

DATA FUSIONResolving Inconsistencies at Schema, Tuple
and Value Level
Naveen RajamoorthyNachiappan Chidambaram
Arunkarthikeyan PalaniswamySriramakrishnan Soundarrajan

To compare different Data Sets
Example:
Shopping Agents
Disaster Management System
Need for Data Fusion

3
Completeness - amount of data (number of attributes and tuples) - achieved by adding more data sources
Conciseness - number of unique objects - number of unique attributes of the objects - achieved by reducing schematic inconsistencies by schema mapping
Correctness - validity of data - achieved by performing duplicate detection and data fusion
GOALS OF DATA INTEGRATION
Data Sources
Schema Mapping
Duplicate Detection
Data Fusion

Fusing data from heterogeneous sources.
All Steps are performed at run-time.
Data Cleaning
Maximum Flexibility
Humboldt Merger(HumMer)

Heterogeneous and Dirty data
Three Steps
1. Schema Matching and Data Transformation
2. Duplicate Detection
3. Data Fusion
Components of Data Fusion

Three Steps in Data Fusion
Resolve inconsistencies at schema level
Resolve inconsistencies at tuple level
Resolve inconsistencies at value level

7
Schema Matching and Data Transformation

Process of resolving schematic heterogeneity.
1. DUMAS Schema Matching Algorithm (Duplicate-based Matching of Schemas )
2. TF IDF Similarity (term frequency–inverse document frequency)
Schema Matching
R A B C D E
R1 John Doe M (408)7573339 (408)7573338
R2 Joe Smith M (249)3615616 (249)2342366
R3 Suzy Klein F (358)2436321 (358)2436321
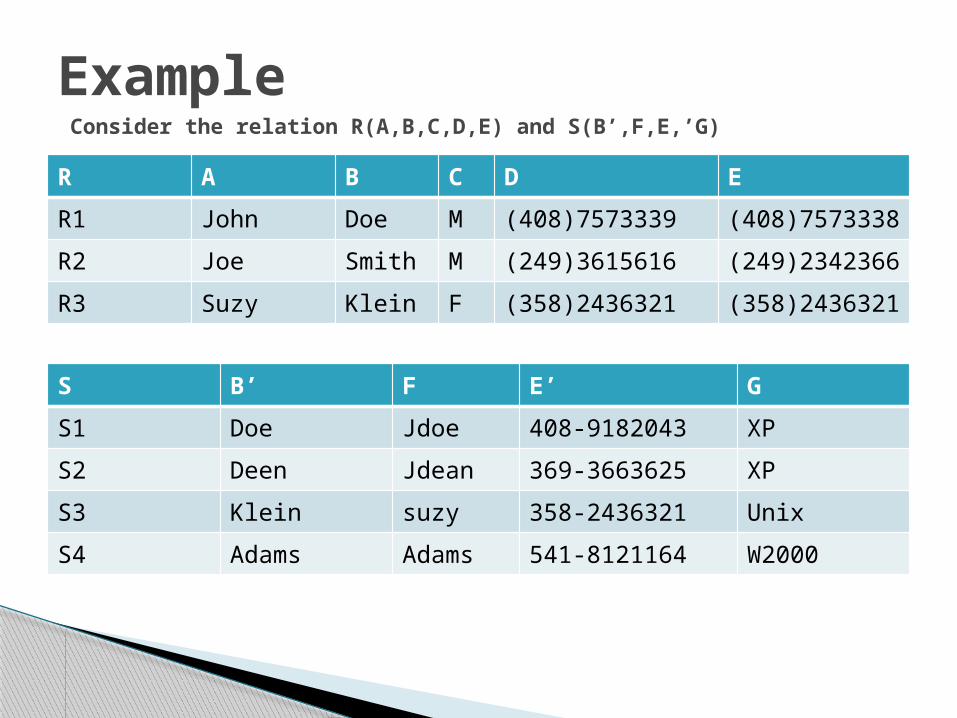
Example Consider the relation R(A,B,C,D,E) and S(B’,F,E,’G)
S B’ F E’ G
S1 Doe Jdoe 408-9182043 XP
S2 Deen Jdean 369-3663625 XP
S3 Klein suzy 358-2436321 Unix
S4 Adams Adams 541-8121164 W2000

ExampleConsider the relation R(A,B,C,D,E) and S(B’,F,E,’G)
R A B C D E
R1 John Doe M (408)7573339 (408)7573338
R2 Joe Smith M (249)3615616 (249)2342366
R3 Suzy Klein F (358)2436321 (358)2436321
R4 Sam Adams M (541)8127100 (541)8121164
S B’ F E’ G
S1 Doe Jdoe 408-9182043 XP
S2 Deen Jdean 369-3663625 XP
S3 Klein suzy 358-2436321 Unix
S4 Adams Adams 541-8121164 W2000
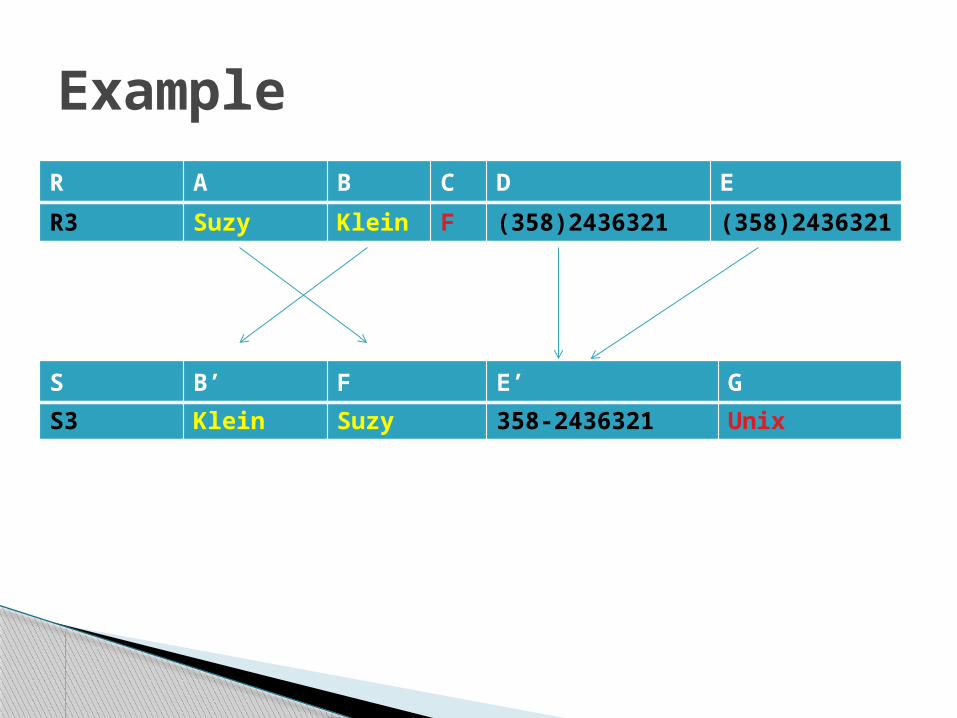
R3 Suzy Klein F (358)2436321 (358)2436321
Example
S3 Klein Suzy 358-2436321 Unix
R A B C D E
S B’ F E’ G

ExampleR A B C D E
R1 John Doe M (408)7573339 (408)7573338
R2 Joe Smith M (249)3615616 (249)2342366
R3 Suzy Klein F (358)2436321 (358)2436321
R4 Sam Adams M (541)8127100 (541)8121164
S B’ F E’ G
S1 Doe Jdoe 408-9182043 XP
S2 Deen Jdean 369-3663625 XP
S3 Klein suzy 358-2436321 Unix
S4 Adams Adams 541-8121164 W2000

Overlap of R and S schema
Schema Matching
Attributes in R Attributes in S
A ----
B B’
C ----
D ----
E E’
---- F
---- G

Preferred schema
Names of attributes are renamed or determined.
sourceID attribute is added to all tables in the schema.
Transformation

15
Duplicate Detection
16
Source A
Source B
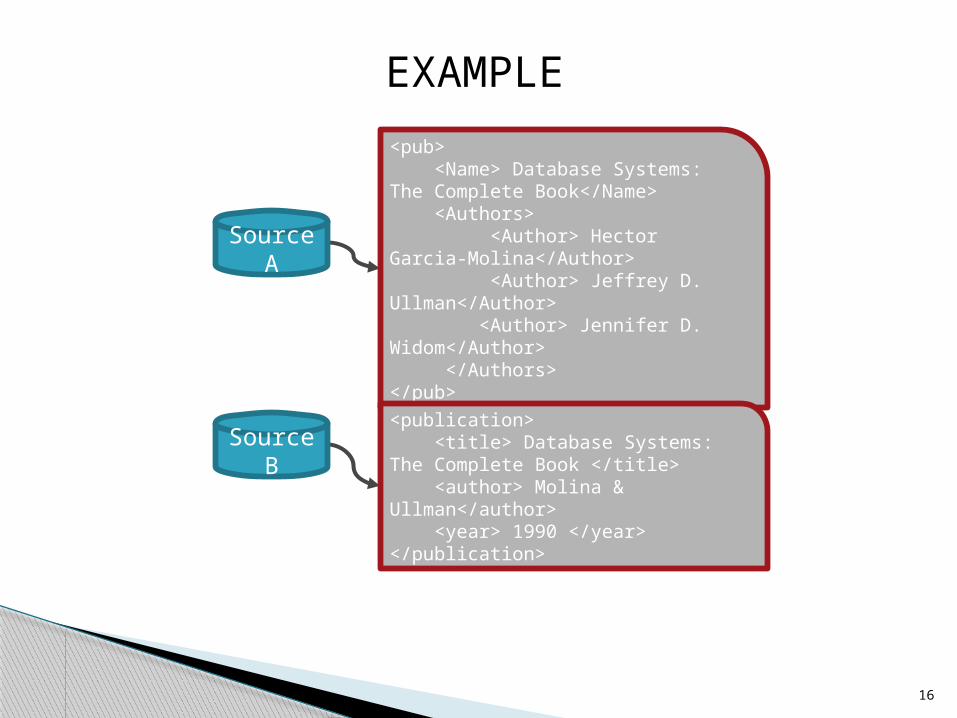
<pub> <Name> Database Systems: The Complete Book</Name> <Authors> <Author> Hector Garcia-Molina</Author> <Author> Jeffrey D. Ullman</Author> <Author> Jennifer D. Widom</Author> </Authors></pub>
<publication> <title> Database Systems: The Complete Book </title> <author> Molina & Ullman</author> <year> 1990 </year></publication>
EXAMPLE

17
<pub> <Name> Database Systems: The Complete Book</Name> <Authors> <Author> Hector Garcia-Molina</Author> <Author> Jeffrey D. Ullman</Author> <Author> Jennifer D. Widom</Author> </Authors></pub>
<publication> <title> Database Systems: The Complete Book </title> <Author> Molina & Ullman</Author> <year> 1990 </year></publication>
SCHEMA MAPPING
Source A
Source B
<pub> <title> </title> <Authors> <author> </author> <author> </author> </Authors> <year> </year></pub>
18
<pub> <title> Database Systems: The Complete Book</title> <Author> Hector Garcia-Molina</Author> <Author> Jeffrey D. Ullman</Author> <Author> Jennifer D. Widom</Author><year> 1990 </year>
</pub>
<pub> <title> Database Systems: The Complete Book </title> <Authors> <Author> Hector Garcia-Molina</Author> <Author> Jeffrey D. Ullman</Author> <Author> Jennifer D. Widom</Author> </Authors></pub><pub> <title> Database Systems: The Complete Book</title> <Author> Hector Garcia-Molina</Author> <Author> Jeffrey D. Ullman</Author> <Author> Jennifer D. Widom</Author> <year> 1990 </year></pub>
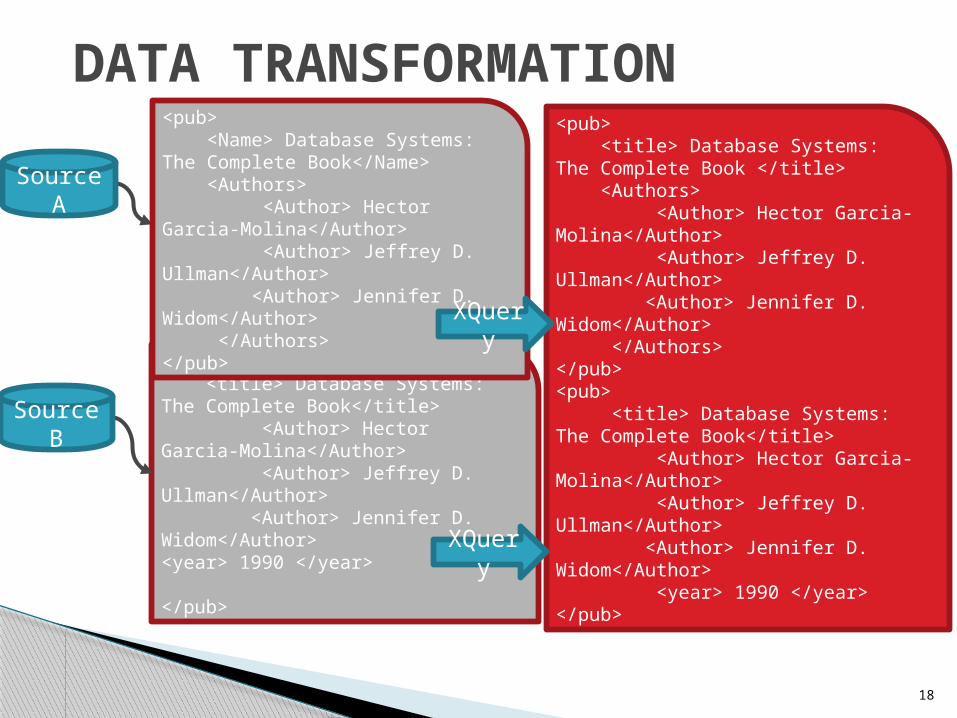
DATA TRANSFORMATION
Source A
Source B
XQuery
<pub> <Name> Database Systems: The Complete Book</Name> <Authors> <Author> Hector Garcia-Molina</Author> <Author> Jeffrey D. Ullman</Author> <Author> Jennifer D. Widom</Author> </Authors></pub>
XQuery

19
DUPLICATE DETECTION AND FUSION<pub> <title> Database Systems: The Complete Book </title> <Authors> <Author> Hector Garcia-Molina</Author> <Author> Jeffrey D. Ullman</Author> <Author> Jennifer D. Widom</Author> </Authors></pub><pub> <title> Database Systems: The Complete Book</title> <Author> Hector Garcia-Molina</Author> <Author> Jeffrey D. Ullman</Author> <Author> Jennifer D. Widom</Author> <year> 1990 </year></pub>
<pub> <title> Database Systems: The Complete Book </title> <Authors> <Author> Hector Garcia-Molina</Author> <Author> Jeffrey D. Ullman</Author> <Author> Jennifer D. Widom</Author> </Authors> <year> 1990 </year></pub>

20
Give the correct order in which integration needs to be carried out:
A) Data Transformation -> Schema Mapping -> Duplicate detection ->Fusion
B) Duplicate detection -> Data Transformation -> Schema Mapping -> Fusion
C)Schema Mapping -> Data Transformation -> Duplicate detection ->Fusion
D) Data Transformation -> Schema Mapping -> Fusion -> Duplicate detection
QUESTION

21
Problem◦ Given one or more data sets, find all sets of
objects that represent the same real-world entity. Difficulties
◦ Duplicates are not identical Similarity measures – Levenshtein, Jaccard, etc.
◦ Large volume, cannot compare all pairs Partitioning strategies – Sorted neighborhood,
Blocking, etc.
Duplicate Detection

22
General Strategy Sorted Neighborhood Method
PARTITIONING STRATEGIES

23
Compare each record with every other record and calculate distance measure. Assuming there are n records in database then we need to compute n(n-1)/2 distance measures.
GENERAL STRATEGY
X Y Z
Star Wars Lucas 1985
Indiana Jones
Lucas 1989
Home Alone
Wright 1991
Starwars George Lucas
1985
Shrek Adamson
2001
Snatch Ritcie 1999
Number of records, n = 6Number of Distance measures to be computed = 10
If there are say, 100000 records,Then, Number of Distance Measures tobe computed = 5*10^8 calculations
EXPENSIVE

24
Using Sorted Neighborhood method we can reduce the number of potential duplicate pairs.
Different fields are identified as key. The database is sorted using this key. After sorting a window of fixed size slides over
the sorted database and duplicate records are identified.
The technique generates O(wN) pairs where w is window size and N is the total number of records in database.
SORTED NEIGHBORHOOD METHOD

25
DUPLICATE DETECTION WITH DESCRIPTIONS
Criteria For Attribute Selection:
Attributes that are:
(i) related to the currently considered objectChild elements having a Foreign key constraint over the attributes of the parent table.
(ii) useable by our similarity measureAttribute City corresponding to attribute Zip code cannot be used to calculate similarity measure
(iii) likely to distinguish duplicates from non-duplicates.Attribute for Denomination is unlikely to distinguish duplicate records

26
Description: Consider attributes from other tables that have a foreign key
relationship with the existing tables. For efficiency, only direct child attributes are considered, i.e. no
descendants reached by following more than one reference are discarded.
DUPLICATE DETECTION WITH DESCRIPTIONS
Movie
Title
Year
Duration
Film
Name
Date
Rating
Actor
Name
Movie
Actress
Name
Movie
Actors
Name
Film
Prod-Com
Name
Film
Let tables T1 and T2 be the two matched tables, and let {T1,1, . . . , T1,k} and {T2,1, . . . , T2,m} be their respective children tables.
Then, every pair of tables (T1,i, T2,j), 1<=i<=k, i<=j<=mis matched.
Thus Actor(Movie),Actress(Movie) and Actors(Film) can also be used for Duplicate Detection

27
Example
ID Country
1 USA
2 United States
3 US
ID City Country ID
1 Charlotte 1
2 California 1
3 Charlotte 2
4 California 2
5 Charlotte 3
6 California 3Table 1
Table 2ID in Table 1 is a foreign key for Country ID in Table 2
From Sim(Country) in Table 1 we understand row 1 and 3 are duplicates (row 1 = row 3)
Now on using the attribute City in child table, Table 2 for Duplicate Detection we cometo the conclusion that row 1 = row 2 = row 3 in table 1.i.e: USA = United States = US

28
Detection From Similarity Measure
Source 1
Source 2
Source1 x Source2
PartitioningSimilarity measure
Sure Duplicat
es
Non-Duplicat
es
Possibile Duplicat
es
sim < θ1
sim > θ 2
θ1>sim<θ2

29
ObjectiveGiven a duplicate, create a single object-representation while resolving conflicting data values.
Simple Example:
Data Fusion
Source 1
Source 2
98765432
R.J.Ludlum 3.50
Year
98765432
Trevayne
Robert Ludlum
4.00
Month
IDMax_length(author)
Min(price)
Concat(Month,Year)

30
Uncertainty
Conflict between a non-null value and one or more null values that are all used to describe the same property of a real-world entity
Causes:Missing information, such as null values in a source or a completely missing attribute in a source
Contradiction
It is a conflict between two or more different non-null values that are all used to describe the same property of the same entity.
Causes:Contradiction is caused by different sources providing different values for the same attribute of a real-world entity.
TYPES OF DATA CONFLICTUncertainty
NULL value vs. non-NULL value“Easy” case
ContradictionNon-NULL value vs. (different) non-NULL value
Title Year Director
Source
Snatch
2000 Ritchie S1
Snatch
2000 null S2
Title Year Director
Source
Snatch
2000 Ritchie S1
Snatch
2000 Benaud S2

31
unknown◦ There is a value, but I do not know it.◦ E.g.: Unknown date-of-birth
not applicable◦ There is no meaningful value.◦ E.g.: Spouse for singles
withheld◦ There is a value, but we are not authorized to see
it.◦ E.g.: Private phone line
NULL TYPES

32
________ refers to “Conflict between a non-null value and one or more null values that are all used to describe the same property of a real-world entity”
A. Contradiction B. Uncertainty C. Resolution D. Ignorance
Question

33
Classification of Functions
conflictignorance
conflictavoidance
conflictresolution
conflict resolutionstrategies
instancebased
instancebased
metadatabased
metadatabased
decidingmediating deciding mediating
CoalesceChooseDepending
Concat
AVG, SUMMIN, MAXRandom
Vote
Choose
MostRecentMostAbstractMostSpecific
Escalate
CommonAncestor

34
Function Description Examples
Min, Max, Sum, Count, Avg
Standard aggregation NumChildren, Salary, Height
Random Random choice Shoe size
Longest, Shortest Longest/shortest value First_name
Choose(source) Value from a particular source DoB (DMV), CEO (SEC)
ChooseDepending(val, col)
Value depends on value chosen in other column
city & zip, e-mail & employer
Vote Majority decision Rating
Coalesce First non-null value First_name
Group, Concat Group or concatenate all values Book_reviews
MostRecent Most recent (up-to-date) value Address
MostAbstract, MostSpecific, CommonAncestor
Use a taxonomy / ontology Location
Escalate Export conflicting values gender
Conflict Resolution Functions

35
Data Fusion Goals
a, b, c a, b, c, d
Assume 2 sources, Source 1(A,B,C) and Source 2(A,B,D)
a, b, d
a, b, c, -
a, b, -, d
a, b, - a, b, -, -
a, b, -
a, b, -, -
a, b, -, -
a, b, c a, f(b,e), c, d
a, e, d
a, b, c, -
a, e, -, d
a, b, c a, b, c, -
a, b, -
a, b, c, -
a, b, -, -
Identical tuples
Subsumed tuples
Conflicting tuples
Complementing tuples

36
Identical tuples (duplicates)UNION, OUTER UNION
Subsumed tuples (uncertainty)MINIMUM UNION
Complementing tuples (uncertainty)COMPLEMENT UNION, MERGE
Conflicting tuples (contradiction)MATCH, GROUP, FUSE
Relational Operators – Overview
37
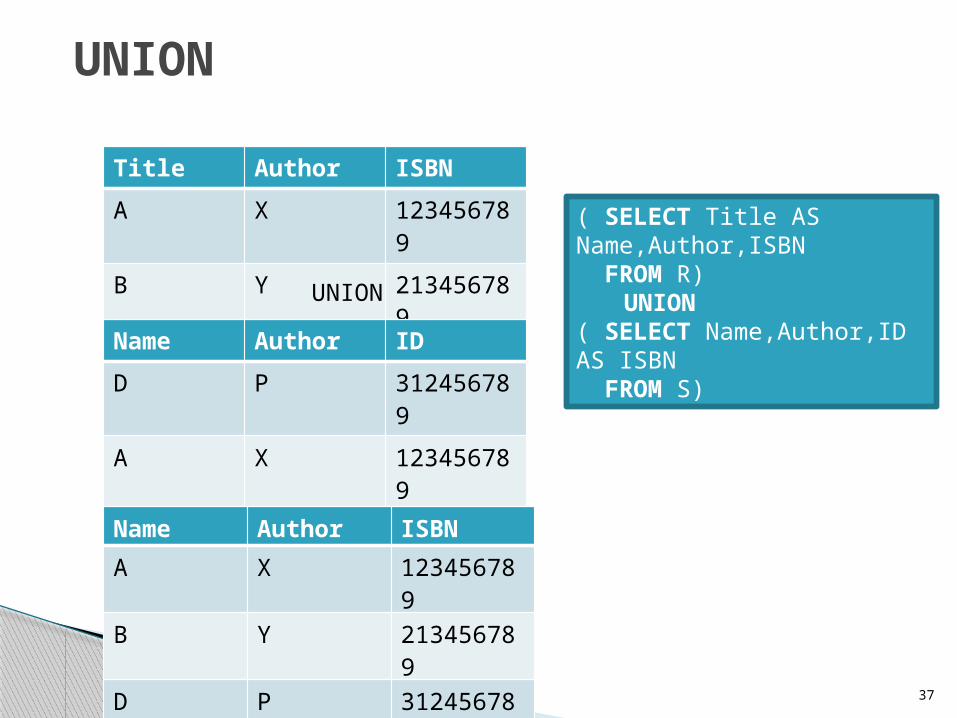
UNION
Title Author ISBN
A X 123456789
B Y 213456789
Name Author ID
D P 312456789
A X 123456789
B Y 213456789
UNION
Name Author ISBN
A X 123456789
B Y 213456789
D P 312456789
( SELECT Title AS Name,Author,ISBN FROM R)
UNION( SELECT Name,Author,ID AS ISBN FROM S)

38
MINIMUM UNION
A B C
a b c
e f g
m n o
A B D
a b
e f h
m p
+ =
A tuple t1 subsumes a tuple t2, if it has same schema, has less NULL-values, and coincides in all non-NULL-values.
A B C D
a b c
e f g
e f h
m n o
m p
A B C D
a b c
a b
e f g
e f h
m n o
m p
Select A,B,C,D AS NULL FROM RUNION ALLSELECT A,B, C AS NULL,D FROM S
39
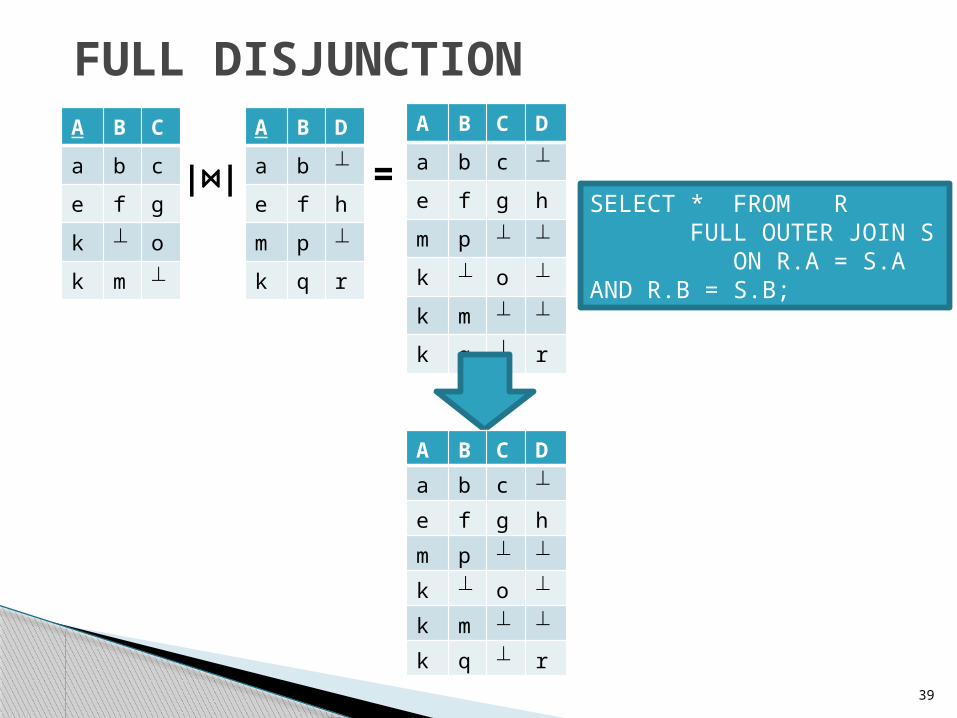
FULL DISJUNCTIONA B C
a b c
e f g
k o
k m
A B D
a b
e f h
m p
k q r
A B C D
a b c
e f g h
m p
k o
k m
k q r
|⋈| =
A B C D
a b c
e f g h
m p
k o
k m
k q r
SELECT * FROM R FULL OUTER JOIN S ON R.A = S.A AND R.B = S.B;

40
A B C
a b c
e f g
m n o
m n
q r s
A B D
a b
e f h
m p |⋈
A B C
a b c
e f g
m n o
m n
q r s
A B D
a b
e f h
m p ⋈|
A B C D
a COAL(b,b)
c
e COAL(f,f)
g h
m COAL(n,p)
o
m COAL(n,p)
q r s
A B C D
a COAL(b,b)
c
e COAL(f,f)
g h
m COAL(p,n)
o
m COAL(p,n)
A B C D
a b c
e f g h
m n o
m n
q r s
=
=
=
=
A B C D
a b c
e f g h
m p o
m p
MERGE AND PRIORITIZED MERGESELECT * FROM R FULL OUTER JOIN S ON R.A = S.A AND R.B = S.B;

41
SELECT Name, RESOLVE(Age, max), RESOLVE(Address,choose(EE_Students))FUSE FROM EE_Students,CS_StudentsFUSE BY (Name)
FUSE BYName Age Addre
ss
Ram 20 ABCD
Rajesh 21 EFGH
Name Age Address
Ram 23 ABCD
Rajesh 20 PQRS
RESULT
Name Age Address
Ram 23 ABCD
Rajesh 21 PQRS

42
SELECT ID,RESOLVE(Title,
Choose(IMDB)), RESOLVE(Year, Max),
RESOLVE(Director,Concat),RESOLVE(Rating),
FUSE FROM IMDB, FilmdienstFUSE BY (ID) ON ORDER Year DESC
ID Title Year Director
Rating
1101 A 1975 Michael
Null
1102 B 1987 John 5
1103 C 1999 Mark NullID Title Year Director
Rating
1101 C 1976 King 4
1102 B 1983 Davis Null
1103 D 1997 Anthony
2
IMDB
FILMBUFF
ID Title Year Director
Rating
1103
C 1999
Mark Anthony
2
1102
B 1987
John Davis
5
1101
A 1976
Mark Anthony
4
RESULT
FUSE BY

43
Question
a, b, c, -
a, b, -, d
a, b, -, -
a, b, -, -
a, b, c, -
a, e, -, d
a, b, c, -
a, b, -, -
Identical tuples
Subsumed tuples
Conflicting tuples
Complementing tuples
Match The Following
1 a
2
3
4
b
c
d
44
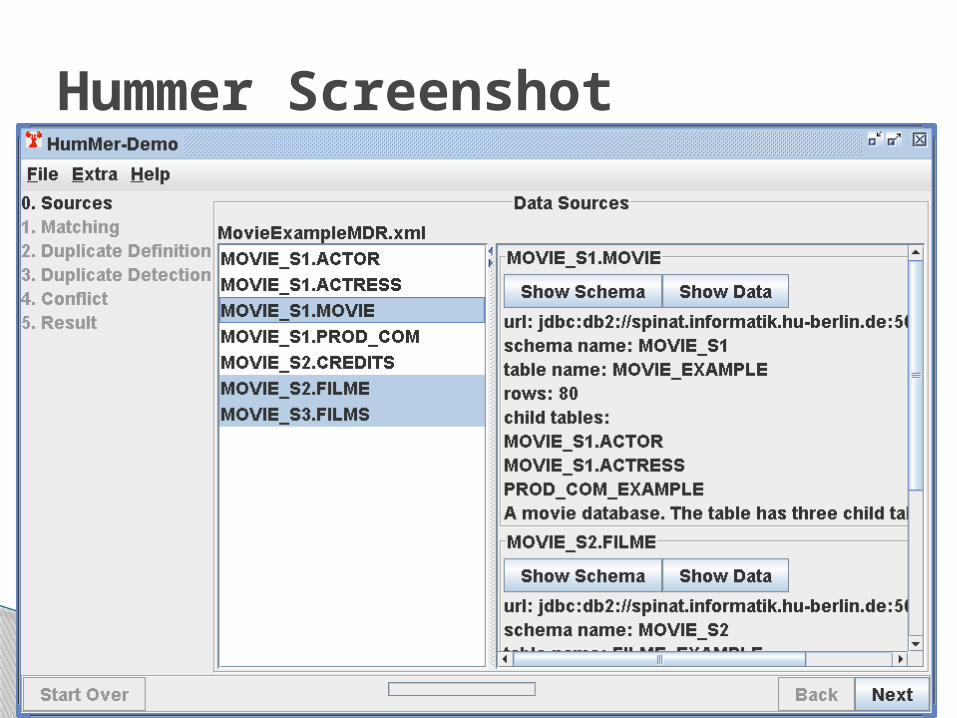
Hummer Screenshot
45
Hummer Screenshot
46
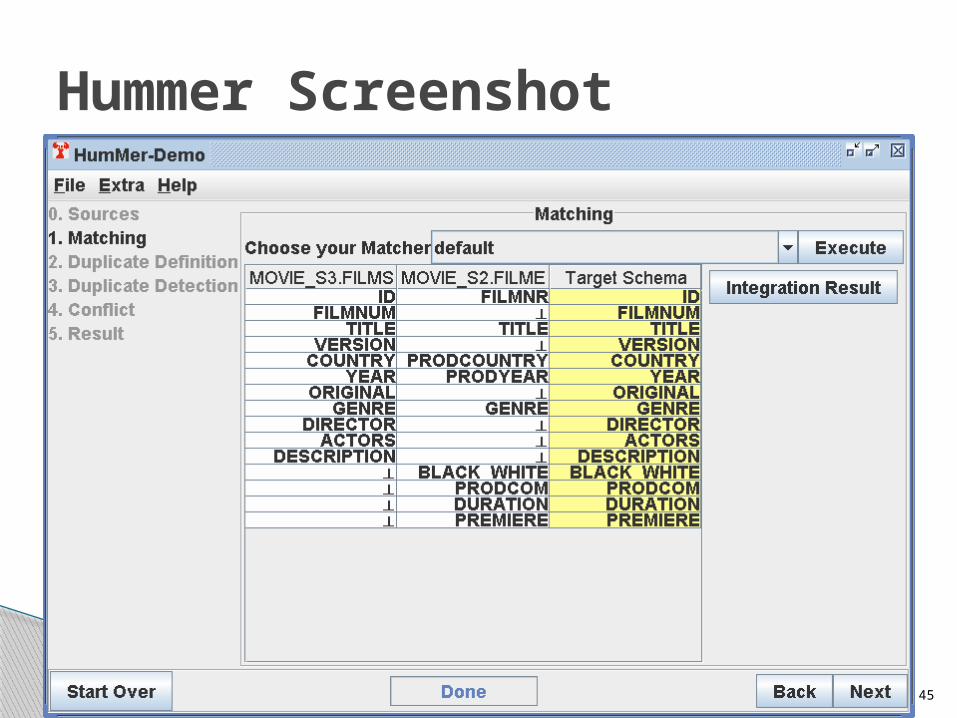
Hummer Screenshot

47
Hummer Screenshot

48
http://coitweb.uncc.edu/~wwu18/itcs6010/presentation/fusion_vldb.pdf
http://vldb.idi.ntnu.no/program/slides/demo/s1251-bilke.pdf
http://coitweb.uncc.edu/~wwu18/itcs6010/presentation/fusion-3step.pdf
http://www.hpi.uni-potsdam.de/fileadmin/hpi/FG_Naumann/publications/Modena05.pdf
http://vldb2009.org/files/DataFusionFinal.pdf http://disi.unitn.it/~p2p/RelatedWork/
Matching/dublicatesICDE05.pdf
REFERENCES







