tesla P4

11
END-TO-END PRODUCT FAMILY
FULLY INTEGRATED DLSUPERCOMPUTER
DGX-1
For customers who need to get going now with fully
integrated solution
HYPERSCALE HPC
Hyperscale deployment for deep learning training &
inference
Training - Tesla P100
Inference - Tesla P40 & P4
STRONG-SCALE HPC
Data centers running HPC and DL apps scaling to multiple
GPUs
Tesla P100 with NVLink
MIXED-APPS HPC
HPC data centers running mix of CPU and GPU
workloads
Tesla P100 with PCI-E

12
TESLA PLATFORM FOR DL TRAINING

13NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
TESLA P100New GPU Architecture to Enable the World’s Fastest Compute Node
Pascal Architecture NVLink HBM2 Memory Page Migration Engine
Highest Compute Performance GPU Interconnect for Maximum Scalability
Ultra-high memory bandwidth Simple Parallel Programming with Virtually Unlimited Memory Space
Unified Memory
CPU
Tesla P100

14
P100 FOR FASTEST DL TRAININGM40 MAXWELL P40 PASCAL P100 PASCAL
FP16 / FP32 (TFLOPs)
NA / 7 NA / 12 21.2 / 10.6
Register File 6 MB 7.5 MB 14 MB
Memory BW 288 GB/s 346 GB/s 732 GB/s
Chip-Chip BW 32 GB/s (PCIE) 32 GB/s (PCIE)160 GB/s (NVLINK)
+ 32 GB/s (PCIE)
Mem Size (Max DL model size)
24 GB 24 GB 16GB (Data Parallel)
16GB x 8 (Model Parallel)

15
P100 FOR FASTEST TRAINING
0.0x
0.5x
1.0x
1.5x
2.0x
2.5x
AlexnetOWT GoogLenet VGG-D Incep v3 ResNet-50
8x K80 8x M40 8x P40 8x P100 PCIE DGX-1
Deepmark test with NVCaffe. AlexnetOWT/GoogLenet use batch 128, VGG-D uses batch 64, Incep-v3/ResNet-50 use batch 32, weak scalingK80/M40/P100/DGX-1 are measured, P40 is projected, software optimization in progress, CUDA8/cuDNN5.1, Ubuntu 14.04
Speedup
Img/sec7172 2194 578 526 661
FP32 Training

16
NVLINK ENABLES LINEAR MULTI-GPU SCALING
1.0x
2.0x
3.0x
4.0x
5.0x
6.0x
7.0x
8.0x
1GPU 2GPU 4GPU 8GPU
AlexnetOWT
DGX-1
P100 PCIE
Deepmark test with NVCaffe. AlexnetOWT use batch 128, Incep-v3/ResNet-50 use batch 32, weak scaling, P100 and DGX-1 are measured, FP32 training, software optimization in progress, CUDA8/cuDNN5.1, Ubuntu 14.04
1.0x
2.0x
3.0x
4.0x
5.0x
6.0x
7.0x
8.0x
1GPU 2GPU 4GPU 8GPU
Incep-v3
DGX-1
P100 PCIE
1.0x
2.0x
3.0x
4.0x
5.0x
6.0x
7.0x
8.0x
1GPU 2GPU 4GPU 8GPU
ResNet-50
DGX-1
P100 PCIE
Speedup
2.3x
1.3x
1.5x

17
TESLA PLATFORM FOR DL INFERENCE & VIDEO

18
40x Efficient vs CPU, 8x Efficient vs FPGA
0
50
100
150
200
AlexNet
CPU FPGA 1x M4 (FP32) 1x P4 (INT8)
Imag
es/S
ec/W
att
Maximum Efficiency for Scale-out Servers P4# of CUDA Cores 2560
Peak Single Precision 5.5 TeraFLOPS
Peak INT8 22 TOPS
Low Precision 4x 8-bit vector dot product with 32-bit accumulate
Video Engines 1x decode engine, 2x encode engine
GDDR5 Memory 8 GB @ 192 GB/s
Power 50W & 75 W
AlexNet, batch size = 128, CPU: Intel E5-2690v4 using Intel MKL 2017, FPGA is Arria10-1151x M4/P4 in node, P4 board power at 56W, P4 GPU power at 36W, M4 board power at 57W, M4 GPU power at 39W, Perf/W chart using GPU power
TESLA P4

19
TESLA P40
P40# of CUDA Cores 3840
Peak Single Precision 12 TeraFLOPS
Peak INT8 47 TOPS
Low Precision 4x 8-bit vector dot product with 32-bit accumulate
Video Engines 1x decode engine, 2x encode engines
GDDR5 Memory 24 GB @ 346 GB/s
Power 250W
0
20,000
40,000
60,000
80,000
100,000
GoogLeNet AlexNet
8x M40 (FP32) 8x P40 (INT8)
Imag
es/S
ec
4x Boost in Less than One Year
GoogLeNet, AlexNet, batch size = 128, CPU: Dual Socket Intel E5-2697v4
Highest Throughput for Scale-up Servers

20NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
P40/P4 – NEW “INT8” FOR INFERENCE
A0A1A2A3
B0B1B2B3
A0 * B0
A1 * B1
A2 * B2
A3 * B3
4x INT8
4x INT8
INT32 intermediate
INT32 intermediate
INT32 intermediate
INT32 intermediate
INT32C
INT32
PRODUCT PRECISION INFERENCE TOPS*
M4 FP32 2.2
M40 FP32 7
P100 FP16 21.2
P4 INT8 22
P40 INT8 47
• Integer 8-bit Dot Product with 32-bit accumulate
• New in Pascal, only in P40/P4
*TOPS = Tera-Operations per second, base on boost clocks

21NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
178480
1,514
4,121
3,200
6,514
0
1,000
2,000
3,000
4,000
5,000
6,000
7,000
E5-2690v414 Core
M4(FP32)
M40(FP32)
P100(FP16)
P4(INT8)
P40(INT8)
Infe
renc
e Im
age/
sec
All results are measured, based on GoogLenet with batch size 128Xeon uses MKL 2017 GOLD with FP32, GPU uses TensorRT internal development ver.
P40/P4+TensorRT DELIVER MAX INFERENCE PERFORMANCE
>35x
1.4
12.3 10.6
27.9
91.1
56.3
0
20
40
60
80
100
E5-2690v414 Core
M4(FP32)
M40(FP32)
P100(FP16)
P4(INT8)
P40(INT8)
Infe
renc
e Im
g/s/
wat
t
>60x
P40 For Max Inference Throughput P4 For Max Inference Efficiency

22NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
4.8 1.5 0.2
21.2
169
91
12
0
20
40
60
80
100
120
140
160
180
AlexNet GoogLeNet VGG-19
CPU FPGA P4
643212 30
950
6,250
3,280
430
0
1000
2000
3000
4000
5000
6000
7000
AlexNet GoogLeNet VGG-19
CPU FPGA P4
CPU NO LONGER RIGHT SOLUTION FOR DEEP LEARNING INFERENCE
EfficiencyImages/Sec/Watt
CPU: E5-2699v4 + IntelCaffe + MKL Gold. P4: TensorRT 8-bit
ThroughputImages/Sec
0
100
200
300
400
500
1 2 3 4 5 6 7 8 9 10
Inference Execution Time (ms) with VGG-19
Real Time Region
Xeon E5-2690v4
P4P40
Batch Size

23NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
UP TO 10X MORE TRANSCODED VIDEO STREAMS
2 3 46
8
16 15
32
18
35 35
70
0
10
20
30
40
50
60
70
80
1080p30 HighQuality
1080p30 HighSpeed
720p30 HighQuality
720p30 HighSpeed
CPU M4 P4
# St
ream
s
M4 P4
H.264 and HEVC/H.265 H.264 and HEVC/H.265
H.264 8-bit 4:2:0, 4:4:4 and lossless encoding
HEVC/H.265 8-bit 4:2:0 encoding
H.264 8-bit 4:2:0, 4:4:4 and lossless encoding
HEVC/H.265 8-bit/10 bit 4:2:0 encoding
Max resolution: 4096 × 4096 Max resolution: 8192 x 8192 (HEVC), 4096 × 4096 (others)
Encode Capabilities
Transcode: Dual Socket E5-2680v4 + libx264; Dual Socket E5-2680v4 + P4 + video Codec SDK 1080p30 slow, 20% of CPU capacity assigned to transcode.

24
NVIDIA TensorRTHigh-performance deep learning inference for production deployment
developer.nvidia.com/tensorrt
High performance neural network inference engine for production deployment
Generate optimized and deployment-ready models for datacenter, embedded and automotive platforms
Deliver high-performance, low-latency inference demanded by real-time services
Deploy faster, more responsive and memory efficient deep learning applications with INT8 and FP16 optimized precision support
0
1,000
2,000
3,000
4,000
5,000
6,000
7,000
2 8 128
CPU-OnlyTesla P40 + TensorRT (FP32)Tesla P40 + TensorRT (INT8)
Up to 36x More Image/sec
Batch Size
GoogLenet, CPU-only vs Tesla P40 + TensorRTCPU: 1 socket E4 2690 v4 @2.6 GHz, HT-onGPU: 2 socket E5-2698 v3 @2.3 GHz, HT off, 1 P40 card in the box
Imag
es/S
econ
d
25
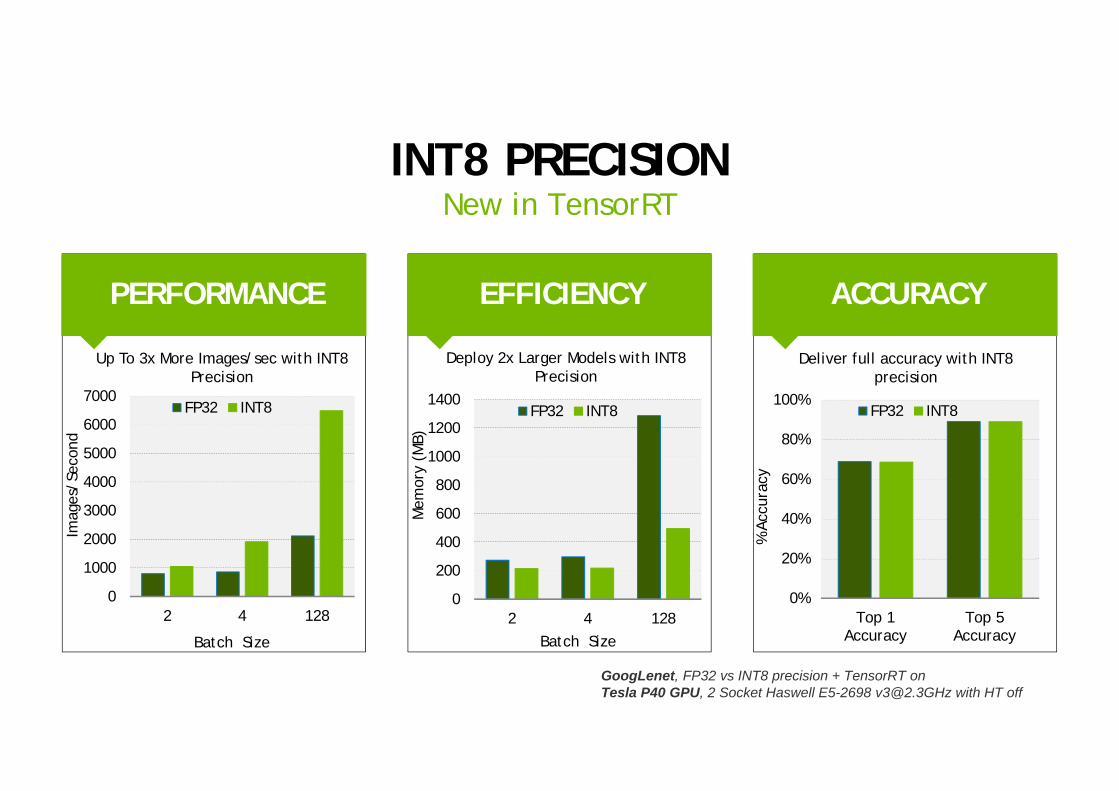
INT8 PRECISIONNew in TensorRT
ACCURACYEFFICIENCYPERFORMANCE
0
1000
2000
3000
4000
5000
6000
7000
2 4 128
FP32 INT8
Up To 3x More Images/sec with INT8 Precision
Batch Size
GoogLenet, FP32 vs INT8 precision + TensorRT on Tesla P40 GPU, 2 Socket Haswell E5-2698 [email protected] with HT off
Imag
es/S
econ
d
0
200
400
600
800
1000
1200
1400
2 4 128
FP32 INT8
Deploy 2x Larger Models with INT8 Precision
Batch Size
Mem
ory
(MB)
0%
20%
40%
60%
80%
100%
Top 1Accuracy
Top 5Accuracy
FP32 INT8
Deliver full accuracy with INT8 precision
% Ac
cura
cy

26
NVIDIA SDK FOR DEEP LEARNING

27
POWERING THE DEEP LEARNING ECOSYSTEMNVIDIA SDK accelerates every major framework
COMPUTER VISION
OBJECT DETECTION IMAGE CLASSIFICATION
SPEECH & AUDIO
VOICE RECOGNITION LANGUAGE TRANSLATION
NATURAL LANGUAGE PROCESSING
RECOMMENDATION ENGINES SENTIMENT ANALYSIS
DEEP LEARNING FRAMEWORKS
Mocha.jl
NVIDIA DEEP LEARNING SDK
developer.nvidia.com/deep-learning-software

28
NVIDIA DEEP LEARNING SOFTWARE PLATFORM
NVIDIA DEEP LEARNING SDK
TensorRT
Embedded
Automotive
Data center
DIGITS
TrainingData
Training
Data Management
Model Assessment
Trained NeuralNetwork
developer.nvidia.com/deep-learning-software

29
NVIDIA DIGITSInteractive Deep Learning GPU Training System
developer.nvidia.com/digits
Interactive deep neural network development environment for image classification and object detection
Schedule, monitor, and manage neural network training jobs
Analyze accuracy and loss in real time
Track datasets, results, and trained neural networks
Scale training jobs across multiple GPUs automatically

30
NVIDIA cuDNNAccelerating Deep Learning
developer.nvidia.com/cudnn
High performance building blocks for deep learning frameworks
Drop-in acceleration for widely used deep learning frameworks such as Caffe, CNTK, Tensorflow, Theano, Torch and others
Accelerates industry vetted deep learning algorithms, such as convolutions, LSTM, fully connected, and pooling layers
Fast deep learning training performance tuned for NVIDIA GPUs
Deep Learning Training PerformanceCaffe AlexNet
Spee
d-up
of
Imag
es/S
ec v
s K4
0 in
201
3
K40 K80 + cuDN…
M40 + cuDNN4
P100 + cuDNN5
0x
10x
20x
30x
40x
50x
60x
70x
80x
“ NVIDIA has improved the speed of cuDNNwith each release while extending the interface to more operations and devices at the same time.”— Evan Shelhamer, Lead Caffe Developer, UC Berkeley
AlexNet training throughput on CPU: 1x E5-2680v3 12 Core 2.5GHz. 128GB System Memory, Ubuntu 14.04M40 bar: 8x M40 GPUs in a node, P100: 8x P100 NVLink-enabled

31
0 50 100 150 200 250 300
P40
P4
1x CPU (14 cores)
Inference Execution Time (ms)
11 ms
6 ms
User Experience: Instant Response45x Faster with Pascal + TensorRT
Faster, more responsive AI-powered services such as voice recognition, speech translation
Efficient inference on images, video, & other data in hyperscale production data centers
Based on VGG-19 from IntelCaffe Github: https://github.com/intel/caffe/tree/master/models/mkl2017_vgg_19CPU: IntelCaffe, batch size = 4, Intel E5-2690v4, using Intel MKL 2017 | GPU: Caffe, batch size = 4, using TensorRT internal version
INTRODUCING NVIDIA TensorRTHigh Performance Inference Engine
260 ms
Training
Device
Datacenter

32
NVIDIA DEEPSTREAM SDKDelivering Video Analytics at Scale
Inference
PreprocessHardware Decode
“Boy playing soccer”
Simple, high performance API for analyzing video
Decode H.264, HEVC, MPEG-2, MPEG-4, VP9
CUDA-optimized resize and scale
TensorRT
0
20
40
60
80
100
1x Tesla P4 Server +DeepStream SDK
13x E5-2650 v4 ServersCo
ncur
rent
Vid
eo S
trea
ms
Concurrent Video Streams Analyzed
720p30 decode | IntelCaffe using dual socket E5-2650 v4 CPU servers, Intel MKL 2017Based on GoogLeNet optimized by Intel: https://github.com/intel/caffe/tree/master/models/mkl2017_googlenet_v2

33
TESLA PASCAL FAMILY

34
TESLA PRODUCTS RECOMMENDATIONPRODUCT P100 NVLINK P100 PCIE P40 P4
Target Use Cases
• Highest DL training perf• Fastest time-to-solution• Larger “Model Parallel”
DL model with 16GB x 8
• HPC DC running mix of CPU and GPU workload
• Best throughput / $ with mix workload
• Highest inference perf• Simplify DC operations:
training & inference in the same server
• Larger “Data Parallel” DL model with 24GB
• Low power, low profile optimized for scale out deployment
• Most efficient inference and video processing
Best Configs. • 8 way Hybrid Cube Mesh • 2-4 GPU/node (HPC)
• 8 GPU/node (DL Train) • Up to 8 GPU/node
• 1-2 GPU/node for scale out
• Up to 8 GPU/node for dense transcode
1st Server Ship • Available Now • Available Now • OEM starting Oct’16 • OEM starting Nov’16

35
K80 M40 M4 P100(SXM2)
P100(PCIE) P40 P4
GPU 2x GK210 GM200 GM206 GP100 GP100 GP102 GP104
PEAK FP64 (TFLOPs) 2.9 NA NA 5.3 4.7 NA NA
PEAK FP32 (TFLOPs) 8.7 7 2.2 10.6 9.3 12 5.5
PEAK FP16 (TFLOPs) NA NA NA 21.2 18.7 NA NA
PEAK INT8 TIOPs NA NA NA NA NA 47 22
Memory Size 2x 12GB GDDR5 24 GB GDDR5 4 GB GDDR5 16 GB HBM2 16/12 GB HBM2 24 GB GDDR5 8 GB GDDR5
Memory BW 480 GB/s 288 GB/s 80 GB/s 732 GB/s 732/549 GB/s 346 GB/s 192 GB/s
Interconnect PCIe Gen3 PCIe Gen3 PCIe Gen3 NVLINK + PCIe Gen3
PCIe Gen3 PCIe Gen3 PCIe Gen3
ECC Internal + GDDR5 GDDR5 GDDR5 Internal + HBM2 Internal + HBM2 GDDR5 GDDR5
Form Factor PCIE Dual Slot PCIE Dual Slot PCIE LP SXM2 PCIE Dual Slot PCIE Dual Slot PCIE LP
Power 300 W 250 W 50-75 W 300 W 250 W 250 W 50-75 W
TESLA PRODUCTS DECODER







