

Size Matters: Space/Time Tradeoffs to Improve GPGPU Application Performance
Abdullah Gharaibeh Matei Ripeanu
NetSysLabThe University of British Columbia

2
GPUs offer different characteristics
High peak compute power
High communication overhead
High peak memory bandwidth
Limited memory space
Implication: careful tradeoff analysis is needed when porting applications to GPU-based platforms

3
Motivating Question: How should we design applications to efficiently exploit GPU characteristics?
Context: A bioinformatics problem: Sequence Alignment
A string matching problem Data intensive (102 GB)
4
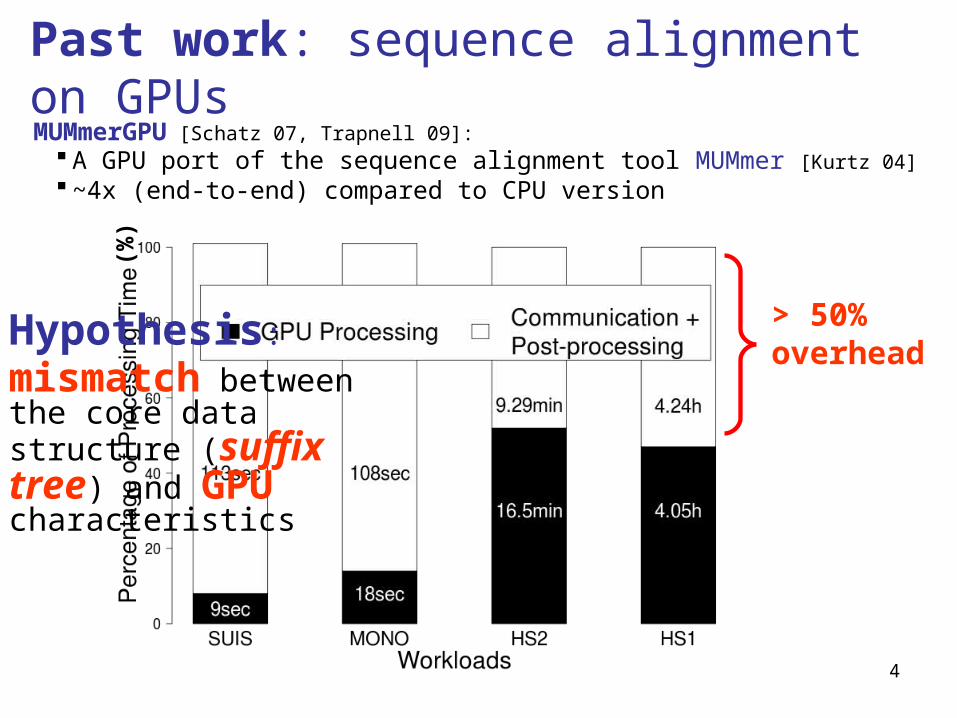
Past work: sequence alignment on GPUsMUMmerGPU [Schatz 07, Trapnell 09]:
A GPU port of the sequence alignment tool MUMmer [Kurtz 04] ~4x (end-to-end) compared to CPU version
Hypothesis:
mismatch between the core data structure (suffix tree) and GPU characteristics
> 50% overhead
(%)

5
Use a space efficient data structure (though, from higher computational complexity class): suffix array
4x speedup compared to suffix tree-based on GPU
Idea: trade-off time for space
Consequences: Opportunity to exploit
multi-GPU systems as I/O is less of a bottleneck
Focus is shifted towards optimizing the compute stage
Significant overhead reduction

6
Outline
Sequence alignment: background and offloading to GPU
Space/Time trade-off analysis
Evaluation

7
CCAT GGCT... .....CGCCCTA GCAATTT.... ...GCGG ...TAGGC TGCGC... ...CGGCA... ...GGCG ...GGCTA ATGCG… .…TCGG... TTTGCGG…. ...TAGG ...ATAT… .…CCTA... CAATT….
..CCATAGGCTATATGCGCCCTATCGGCAATTTGCGGCG..
Background: sequence alignment problem
Find where each query most likely originated from
Queries 108 queries101 to 102 symbols length per query
Reference106 to 1011 symbols length
Queries
Reference

8
GPU Offloading: opportunity and challenges
Sequence alignment
Easy to partition Memory intensive
GPU
Massively parallel High memory bandwidth
Op
po
rtu
nit
y
Data Intensive Large output size
Limited memory space No direct access to
other I/O devices (e.g., disk)C
hal
len
ges

9
GPU Offloading: addressing the challenges
subrefs = DivideRef(ref) subqrysets = DivideQrys(qrys)foreach subqryset in subqrysets { results = NULL CopyToGPU(subqryset) foreach subref in subrefs { CopyToGPU(subref) MatchKernel(subqryset,
subref) CopyFromGPU(results) } Decompress(results)}
• Data intensive problem and limited memory space
→divide and compute in rounds
• Large output size→compressed output
representation (decompress on the CPU)
High-level algorithm (executed on the host)

10
Space/Time Trade-off AnalysisSpace/Time Trade-off Analysis

11
The core data structure
massive number of queries and long reference => pre-process reference to an index
$
CAA TACACA$
0
5
CA$
2 4
CA$ $
3 1
$ CA$
Past work: build a suffix tree (MUMmerGPU [Schatz 07, 09])
Search: O(qry_len) per query
Space: O(ref_len), but the constant is high: ~20xref_len
Post-processing: O(4qry_len - min_match_len), DFS traversal per query

12
The core data structure
massive number of queries and long reference => pre-process reference to an index
Past work: build a suffix tree (MUMmerGPU [Schatz 07])
Search: O(qry_len) per query
Space: O(ref_len), but the constant is high: ~20xref_len
Post-processing: O(4qry_len - min_match_len), DFS traversal per query
subrefs = DivideRef(ref) subqrysets = DivideQrys(qrys)foreach subqryset in subqrysets { results = NULL CopyToGPU(subqryset) foreach subref in subrefs { CopyToGPU(subref)
MatchKernel(subqryset, subref) CopyFromGPU(results) } Decompress(results)}
Expensive
Expensive
Efficient

13
A better matching data structure
$
CAA TACACA$
0
5
CA$
2 4
CA$ $
3 1
$ CA$
Suffix Tree
0 A$
1 ACA$
2 ACACA$
3 CA$
4 CACA$
5 TACACA$
Suffix Array
Space O(ref_len), 20 x ref_len O(ref_len), 4 x ref_len
Search O(qry_len) O(qry_len x log ref_len)
Post-process O(4qry_len - min_match_len) O(qry_len – min_match_len)
Impact 1: reduced communication
Less data to transfer

14
A better matching data structure
$
CAA TACACA$
0
5
CA$
2 4
CA$ $
3 1
$ CA$
Suffix Tree
0 A$
1 ACA$
2 ACACA$
3 CA$
4 CACA$
5 TACACA$
Suffix Array
Space O(ref_len), 20 x ref_len O(ref_len), 4 x ref_len
Search O(qry_len) O(qry_len x log ref_len)
Post-process O(4qry_len - min_match_len) O(qry_len – min_match_len)
Impact 2: better data locality is achieved at the cost of additional per-thread processing time
Space for longer sub-references => fewer processing rounds

15
A better matching data structure
$
CAA TACACA$
0
5
CA$
2 4
CA$ $
3 1
$ CA$
Suffix Tree
0 A$
1 ACA$
2 ACACA$
3 CA$
4 CACA$
5 TACACA$
Suffix Array
Space O(ref_len), 20 x ref_len O(ref_len), 4 x ref_len
Search O(qry_len) O(qry_len x log ref_len)
Post-process O(4qry_len - min_match_len) O(qry_len – min_match_len)
Impact 3: lower post-processing overhead

16
Evaluation
17
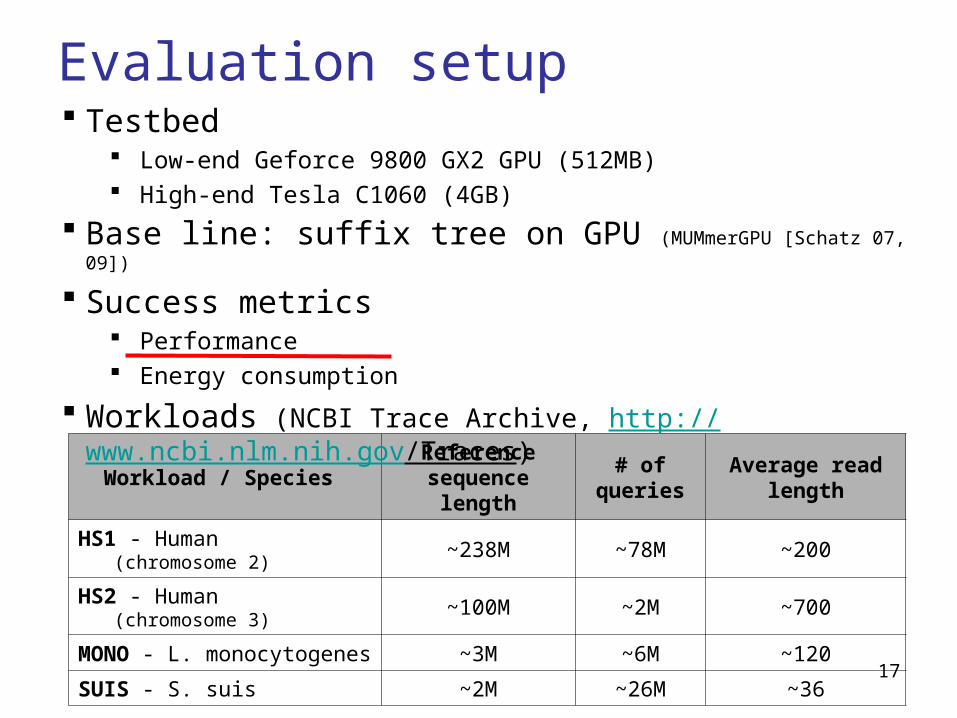
Evaluation setup
Workload / Species Reference
sequence length# of
queriesAverage read
length
HS1 - Human (chromosome 2) ~238M ~78M ~200
HS2 - Human (chromosome 3) ~100M ~2M ~700
MONO - L. monocytogenes ~3M ~6M ~120
SUIS - S. suis ~2M ~26M ~36
Testbed Low-end Geforce 9800 GX2 GPU (512MB) High-end Tesla C1060 (4GB)
Base line: suffix tree on GPU (MUMmerGPU [Schatz 07, 09])
Success metrics Performance Energy consumption
Workloads (NCBI Trace Archive, http://www.ncbi.nlm.nih.gov/Traces)

18
Speedup: array-based over tree-based

19
Dissecting the overheads
Significant reduction in data transfers and post-processing
Workload: HS1, ~78M queries, ~238M ref. length on Geforce

20
Summary GPUs have drastically different performance
characteristics
Reconsidering the choice of the data structure used is necessary when porting applications to the GPU
A good matching data structure ensures: Low communication overhead Data locality: might be achieved at the cost of
additional per thread processing time Low post-processing overhead

21
Code available at:Code available at: netsyslab.ece.ubc.ca netsyslab.ece.ubc.ca







