

R as superglue language
f.jamitzky
http://goo.gl/Iwajh

One R to rule them all
●C/C++/objectiveC
●Fortran
●java
●Mpi
●Threads
●opengl
●ssh
●web server/client
●linux mac mswin
●R shell
●R gui
●math notebook
●automatic latex/pdf
●vtk

One R to bind them
●C/C++/objectiveC
●Fortran
●java
●R objects
●R objects
●.C("funcname", args...)
●.Fortran("test", args...)
●.jcall("class", args...)
●.Call
●.External

C integration
●shared object libraries can
be used in R out of the box
●R arrays are mapped to C
pointers
R C
integer int*
numeric double*
character char*
Example:
R CMD SHLIB -o test.so
test.c
use in R:
> dyn.load("test.so")
> .C("test", args)

C example
test.c:
void test(double* x, double* v, int *np, double *dt) {
int i;
double dx,dv;
for(i=0; i< *np; i++) {
dx=v[i]* *dt; dv=-x[i]* *dt;
x[i]+=dx; v[i]+=dv;
}
}
in R:
.C("test",as.numeric(runif(10)),as.numeric(runif(10)),as.integer(
10), as.numeric(0.01))

FORTRAN integration
test.f90:
subroutine testf(x,v,nstep)
! simulate harmonic oscillator
integer, parameter :: np=1000
real*8 :: x(np), v(np), dx(np), dv(np), dt=0.001
integer :: i,j, nstep
do j=1,nstep
dx=v*dt; dv=-x*dt
x=x+dx; v=v+dv
end do
return
end subroutine
gfortran -shared -fPIC -o test_f.so test.f90
in R:
dyn.load("test_f.so")
str(.Fortran("testf",as.numeric(runif(1000)),as.numeric(runif(1000)),as.integer(10000)))

even more: GPGPU acceleration
test.f90:
subroutine testf(x,v,nstep)
! simulate harmonic oscillator
integer, parameter :: np=1000
real*8 :: x(np), v(np), dx(np), dv(np), dt=0.001
integer :: i,j, nstep
do j=1,nstep
!$acc region
dx=v*dt; dv=-x*dt
x=x+dx; v=v+dv
!$acc end region
end do
return
end subroutine

Compare
don't forget to load the modules!
module unload ccomp fortran
module load ccomp/pgi/10.4
module load fortran/pgi/10.4
module load R/2.10.1plain
pgf90 -shared -fPIC -o mysub_host.so mysub_host.f90
pgf90 -ta=nvidia -shared -fPIC -o mysub_cuda.so
mysub_cuda.f90

Load and run
Load dynamic libraries> dyn.load("mysub_host.so"), dyn.load("mysub_cuda.so"); np=1000000
Benchmark> system.time(str(.Fortran("mysub_host",x=numeric(np),v=numeric(np),nstep=as.integer(1000))))
total energy: 666667.6633012500
total energy: 667334.6641391169
List of 3
$ x : num [1:1000000] -3.01e-07 -6.03e-07 -9.04e-07 -1.21e-06 -1.51e-06 ...
$ v : num [1:1000000] 1.38e-06 2.76e-06 4.15e-06 5.53e-06 6.91e-06 ...
$ nstep: int 1000
user system elapsed
26.901 0.000 26.900
> system.time(str(.Fortran("mysub_cuda",x=numeric(np),v=numeric(np),nstep=as.integer(1000))))
total energy: 666667.6633012500
total energy: 667334.6641391169
List of 3
$ x : num [1:1000000] -3.01e-07 -6.03e-07 -9.04e-07 -1.21e-06 -1.51e-06 ...
$ v : num [1:1000000] 1.38e-06 2.76e-06 4.15e-06 5.53e-06 6.91e-06 ...
$ nstep: int 1000
user system elapsed
0.829 0.000 0.830
Acceleration Factor:> 26.9/0.83
[1] 32.40964

opengl bindings for R
●library(rgl)
●abstraction for opengl primitives:
osurfaces, spheres, triangles
opoints, lines, text, sprites
olights, background, materials, textures

Simple Example: colored spheres
rgl.clear("all")
rgl.bg(sphere = T, back = "lines")
rgl.light()
rgl.bbox()
x=runif(1000)
y=runif(1000)
z=runif(1000)
col=rainbow(1000)
rad=runif(1000)/10
rgl.spheres(x,y,z,col=col,radius=rad)
clear space
set background
some light
bounding box
some coordinates
set colors
set radii
generate the spheres

rgl.spheres(x,y,z,col=col,radius=rad)

Simple Example: surface
rgl.clear("shapes")
data(volcano)
y = 2*volcano
x=10 * (1:nrow(y))
z=10 * (1:ncol(y))
rgl.surface(x, z, y, back="lines")
clear space
some data
define coordinates
plot surface
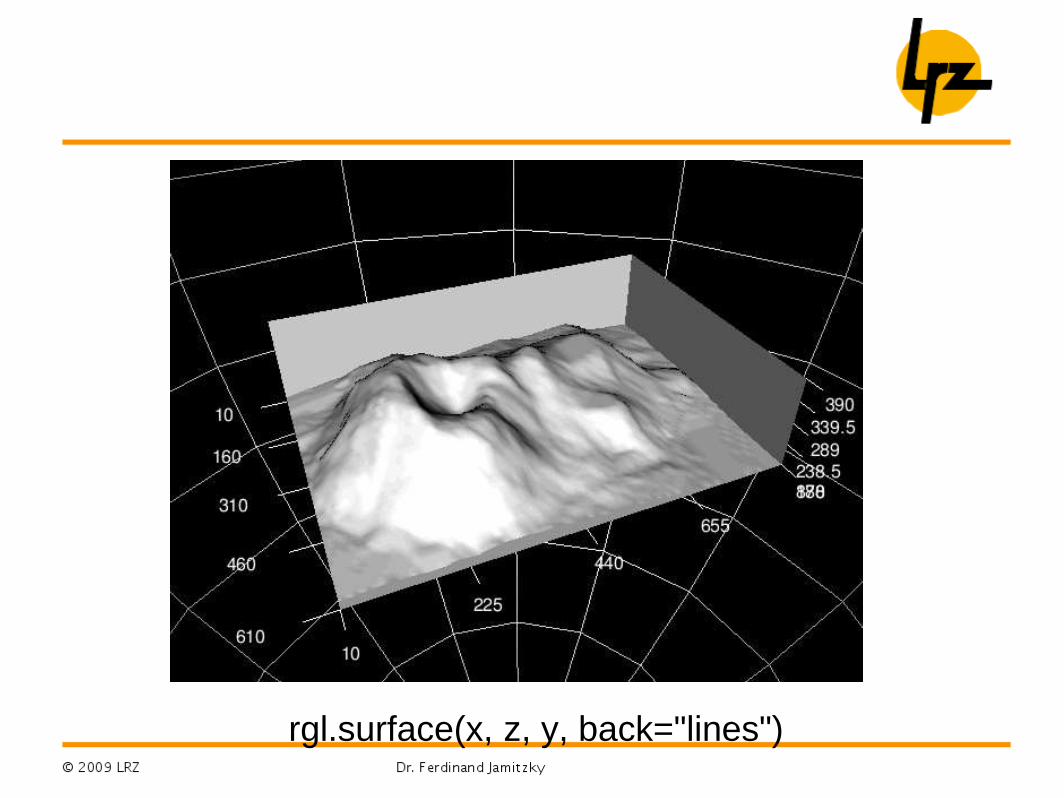
rgl.surface(x, z, y, back="lines")

scatterplots
●load data into graka
●catch mouse and kbd events
●e.g. run prefilter on linux cluster via snow
●update data dynamically

Parallel programming with R
●Parallel APIs:
oSMP - multicore
oMPP - mpi
ossh - snow
●Abstraction:
●foreach package
●doMC
●doMPI
●doSNOW
Example:
library(doMC)
registerDoMC(cores=5)
foreach(i=1:10) %dopar%
sqrt(i)
roots -> foreach(i=1:10)
%dopar% sqrt(i)

multithreading with R
library(foreach)
foreach(i=1:N) %do%
{
mmult.f()
}
# serial execution
library(foreach)
library(doMC)
registerDoMC()
foreach(i=1:N)
%dopar%
{
mmult.f()
}
# thread execution

MPI with R
library(foreach)
foreach(i=1:N) %do%
{
mmult.f()
}
# serial execution
library(foreach)
library(doSNOW)
registerDoSNOW()
foreach(i=1:N)
%dopar%
{
mmult.f()
}
# MPI execution

doMC
# R
> library(foreach)
> library(doMC)
> registerDoMC(cores=4)
> system.time(foreach(i=1:10) %do%
sum(runif(10000000)))
user system elapsed
9.352 2.652 12.002
> system.time(foreach(i=1:10) %dopar%
sum(runif(10000000)))
user system elapsed
7.228 7.216 3.296
doSNOW
# mpirun -np 5 R --no-save -q
> library(doSNOW)
> registerDoSNOW(getMPIcluster())
> system.time(foreach(i=1:10) %do%
sum(runif(10000000)))
user system elapsed
15.377 0.928 16.303
> system.time(foreach(i=1:10) %dopar%
sum(runif(10000000)))
user system elapsed
4.864 0.000 4.865

R and ssh
●snow and foreach
abstraction
●socket connection
●tunneling
●gsissh certificate
based (in progress)

MPI-CUDA with R
Using doSNOW and dyn.load with pgifortran:
library(doSNOW)
cl=makeCluster(c("gvs1","gvs2"),type="SOCK")
registerDoSNOW(cl)
foreach(i=1:2) %dopar% setwd("~/KURSE/R_cuda")
foreach(i=1:2) %dopar% dyn.load("mysub_cuda.so")
system.time(
foreach(i=1:4) %dopar%
str(.Fortran("mysub_cuda",x=numeric(np),v=numeric(np)
,
nstep=as.integer(1000))))

R as web client
●source(textObject)
●textObject can be:
●file
●url
●pipe
●clipboard
●...
●rcurl
●all http requests
●get put del post
●https cookies
●e.g. googledocs

R as web server
●rpad webserver
●rapache webserver
●rserve
●r2html
●r4x
●xml lib
●automatic conversion
●r callbacks







