

Programming Trends in
High Performance Computing
2016
Juris Vencels
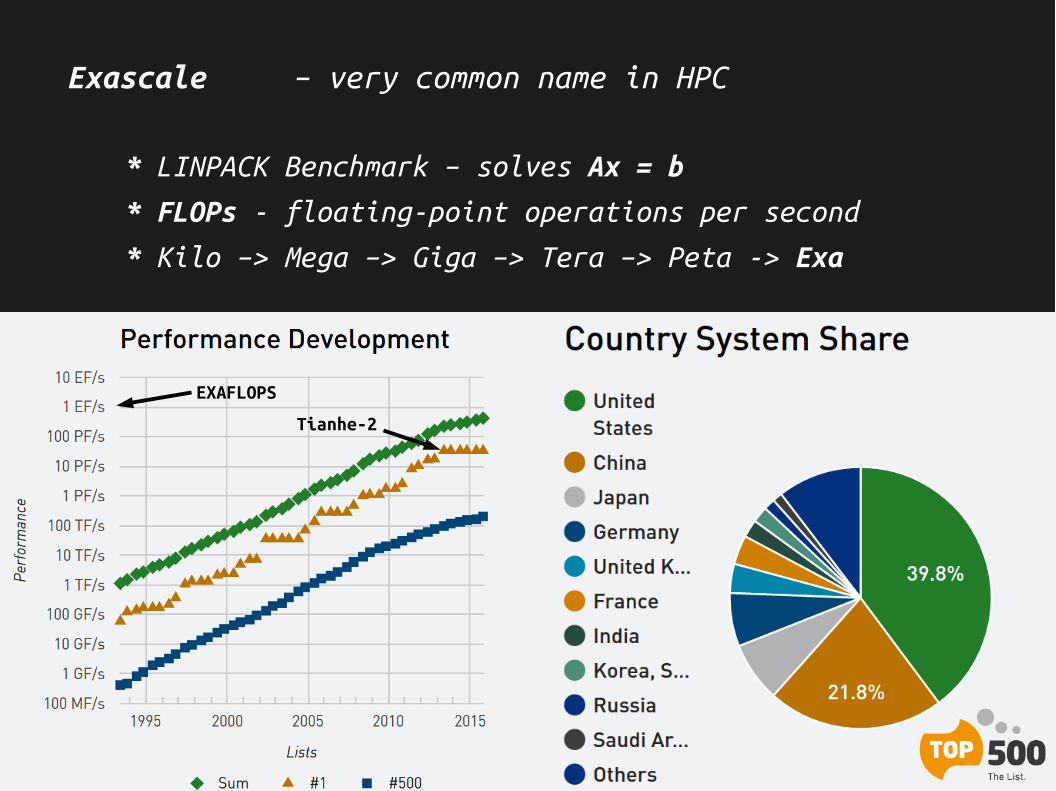
* Tianhe-2 (China) fastest in the world since June 2013

2
About Me
B.Sc - Physics @ University of Latvia
* Modeling of plasma processes in magnetron sputtering systems (Sidrabe, Inc.)
M.Sc - Electrophysics @ KTH (Sweden)
* Research engineer at EPiGRAM project (PDC Center for High Performance Comp.)
Intern @ Los Alamos National Lab (USA)
* Development of spectral codes for plasma physics problems (instabilities, turbulence)
3
* LINPACK Benchmark – solves Ax = b
* FLOPs - floating-point operations per second
* Kilo –> Mega –> Giga –> Tera –> Peta -> Exa
Exascale – very common name in HPC
EXAFLOPS
Tianhe-2

4
CPUs: Intel Xeon E5-2692v2 12C 2.2GHz
Accelerators: Intel Xeon Phi 31S1P 57C 1.1GHz
32’000 x
48’000 x
3’120’000 cores
Linpack: 34 PFLOPS
Theoretical: 55 PFLOPS
17.6 MW (24 MW with cooling)
US$390 million
Tianhe-2
- heterogeneous
* CPUs - few fast cores * Accelerators – many slow cores
- Accelerators outperform CPUs in
* FLOPs/$ * FLOPs/Watts
Future of HPC – heterogeneous hardware

5
Exascale ProGRAmming Models
www.epigram-project.eu
Extrapolation of current technology to Exascale would result in
* Codes that do not scale efficiently * Large risk of hardware failure * High power consumption * Expensive hardware
The project mostly aims to solve the 1st problem

6
EPiGRAM project
- Test experimental programming models in practice
- IPIC3D for plasma physics * implicit Particle-In-Cell, fully electromagnetic * magnetic reconnection, magnetosphere, instabilities * C++, MPI+OpenMP
- Nek5000 for incompressible fluids * spectral elements * fluid-dynamics in fission nuclear reactor * Fortran, MPI

7
Existing parallel programming APIs
Widely used
* MPI - Message Passing Interface
* OpenMP - Open Multi-Processing
* CUDA - programming interface for NVIDIA GPUs
Application dependent or experimental
* GPI-2 - Partitioned Global Address Space
* OpenACC - Open Accelerators
* OpenCL, Coarray Fortran, Chapel, Cilk, TBB, ...

8
MPI - Message Passing Interface
- Distributed memory model
- MPI 3.x provides some shared memory mechanisms
Implementations
* free: MPICH, Open MPI, ...
* prop: Intel, Cray, ...
9
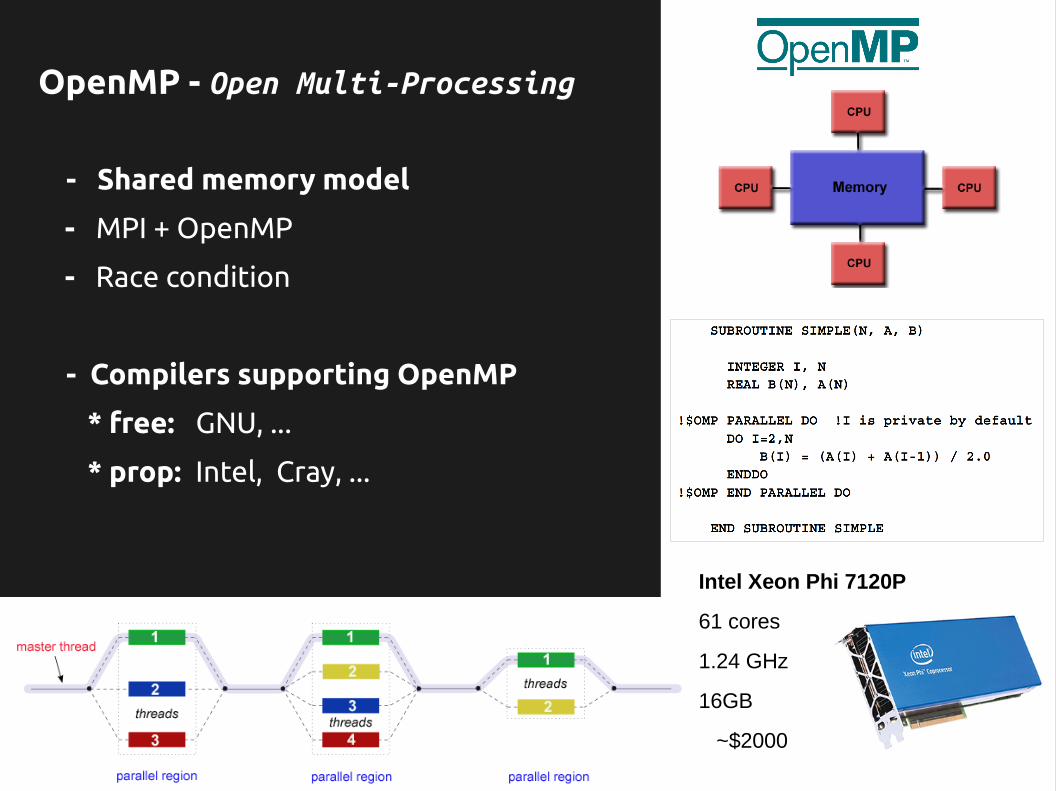
OpenMP - Open Multi-Processing
- Shared memory model
- MPI + OpenMP
- Race condition
- Compilers supporting OpenMP
* free: GNU, ...
* prop: Intel, Cray, ...
Intel Xeon Phi 7120P
61 cores
1.24 GHz
16GB
~$2000
10
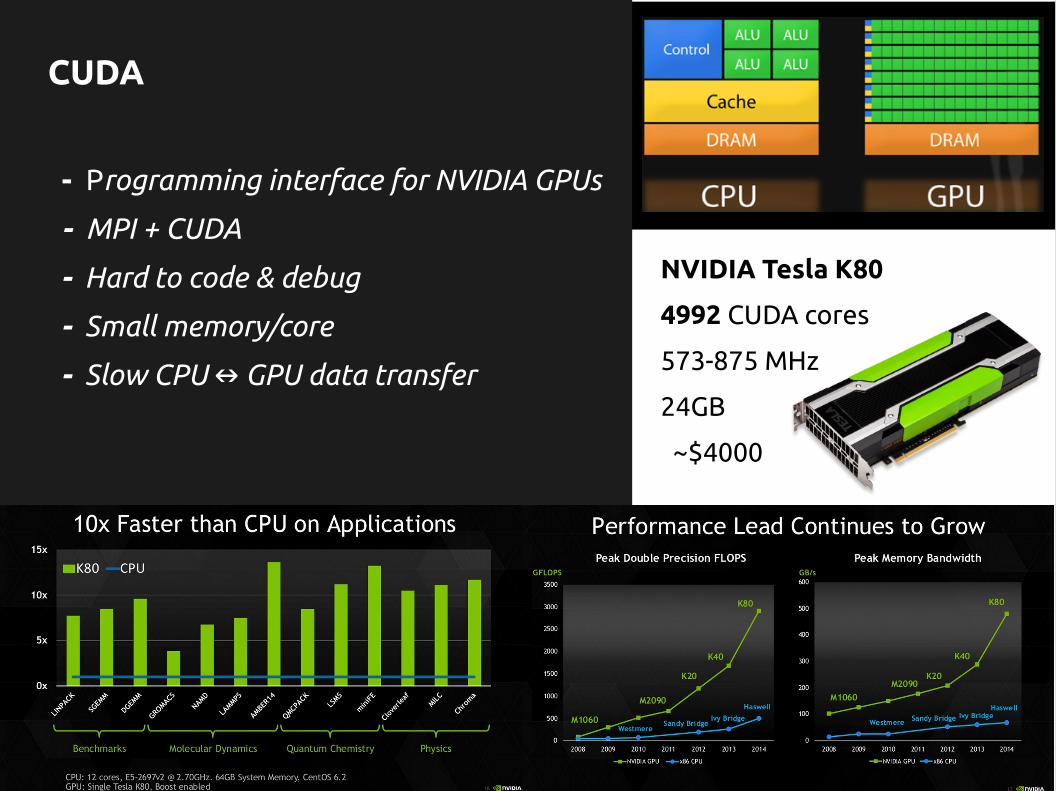
CUDA
- Programming interface for NVIDIA GPUs
- MPI + CUDA
- Hard to code & debug
- Small memory/core
- Slow CPU GPU data transfer↔
NVIDIA Tesla K80
4992 CUDA cores
573-875 MHz
24GB
~$4000

11
PGAS - Partitioned Global Address Space
- Abstract shared address space
- Standards: GASPI, Coarray Fortran, Chapel, …
EPiGRAM focused on GASPI implementation GPI-2 from
* scalable, asynchronous, fault tolerant
* proprietary €
6 24 96 384 15360.00
1.00
2.00
3.00
4.00
5.00
6.00
iPIC3D particle communication time (s)
GPI2
MPI
# of cores

12
One sided communication
MPI vs GASPI

13
OpenACC - Open Accelerators
- Compiler directives (pragmas) for CPU+GPU systems
- Higher level than CUDA, easier to use
- Similar to OpenMP
- Compilers:
* free: OpenUH
* prop: PGI, Cray, CAPS
14
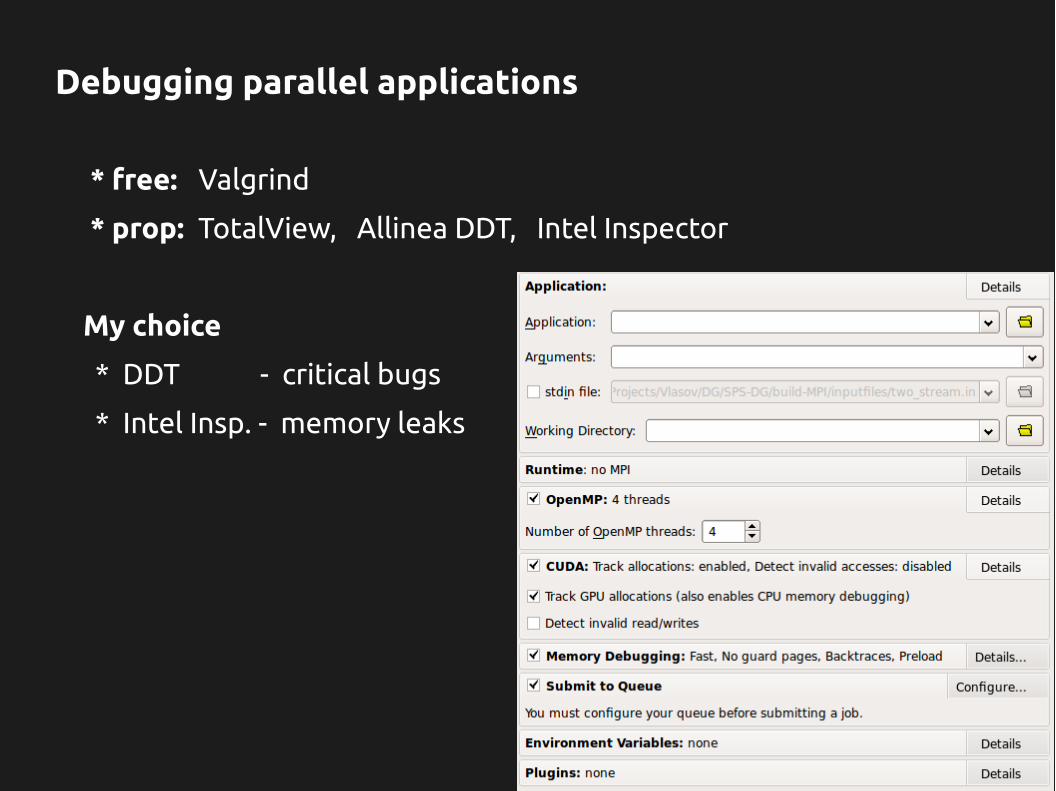
Debugging parallel applications
* free: Valgrind
* prop: TotalView, Allinea DDT, Intel Inspector
My choice
* DDT - critical bugs
* Intel Insp. - memory leaks

15
Profiling parallel applications
* free: Valgrind
* prop: Allinea MAP, Intel Vtune, Vampir
My choice: Allinea MAP – simply compile the code with ‘-g’ option and run

16
Conclusions
- HPC is moving towards heterogeneous hardware
- Future codes will exploit high degree of parallelism
- Petascale computer in 2008, Exascale in ~2020
- Most likely MPI will be present in Exascale (MPI+x)
- Tolerance to hardware failures
- Power consumption must be below 20MW
Thank you! Questions?







