

m2r2: A Framework for Results Materialization and
Reuse in High-Level Dataflow Systems for Big Data
2nd International Conference on Big Data Science and Engineering (BDSE 2013)
Vasiliki Kalavri, Hui Shang, Vladimir Vlassov{kalavri, hshang, vladv}@kth.se
4 December 2013, Sydney, Australia

Outline
➔ Motivation➔ Materialized Views in Relational DBMSs➔ High-Level Dataflow Systems for Big Data
◆ similarities in design and implementation
➔ m2r2 design◆ design goals and system components
➔ Prototype Implementation Details➔ Evaluation Results➔ Conclusions and Future Work
2

Motivation
➔ Avoid computational redundancies◆ filter out bad records, spam e-mail◆ data representation transformations
➔ Microsoft has found a 30%-60% similarity in queries submitted for execution
➔ A Berkeley MapReduce workload characterization study shows a big need for caching job results
3

Materialized Views in RDBMSs
➔ A derived relation, stored in the database◆ Queries are computed using the views instead of
the base relations
➔ Challenges◆ View Design: What to materialize?◆ View Maintenance: How to update the views?◆ View Exploitation: How to use the views for query
optimization?● view matching and query rewriting
4

High-Level Dataflow Systems (1)
High-Level Dataflow Systems for Big Data (Pig, Hive, Jaql, DryadLINQ, etc.) exhibit wide similarities on multiple design levels:➔ Language Layer
◆ Declarative, SQL-like language◆ Statements define transformations on collections of datasets
➔ Data Operators◆ Encapsulate the logic of the transformations to be performed◆ Relational, Expressions, Control-flow
5

High-Level Dataflow Systems (2)
Pig Latin
HiveQL
Jaql
6

High-Level Dataflow Systems (3)
● The Logical Plan○ Parser → AST → DAG of operators
● Compilation to an Execution Plan
7

m2r2: materialize - match - rewrite - reuse
➔ A language-independent, extensible framework for◆ storing◆ managing and◆ using
previous job and sub-job results
➔ Operates on the logical plan level, in order to support different languages and backend execution engines
8

m2r2 Components
➔ Plan Matcher and Rewriter◆ How to be independent of the high-level
language and execution engine?◆ Shark: Hive on Spark, PonIC: Pig on
Stratosphere, etc.? → Match at the Logical Plan level!
➔ Plan Optimizer➔ Results Cache➔ Plan Repository➔ Garbage Collector
9
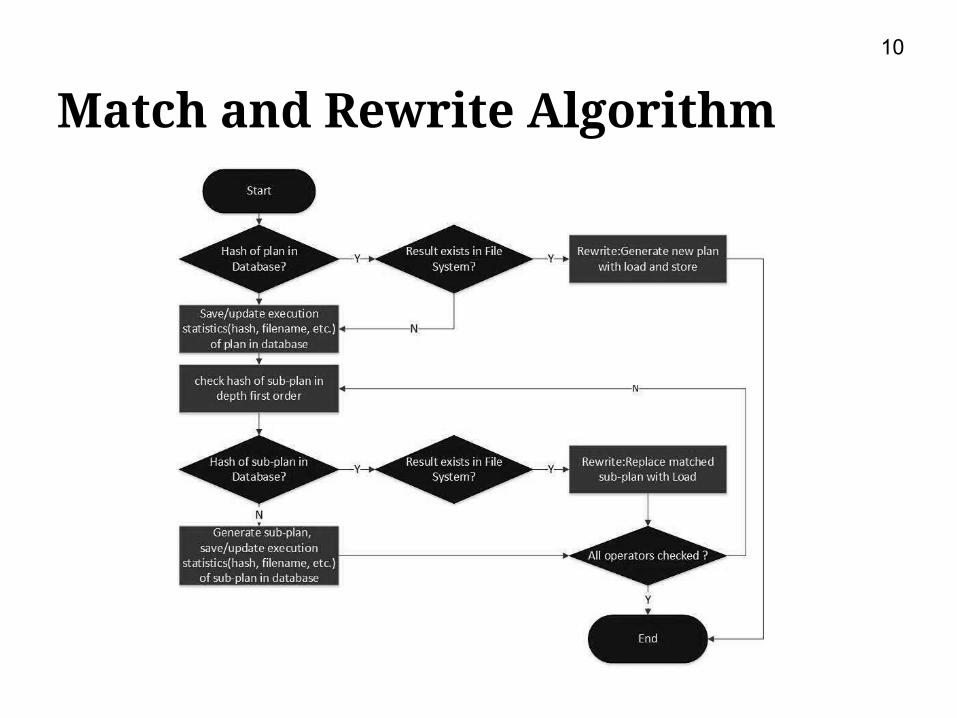
Match and Rewrite Algorithm
10

m2r2 Implementation
➔ Built on top of Pig/Hadoop
➔ HDFS as the Results Cache➔ MySQL Cluster as the
Repository◆ in-memory, highly-available
and fault-tolerant
➔ Garbage Collection as a separate module◆ policy on reuse frequency and
last access time
11

Evaluation Setup12
➔ Cluster Setup◆ Pig 0.11, Hadoop 1.0.4 and MySQL Cluster 7.2.12
deployed on top of OpenStack◆ 20 Ubuntu 11.10 VMs
➔ Data and Queries◆ TPC-H Benchmark for Pig◆ 20 queries, out of which 6 with reuse
opportunity◆ 107 GB of data using DBGEN tools of TPC-H

Speedup using Sub-Jobs
13

Speedup using Whole Jobs
14

Conclusions15
➔ The logical plan is the proper layer to build a language-independent reuse framework
➔ When there exists reuse opportunity, query execution time can be immensely reduced
◆ 65% on average in our experiments➔ The materialization overhead is quite
small and I/O dominant

Future Work
➔ Integrate with other high-level systems➔ Explore the possibility of sharing results
among different frameworks➔ Obtain execution traces and perform a
more realistic evaluation➔ Minimize costs by overlapping
materialization with regular query execution
16

m2r2: A Framework for Results Materialization and
Reuse in High-Level Dataflow Systems for Big Data
2nd International Conference on Big Data Science and Engineering (BDSE 2013)
Vasiliki Kalavri, Hui Shang, Vladimir Vlassov{kalavri, hshang, vladv}@kth.se
4 December 2013, Sydney, Australia







