

Learning of Pseudo-Metrics. Slide 1
Online and Batch Learning of Pseudo-Metrics
Shai Shalev-Shwartz
Hebrew University, Jerusalem
Joint work with
Yoram Singer, Google Inc.
Andrew Y. Ng, Stanford University

Learning of Pseudo-Metrics. Slide 2
Motivating Example

Learning of Pseudo-Metrics. Slide 3
Our Technique• Map instances into a space in which
distances correspond to labels

Learning of Pseudo-Metrics. Slide 4
Outline
• Distance learning setting
• Large margin for distances
• An online learning algorithm
• Online loss analysis
• A dual version
• Experiments:• Online - document filtering• Batch - handwritten digit recognition

Learning of Pseudo-Metrics. Slide 5
Problem Setting
• Training examples:• two instances• similarity label
• Hypotheses class: Pseudo-metrics
matrix
symmetric positive semi-definite matrix

Learning of Pseudo-Metrics. Slide 6
Large Margin for Pseudo-Metrics
• Sample S is -separated w.r.t. a metric

Learning of Pseudo-Metrics. Slide 7
Batch Formulations.t.
s.t.

Learning of Pseudo-Metrics. Slide 8
Pseudo-metric Online Learning Algorithm (POLA)
For
• Get two instances
• Calculate distance
• Predict
• Get true label and suffer hinge-loss
• Update matrix and threshold
If: we want that
If: we want that

Learning of Pseudo-Metrics. Slide 10
Core Update: Two Projections
• Start with• An example
defines a half-space
• is the projection of onto this half-space
• is the projection of onto the PSD cone
PS
D c
one
All zero loss matrices

Learning of Pseudo-Metrics. Slide 11
Online Learning
• Goal – minimize cumulative loss
• Why Online?• Online processing tasks (e.g. Text Filtering)• Simple to implement• Memory and run-time efficient• Worst-case bounds on the performance• Online to batch conversions

Learning of Pseudo-Metrics. Slide 12
Online Loss Bound
• sequence of examples s.t.
• any fixed matrix and threshold
• Then,
Loss bound does not depend on dimension
Loss suffered by “Complexity” of

Learning of Pseudo-Metrics. Slide 13
Incorporating Kernels
• Matrix A can be written as ,
where
• Therefore:

Learning of Pseudo-Metrics. Slide 14
Online Experiments• Task: Document filtering according to topics
• Dataset: Reuters-21578 • 10,000 documents
• Documents labeled as Relevant and Irrelevant
• A few relevant documents (1% - 10% of entire set)
• Algorithms: • POLA
• 1 Nearest Neighbor (1-NN)
• Perceptron Algorithm
• Perceptron Algorithm with Uneven Margins (PAUM) (Li, Zaragoza, Herbrich, Shawe-Taylor, Kandola)

Learning of Pseudo-Metrics. Slide 15
POLA for Document Filtering
• Get a document
• Calculate distance to relevant documents observed so far using current matrix
• Predict: document is relevant iff the distance to the closest relevant document is smaller than the current threshold
• Get true label
• Update matrix and threshold

Learning of Pseudo-Metrics. Slide 16
Document Filtering Results• Each blue point corresponds to one topic
• Y-axis designates the error of POLA
• Points beneath the black diagonal line mean that POLA wins
1-NN error
PO
LA
err
or
Perceptron error
PO
LA
err
or
PAUM error
PO
LA
err
or

Learning of Pseudo-Metrics. Slide 17
Batch Experiments• Task: Handwritten digits recognition
• Dataset: MNIST dataset• 45 binary classification problems (all pairs)
• 10,000 training examples
• 10,000 test examples
• Algorithms: Used k-NN with various metrics:• Pseudo-metric learned by POLA
• Euclidean distance
• Metric induced by Fisher Discriminant Analysis (FDA)
• Metric learned by Relevant Component Analysis (RCA)
(Bar-Hillel, Hertz, Shental, and Weinshall)

Learning of Pseudo-Metrics. Slide 18
MNIST Results
Euclidean distance errorFDA errorRCA error
RCA was applied after using PCA as a pre-processing step
• Each blue point corresponds to one binary classification problem
• Y-axis designates the error of POLA
• Points beneath the black diagonal line mean that POLA wins

Learning of Pseudo-Metrics. Slide 20
Toy problem
A color-coded matrix of Euclidean distances between pairs of images
Learning of Pseudo-Metrics. Slide 21
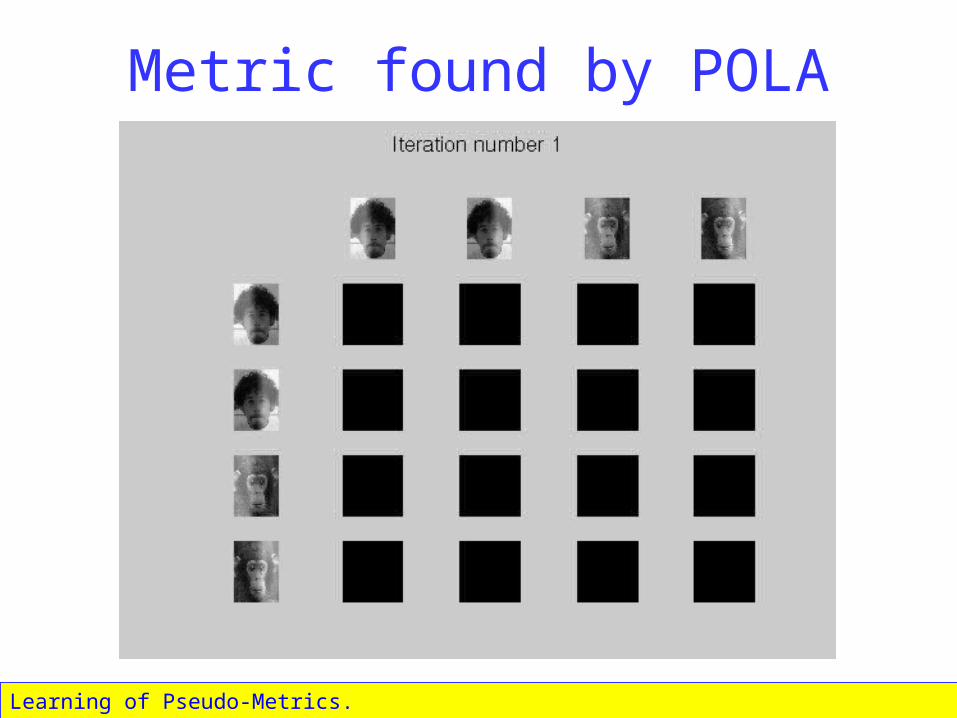
Metric found by POLA

Learning of Pseudo-Metrics. Slide 22
Mapping found by POLA
• Our Pseudo-metrics:

Learning of Pseudo-Metrics. Slide 23
Mapping found by POLA

Learning of Pseudo-Metrics. Slide 24
Summary and Extensions• An online algorithm for learning pseudo-metrics• Formal properties, good experimental results
Extensions:• Alternative regularization schemes to the
Frobenius norm • “Learning to learn”:
• Learning a metric from one set of classes and apply to another set of related classes

Learning of Pseudo-Metrics. Slide 25
• Hello bye = w ¢ x







