

More Machine Learning
PerceptronSupport Vector Machines and Margins
The Kernel TrickK-Nearest Neighbor

Recall: Key Components of Intelligent Agents
Representation Language: Graph, Bayes Nets, Linear functions
Inference Mechanism: A*, variable elimination, Gibbs sampling
Learning Mechanism: Maximum Likelihood, Laplace Smoothing, gradient descent, many more: perceptron, k-Nearest Neighbor, …
-------------------------------------Evaluation Metric: Likelihood, quadratic loss (a.k.a. squared error), regularized loss, many more: margins, 0-1 loss, conditional likelihood, precision/recall, …

Linear Separability
Linear Separator
Data has two features: X1 and X2.Two possible labels: blue and red.
X2
X1

Linear Classification
Suppose there are N input variables, X1, …, XN (all real numbers).
A linear classifier is a function that looks like this:
The wi variables are called weights or parameters. Each one is a real number.
The set of all functions that look like this (one function for each choice of weights w0 through wN) is called the Hypothesis Class for linear regression.
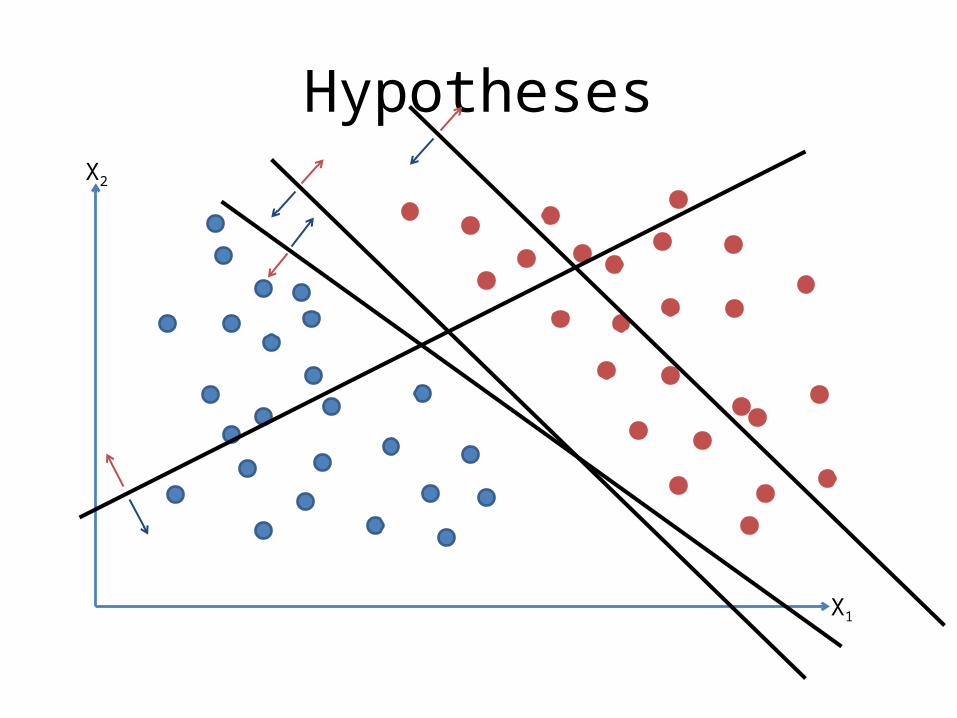
HypothesesX2
X1

Quiz: Making predictionsA: Which label?
C: Which label?
B: Which label?
X2
X1

Answer: Making predictionsA: Which label?
C: Which label?
B: Which label?
X2
X1

The Perceptron Algorithm
Input: Training data (Xi1, …, XiN, Yi), where each Yi is either 0 or 1.
1. Set each wj random initial guess
2. For each training example i:For each weight wj:
wj wj + α (Yi – f(Xi1, …, XiN))
Output: weights wj
ErrorLearning Rate

Properties of Perceptron
Convergence: If the data set is linearly separable, then the Perceptron algorithm converges to a linear separator (amazingly enough).
(If there is no linear separator, then perceptron will keep moving the line around forever.)
Online: Unlike gradient descent, MLE, etc., the Perceptron algorithm can train by looking at one example at a time, rather than processing all of the data in a batch. This is something called an online training algorithm.

QuizX2
X1
a
bc
Which classifier would you prefer?

AnswerX2
X1
a
bc
It’s an opinion question, so any answer is acceptable. But machine learning people prefer b. Intuitively, b has the best chance of classifying a new data point correctly. a and c are overfitting.

MarginX2
X1
a
bc
marginDistance between the linear separator and the nearest data point.

Maximum Margin Learning
A very popular approach to combating overfitting is to select hypotheses with large margins.
This is called “maximum margin” learning.
Two very popular techniques:• Support Vector Machines• Boosting
These techniques are beyond the scope of this class.
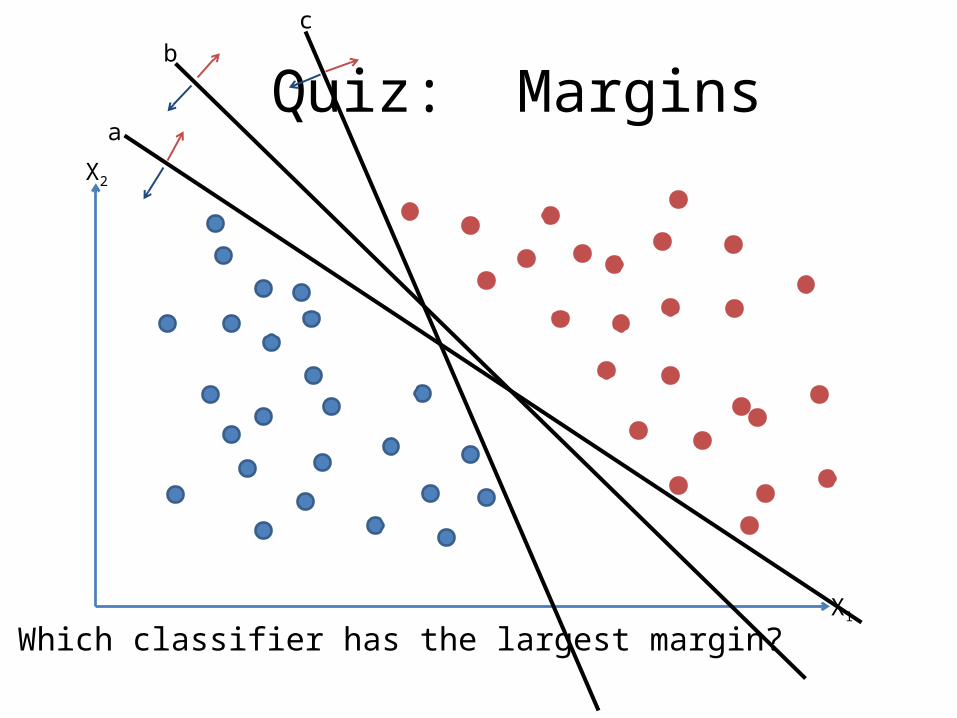
Quiz: MarginsX2
X1
a
bc
Which classifier has the largest margin?

Answer: MarginsX2
X1
a
bc
Answer: b is farthest from the data, so it has the largest margin.

Non-linear (or non-linearly-separable) data
No line can separate these two classes.
X2
X1

The “Kernel Trick”
X2
X1
The Kernel Trick is to add a new input variable that is computed from the existing ones.
Let
X3
Now there’s a linear separator!
In the original feature space, the linear separator looks like a circle.

The “Kernel Trick”
SVMs use automatic methods (called “kernels”) to add new features to a learning problem. We won’t go into these in detail.
The important lesson: it’s possible to apply linear classifiers to non-linearly-separable data, by extending the feature space.

Parametric vs. Nonparametric models
Almost all models for machine learning have “parameters” or “weights” that need to be learned.
Parametric Models Nonparametric modelsThe number of parameters is constant, or independent of the number of training examples.
The number of parameters grows with the number of training examples.

Parametric Model Examples
Linear regression: Each training example has N inputs, X1, …, XN.
It doesn’t matter how many examples are in the training data, the regression model will always have N+1 weights.
This number is independent of the number of training examples (M).
So linear regression is parametric.

Parametric Model Examples
Naïve Bayes (with fixed vocabulary): Each training example has a 1 or 0 for every word in the vocabulary.
No matter how many training examples there are, we will only need parameters for the number of words in the vocabulary, which is fixed.
So this number is independent of the number of training examples (M).
So Naïve Bayes (with fixed vocabulary size) is parametric.

Quiz: Nonparametric Model: k-Nearest Neighbor Classifier
a
bc
Color each blank point with the color of its closest neighbor.
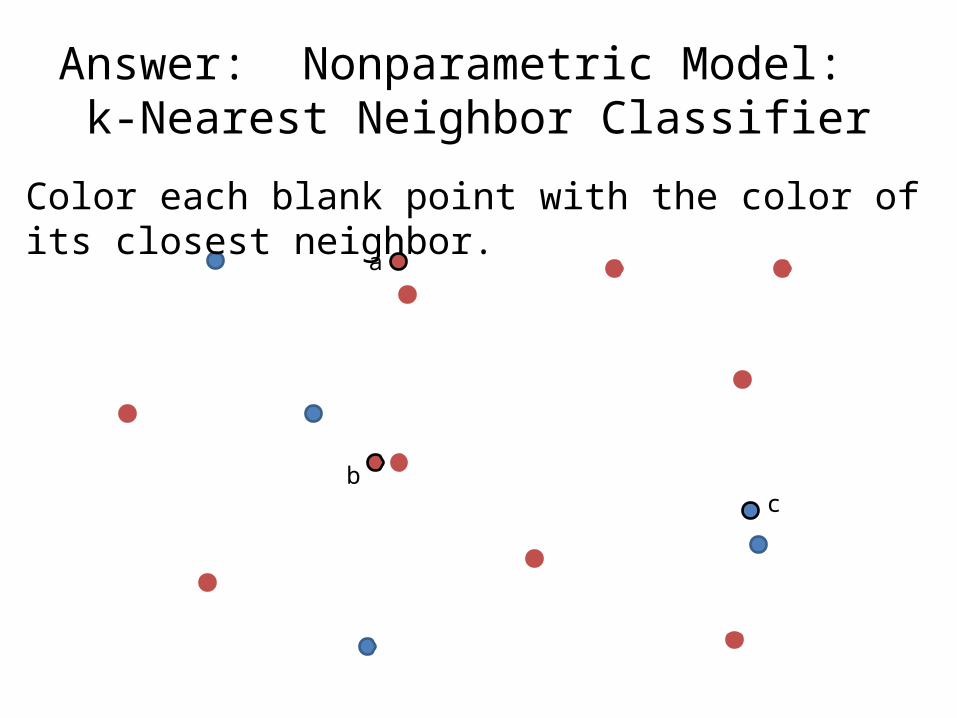
Answer: Nonparametric Model: k-Nearest Neighbor Classifier
a
bc
Color each blank point with the color of its closest neighbor.
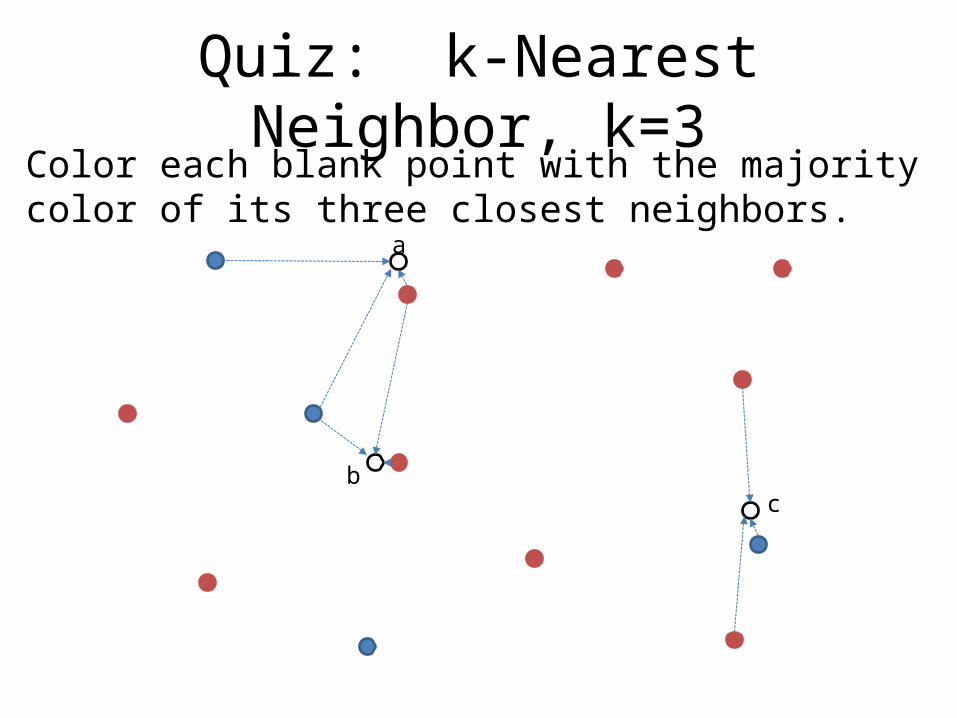
Quiz: k-Nearest Neighbor, k=3
a
bc
Color each blank point with the majority color of its three closest neighbors.

Quiz: k-Nearest Neighbor, k=3
a
bc
Color each blank point with the majority color of its three closest neighbors.

The k-Nearest Neighbor Classifier
Learning algorithm: memorize the X and Y components of each training example.
Inference algorithm: For each new point X, find the k nearest points from the training data, and select the most common Y value from those training data points. Use that Y value as the prediction.

Properties of k-NN
Convergence: as the number of training examples grows, the expected accuracy on test data points approaches 100%.
Smoothing: Higher values of k can be used to combat overfitting. Typically, only odd values of k are used, to ensure that there are no ties during prediction.
Complexity: Training k-NN is very simple: just memorize each training data point. However, finding the nearest neighbors at test time can be an expensive operation. All sorts of hashing and indexing techniques have been invented to improve the time complexity of inference, but this remains an active area of study.

Quiz: Learning model typesModel Classification or
Regression?Generative or
Discriminative?Parametric or
Nonparametric?
Bayes Net
Naïve Bayes
Linear Regression
Linear Classifier
K-Nearest Neighbor

Answers: Learning model typesModel Classification or
Regression?Generative or
Discriminative?Parametric or
Nonparametric?
Bayes Net Classification (from what you’ve seen,
although it’s possible to do
regression as well)
Generative Parametric
Naïve Bayes Classification Generative Parametric
Linear Regression Regression Discriminative Parametric
Linear Classifier Classification Discriminative Parametric
K-Nearest Neighbor Classification (or regression)
Discriminative Nonparametric

Quiz: Learning algorithm typesAlgorithm Supervised or
Unsupervised?Online or batch? Closed-form or
iterative?
MLE
Laplace Smoothing
Minimize Squared Error (for linear regression)
Gradient Descent
Perceptron
k-NN training (memorization)

Answers: Learning algorithm typesAlgorithm Supervised or
Unsupervised?Online or batch? Closed-form or
iterative?
MLE Supervised Batch Closed-form
Laplace Smoothing Supervised Batch Closed-form
Minimize Squared Error (for linear regression)
Supervised Batch Closed-form
Gradient Descent Supervised Batch Iterative
Perceptron Supervised Online Iterative
k-NN training (memorization)
Supervised Online Closed-form

Quiz: Preventing overfittingModel Method to prevent overfitting
Bayes Net/Naïve Bayes
Linear Regression
Linear Classification
k-NN

Answers: Preventing overfittingModel Name an appropriate method to prevent overfitting
Bayes Net/Naïve Bayes Laplace smoothing
Linear Regression L1 or L2 regularization + gradient descent
Linear Classification Maximum margin learning
k-NN Choose higher values of k







