

Lecture 4 :PipeliningLecture 4 :Pipelining
1
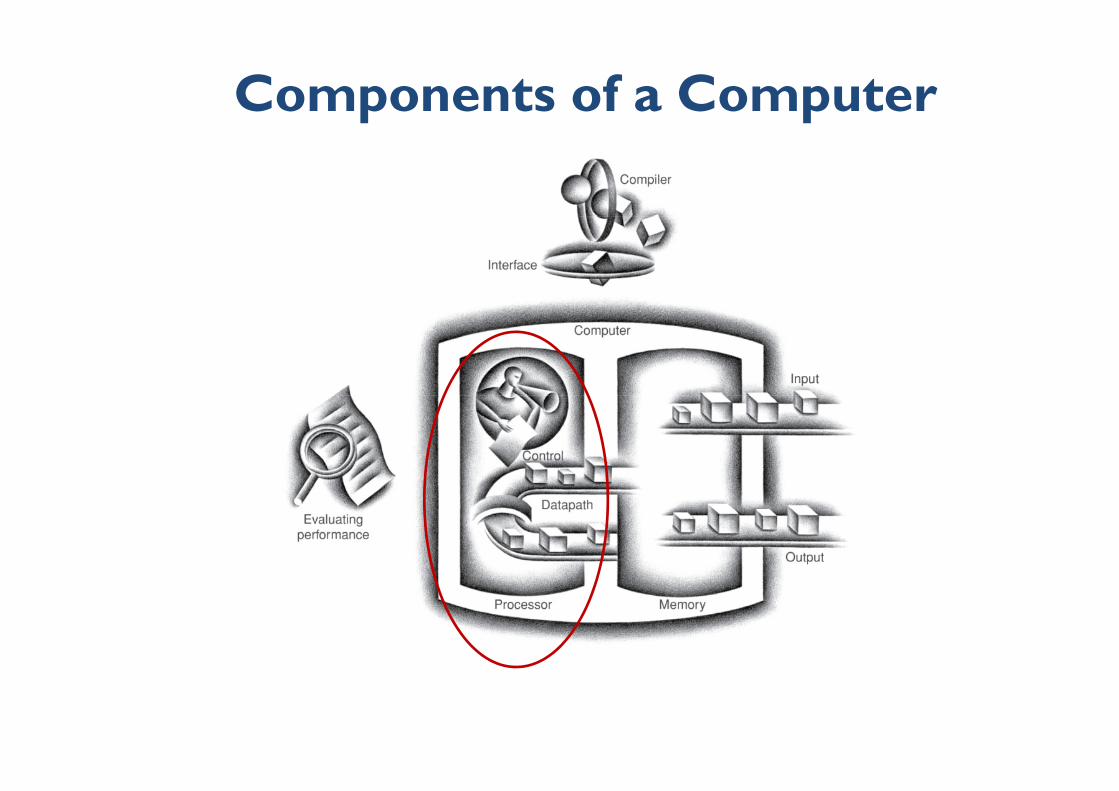
Components of a Computer

Processor
Datapath Control Component of the
processor that Component of the
processor that pperforms arithmetic operations
pcommands the datapath, memory, p p yI/O devices according to the instructions of the memory
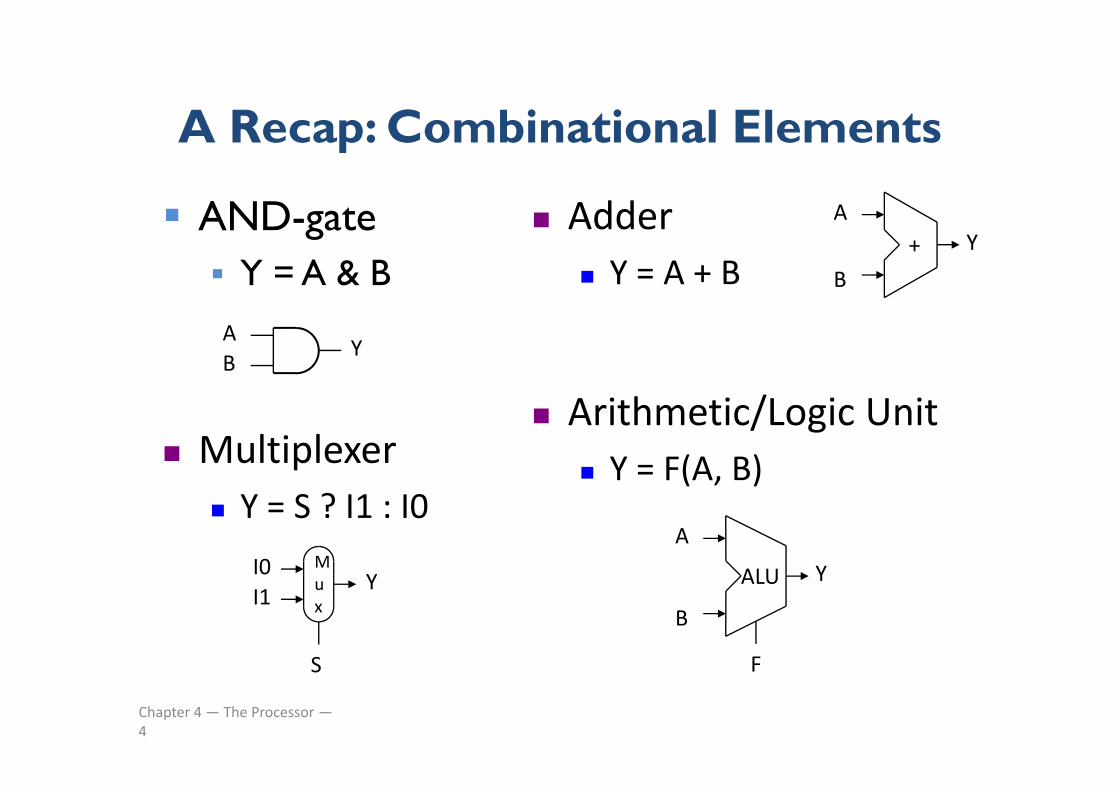
A Recap: Combinational ElementsA Recap: Combinational Elements
AND gate A Adder AND-gate Y = A & B
A
BY+
Adder Y = A + B
AB
Y
/ Multiplexer
Arithmetic/Logic Unit Y = F(A, B)
I0Y
M
Y = S ? I1 : I0A
YALU
( , )
I1Yu
x
S
B
YALU
F
Chapter 4 — The Processor —4
S F

A Recap: State Elements A Recap: State Elements
Registers Data MemoryData Memory Instruction Memory
Clocks are needed to decide when an element that contains state should be updated
5
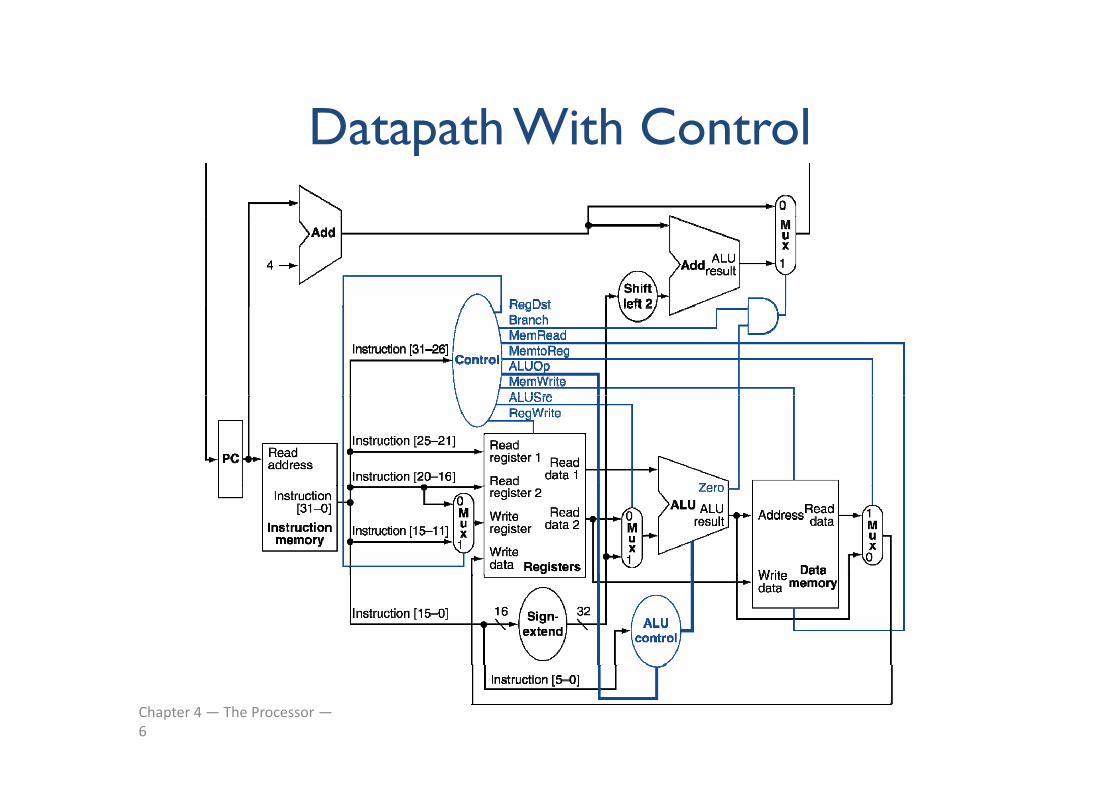
Datapath With ControlDatapath With Control
Chapter 4 — The Processor —6

Clocking Methodology Clocking Methodology
We studyEd i d h d l Edge triggered methodology
• Because it is simple
Edge triggered methodology: All state changes occur on a clock edgeAll state changes occur on a clock edge
Chapter 4 — The Processor —7

Clocking MethodologyClocking Methodology
Longest delay determines clock period
Chapter 4 — The Processor —8

Single Cycle: PerformanceSingle Cycle: Performance Assume time for stages isAssume time for stages is 100ps for register read or write
200 f h 200ps for other stages
What is the clock cycle time ?y

The 5 Stagesg
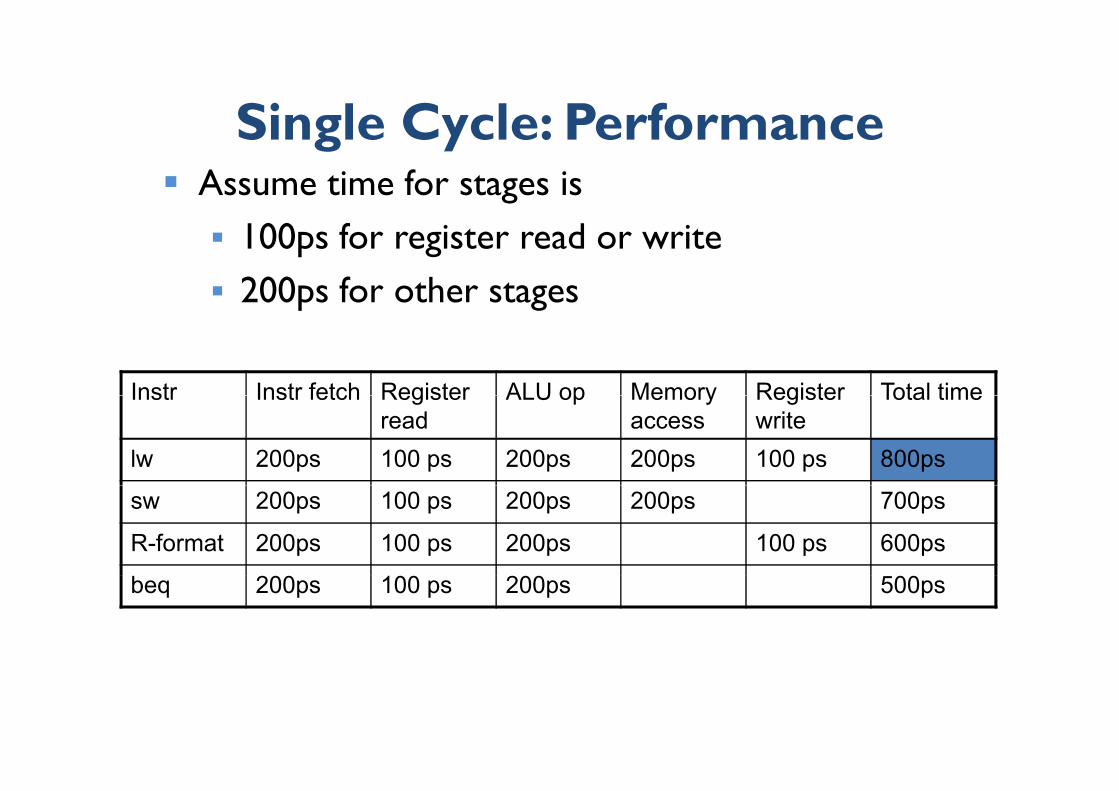
Single Cycle: PerformanceSingle Cycle: Performance Assume time for stages is 100ps for register read or write 200ps for other stagesp g
Instr Instr fetch Register ALU op Memory Register Total timeInstr Instr fetch Register read
ALU op Memory access
Register write
Total time
lw 200ps 100 ps 200ps 200ps 100 ps 800ps
sw 200ps 100 ps 200ps 200ps 700ps
R-format 200ps 100 ps 200ps 100 ps 600ps
beq 200ps 100 ps 200ps 500ps
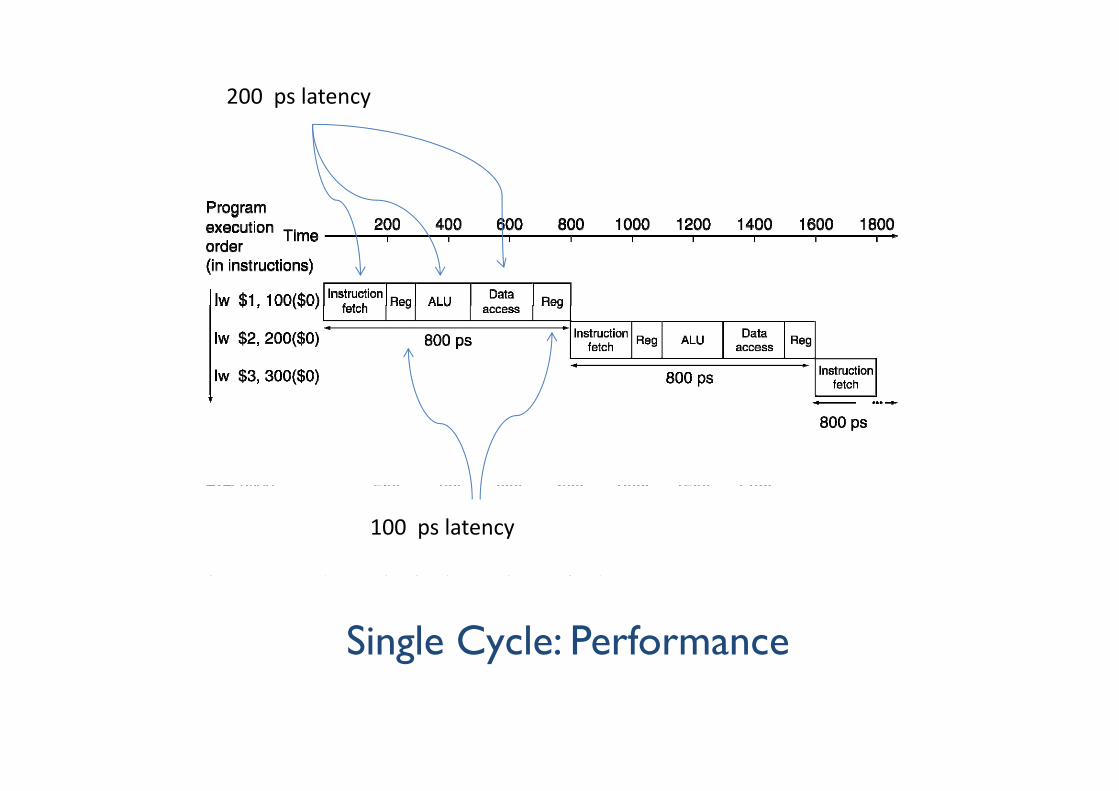
200 ps latency
100 ps latency
Single Cycle: PerformanceChapter 4 — The Processor — 12
Pipelining = Overlap the stages

Performance IssuesPerformance Issues
L d l d i l k i d Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU
data memory register filey g

Performance IssuesPerformance Issues
Violates design principle Violates design principle Making the common case fast
• (read text in p.329-330)
Improve performance by pipelining!

Recap: the stages of the datapathRecap: the stages of the datapath
W l k h d h fi We can look at the datapath as five stages, one step per stage
1. IF: Instruction fetch from memory2. ID: Instruction decode & register readg3. EX: Execute operation or calculate address4 MEM: Access memory operand4. MEM: Access memory operand5. WB: Write result back to register
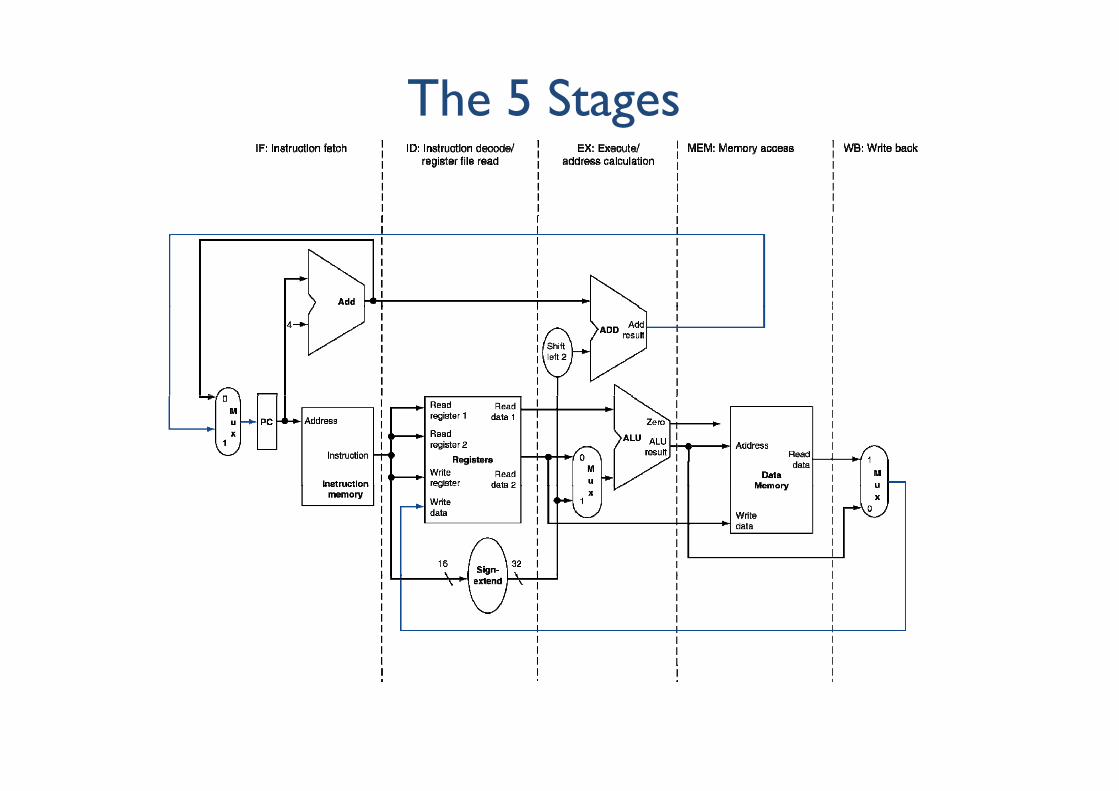
The 5 Stagesg

200 ps latency
100 ps latency
Pipelining = Overlap the stages
Chapter 4 — The Processor — 17

Pipeline Pipeline
Chapter 4 — The Processor — 18
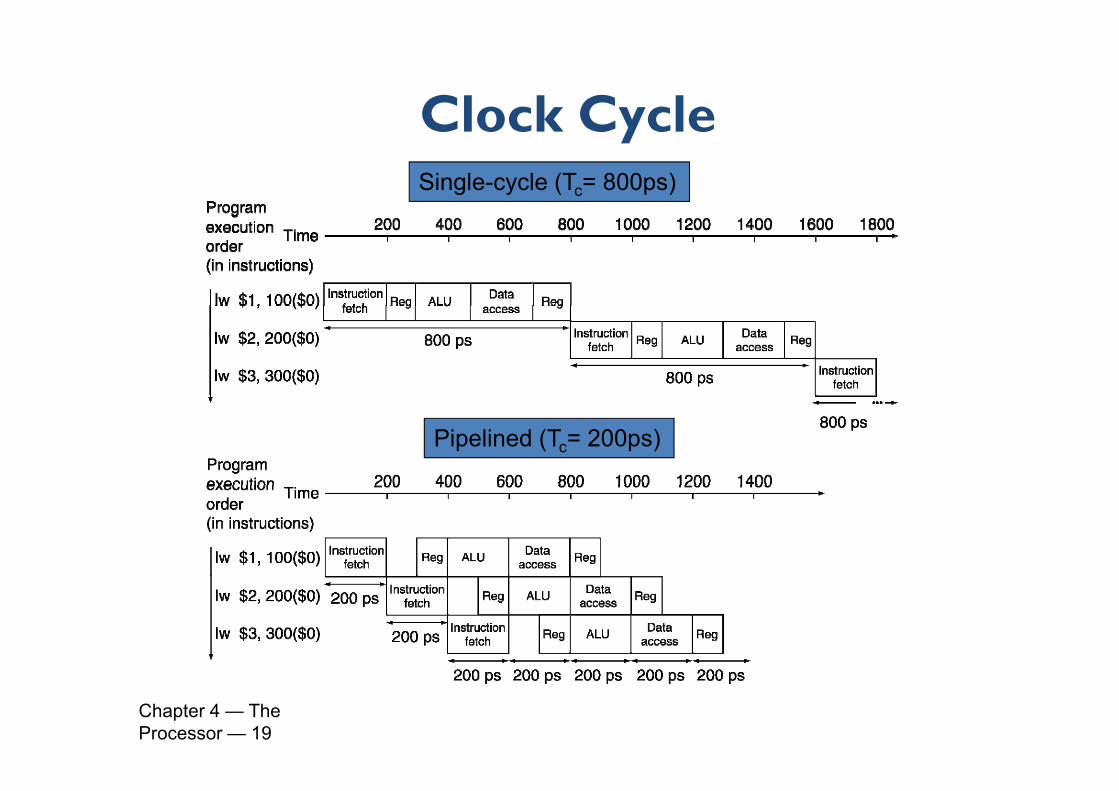
Clock CycleClock CycleSingle-cycle (Tc= 800ps)
Pipelined (Tc= 200ps)
Chapter 4 — The Processor — 19

Even if some stages take only 100ps instead of 200ps, the pipelined execution clock cycle must have the worst case clock cycle time of 200ps
20

Speedup from PipeliningSpeedup from Pipelining
If all stages are balanced i.e., all take the same time Time between instructionspipelined
= Time between instructions i li d Time between instructionsnonpipelined
Number of stages
Chapter 4 — The Processor — 21

Speedup from PipeliningSpeedup from Pipelining
If the stages are not balanced (not equal), speedup is less . Look at our example: Time between instructions (non-pipelined) = 800ps Number of stages = 5 Time between instructions (pipelined) = 800/5 =160 ps But, what did we get ?
Also read text in p.334p
Chapter 4 — The Processor — 22

Speedup from PipeliningSpeedup from Pipelining
Recall from Chapter 1: Throughput versus latency Speedup in pipelining is due to increased throughputp p p p g g p Latency (time for each instruction) does not
decreasedecrease
Chapter 4 — The Processor — 23

HazardsHazards
Situations that prevent starting the next instruction Situations that prevent starting the next instruction in the next cycle are called hazards
There are 3 kinds of hazards Structure hazards Data hazards Control hazards
Chapter 4 — The Processor — 24

Structure HazardsStructure Hazards
When an instruction cannot execute in proper cycle due to a conflict for use of a resource
Chapter 4 — The Processor — 25

Example of structural hazardExample of structural hazard Imagine
a MIPS pipeline with a single data and instruction memoryp p g y a fourth additional instruction in the pipeline; when this instruction is
trying to fetch from instruction memory, the first instruction is fetching of data memory – leading to a hazard
Hence, pipelined datapaths require separate instruction/data memories Or separate instruction/data caches

Data HazardsData Hazards An instruction depends on completion of data access
b i i iby a previous instruction
Chapter 4 — The Processor — 27

Data HazardsData Hazards add $s0, $t0, $t1
b $ 2 $ 0 $ 3sub $t2, $s0, $t3
For the above code, when can we start the second instruction ?
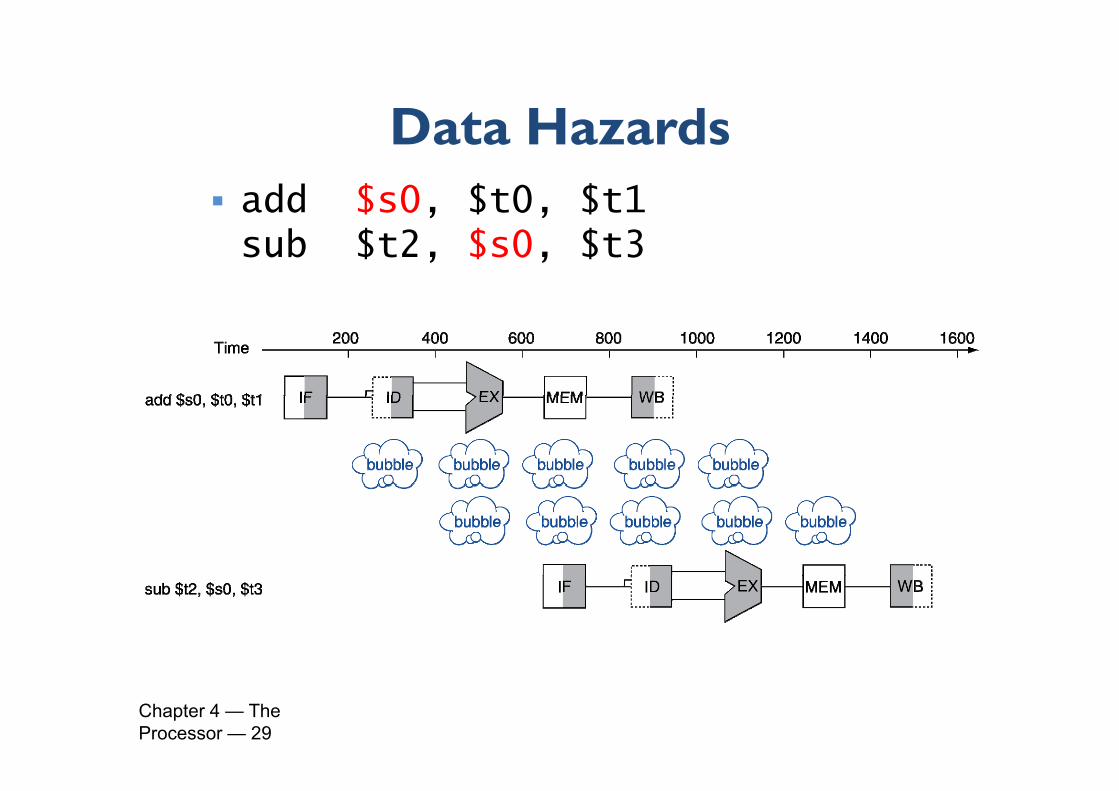
Data HazardsData Hazards add $s0, $t0, $t1, ,sub $t2, $s0, $t3
Chapter 4 — The Processor — 29

Bubble or the pipeline stall is used to resolve a hazardp p BUT it leads to wastage of cycles = performance
deteriorationdeterioration Solve the performance problem by ‘forwarding’ the
required datarequired data
30

Forwarding (aka Bypassing)Forwarding (aka Bypassing)
Use result when it is computed : don’t wait for it to Use result when it is computed : don t wait for it to be stored in a register
Requires extra connections in the datapath Requires extra connections in the datapath

Forwarding (aka Bypassing)Forwarding (aka Bypassing) add $s0, $t0, $t1sub $t2, $s0, $t3
For the above code, draw the datapath with pforwarding
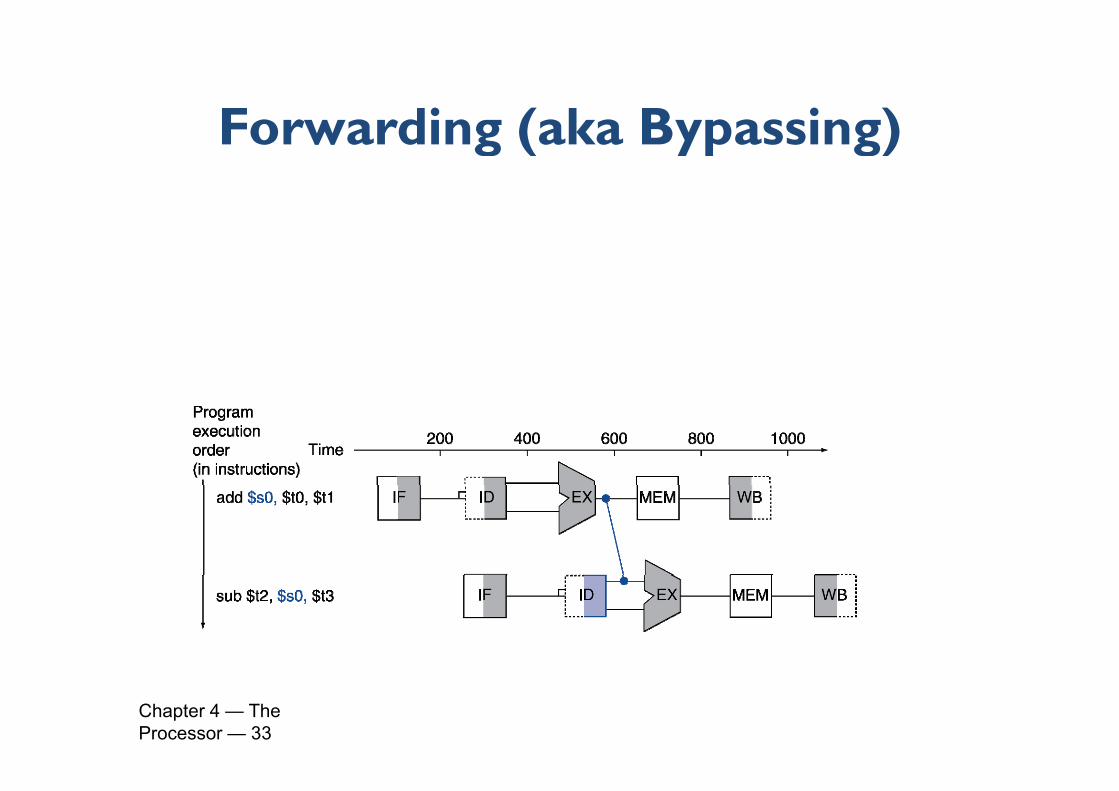
Forwarding (aka Bypassing)Forwarding (aka Bypassing)
Chapter 4 — The Processor — 33
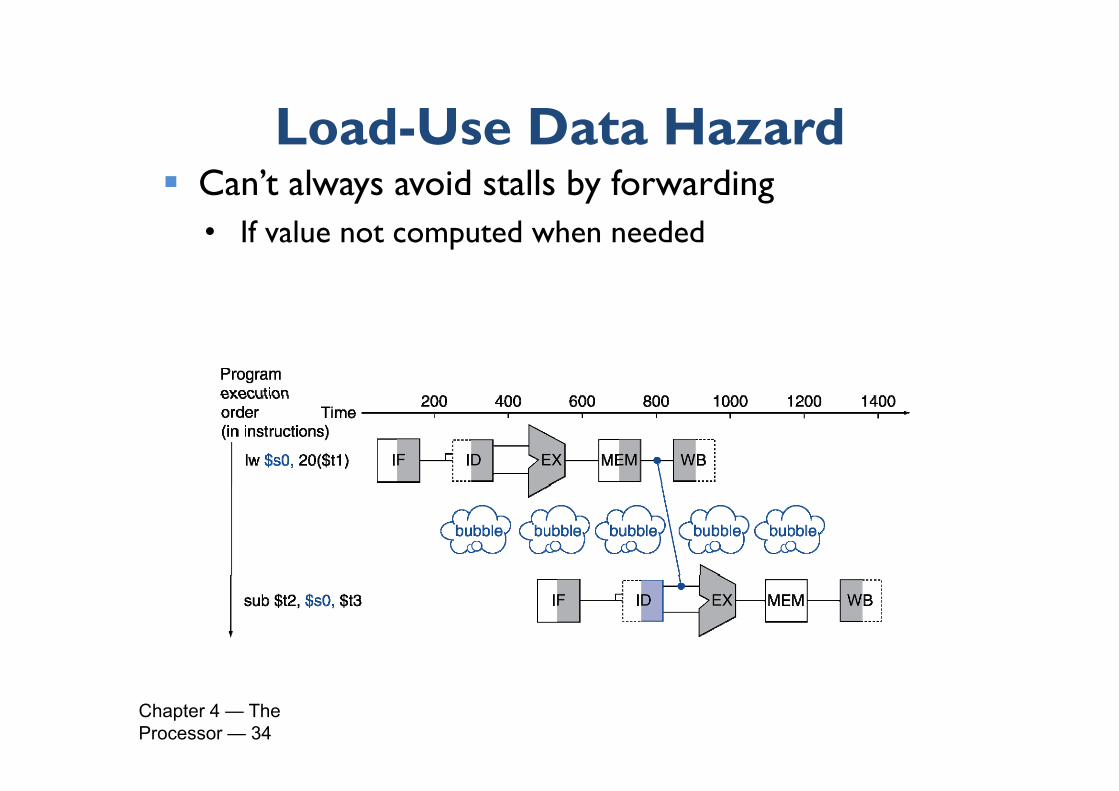
Load Use Data HazardLoad-Use Data Hazard Can’t always avoid stalls by forwarding
• If value not computed when needed
Chapter 4 — The Processor — 34

Code Scheduling to Avoid Stallsg Reorder code to avoid use of load result in the next
i iinstruction
C code for A = B + E; C = B + F;; ;
lw $t1 0($t0)lw $t1, 0($t0)
lw $t2, 4($t0)
add $t3, $t1, $t2
sw $t3, 12($t0)
lw $t4, 8($t0)
$ $ $add $t5, $t1, $t4
sw $t5, 16($t0)
13 l
Chapter 4 — The Processor — 35
13 cycles

Code Scheduling to Avoid Stallsg Reorder code to avoid use of load result in the next
i iinstruction
C code for A = B + E; C = B + F;; ;
lw $t1 0($t0)lw $t1, 0($t0)
lw $t2, 4($t0)
add $t3, $t1, $t2stallsw $t3, 12($t0)
lw $t4, 8($t0)
$ $ $
stall
add $t5, $t1, $t4
sw $t5, 16($t0)stall
13 l
Chapter 4 — The Processor — 36
13 cycles

Code Scheduling to Avoid Stallsg Reorder code to avoid use of load result in the next
i iinstruction
C code for A = B + E; C = B + F;; ;
lw $t1 0($t0) lw $t1 0($t0)lw $t1, 0($t0)
lw $t2, 4($t0)
add $t3, $t1, $t2stall
lw $t1, 0($t0)
lw $t2, 4($t0)
lw $t4, 8($t0)
sw $t3, 12($t0)
lw $t4, 8($t0)
$ $ $
stalladd $t3, $t1, $t2
sw $t3, 12($t0)
$ $ $add $t5, $t1, $t4
sw $t5, 16($t0)stall add $t5, $t1, $t4
sw $t5, 16($t0)
11 l13 l
Chapter 4 — The Processor — 37
11 cycles13 cycles

Control HazardsControl Hazards When the proper instruction cannot execute
in the proper pipeline clock cycle because the instruction that was fetched is not the one that is needed
Chapter 4 — The Processor — 38

Control HazardsControl Hazards Branch determines flow of control Fetching next instruction depends on branch
outcome
Naïve/Simple Solution: Stall if we fetch a branch pinstruction Drawback: Several cycles losty Improve by adding hardware so that already in
second stage we can know the address of the next ginstruction
Chapter 4 — The Processor — 39
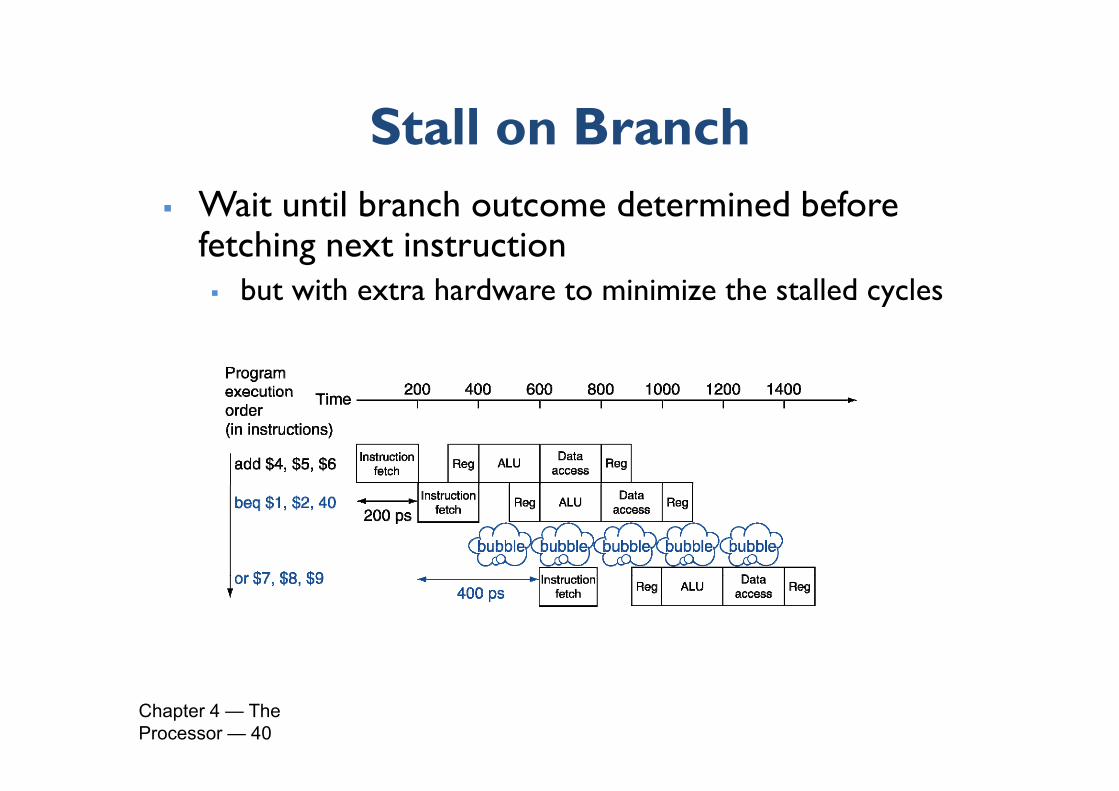
Stall on BranchStall on Branch Wait until branch outcome determined before Wait until branch outcome determined before
fetching next instruction but with extra hardware to minimize the stalled cycles y
Chapter 4 — The Processor — 40

Branch PredictionBranch Prediction Longer pipelines can’t readily determine g p p y
branch outcome early (in second stage) Stall penalty becomes unacceptable Stall penalty becomes unacceptable
Solution: predict outcome of branch Only stall if prediction is wrong We will not study the detailsy
Chapter 4 — The Processor — 41

MIPS with Predict Not TakenMIPS with Predict Not Taken
Prediction correctcorrect
Prediction incorrect
Chapter 4 — The Processor — 42

Recap: HazardsRecap: Hazards
Situations that prevent starting the next instruction Situations that prevent starting the next instruction in the next cycleS h d Structure hazards A required resource is busy
Data hazard Need to wait for previous instruction to complete Need to wait for previous instruction to complete
its data read/write Control hazard Control hazard Deciding on control action depends on previous
i t tiChapter 4 — The Processor — 43
instruction

Pipeline SummaryPipeline Summary
Pi li i i f b i i Pipelining improves performance by increasing instruction throughput Executes multiple instructions in parallel Each instruction has the same latencyEach instruction has the same latency
Subject to hazards Structure, data, control
Instruction set design affects complexity of Instruction set design affects complexity of pipeline implementation (p.335)
Chapter 4 — The Processor — 44

Instruction Level Parallelism (ILP)§
4.10 PInstruction-Level Parallelism (ILP)
Pi li i ti lti l i t ti i
Parallelis
Pipelining: executing multiple instructions in parallelT i ILP
sm and A
To increase ILP Deeper pipeline
L k t h t l k l
Advanced
• Less work per stage shorter clock cycle Multiple issue
• Replicate pipeline stages multiple pipelines
d InstructiReplicate pipeline stages multiple pipelines• Start multiple instructions per clock cycle• CPI < 1, so use Instructions Per Cycle (IPC)
E 4GH 4 lti l i
ion Leve
• E.g., 4GHz 4-way multiple-issue– 16 BIPS, peak CPI = 0.25, peak IPC = 4
• But dependencies reduce this in practice
l Parallel
Chapter 4 — The Processor — 45
ism

Multiple IssueMultiple Issue
Static multiple issue Compiler groups instructions to be issued together Packages them into “issue slots” Compiler detects and avoids hazards
Dynamic multiple issue CPU examines instruction stream and chooses
instructions to issue each cycle Compiler can help by reordering instructions CPU resolves hazards using advanced techniques at
runtime
Chapter 4 — The Processor — 46

SpeculationSpeculation
“G ” h t t d ith i t ti “Guess” what to do with an instruction Start operation as soon as possible
Ch k h th i ht Check whether guess was right• If so, complete the operation• If not, roll-back and do the right thingIf not, roll back and do the right thing
Common to static and dynamic multiple issue ExamplesExamples Speculate on branch outcome
• Roll back if path taken is differentp Speculate on load
• Roll back if location is updated
Chapter 4 — The Processor — 47

Compiler/Hardware SpeculationCompiler/Hardware Speculation
Compiler can reorder instructions Can include “fix-up” instructions to recover p
from incorrect guess Hardware can look ahead for instructions Hardware can look ahead for instructions
to execute Buffer results until it determines they are
actually needed Flush buffers on incorrect speculation
Chapter 4 — The Processor — 48

Static Multiple IssueStatic Multiple Issue
C il i t ti i t “i Compiler groups instructions into “issue packets” Group of instructions that can be issued on a
single cycle Determined by pipeline resources required
Think of an issue packet as a very longThink of an issue packet as a very long instruction Specifies multiple concurrent operations Specifies multiple concurrent operations Very Long Instruction Word (VLIW)
Chapter 4 — The Processor — 49

Scheduling Static Multiple IssueScheduling Static Multiple Issue
Compiler must remove some/all hazards Reorder instructions into issue packetsp No dependencies with a packet
Possibly some dependencies between Possibly some dependencies between packets
V i b t ISA il t k !• Varies between ISAs; compiler must know! Pad with nop if necessary
Chapter 4 — The Processor — 50
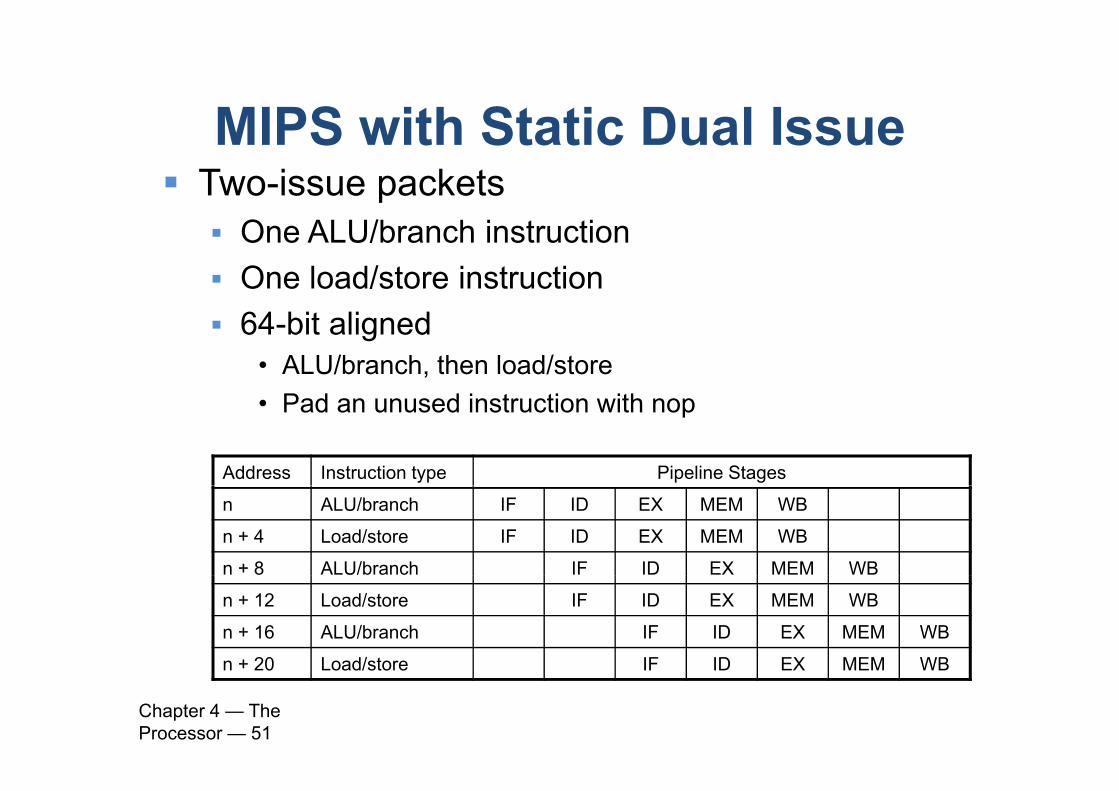
MIPS with Static Dual IssueMIPS with Static Dual Issue Two-issue packets One ALU/branch instruction One load/store instruction 64-bit aligned
• ALU/branch, then load/storeP d d i t ti ith• Pad an unused instruction with nop
Address Instruction type Pipeline Stages
n ALU/branch IF ID EX MEM WB
n + 4 Load/store IF ID EX MEM WB
n + 8 ALU/branch IF ID EX MEM WB
n + 12 Load/store IF ID EX MEM WB
n + 16 ALU/branch IF ID EX MEM WB
n + 20 Load/store IF ID EX MEM WB
Chapter 4 — The Processor — 51
n + 20 Load/store IF ID EX MEM WB
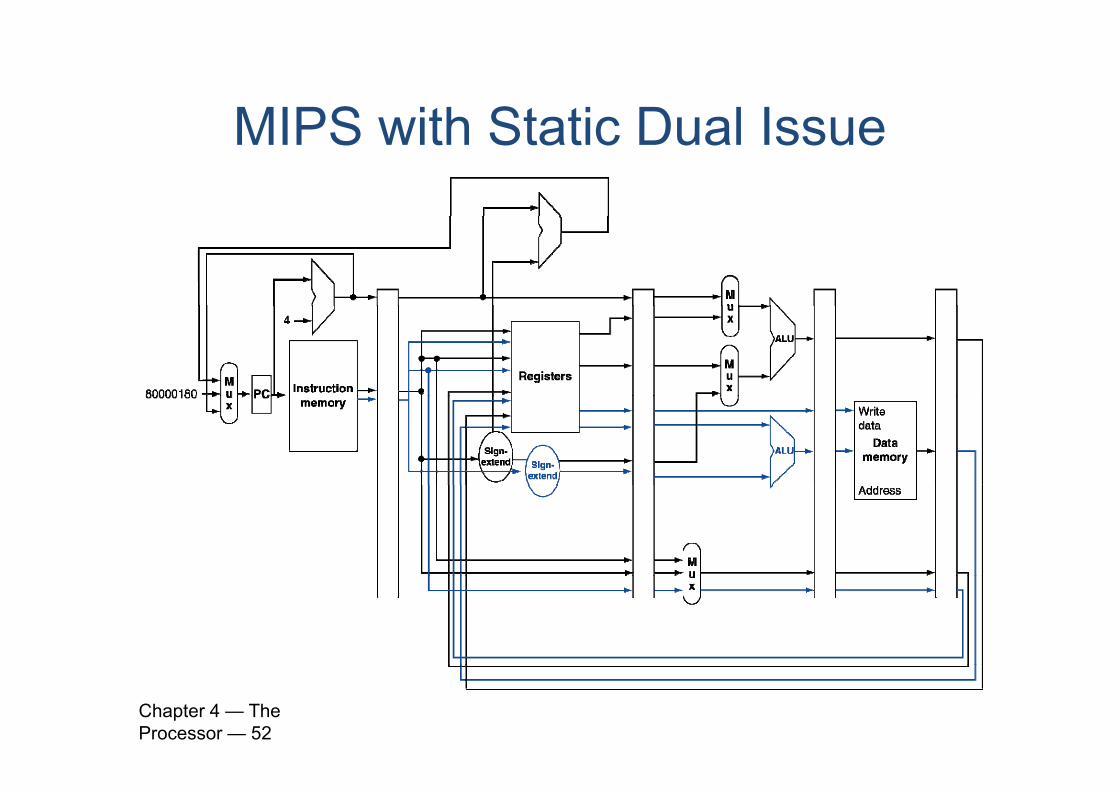
MIPS with Static Dual IssueMIPS with Static Dual Issue
Chapter 4 — The Processor — 52

Hazards in the Dual Issue MIPSHazards in the Dual-Issue MIPS
More instructions executing in parallel Data hazard Forwarding avoided stalls with single-issue Now can’t use ALU result in load/store in same packetp
• add $t0, $s0, $s1load $s2, 0($t0)
S lit i t t k t ff ti l t ll• Split into two packets, effectively a stall
Load-use hazard Still one cycle use latency, but now two instructions
More aggressive scheduling required
Chapter 4 — The Processor — 53

Dynamic Multiple IssueDynamic Multiple Issue
“Superscalar” processors CPU decides whether to issue 0 1 2CPU decides whether to issue 0, 1, 2, …
each cycleA idi t t l d d t h d Avoiding structural and data hazards
Avoids the need for compiler schedulingp g Though it may still help Code semantics ensured by the CPU Code semantics ensured by the CPU
Chapter 4 — The Processor — 54

Dynamic Pipeline SchedulingDynamic Pipeline Scheduling
Allow the CPU to execute instructions out of order to avoid stalls But commit result to registers in order
Example Examplelw $t0, 20($s2)addu $t1, $t0, $t2sub $s4, $s4, $t3
$ $slti $t5, $s4, 20
Can start sub while addu is waiting for lwChapter 4 — The Processor — 55
g

Dynamically Scheduled CPUDynamically Scheduled CPUPreserves dependenciesdependencies
Hold pending operands
Results also sent to any waiting reservation stations
Reorders buffer for register writes
Can supply operands for issued
Chapter 4 — The Processor — 56
for issued instructions

Why Do Dynamic Scheduling?Why Do Dynamic Scheduling?
Why not just let the compiler schedule code? Not all stalls are predicable
h i e.g., cache misses Can’t always schedule around branchesy Branch outcome is dynamically determined
Different implementations of an ISA have Different implementations of an ISA have different latencies and hazards
Chapter 4 — The Processor — 57

Does Multiple Issue Work?Does Multiple Issue Work?
Yes, but not as much as we’d like Programs have real dependencies that limit ILP Programs have real dependencies that limit ILP Some dependencies are hard to eliminate Some parallelism is hard to expose Limited window size during instruction issueg
Memory delays and limited bandwidth Hard to keep pipelines fullHard to keep pipelines full
Speculation can help if done well
Chapter 4 — The Processor — 58







