

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 18, NO. 4, APRIL 2008 467
Real-Time Multimodal Human–Avatar InteractionYun Fu, Student Member, IEEE, Renxiang Li, Member, IEEE, Thomas S. Huang, Life Fellow, IEEE, and
Mike Danielsen
Abstract—This paper presents a novel real-time multimodalhuman–avatar interaction (RTM-HAI) framework with vi-sion-based remote animation control (RAC). The framework isdesigned for both mobile and desktop avatar-based human–ma-chine or human–human visual communications in real-worldscenarios. Using 3-D components stored in the Java mobile 3-D(M3G) file format, the avatar models can be flexibly constructedand customized on the fly on any mobile devices or systems thatsupport the M3G standard. For the RAC head tracker, we pro-pose a 2-D real-time face detection/tracking strategy through aninteractive loop, in which the detection and tracking complementeach other for efficient and reliable face localization, toleratingextreme user movement. With the face location robustly tracked,the RAC head tracker selects a main user and estimates the user’shead rolling, tilting, yawing, scaling, horizontal, and verticalmotion in order to generate avatar animation parameters. Theanimation parameters can be used either locally or remotely andcan be transmitted through socket over the network. In addition,it integrates audio-visual analysis and synthesis modules to realizemultichannel and runtime animations, visual TTS and real-timeviseme detection and rendering. The framework is recognizedas an effective design for future realistic industrial products ofhumanoid kiosk and human-to-human mobile communication.
Index Terms—Avatar, DAZ3D, head tracking, human–computerinteraction, mobile 3-D (M3G), multimodal system, real-timemultimodal human–avatar interaction (RTM-HAI), TTS, visualcommunication.
I. INTRODUCTION
THE humanoid actors in a virtual environment are repre-sented by realistic cartoon icons, called avatars [2], [8],
[19], that can be customized virtual stand-ins to substantiallyrepresent the user for nonverbal interactions with others at aremote location, using human-like expressions and gestures[18]. Even though the most common human-to-human commu-nication has been based on verbal messages in the last century,modern technologies start assisting people with nonverbalmessage exchange through their behaviors, such as facialexpressions, poses, and body languages. By using humanoidavatars as users or machine proxies, multimedia communica-tion and virtual reality communities are currently attempting toestablish human-friendly communication systems of multi-user
Manuscript received March 24, 2007; revised May 15, 2007. This paper wasrecommended by Associate Editor E. Izquierdo.
Y. Fu and T. S. Huang are with the Beckman Institute for Advanced Scienceand Technology, University of Illinois at Urbana-Champaign, Urbana, IL 61801USA (e-mail: [email protected]; [email protected]).
R. Li and M. Danielsen are with Multimedia Research Lab (MRL), MotorolaLabs, Schaumburg, IL 60196 USA (e-mail: [email protected]; [email protected]).
Color versions of one or more of the figures in this paper are available onlineat http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TCSVT.2008.918441
Internet-based virtual environments. Many significant tech-nical difficulties inspired by aesthetic requirements, such asenhancing realistic impressions and simplifying interactivemanipulations, induced rapidly expanding research. Particu-larly, realistic 3-D talking head synthesis has recently attractedincreasing attention for diversified applications in multimediacommunications, entertainment, interpersonal collaboration,experiments in natural language interactions, and interfaces foravatar control.
Various avatar head models and animation control techniqueshave been developed over the past three decades, since the pi-oneering work by Parke in the 1970s [20]. Among them areanatomy-based models, mesh-based models, and appearance-based models. Anatomy-based models digitize facial mesh withgeometric units representing face muscles, tissues, and skins. Itcan achieve reasonably lifelike rendering results, yet with thecost of computational complexity. Appearance-based models[2], [19] focus on object shapes and textures. These approachesneed to label several classes of object examples and separateshape and texture into vectors. A new object is represented bythe linear combination of these samples. Re-rendered objectappearance is produced via tuning standard model parameters.They yield photo-realistic avatar models, thus avoiding subjec-tive definition and data interpolation. Nevertheless, the diffi-culty of achieving a large-scale database, which covers enoughgeneral information of object attributes for the rendering task,makes it impractical for many implementations in real-worldscenarios.
The majority of the head models are mesh-based [1], sincethey are easy to manipulate for animation and caricatures withreasonable system resources. Within this category, there are anumber of varieties, described here.
1) Facial Morph-Based Models: Each morph deforms the facein a certain way, and morph-target-blending synthesizesfacial animations. A more detailed discussion is given inSection III.
2) Skeleton-Based Models: Skeletal models still use meshdata to represent the skin. A vertex may associate with oneor more bones. When a bone moves, the vertex positionthat is associated with this bone also moves. This providesa way to animate the facial mesh by changing the positionof the bones.
Once the avatar model is available, it can be used to facil-itate face-to-face communication in virtual space. This can beachieved by capturing a person’s facial motion in real world,communicating the facial motion parameters through commu-nication channel, and mapping the parameters to the person’savatar. There are a variety of approaches to control avatar ani-mations to simulate real human beings as closely as possible invirtual environments.
1051-8215/$25.00 © 2008 IEEE

468 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 18, NO. 4, APRIL 2008
1) Real-time agents [23]. For the avatar movements, a timeseries of joint angles are stored so that specific motionscan be replayed under real-time constraints. The major ad-vantages of prestored motions lie on the better algorithmicsecurity and fast execution speed.
2) Behavioral scripts [21]. The behavioral script is translatedfrom a given storyboard for predefined scenarios in the vir-tual environment. Characters created in this manner cansmoothly blend and layer animations. For real-time con-trol, external functions need to be added.
3) Script languages [22]. The existing script languages areapplication-dependent, allowing complex avatar storydevelopment.
4) Hierarchical animation control (HAC) [18]. The HACtechnique is represented according to the InternationalISO/IEC Humanoid Standard. Different function layerscontrol the specific properties and attributes of the avatarobject.
From research to product, it has been shown that there arelots of interesting opportunities in both academia and industrywhen human–human communication and human–machineinteraction are combined with multimedia and virtual reality,since recent advances in human–computer interaction (HCI)already allow real-time system [5], [10]–[12], [16] perfor-mance on both computer-based cooperative entertainment [27]and vision-based perceptual user interface [6]. For example,researchers have reported the successful development of suchsystems as human–avatar interactive table tennis simulation[25], [26], “camera mouse” for the elderly and disabled invision-based hand-free OS control [3], [24], and emotionaltalking head and virtual robot for human–machine interaction[7], [9].
A. Our Work
In view of foregoing discussions, we extend our previouswork in [4] and present a novel real-time multimodal humanavatar interaction (RTM-HAI) framework and introduce the as-sociated prototype system, which is designed for real-world ap-plications—mobile and desktop avatar-based visual communi-cations (AVC). RTM-HAI features run-time avatar customiza-tion as well as multichannel real-time animations including headpose, facial expressions, and visemes. The 3-D avatar uses Javamobile 3-D graphics (M3G1) [17] files as a basic building blockand is rendered in an M3G graphics environment, thus ensuringportability to any device that supports the M3G standard. Theframework, working appropriately for Linux and Windows, isrecognized as effective and integrated into the first generationof a commercial kiosk prototype.
The main contributions of our work are summarized asfollows.
• We propose the novel RTM-HAI framework for realisticapplications in industrial products. It is not only a renderingengine, but it also integrates audio/visual analysis and syn-thesis modules and demonstrates real-time head tracking,
1Mobile 3-D graphics API (M3G) is an optional package which can be usedwith existing J2ME MIDP 1.0 or MIDP 2.0 profiles. The specification was de-fined under JSR-184. The target platform of this optional API is J2ME/CLDC1.1.
visual text-to-speech (TTS), and real-time viseme detec-tion and rendering.
• The framework targets future mobile applications byadopting M3G standard and supports MPEG-4 facialanimation parameters (FAPs) [28].
• We designed a 3-D avatar prototype, which turns a staticcommercial avatar model into an animatable model. Itallows avatar customization on the fly by storing meshcomponents in M3G files and scene tree description inXML. This design improves the common practices ofM3G games, which usually pack everything into a singlefile and are hard to customize.
• A robust user head tracker was developed for real-timeavatar animation control. A low-cost head pose and motionestimation scheme was developed to generate low-dimen-sional animation parameters.
The remainder of this paper is structured as follows. We pro-pose the RTM-HAI system framework in Section II. The avatarstructure and morph target blending methods are summarizedin Section III. Some implementation techniques are discussedin Section IV. We propose the vision-based remote animationcontrol in Section V. The system performances are shown inSection VI. We finish with some conclusions and future work.
II. RTM-HAI FRAMEWORK OVERVIEW
There are two primary cases for using the RTM-HAI avatarframework: communications and user interactions. In the firstcase, the avatar usually represents a person to interact with otheravatars that represent other users in cyber space. In the secondcase, the avatar usually represents a device to interact with theuser of that device. A common functional requirement for bothcases is the ability to create an avatar at a rendering environ-ment, customize it, and finally animate it with head pose, facialexpressions, visemes, and body movements.
Fig. 1 shows the framework diagram of our RTM-HAIsystem. In human-to-human communication or human–ma-chine interaction activities, each user (each machine object) hasa respective avatar representative with customizing human-lifefeatures. Low-bit-rate avatar parameters of facial expres-sions and human head poses are estimated, recorded, andsent through a wireless network for virtual interactions. Theframework consists of two parts: the Java mobile 3-D stan-dard (M3G) rendering environment and the animation input.Inside the M3G environment, there are one or more avatarinstances; each specifies an avatar that can be independentlyanimated. The reason to allow multiple avatar instances isthat, for the communication usage, typically multiple avatarscoexist in a cyber space. The functional modules that provideanimation input for the avatar(s) include the real-time headtracker, real-time viseme detector, TTS engine and GUI forinteractive avatar control (puppet). In addition, some utilitiesare used to provide random eye movement and blink so as tomake the avatar more lifelike at idle states. The head trackerprovides estimated low-bit-rate user’s head pose parametersin real-time. The viseme detection module detects visemes inreal-time from live speech inputs of users. The TTS enginesynthesizes speech with given text and outputs viseme symbolsand corresponding timing. Each avatar instance is associated
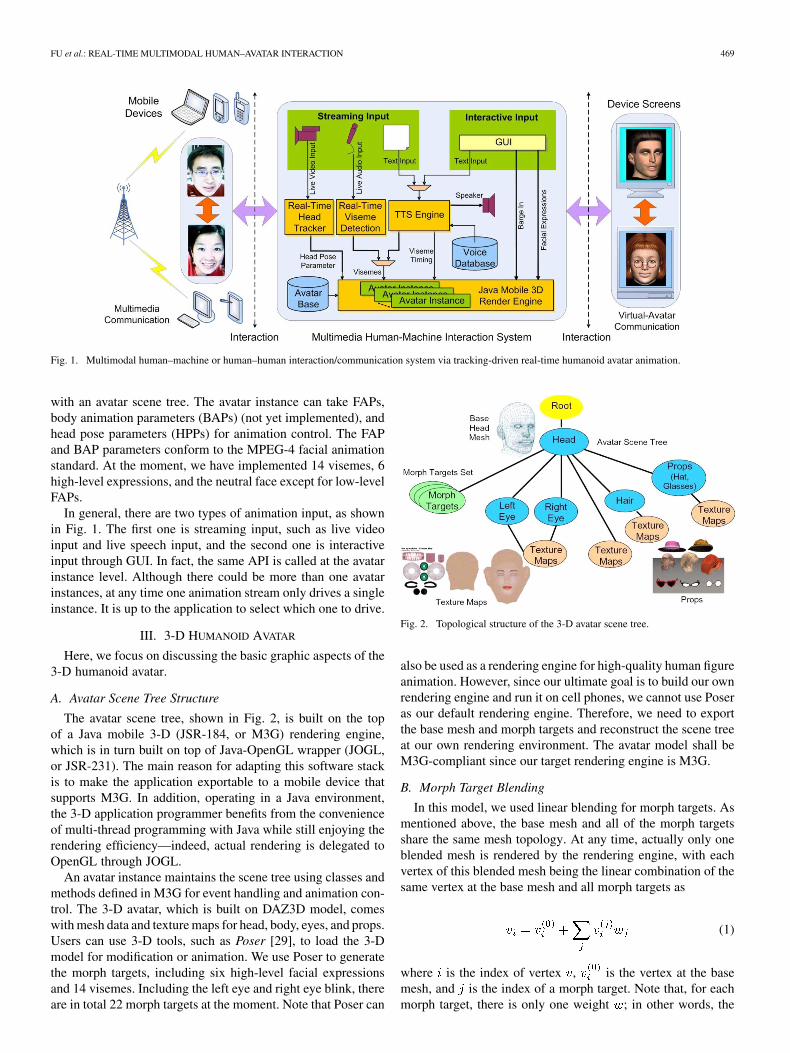
FU et al.: REAL-TIME MULTIMODAL HUMAN–AVATAR INTERACTION 469
Fig. 1. Multimodal human–machine or human–human interaction/communication system via tracking-driven real-time humanoid avatar animation.
with an avatar scene tree. The avatar instance can take FAPs,body animation parameters (BAPs) (not yet implemented), andhead pose parameters (HPPs) for animation control. The FAPand BAP parameters conform to the MPEG-4 facial animationstandard. At the moment, we have implemented 14 visemes, 6high-level expressions, and the neutral face except for low-levelFAPs.
In general, there are two types of animation input, as shownin Fig. 1. The first one is streaming input, such as live videoinput and live speech input, and the second one is interactiveinput through GUI. In fact, the same API is called at the avatarinstance level. Although there could be more than one avatarinstances, at any time one animation stream only drives a singleinstance. It is up to the application to select which one to drive.
III. 3-D HUMANOID AVATAR
Here, we focus on discussing the basic graphic aspects of the3-D humanoid avatar.
A. Avatar Scene Tree Structure
The avatar scene tree, shown in Fig. 2, is built on the topof a Java mobile 3-D (JSR-184, or M3G) rendering engine,which is in turn built on top of Java-OpenGL wrapper (JOGL,or JSR-231). The main reason for adapting this software stackis to make the application exportable to a mobile device thatsupports M3G. In addition, operating in a Java environment,the 3-D application programmer benefits from the convenienceof multi-thread programming with Java while still enjoying therendering efficiency—indeed, actual rendering is delegated toOpenGL through JOGL.
An avatar instance maintains the scene tree using classes andmethods defined in M3G for event handling and animation con-trol. The 3-D avatar, which is built on DAZ3D model, comeswith mesh data and texture maps for head, body, eyes, and props.Users can use 3-D tools, such as Poser [29], to load the 3-Dmodel for modification or animation. We use Poser to generatethe morph targets, including six high-level facial expressionsand 14 visemes. Including the left eye and right eye blink, thereare in total 22 morph targets at the moment. Note that Poser can
Fig. 2. Topological structure of the 3-D avatar scene tree.
also be used as a rendering engine for high-quality human figureanimation. However, since our ultimate goal is to build our ownrendering engine and run it on cell phones, we cannot use Poseras our default rendering engine. Therefore, we need to exportthe base mesh and morph targets and reconstruct the scene treeat our own rendering environment. The avatar model shall beM3G-compliant since our target rendering engine is M3G.
B. Morph Target Blending
In this model, we used linear blending for morph targets. Asmentioned above, the base mesh and all of the morph targetsshare the same mesh topology. At any time, actually only oneblended mesh is rendered by the rendering engine, with eachvertex of this blended mesh being the linear combination of thesame vertex at the base mesh and all morph targets as
(1)
where is the index of vertex , is the vertex at the basemesh, and is the index of a morph target. Note that, for eachmorph target, there is only one weight ; in other words, the

470 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 18, NO. 4, APRIL 2008
Fig. 3. Examples of avatar facial expressions.
weight does not change from vertex to vertex. Given that amoderate complex model often consists of over 5000 polygons,which means there are also several thousands of vertices, morphtargets blending could be a serious computational burden. Typ-ically, for a facial expression or viseme, the control commandcome as a vector of weights formorph targets, where is the time index. To animate, the weightvector will change over time, hence the blending has to be donefor every frame. For our current implementation, we do morphtarget blending inside Java. Unlike the actual 3-D rendering, nohardware acceleration is used in our system. However, the ren-dering performance is still quite acceptable—over 25 fps, evenon a laptop.
C. Expressiveness
For avatar expression synthesis, we used dedicated morphtargets for a small set of (six in total) facial expressions withone morph target for one expression. Using a dedicated morphtarget, the expression can be generated without worrying howto blend with other morph targets. If the user wants a differentstrength of smile, he/she only needs to blend the “smile” morphtarget with the based morph. Fig. 3 illustrates some examples ofour avatar facial expressions. To further improve the expressivepower of our avatar, we are currently making a more compli-cated avatar for the emotive animation, which consists of over 50morphs. In order to extract the particular expression for avatarexpression analysis, we use predetermined (offline fine-tuned)weights through the manually controlled GUI to synthesize de-sired expressions.
IV. CREATING THE AVATAR MODEL
Here, we present the visual and audio aspect of the humanoidavatar modeling techniques for RTM-HAI system.
A. The Avatar API
The avatar API is defined to allow adequately flexible avatarcustomization and animation control. Application programmerscan use this API to gain advanced animation effects. The func-tions at the avatar API fall into several categories as follows.
• Avatar model construction and customization. The avatarscene tree is described using a configuration file, which iswritten in XML. It is easy and straightforward to edit theconfiguration file in order to control the appearance, size,and capacity of the avatar. In addition, a set of methods is
Fig. 4. Processing flow for generating a morph target in the M3G file format.
designed to customize an avatar on the fly while it is beingused, including adding, removing, or replacing individualcomponents (mesh and corresponding texture map) at thescene tree.
• Avatar size and pose control. This is the basic interfacethat controls the size (zoom in/out factor) and head pose(rolling, tilting, yawing, horizontal, and vertical) of the 3-Dhead model.
• Facial expression and viseme control. A subset of mod-eling methods is adopted for FAP animation. Currently,only six high-level facial expressions and 14 visemes aresupported. Each FAP is represented by a morph target, anddifferent facial expressions and lip shapes are synthesizedby the linear blending of these morph targets.
• TTS control interfaces. Basically, these methods are used tofeed text to the TTS engine and configure the TTS system,such as male or female voice selection.
• Streaming animation control. These are high-level appli-cation interfaces. By connecting a stream to the avatarsystem, each command at the stream will be (in theory)instantly rendered.
In addition, there are a number of event types generated by therendering engine that are used to communicate with external an-imation control modules, such as the endOfSession signal indi-cating that the rendering engine finishes the audio-visual anima-tion for a dialog text. Such setter-getter types of API functionsare not listed here.
B. Morph Target Generation From a Static Model
We build our facial-morph-driven 3-D avatar with the com-mercially available static 3-D model—DAZ3D2 [29]. The workflow for generating mesh data and texture map for a morph targetis shown in Fig. 4. As can be seen, the Poser mesh is first ex-ported into Wavefront OBJ file format. However, there are anumber of factors preventing one from directly using this OBJfile to generate the triangle strips that is required by M3G. First,the mesh data may not be based on triangles but quadrilaterals.
2DAZ3D is leading developer of professional quality 3-D software andmodels, specializing in providing high-quality 3-D content for Poser, the 3-Dcharacter animation and figure design tool.

FU et al.: REAL-TIME MULTIMODAL HUMAN–AVATAR INTERACTION 471
Fig. 5. Creating the avatar model. (a) From the rendering environment perspective, the complete scene tree consists of background, avatar instances, and otherviewing-related nodes from M3G. (b) Overwriting buffer for automatic adaptation of rate difference between rendering and animation control. (c) Illustration ofdifferent scenarios using the automatic rate adjustment.
Second, the mesh names and coordinate origin may not be ap-propriate for head animation (for easy head pose control, theorigin shall be inside the skull). For these reasons, the OBJ fileis first loaded into another 3-D tool, TrueSpace, for adjustmentand then exported again in OBJ format. Finally, an internally de-veloped Java utility is used to convert the triangle-based meshdata into triangle strips, and M3G exporter is used to store it intostandard M3G file format.
To support online customization, in our implementation, wemake the compliance at the component level rather than thewhole scene tree—each morph target is an M3G-compliant fileand can be loaded independently. Internally, the loaded morphtarget is added to an empty scene tree according to a givenscene tree configuration. The advantage of this strategy is thatthe individual component of the scene tree can be convenientlyadded, removed, or replaced. Hence, initially there is only anempty scene tree for an avatar instance. All components (basemeshes, morph targets, props, and texture maps) can be indi-vidually changed as long as some basic constraints are satisfied.For example, a new morph target has to have the same meshtopology as the base mesh and the other morph targets; other-wise, the model cannot be animated properly. A Java utility isbuilt to convert a single OBJ file that encodes a morph target intoa corresponding M3G MorphingMesh object, and then exportthe M3G object into a standard compliant M3G file. In addi-tion, a batch processing utility is created to convert a number ofmorph targets at once. These manipulations provide flexibilityfor customizing the avatar appearance.
C. Rendering Environment and Event Handling
The avatar instance communicates with the M3G graphics en-vironment through a single class—RenderEnvM3G. The func-tions of this class are summarized below.
• It provides a complete 3-D environment including sceneroot, capability of setting cameras, lights, viewer, andbackground.
• It provides a canvas object on which the rendering results(rasterized pixels) are drawn.
• It handles classical OpenGL rendering events (callbacks)through the GLEventListener interface of JOGL: initial,display, reshape, and display changes.
• It also senses GUI events including key and mouse eventsand delegates the events to respective event handlers. Thisis the only class that the avatar application communicateswith a low-level graphics environment. In addition, there
are a few user-defined events, e.g., endOfSession andbargeIn. These are handled at the application level andare completely separated from the GUI events and OpenGLcallbacks.
D. Meeting Time Requirement for Real-Time Stream DrivenRendering
The rendering engine typically traverses the scene treestarting from the scene root as shown in Fig. 5(a), consolidatesany changes in the vertex (caused by morph targets blending)or transformations (caused by pose change), and then callslow-level rendering functions to generate the updated renderingresults. We call such a cycle a frame of rendering.
An implementation question faced by any real-time 3-D ap-plications is that the frame rate is varying and a rendering com-mand may come at any moment, completely independent of therendering frame rate. Typically, the rendering loop is associatedwith one thread, and the animation command comes from otherthread(s). One way to cope with the rate difference is to buffer allincoming rendering commands and to determine by time stampwhich one to render. In reality, this does not work when the in-coming rendering command happens much faster than the actualrendering frame rate. If every command is buffered, eventuallyit will lose audio-visual (A/V) synchronization. In our imple-mentation, we use a simple method to automatically adjust therate difference. The concept is simple: if a new command did notarrive yet when the rendering engine finished a frame, reuse theold command; if, however, during the rendering of the currentframe more than one commands have arrived, keep the latestone and discard all previous ones, even though they never getthe chance to be rendered. To implement this idea, a thread-safe“buffer” object is defined to store the latest animation commandfor each stream, as illustrated in Fig. 5(b). Every time the ren-dering engine finishes a frame, it copies the animation commandfrom the corresponding buffer object for each stream to renderthe next frame. Fig. 5(c) illustrates all scenarios for this au-tomatic rate adjustment. The vertical lines indicate the timingfor the rendering engine to copy the next animation commandfor each stream. The animation command may be updated zero,one, or more times during last frame, resulting in reuse, update,and discard of animation commands.
E. TTS and Viseme Synchronization
We use the Motorola TTS system in developing the relatedfunctional part of our system. There are basically 14 visemes

472 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 18, NO. 4, APRIL 2008
TABLE IDESCRIPTION OF 14 VISEMES AND CORRESPONDING MULTIPLE PHONEMES FOR HUMANOID AVATAR TTS SYSTEM
Fig. 6. Visemes of the custom-built male and female avatars. (a) Female avatarvisemes. (b) Male avatar visemes.
and corresponding multiple standard phonemes defined forour humanoid avatar TTS system. The description of thiscorrespondence is summarized in Table I. Fig. 6 also showsthe 14 visemes of the male and female avatars, respectively.Basically, given a paragraph of text, the TTS engine first parsesit into sentences (any text strings separated by the delimiters“,”, “:”, “.”, “;”, etc.). For each sentence, the TTS comes backwith the following information: 1) synthesized speech data (16K sample rate, 16 bits sample); 2) phonemes for each word;and 3) phoneme duration (timing). These data are sufficientfor phoneme-level lip synchronization. A simple mapping isdone to map each phoneme into a viseme (the mapping tablecan be customized). To summarize, the TTS engine outputs thefollowing information:
• audioClip—the synthesized speech data;• visemes—the visemes corresponding to the synthesized
speech;• visemeTiming—the duration, in unit of milliseconds, for
each viseme symbol.The TTS engine is written in C. Because the rest of the systemis written in Java, we designed a Java class with native methodsto build the TTS engine through the Java native interface (JNI).
Psychological study has long revealed that the lip shape isnot only determined by the current phoneme, but also the pre-vious one and the one to come. In few cases, the lip is evenaffected by the far away future phoneme. One way to cope withthis observation is to introduce viseme blending. Let visemesgradually phase in and out according to the rules of co-articu-lation. Because each viseme corresponds to a morph target, thephase in and out of a viseme are controlled by their weightsover time (frame; each one corresponds to 20 ms). Although it ishard to predict the future viseme for real-time detected visemes,the co-articulation is easier to handle with TTS output since allviseme data are available before rendering.
Fig. 7. Some cases for the simple viseme blending using a sliding windowcentered at the current audio position.
The current implementation of synchronization is at the sen-tence level. As mentioned above, a sentence does not necessarilyend with a period. We implement a crude level of co-articula-tion shown in Fig. 7. As a sliding triangular window slicing overtime, the area of intersection with a viseme window determinesthe corresponding weight. Since the TTS engine operates at thesentence level, we know the duration for each viseme for thesentence. Hence, the current viseme can be inferred based onthe audio sample position. The idea is to give the current visemethe largest weight and give the past and future viseme smallerweight such that more smooth viseme rendering is perceived.
V. VISION-BASED REMOTE ANIMATION CONTROL
For the user-interface implementation, we need to simultane-ously capture the users’ nonverbal message exchanging throughtheir behaviors, such as facial expressions, poses, and body lan-guages, during the real-time interaction or virtual communica-tion. This task is fulfilled by analyzing the video input from thecamera in front of the users.
A. Real-Time Head Tracker
The RTM-HAI system is integrated with a robust headtracker for real-time avatar animation control. The tracker isworking through an interactive loop shown in Fig. 8 with au-tomatic switching between detection and tracking at run-time.Many existing single-model frontal/profile face detection andskin-color-based head tracking systems can work well in limiteduse conditions [5], [14]. Our fundamental detection-trackingalgorithm is a hybrid approach inheriting the advantages of twopopular vision methods proposed by Viola and Jones [12] andBradski [13], which can handle fairly difficult cases, such asusers jumping, coming in and out, large degree rotations, users’faces partially out of the camera viewport, turning around, andmulti-user occlusion. In each tracking cycle, for a capturedvideo frame, the system first processes automatic real-time face

FU et al.: REAL-TIME MULTIMODAL HUMAN–AVATAR INTERACTION 473
Fig. 8. Framework of robust real-time head tracker and head pose estimation.
detection. If there are any detected faces, the system will choosethe most possible user according to predefined rules or previoustracking positions. The first detection window determined sincethe system is turned on is then selected as the initialization ofthe real-time tracking module. A pose or motion estimationmodule is further activated accompanied with head tracking.Part of the system is implemented on an OpenCV [16] platformto bring a reliable and fast head tracking performance.
B. Head Pose and Motion Estimation
Following our previous work in [3], the six typical head-poseparameters of the system, , are definedto record the estimation of rolling, tilting, yawing, scaling, andhorizontal and vertical user head motion. In order to save thesystem resource for real-time applications, a 3-D head poseand motion estimation scheme with low computational costis designed allowing the efficient merge of face-related 2-Dtechniques.
The RTM-HAI system uses the same algorithm asCAMSHIFT [13] to estimate head rolling parameter .Suppose denotes the intensity of pixel at thesearching area in each frame, where ,
, and are the window bound-aries in searching, which can be either the detection resultor the on-tracking result. The five distribution area moments
are calculated in the sameway as that in [3]. Then, the head rolling angle indicatingthe parameter is estimated by (2). The OpenCV functioncvCamShift is created in terms of this algorithm as follows:
(2)
We use a motion-based algorithm to approximately estimatethe coarse tilting and yawing angle parameters and . First,calculate and threshold differences between frames to get the sil-houette mask. Second, update the motion history image (MHI)[32]. Third, calculate the derivatives of MHI and calculate gra-dient orientation. Fourth, in the face tracking window, build theorientation histogram and find the basic orientation. Fifth, cal-culate the shift relative to the basic orientation and estimatethe general motion direction. Finally, cumulate motion intensity(time shifts) in the general motion direction of several adjacent
frames, relative to neutral position ,to determine the tilting and yawing angles.
The scaling parameter is straightforwardly determined bythe size of the tracking window. Since the tracking window canyield severe jitters at some detection-tracking mode switchingpoints, we smooth the results in the spatio-temporal domain byrestricting the tracking bounding boxes to be all squares in theRTM-HAI system. In the spatial domain, for an estimated objectsize (length and width) by raw tracking in which the estimatedtracking window can be rectangular, we rescale the window sizeto be . The square window is easily deter-mined as the centroid coordinates of the object. In the temporaldomain, the smoothing is performed by averaging three adja-cent frames including the previous two frames and the currentframe.
The horizontal and vertical motion parameters and arecalculated differently in the two modes. In the detection mode,the reference motion point is
, where denotes the detection window coordi-nates in the frame space. In the tracking mode, the referencemotion point is the object centroid determined by three dis-tribution area moments , , and via the equation
.
C. Remote Animation Control Via Socket
It is convenient to allow low-bit-rate remote animation con-trol. In our implementation, we used a socket compatible withthe Berkeley sockets API to transmit animation parameters,e.g., HPP. Using socket not only makes the avatar frameworkmachine-independent, but also language-independent. Anylanguages can be used to send out the animation data througha socket. At the receiving end, a Java class is developed tolisten to the socket connections and spawn a new thread forevery new connection. Depending on the type of animationcontrol parameters, different avatar APIs are called to animatethe avatar. Because of this multithread implementation, headpose, facial expression, and visemes can actually come fromdifferent machines and still animate cohesively.
VI. SYSTEM PERFORMANCE
The user interface (UI) of the RTM-HAI system is imple-mented in C++ on a recent standard PC, using a typical webcamera mounted on top of the monitor as video input and Vis-Genie [15] as video-based information visualization platform.The tracker processes 11–13 fps on a desktop with 2.80-GHzPentium 4 CPU and 1.0 G RAM. The pure detection part pro-cesses 13–14 fps. It works on a Windows XP operating systemwith 320 240 video frame size in the RGB channels. The av-erage CPU usage is 35%–43%. The avatar rendering and ani-mation module works in real-time with 23–27 fps.
To demonstrate the performance of the RTM-HAI tracker,we test the robustness of our head tracker under many diffi-cult circumstances, such as users jumping, extreme movements,large degree rotations, users turning around, hand/object occlu-sions, users’ faces partially out of the camera viewport, andmulti-user occlusions. Fig. 9 shows some key frames of theavailable tracking demo. A blue square is drawn to indicatethe tracking window. Our RTM-HAI tracker can almost always

474 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 18, NO. 4, APRIL 2008
Fig. 9. Robust real-time head tracking with RTM-HAI tracker. Each row shows a case of users jumping, extreme movements, users’ faces partially out of thecamera viewport, multi-user occlusion, hand/object occlusion, and turning around, respectively.
keep tracking the main user’s head, except when the user turnsto the back or other users totally occlude the main user’s head. Inpractice, this tracker can work at user interfaces via the camerato capture users’ activities. This robust processing provides suf-ficient reliability and efficient tracking for real-time user–avatarcommunication.
To test the RAC of RTM-HAI, we run the two demos (userhead tracking and avatar animation) separately on an IBM T42laptop (1.60-GHz Pentium M CPU and 512 M RAM) and thedesktop mentioned above. The user head pose parameters areestimated from the UI and sent to the avatar demo from a wire-less network. The avatar is controlled in real-time for rolling,tilting, yawing, scaling, and horizontal and vertical head mo-tion. Fig. 10 shows some sample frames of the available demo.Although there is sometimes a small delay during the commu-nication, we can see that the avatar head pose animation is rea-sonably associated with the user’s head motion. This demo hasbeen shown to 20 subjects for a subjective evaluation. A largepart of those users were convinced by the presented avatar andindicated that this human–avatar communication is interestingand the small mismatching of the head pose animation due tothe communication delay is acceptable.
Fig. 11 illustrates some examples of our 3-D humanoid avataranimation and human-to-human multimodal communicationthrough tracking-driven real-time animation control. The two
rows show eight sample frames of a real-world two-user com-munication experiment. The female user agent is representedby an avatar named “Lily” in the virtual space, while the maleuser agent is represented by “Henry.” During the multimediacommunication through the wireless network connecting twolaptops, the real-time tracking modules perceive two users’activities (head poses and expressions) and translate estimatedparameters into corresponding avatar animations. It appearsthat our head tracker works effectively for large variations ofuser head pose in a cluttered background. During the commu-nication, users can input text for chatting. The representativeavatar can animate the user’s head pose along with the TTSinteraction and expression rendering. The entire system has ef-ficient and fast interactive performance for real-world networkapplications.
Although the current version of our system works fine most ofthe time, it may somehow not work well in some sporadic situa-tions. For example, when the background color is very similar toskin color, the tracker may lose tracking for side face views withlarge head motions. Moreover, if head rotation is too fast, thehead pose estimator may fail to capture the head position sincethe motion accumulation cannot be perfectly fulfilled. However,we believe these common difficulties in head tracking can betackled by more advanced real-time algorithms using diversi-fied visual features.

FU et al.: REAL-TIME MULTIMODAL HUMAN–AVATAR INTERACTION 475
Fig. 10. Real-time RTM-HAI avatar animation control remotely through head tracking. The avatar, representing the main user, is controlled in real-time for rolling,tilting, yawing, scaling, and horizontal and vertical head motion.
Fig. 11. 3-D humanoid avatar animation and human-to-human multimodal communication through tracking-driven real-time animation control. A real-world caseof two-user communication through a wireless network is shown in the two rows. The two users are respectively represented by the customizing avatars “Lily” and“Henry.”
VII. CONCLUSION AND FUTURE WORK
We have proposed a novel avatar-based human–machine orhuman–human framework with remote animation control. Thecurrent version of our prototype system provides reliable real-time user–avatar communication with remotely sent user HPPsthat are estimated through a robust 2-D face detection/trackingstrategy. It has been demonstrated to be an effective design andintegrated into the first generation of a commercial kiosk pro-totype. The future development of RTM-HAI will focus on de-signing a highly compact 3-D engine, avatar instance, and cor-responding content that are tailored for the current and nearfuture mobile device. The development of emotive TTS is con-sidered to further smooth the interactive quality. We are also in-terested in identifying an efficient way to export facial and body(especially the shoulder part) animations from motion capture(MoCap) data or 3-D authoring tools (e.g., Poser and 3-D studio
max) into avatar models and rendering a command that can beloaded and executed by the avatar engine for the embodied con-versational agent (ECA) type of applications.
ACKNOWLEDGMENT
The authors would like to thank Y. Xu, Department ofPsychology, University of Illinois at Urbana-Champaign, forproofreading the paper and editing the demos.
REFERENCES
[1] R. Li, “A technical report on motorola avatar framework,” ApplicationsResearch Center, Motorola Labs, Schaumburg, IL, TR-2006, 2006.
[2] Y. Fu and N. Zheng, “M-face: An appearance-based photorealisticmodel for multiple facial attributes rendering,” IEEE Trans. CircuitsSyst. Video Technol., vol. 16, no. 7, pp. 830–842, Jul. 2006.

476 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 18, NO. 4, APRIL 2008
[3] Y. Fu and T. S. Huang, “hMouse: Head tracking driven virtual com-puter mouse,” in Proc. IEEE Workshop WACV, Feb. 2007, p. 30.
[4] Y. Fu, R. Li, T. S. Huang, and M. Danielsen, “Real-time humanoidavatar for multimodal human-machine interaction,” in Proc. IEEEConf. ICME, 2007, pp. 991–994.
[5] T. Yang, S. Li, Q. Pan, J. Li, and C. H. Zhao, “Reliable and fast trackingof faces under varying pose,” in Proc. IEEE Conf. FGR, 2006, pp.421–428.
[6] H. Tao and T. S. Huang, “Explanation-based facial motion trackingusing a piecewise Bézier volume deformation model,” in Proc. IEEEConf. CVPR, 1999, vol. 1, pp. 611–617.
[7] P. Hong, Z. Wen, and T. S. Huang, “Real-time speech-driven face an-imation with expressions using neural networks,” IEEE Trans. NeuralNetw., vol. 13, no. 4, pp. 916–927, Jul. 2002.
[8] Z. Wen and T. S. Huang, 3D Face Processing: Modeling, Analysis andSynthesis, 1st ed. Berlin, Germany: Springer-Verlag, 2004.
[9] M. Mancini, R. Bresin, and C. Pelachaud, “A virtual head driven bymusic expressivity,” IEEE Trans. Audio, Speech, Lang. Process., vol.15, no. 6, pp. 1833–1841, Aug. 2007.
[10] M. La Cascia, S. Sclaroff, and V. Athitsos, “Fast, reliable head trackingunder varying illumination: An approach based on registration of tex-ture-mapped 3-D models,” IEEE Trans. Pattern Anal. Mach. Intell., vol.22, no. 4, pp. 322–336, Apr. 2000.
[11] H. Nanda and K. Fujimura, “A robust elliptical head tracker,” in Proc.IEEE Conf. FGR, 2004, pp. 469–474.
[12] P. A. Viola and M. J. Jones, “Rapid object detection using a boostedcascade of simple features,” in Proc. IEEE Conf. CVPR, 2001, pp.511–518.
[13] G. R. Bradski, “Real time face and object tracking as a component of aperceptual user interface,” in Proc. IEEE Workshop WACV, 1998, pp.214–219.
[14] M. T. Wenzel and W. H. Schiffmann, “Head pose estimation of par-tially occluded faces,” in Proc. 2nd Can. Conf. Comput. Robot Vision,2005, pp. 353–360.
[15] Y. Wang, VisGenie [Online]. Available: http://www.ee.columbia.edu/~ywang/Research/VisGenie/
[16] Open Source Computer Vision Library (OpenCV). Intel Corpora-tion. [Online]. Available: http://www.intel.com/technology/com-puting/opencv/index.htm
[17] Java Mobile 3D [Online]. Available: http://www.jcp.org/en/jsr/de-tail?id=184
[18] X. L. Yang, D. C. Petriu, T. E. Whalen, and E. M. Petriu, “Hierarchicalanimation control of avatars in 3-D virtual environments,” IEEE Trans.Instrum. Meas., vol. 54, no. 3, pp. 1333–1341, Jun. 2005.
[19] V. Blanz and T. Vetter, “A morphable model for the synthesis of 3-Dfaces,” in Proc. SIGGRAPH, 1999, pp. 187–194.
[20] F. I. Parke, “Computer generated animation of faces,” in Proc. ACMNat. Conf., 1972, pp. 451–457.
[21] K. Perlin and A. Goldberg, “Improv: A system for scripting interactiveactors in virtual worlds,” in Proc. SIGGRAPH, 1996, pp. 205–216.
[22] C. S. Pinhanez, K. Mase, and A. F. Bobick, “Interval scripts: A designparadigm for story-based interactive systems,” in Proc. ACM SIGCHI,1997, pp. 287–294.
[23] N. Badler, C. Phillips, and B. Webber, “Simulating humans,” in Com-puter Graphics Animation and Control. New York: Oxford Univ.Press, 1993.
[24] M. Betke, J. Gips, and P. Fleming, “The camera mouse: Visual trackingof body features to provide computer access for people with severedisabilities,” IEEE Trans. Neural Syst. Rehab. Eng., vol. 10, no. 1, pp.1–10, Mar. 2002.
[25] S. Rusdorf, G. Brunnett, M. Lorenz, and T. Winkler, “Real-time inter-action with a humanoid avatar in an immersive table tennis simulation,”IEEE Trans. Visualiz. Comput. Graphics, vol. 13, no. 1, pp. 15–25, Jan.2007.
[26] H. Ishii, C. Wisneski, J. Orbanes, B. Chun, and J. Paradiso, “PingPong-Plus: Design of an athletic-tangible interface for computer-supportedcooperative play,” in Proc. ACM SIGCHI, 1999, pp. 394–401.
[27] V. Wulf, E. F. Moritz, C. Henneke, K. Al-Zubaidi, and G. Stevens,“Computer supported collaborative sports: Creating social spaces filledwith sports activities,” in Proc. Int. Conf. Educational Computing,2004, pp. 80–89.
[28] I. Pandzic and R. Forchheimer, Eds., MPEG-4 Facial Animation.Chichester, U.K.: Wiley, 2002.
[29] DAZ3D [Online]. Available: http://www.daz3d.com/[30] K.-H. Choi and J.-N. Hwang, “Constrained optimization for audio-to-
visual conversion,” IEEE Trans. Signal Process., vol. 52, no. 6, pp.1783–1790, Jun. 2004.
[31] J. Ma, R. Cole, B. Pellom, W. Ward, and B. Wise, “Accurate visiblespeech synthesis based on concatenating variable length motion cap-ture data,” IEEE Trans. Visualiz. Comput. Graphics, vol. 12, no. 2, pp.266–276, Feb. 2006.
[32] J. W. Davis and A. F. Bobick, “The representation and recognitionof human movement using temporal templates,” in Proc. IEEE Conf.CVPR, 1997, pp. 928–934.
Yun Fu (S’07) received the B.E. degree in infor-mation and communication engineering and theM.S. degree in pattern recognition and intelligencesystems from Xi’an Jiaotong University (XJTU),Xi’an, China, in 2004, and the Applied Science M.S.degree in statistics from the Department of Statistics,University of Illinois at Urbana-Champaign, Urbana,in 2007, where he is currently working towardthe Ph.D. degree at the Electrical and ComputerEngineering Department.
From 2001 to 2004, Mr. Fu was a research assis-tant at the Institute of Artificial Intelligence and Robotics (AI&R), XJTU. From2004 to 2007, he was a research assistant at the Beckman Institute for AdvancedScience and Technology at UIUC. He was a research intern with MitsubishiElectric Research Laboratories (MERL), Cambridge, MA, in summer 2005 andwith Multimedia Research Laboratory of Motorola Labs, Schaumburg, IL, insummer 2006. His research interests include machine learning, human–com-puter interaction, and image processing.
Mr. Fu is a student member of Institute of Mathematical Statistics (IMS), andBeckman Graduate Fellow. He was the recipient of the 2002 Rockwell Automa-tion Master of Science Award, two Edison Cups of the 2002 GE Fund EdisonCup Technology Innovation Competition, the 2003 HP Silver Medal and Sci-ence Scholarship for Excellent Chinese Student, the 2007 Chinese GovernmentAward for Outstanding Self-financed Students Abroad, the 2007 DoCoMo USALabs Innovative Paper Award (IEEE ICIP’07 Best Paper Award), the 2007-2008Beckman Graduate Fellowship, and the 2008 M. E. Van Valkenburg GraduateResearch Award.
Renxiang Li (M’96) received the B.S. and M.S.degrees from the University of Science and Tech-nology of China, Hefei, and the Ph.D. degree fromHong Kong University of Science and Technology,all in electrical and electronic engineering.
He joined Motorola in 1995, where he is currentlya Principle Staff Research Engineer with MotorolaLabs, Schaumburg, IL. His recent interests includemultimedia systems, human–computer interaction,and avatar applications for communications and userinterfaces.
Thomas S. Huang (S’61–M’63–SM’76–F’79–LF’01) received the B.S. degree from NationalTaiwan University, Taipei, Taiwan, China, and theM.S. and Sc.D. degrees from the MassachusettsInstitute of Technology (MIT), Cambridge, all inelectrical engineering.
He was a member of the faculty of the Departmentof Electrical Engineering at MIT from 1963 to 1973and with the faculty of the School of Electrical En-gineering and Director of its Laboratory for Informa-tion and Signal Processing at Purdue University, West
Lafayette, IN, from 1973 to 1980. In 1980, he joined the University of Illinoisat Urbana-Champaign, Urbana, where he is now the William L. Everitt Distin-guished Professor of Electrical and Computer Engineering, Research Professorat the Coordinated Science Laboratory, Head of the Image Formation and Pro-cessing Group at the Beckman Institute for Advanced Science and Technology,and Co-chair of the Institute’s major research theme: human–computer intelli-gent interaction. His professional interests lie in the broad area of information

FU et al.: REAL-TIME MULTIMODAL HUMAN–AVATAR INTERACTION 477
technology, especially the transmission and processing of multidimensional sig-nals. He has published 20 books and over 500 papers in network theory, digitalfiltering, image processing, and computer vision.
Dr. Huang is a member of the National Academy of Engineering, a ForeignMember of the Chinese Academies of Engineering and Science, and a Fellowof the International Association of Pattern Recognition and the Optical Societyof America He has received a Guggenheim Fellowship, an A. von HumboldtFoundation Senior U.S. Scientist Award, and a Fellowship from the Japan As-sociation for the Promotion of Science. He was the recipient of the IEEE SignalProcessing Society’s Technical Achievement Award in 1987 and the SocietyAward in 1991. He was awarded the IEEE Third Millennium Medal in 2000.Also in 2000, he received the Honda Lifetime Achievement Award for “contri-butions to motion analysis.” In 2001, he received the IEEE Jack S. Kilby Medal.In 2002, he received the King-Sun Fu Prize, the International Association ofPattern Recognition, and the Pan Wen-Yuan Outstanding Research Award. Heis a Founding Editor of the International Journal of Computer Vision, Graphics,
and Image Processing and Editor of the Springer Series in Information Sciences,published by Springer.
Mike Danielsen received the B.S. degree in elec-trical engineering from Michigan TechnologicalUniversity, Houghton, in 1979 and the M.S. degree incomputer sciences from online University NationalTechnology University in 1995.
He has been with Motorola Labs and CorporateResearch, Schaumburg, IL, since 1984, where he isa Distinguished Staff Engineer. He has been creatingnew technological solutions in multimedia and otherfields.





