

Personalized Search Result Diversification via Structured LearningSHANGSONG LIANG, ZHAOCHUN REN, MAARTEN DE RIJKE
UNIVERSITY OF AMSTERDAM
PRESENTED BY YU HU

Tackling Ambiguous Query Personalization approach:
◦ Tailor the results to the specific interests of the user
◦ Inaccurate user profile
◦ When query is unrelated to the personalized information
Diversification Approach:◦ Maximize probability of showing an interpretation relevant to the user
◦ Outliers
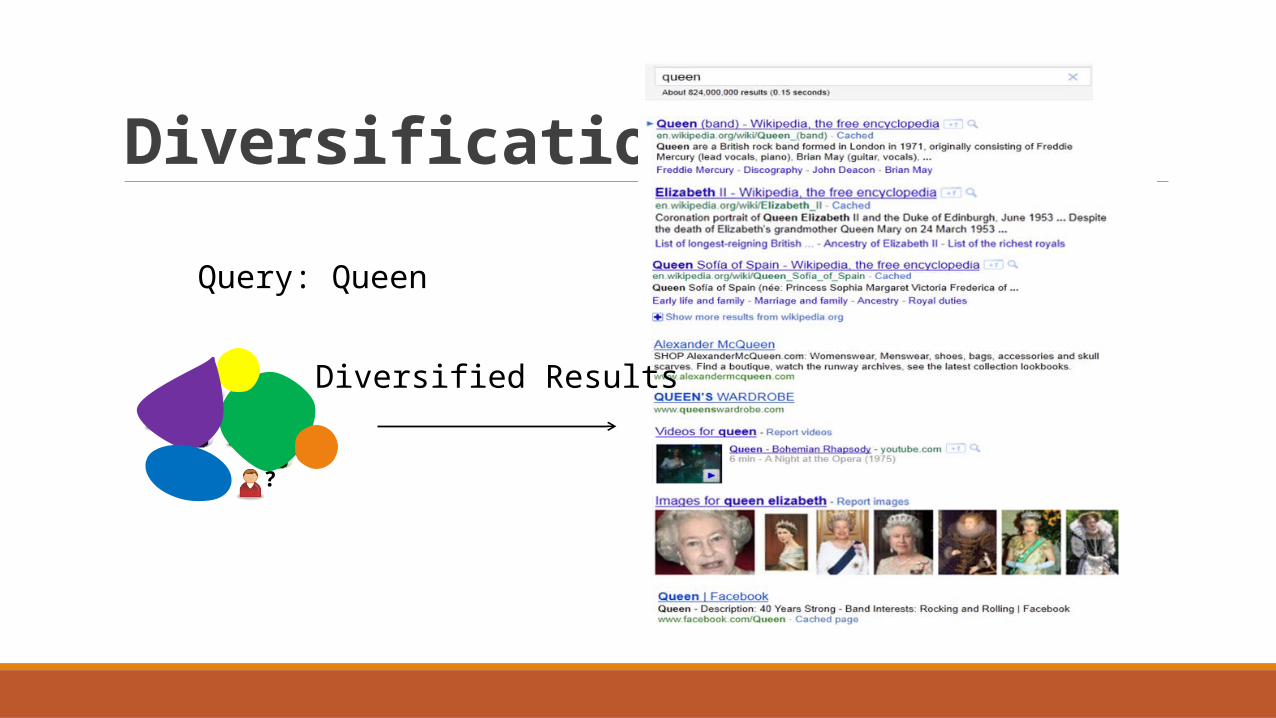
Diversification
?
Diversified Results
Query: Queen

Personalization
User Profile
Query: Queen
Personalized ordering

Overview of PSVMdiv Given a user and a query, predict a diverse set of docs
◦ Formulate a discriminant based on maximizing search result diversification◦ Perform training using the structured support vector machines framework◦ User interest LDA-style topic model
◦ Infer a per-document per-user multinomial distribution over topics and determine whether a document can cater to a specific user
◦ During Training use features extracted from three sources

The Learning Problem
u: documents user u is interested in x : a set of documents• y: candidate documents
• Given a user and a set of documents, select a subset of documents that maximizes search result diversification for the user
• Loss Function:

The Learning Problem• Learn a hypothesis function to predict a y given x and u;• Labeled training data assumed to be available: • To find a function h such that the empirical risk can be minimized;• Let a discriminant compute how well the predicting y fits x
and u. • The hypothesis predicts the y that maximizes F: • Each (x, u, y) is described through a feature vector • The discriminant function is assumed to be linear in the feature space:

Standard SVMs and Additional Constraints
Optimization problem for standard SVMs
Additional constraints:For diversity:
For consistency with user’s interest:
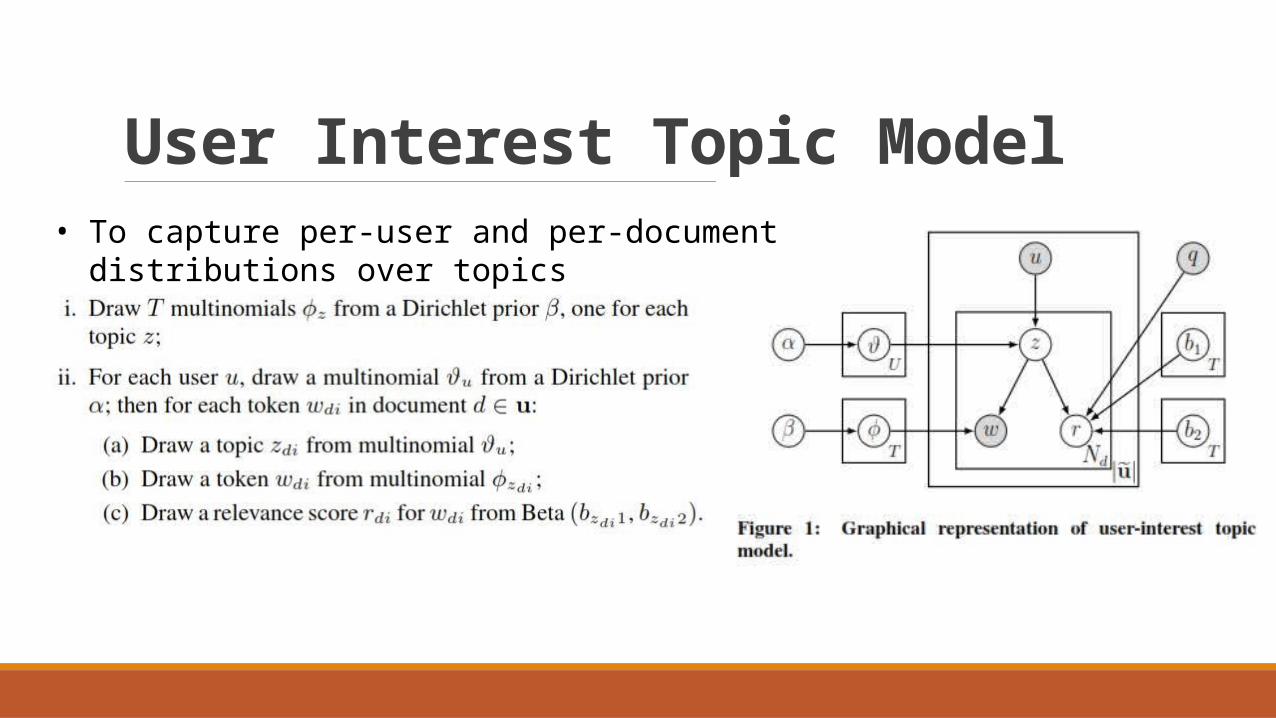
User Interest Topic Model• To capture per-user and per-document distributions over topics

Latent Dirichelet Allocation
α is the Dirichlet prior on the per-document topic distributions,β is the Dirichlet prior on the per-topic word distribution,θi is the topic distribution for document i,ϕk is the word distribution for topic k,Z is the topic for the j th word in document i, andwij is the specific word.

Feature Space Three types:
◦ Extracted directly from tokens’ statistical information in the documents◦ Compute similarity scores between a document x ϵ y and a set of documents u that a user is interested in. Cosine, Euclidean, KL
divergence metrics are considered.
◦ Those generated from proposed user- interest LDA-style topic model◦ Compute similarity scores between a document x ϵ y and a set of documents u based on a multinomial distribution over topics and
the user’s multinomial distribution over topics generated by the User Interest Topic Model. Cosine, Euclidean, KL divergence metrics are considered.
◦ Those utilized by unsupervised personalized diversification algorithms◦ The main probability used in state-of-art unsupervised personalized diversification methods are utilized here as features. Such as
p(d|q), the probability of d relevant to q; p(c|d), the probability of d belonging to a category c, etc.

Dataset A publicly available personalized diversification dataset.
◦ Contains private evaluation information from 35 users on 180 search queries◦ Ambiguous queries, length no more than two keywords◦ 751 subtopics for the queries, with most of the queries having more than 2 subtopics◦ Over 3800 relevance judgments are available, for at least top 5 results for each query◦ Each relevance judgment includes 3 main assessments
◦ 4-grade scale assessment on how relevant the result is to the user’s interest—user relevance◦ 4-grade scale assessment on how relevant the result is to the evaluated query—topic relevance◦ 2-grade assessment whether a subtopic is related to the evaluated query

Baselines PSVMdiv compared to 11 baselines:
◦ Traditional: BM25◦ Plain diversity: IA-select, xQuAD ◦ Plain personalization: PersBM25 ◦ Two step, first div, then pers: xQuADBM25
◦ Pers-diversification: PIA-select, PIA-select BM25 , PxQuAD, PxQuAD BM25
◦ Supervised diversification: SVMdiv, SVMrank

Results & Analysis -Supervised v. Unsupervised

Results & Analysis- Effect of UIT Model

Results & Analysis-Effects of Constraints

Query-Level Analysis

Conclusion Pro:
◦ User Interest Topic Model Con:
◦ Evaluated on a single, small dataset

Thank you!
Questions?







