

SnappyDataA Unified Cluster for Streaming,
Transactions, & Interactive Analytics
© Snappydata Inc 2017www.Snappydata.io
Jags RamnarayanCTO, CoFounder
2
Our Pedigree
GTD Ventures Team : ~ 30
- Founded GemFire (In-memory data grid)- Pivotal Spin out- 25+ VMWare, Pivotal Database Engineers
Investors
3
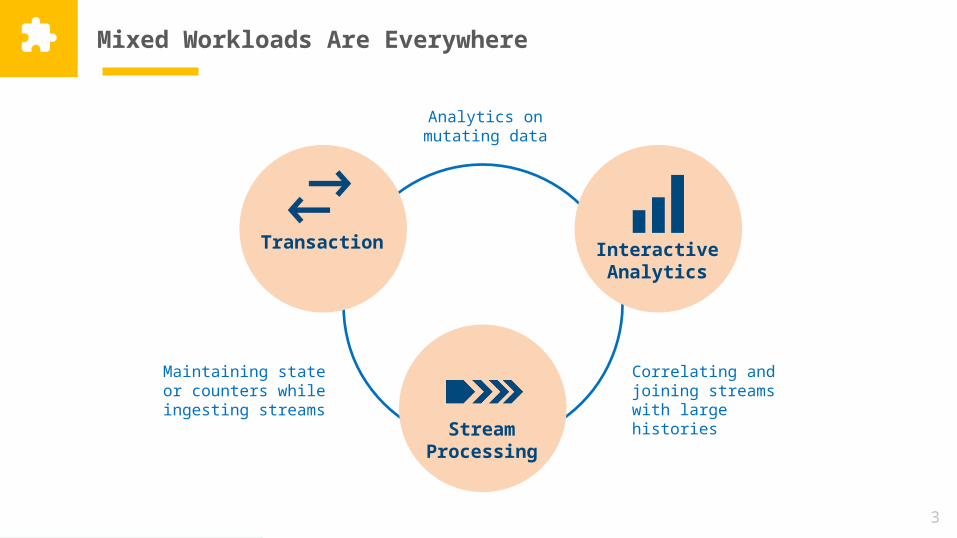
Mixed Workloads Are Everywhere
Stream Processing
Transaction Interactive Analytics
Analytics on mutating data
Correlating and joining streams with large histories
Maintaining state or counters while
ingesting streams
4
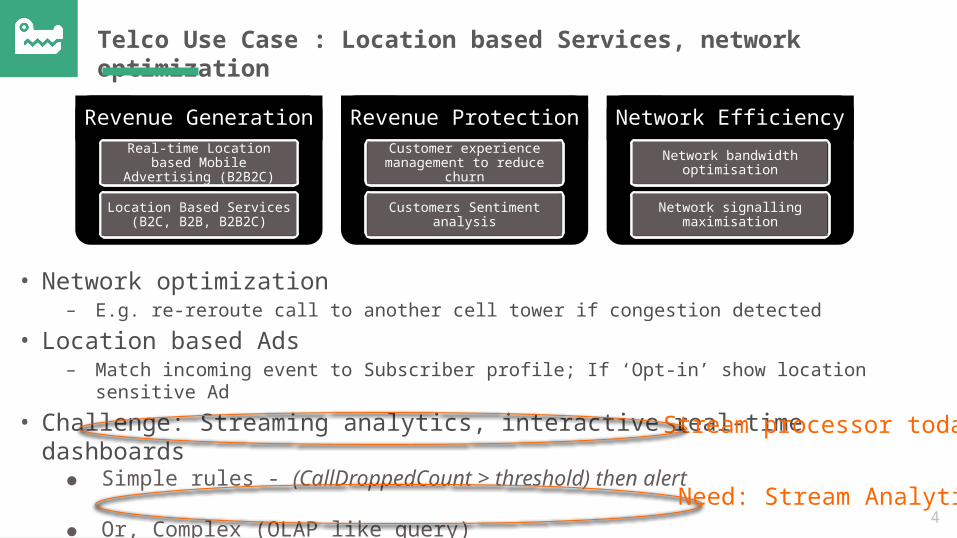
Telco Use Case : Location based Services, network optimization
Revenue GenerationReal-time Location based
Mobile Advertising (B2B2C)
Location Based Services (B2C, B2B, B2B2C)
Revenue ProtectionCustomer experience
management to reduce churn
Customers Sentiment analysis
Network EfficiencyNetwork bandwidth
optimisation
Network signalling maximisation
• Network optimization– E.g. re-reroute call to another cell tower if congestion detected
• Location based Ads– Match incoming event to Subscriber profile; If ‘Opt-in’ show location sensitive Ad
• Challenge: Streaming analytics, interactive real-time dashboards● Simple rules - (CallDroppedCount > threshold) then alert
● Or, Complex (OLAP like query)● TopK, Trending, Join with reference data, correlate with history
Stream processor today
Need: Stream Analytics
5
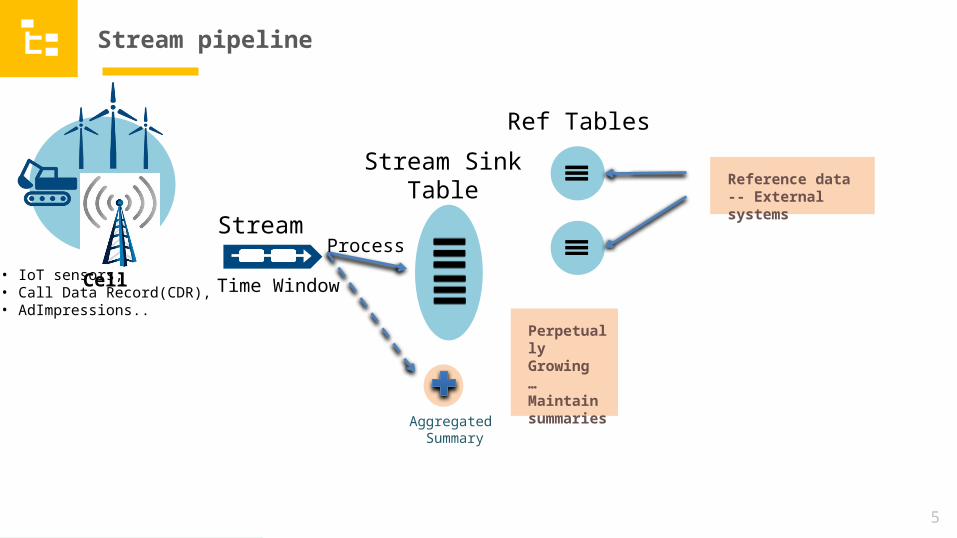
Stream pipeline
Perpetually Growing… Maintain summaries
Reference data-- External systems
Time Window
Aggregated Summary
Ref Tables
StreamProcess
Stream SinkTableIOT
Devices….Cell • IoT sensors,
• Call Data Record(CDR), • AdImpressions..
6
Number of Processing Challenges
Perpetually Growing… Maintain summaries
Reference data-- External systems
Time Window
Aggregated Summary
Stream SinkTable
Ref Tables
StreamProcess
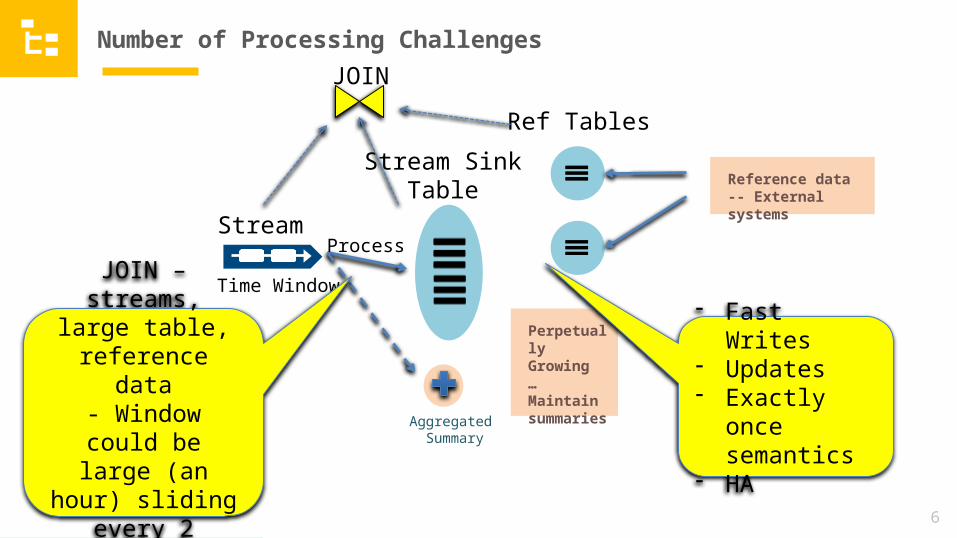
JOIN – streams, large table,
reference data- Window could be
large (an hour) sliding every 2
seconds
- Fast Writes- Updates- Exactly once
semantics- HA
JOIN
7
Number of Processing Challenges
Time Window
Aggregated Summary
Stream Sink
Ref Tables
StreamProcess
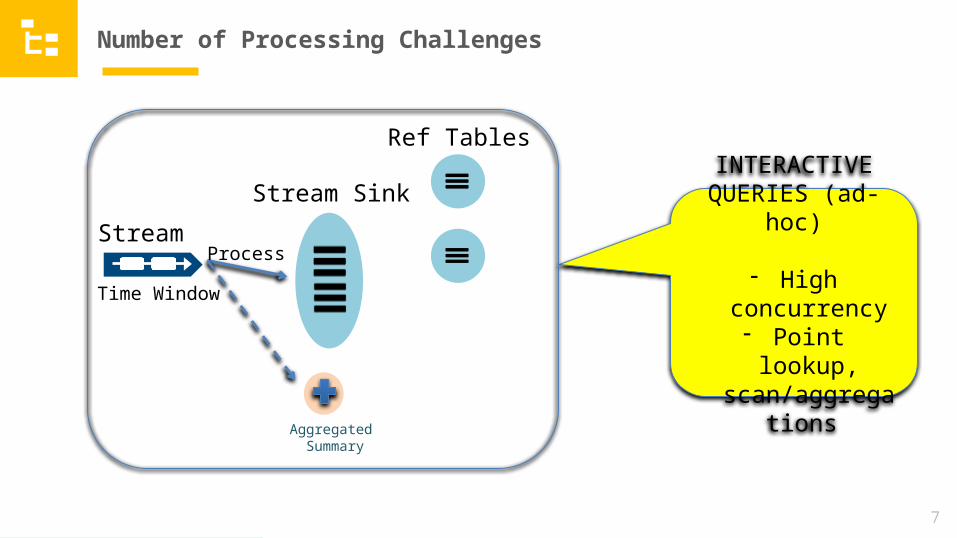
INTERACTIVE QUERIES (ad-hoc)
- High concurrency- Point lookup, scan/aggregations
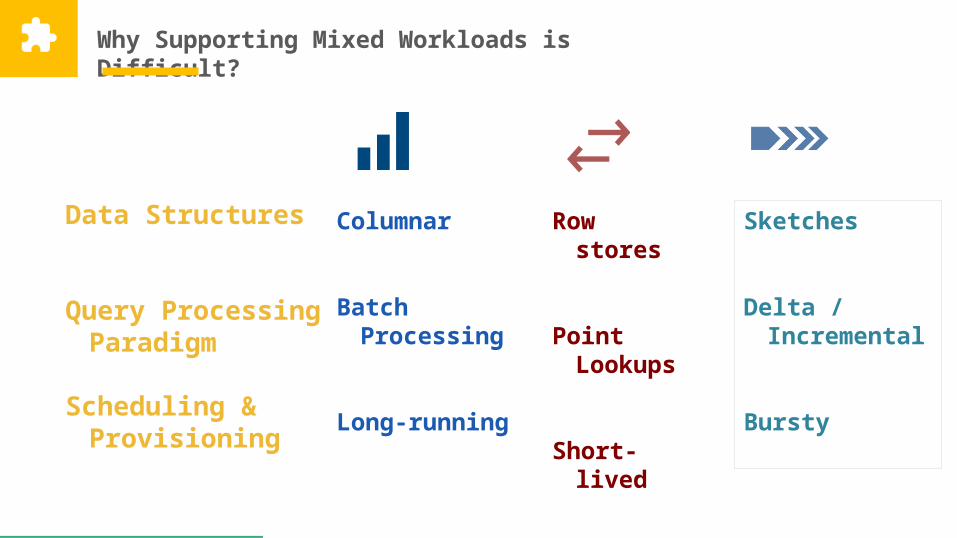
Why Supporting Mixed Workloads is Difficult?
Data Structures
Query Processing Paradigm
Scheduling & Provisioning
Columnar
Batch Processing
Long-running
Row stores
Point Lookups
Short-lived
Sketches
Delta / Incremental
Bursty
9
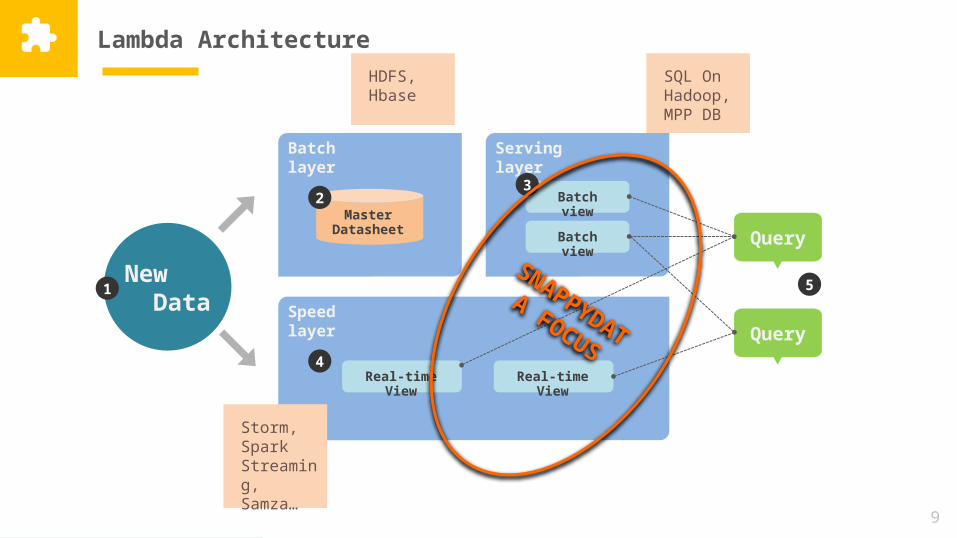
Lambda Architecture
Query
New Data
Batch layer
Master Datasheet
2
Serving layer
Batch view
3
Batch view
Speed layer
4Real-time
ViewReal-time
View
1
Query
5SNAPPYDATA FOCUS
Storm, Spark Streaming, Samza…
HDFS, Hbase
SQL On Hadoop,MPP DB

10
Lambda Architecture is Complex
• Complexity• Learn and master multiple
products, data models, disparate APIs & configs
• Wasted resources
• Slower• Excessive copying, serialization,
shuffles• Impossible to achieve interactive-
speed analytics on large or mutating data
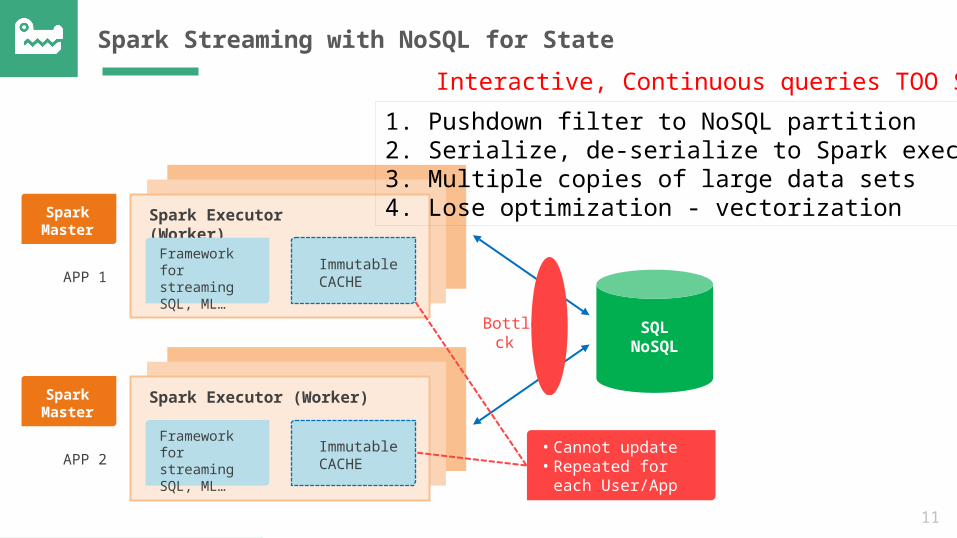
11
• Cannot update• Repeated for each
User/App
APP 1
SparkMaster
Spark Executor (Worker)
Framework for streaming SQL, ML…
ImmutableCACHE
APP 2
SparkMaster
Spark Executor (Worker)
Framework for streaming SQL, ML…
ImmutableCACHE
SQLNoSQL
Bottleneck
Spark Streaming with NoSQL for State
1. Pushdown filter to NoSQL partition 2. Serialize, de-serialize to Spark executor 3. Multiple copies of large data sets 4. Lose optimization - vectorization
Interactive, Continuous queries TOO SLOW

12
Can We Simplify & Optimize?

13© Snappydata INC 2017
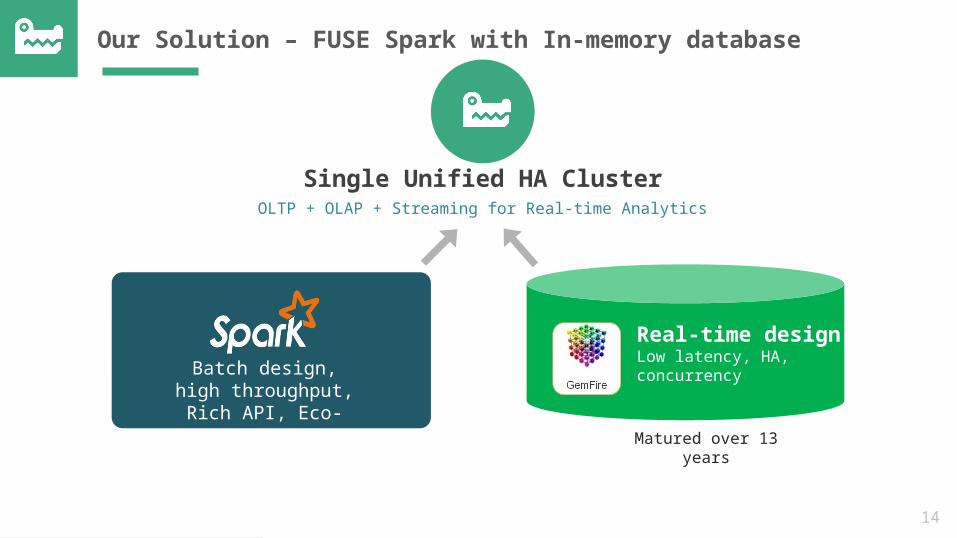
OurSolution
SnappyDataA Single Unified Cluster: OLTP + OLAP + Streaming for real-time analytics
14
Our Solution – FUSE Spark with In-memory database
Deep Scale,High Volume
MPP DB
Real-time designLow latency, HA, concurrencyBatch design, high
throughput, Rich API, Eco-system
Matured over 13 years
Single Unified HA ClusterOLTP + OLAP + Streaming for Real-time Analytics
15
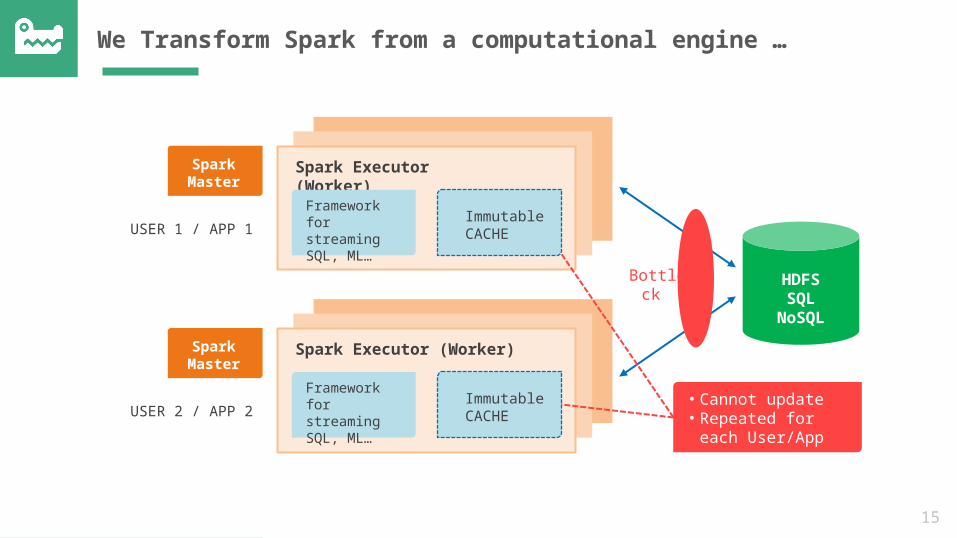
• Cannot update• Repeated for each
User/App
USER 1 / APP 1
SparkMaster
Spark Executor (Worker)
Framework for streaming SQL, ML…
ImmutableCACHE
USER 2 / APP 2
SparkMaster
Spark Executor (Worker)
Framework for streaming SQL, ML…
ImmutableCACHE
HDFSSQL
NoSQL
Bottleneck
We Transform Spark from a computational engine …
16
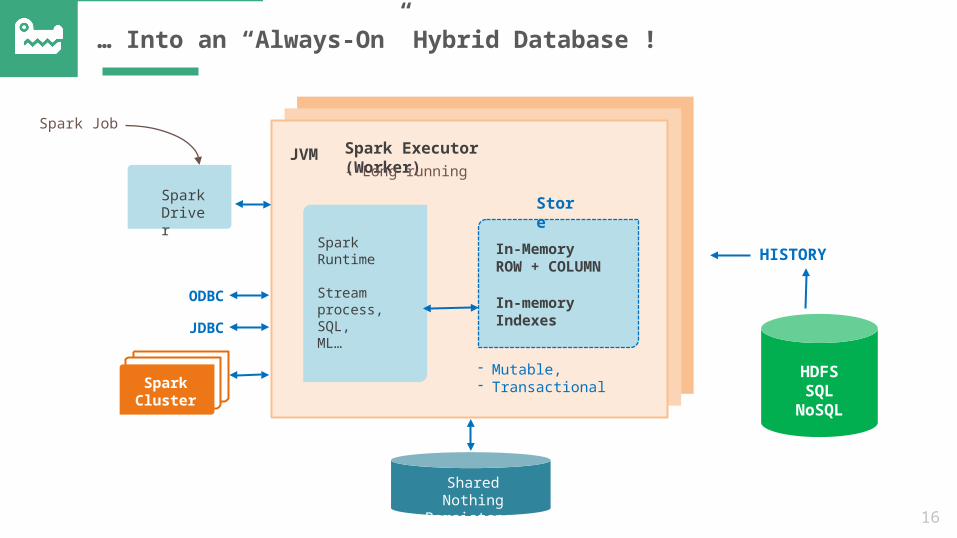
… Into an “Always-On” Hybrid Database !
Deep Scale,High Volume
MPP DB
HDFSSQL
NoSQL
HISTORY
Spark Executor (Worker)
JVM- Long running
Spark Runtime
Stream process, SQL, ML…
SparkDriver
In-MemoryROW + COLUMNIn-memory Indexes
Store
- Mutable, - TransactionalSpark
Cluster
JDBC
ODBC
Spark Job
Shared Nothing Persistence
17
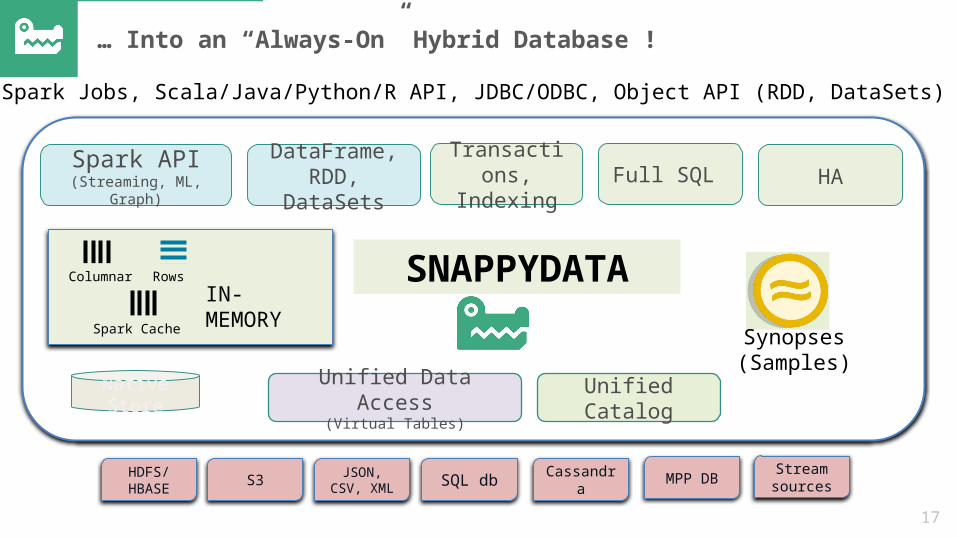
… Into an “Always-On” Hybrid Database !
Spark API(Streaming, ML,
Graph)
Transactions, Indexing Full SQL HA
DataFrame, RDD,
DataSets
RowsColumnarIN-MEMORY
Spark Cache Synopses(Samples)
Unified Data Access(Virtual Tables)
Unified Catalog
Native Store
SNAPPYDATA
HDFS/HBASE S3 JSON, CSV, XML SQL db Cassandra MPP DB
Stream sources
Spark Jobs, Scala/Java/Python/R API, JDBC/ODBC, Object API (RDD, DataSets)
18
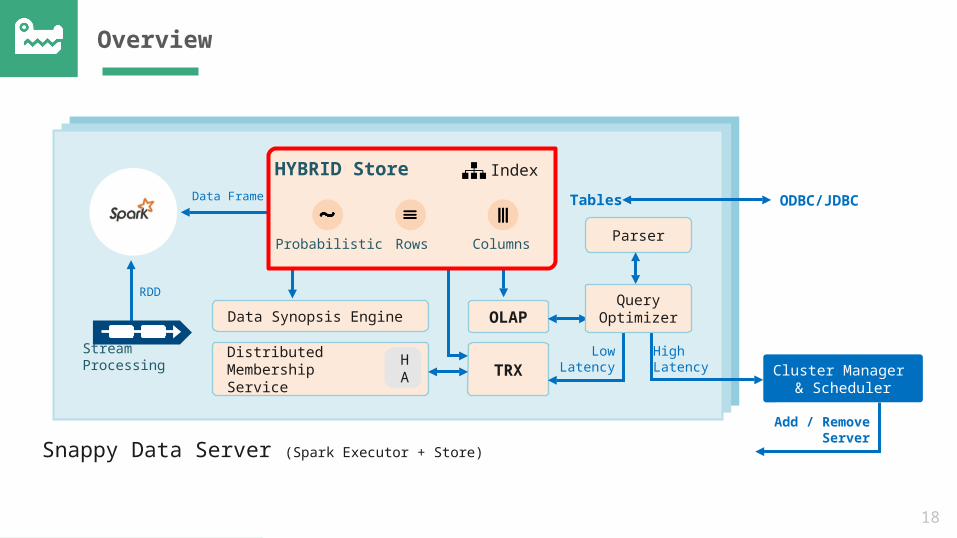
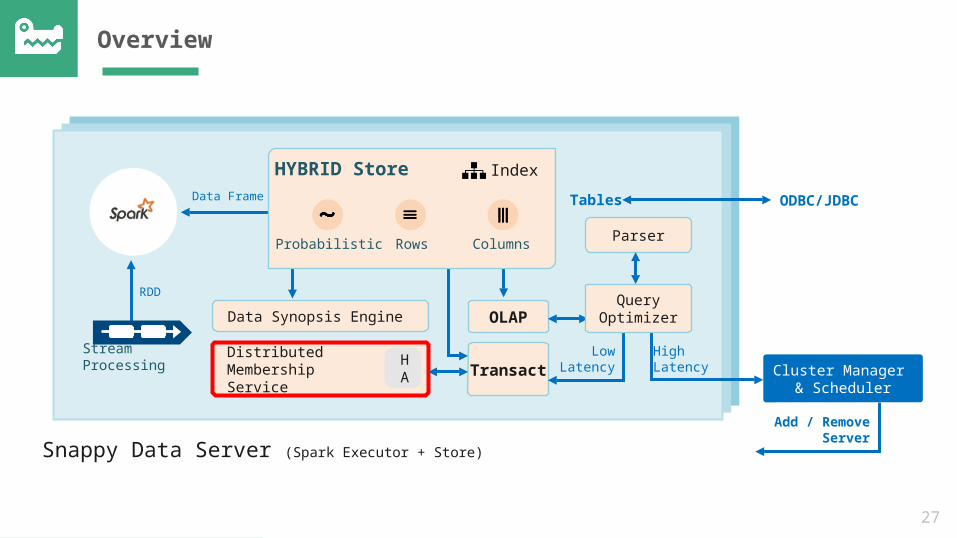
Overview
Cluster Manager & Scheduler
Snappy Data Server (Spark Executor + Store)
Parser
OLAP
TRX
Data Synopsis Engine
Distributed Membership Service
HA
Stream Processing
Data Frame
RDD
LowLatency
HighLatency
HYBRID Store
Probabilistic Rows Columns
Index
Query Optimizer
Add / Remove
Server
Tables ODBC/JDBC
19
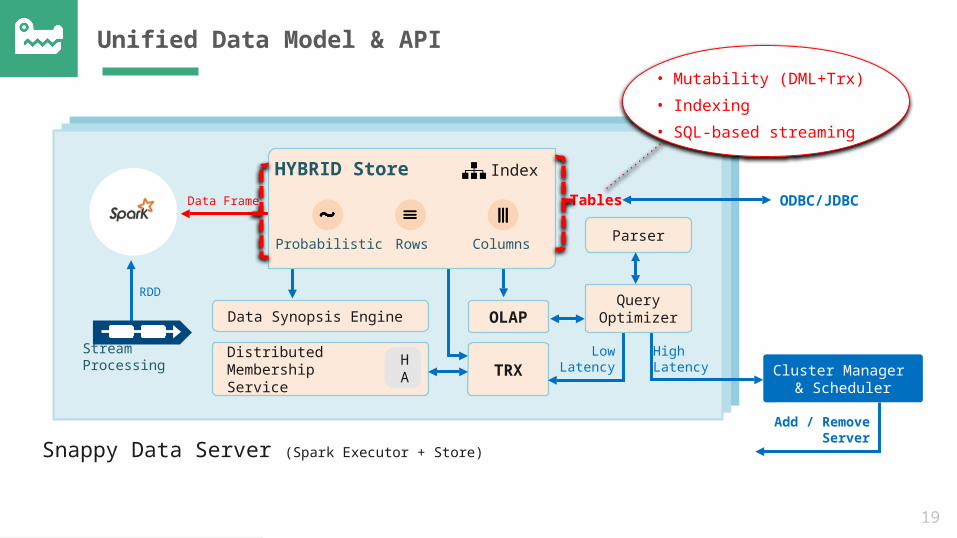
Unified Data Model & API
Cluster Manager & Scheduler
Snappy Data Server (Spark Executor + Store)
Parser
OLAP
TRX
Data Synopsis Engine
Distributed Membership Service
HA
Stream Processing
Tables ODBC/JDBCData Frame
RDD
LowLatency
HighLatency
HYBRID Store
Probabilistic Rows Columns
Index
Query Optimizer
Add / Remove
Server
• Mutability (DML+Trx)• Indexing• SQL-based streaming
20
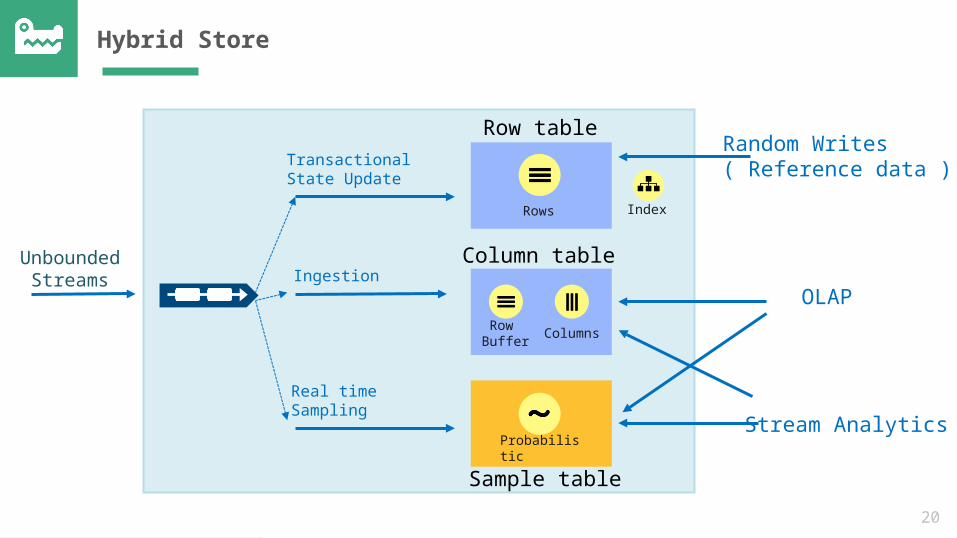
Hybrid Store
Unbounded Streams Ingestion
Real time Sampling
Transactional State Update
Probabilistic
IndexRows
Row Buffer Columns
Random Writes ( Reference data )
OLAP
Stream Analytics
Row table
Column table
Sample table
21
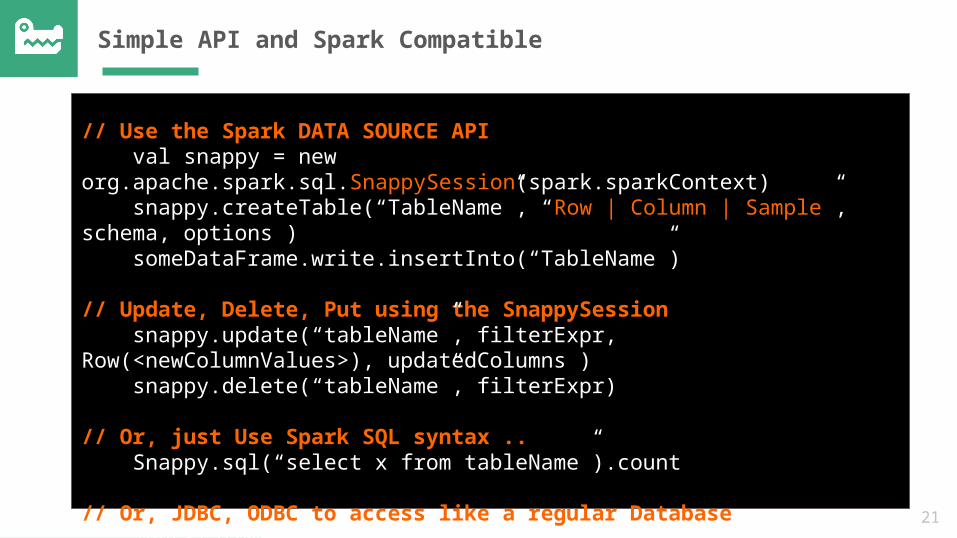
Simple API and Spark Compatible
// Use the Spark DATA SOURCE API val snappy = new org.apache.spark.sql.SnappySession(spark.sparkContext) snappy.createTable(“TableName”, “Row | Column | Sample”, schema, options ) someDataFrame.write.insertInto(“TableName”)
// Update, Delete, Put using the SnappySession snappy.update(“tableName”, filterExpr, Row(<newColumnValues>), updatedColumns ) snappy.delete(“tableName”, filterExpr)
// Or, just Use Spark SQL syntax .. Snappy.sql(“select x from tableName”).count
// Or, JDBC, ODBC to access like a regular Database jdbcStatement.executeUpdate(“insert into tableName values …”)
22
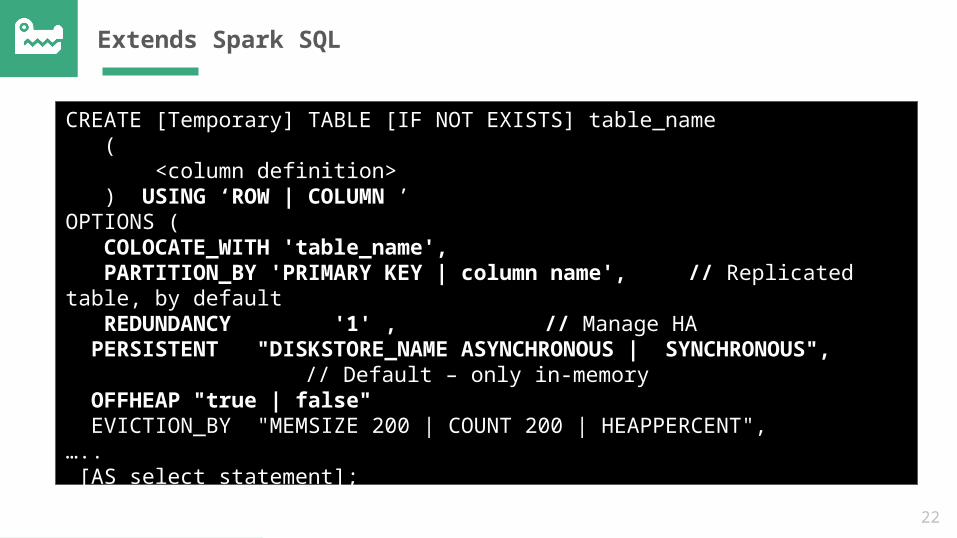
Extends Spark SQL
CREATE [Temporary] TABLE [IF NOT EXISTS] table_name ( <column definition> ) USING ‘ROW | COLUMN ’OPTIONS ( COLOCATE_WITH 'table_name', PARTITION_BY 'PRIMARY KEY | column name', // Replicated table, by default REDUNDANCY '1' , // Manage HA PERSISTENT "DISKSTORE_NAME ASYNCHRONOUS | SYNCHRONOUS",
// Default – only in-memory OFFHEAP "true | false" EVICTION_BY "MEMSIZE 200 | COUNT 200 | HEAPPERCENT",….. [AS select_statement];
23
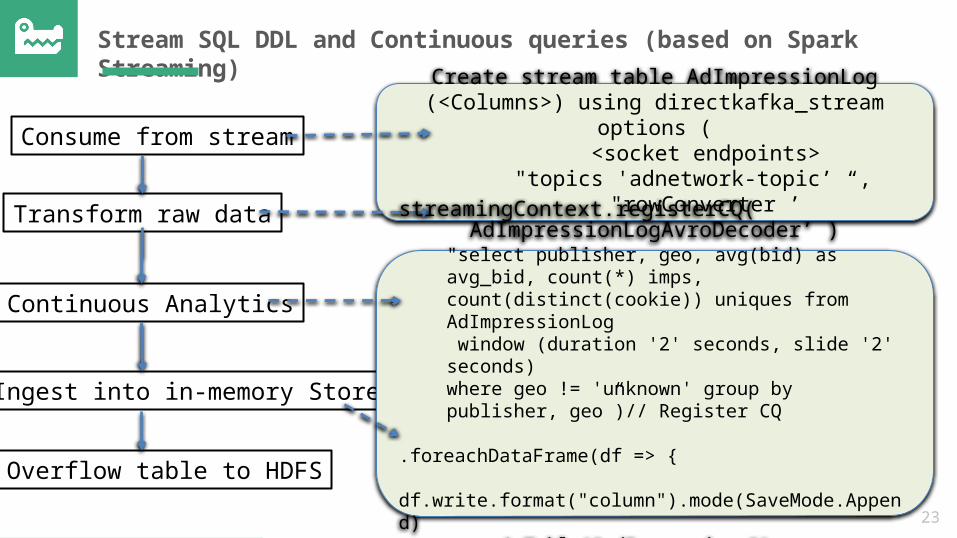
Stream SQL DDL and Continuous queries (based on Spark Streaming)
Consume from stream
Transform raw data
Continuous Analytics
Ingest into in-memory Store
Overflow table to HDFS
Create stream table AdImpressionLog(<Columns>) using directkafka_stream options (
<socket endpoints> "topics 'adnetwork-topic’ “,
"rowConverter ’ AdImpressionLogAvroDecoder’ )
streamingContext.registerCQ(
"select publisher, geo, avg(bid) as avg_bid, count(*) imps, count(distinct(cookie)) uniques from AdImpressionLog window (duration '2' seconds, slide '2' seconds)where geo != 'unknown' group by publisher, geo”)// Register CQ
.foreachDataFrame(df => { df.write.format("column").mode(SaveMode.Append)
.saveAsTable("adImpressions")
24
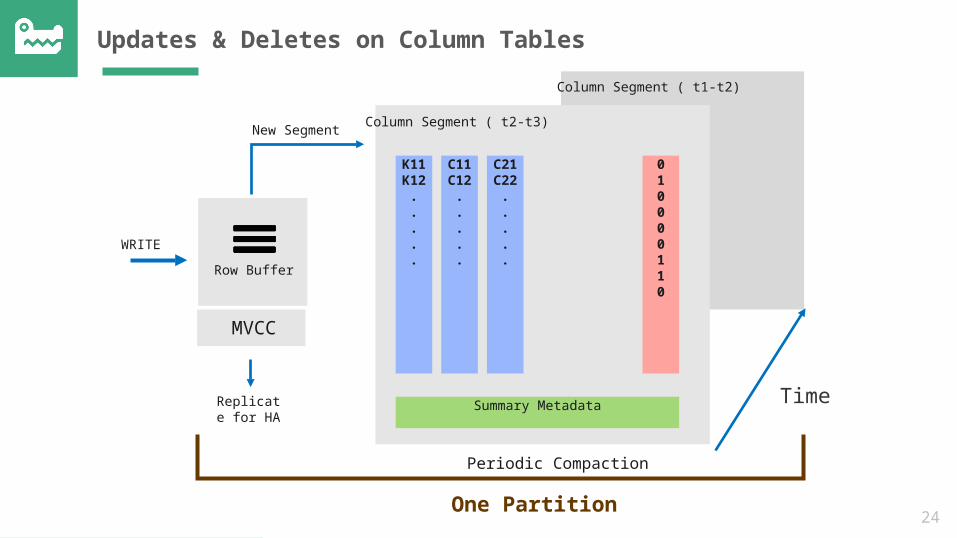
Updates & Deletes on Column TablesColumn Segment ( t1-t2)
Column Segment ( t2-t3)
010000110
K11K12
.
.
.
.
.
C11C12
.
.
.
.
.
C21C22
.
.
.
.
.
Summary Metadata
Periodic Compaction
One Partition
Time
WRITERow Buffer
MVCC
New Segment
Replicate for HA
25
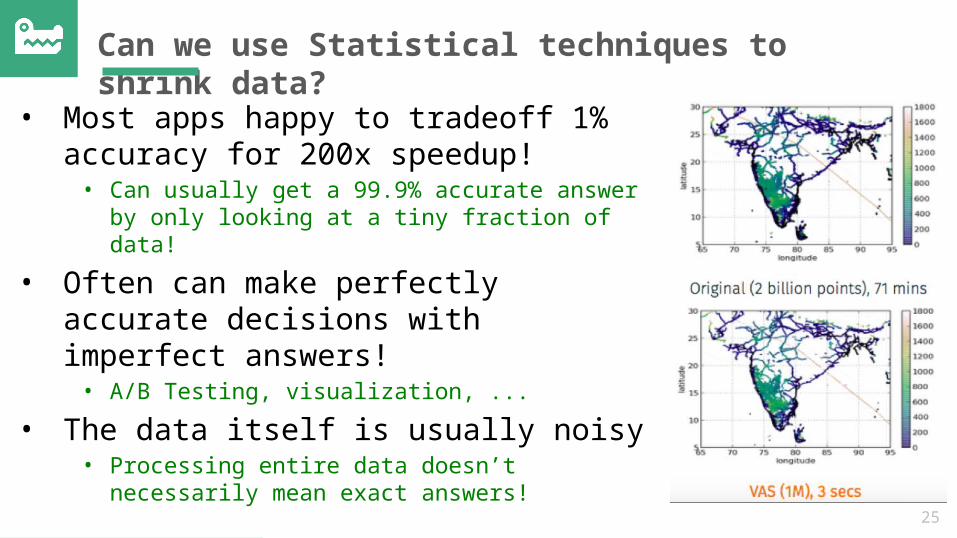
Can we use Statistical techniques to shrink data?
• Most apps happy to tradeoff 1% accuracy for 200x speedup! • Can usually get a 99.9% accurate answer by only
looking at a tiny fraction of data!
• Often can make perfectly accurate decisions with imperfect answers! • A/B Testing, visualization, ...
• The data itself is usually noisy• Processing entire data doesn’t necessarily mean exact
answers!
`
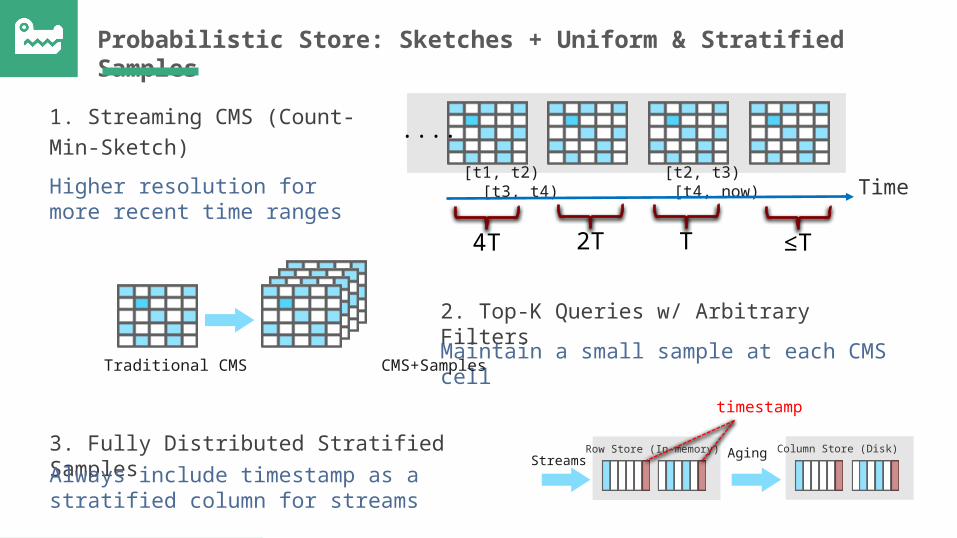
Probabilistic Store: Sketches + Uniform & Stratified Samples
Higher resolution for more recent time ranges
1. Streaming CMS (Count-Min-Sketch)
[t1, t2) [t2, t3) [t3, t4) [t4, now) Time
4T 2T T ≤T
....
Maintain a small sample at each CMS cell2. Top-K Queries w/ Arbitrary Filters
Traditional CMS CMS+Samples
3. Fully Distributed Stratified SamplesAlways include timestamp as a stratified column for streams
Streams AgingRow Store (In-memory) Column Store (Disk)
timestamp
27
Overview
Cluster Manager & Scheduler
Snappy Data Server (Spark Executor + Store)
Parser
OLAP
Transact
Data Synopsis Engine
Distributed Membership Service
HA
Stream Processing
Data Frame
RDD
LowLatency
HighLatency
HYBRID Store
Probabilistic Rows Columns
Index
Query Optimizer
Add / Remove
Server
Tables ODBC/JDBC
28
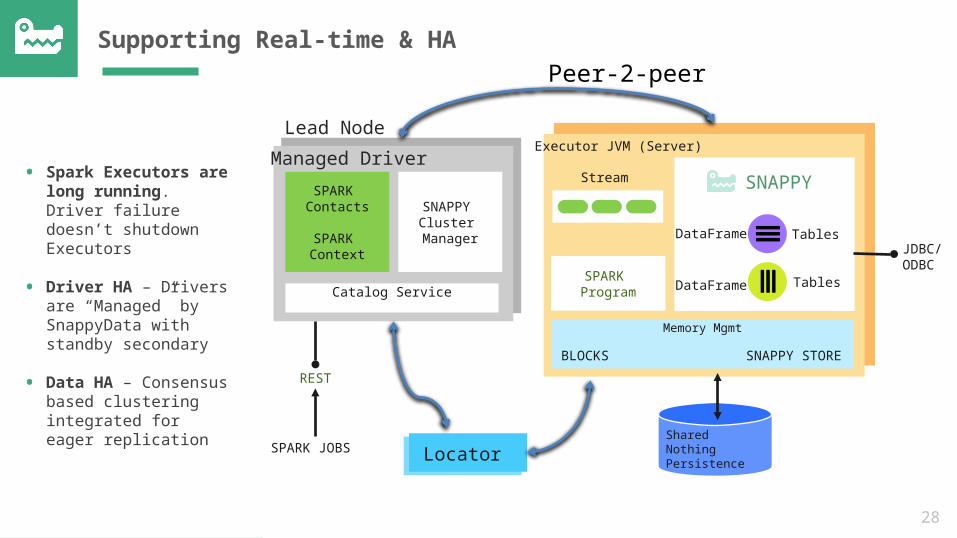
Supporting Real-time & HA
Locator
Lead NodeExecutor JVM (Server)
Shared Nothing Persistence
JDBC/ODBC
Catalog Service
Managed DriverSPARK
Contacts
SPARK Context
SNAPPY Cluster Manager
REST
SPARK JOBS
SPARK Program
Memory Mgmt
BLOCKS SNAPPY STORE
Stream SNAPPY
Tables
Tables
DataFrame
• Spark Executors are long running. Driver failure doesn’t shutdown Executors
• Driver HA – Drivers are “Managed” by SnappyData with standby secondary
• Data HA – Consensus based clustering integrated for eager replication
DataFrame
Peer-2-peer
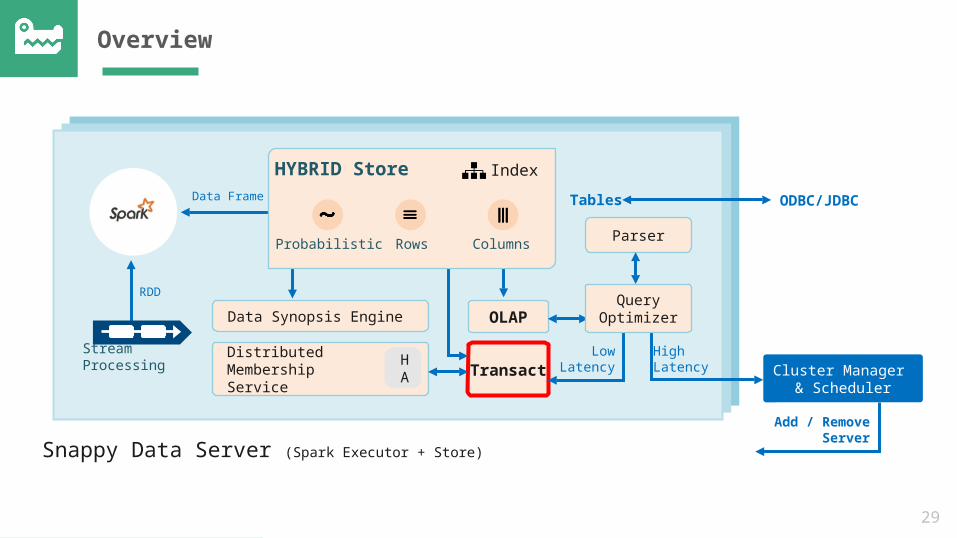
29
Overview
Cluster Manager & Scheduler
Snappy Data Server (Spark Executor + Store)
Parser
OLAP
Transact
Data Synopsis Engine
Distributed Membership Service
HA
Stream Processing
Data Frame
RDD
LowLatency
HighLatency
HYBRID Store
Probabilistic Rows Columns
Index
Query Optimizer
Add / Remove
Server
Tables ODBC/JDBC

30
Transactions
• Support for Read Committed & Repeatable Read
• W-W and R-W conflict detection at write time
• MVCC for non blocking reads and snapshot isolation
• Distributed system failure detection integrated with commit protocol- Evict unresponsive replicas
- Ensure consistency when replicas recover
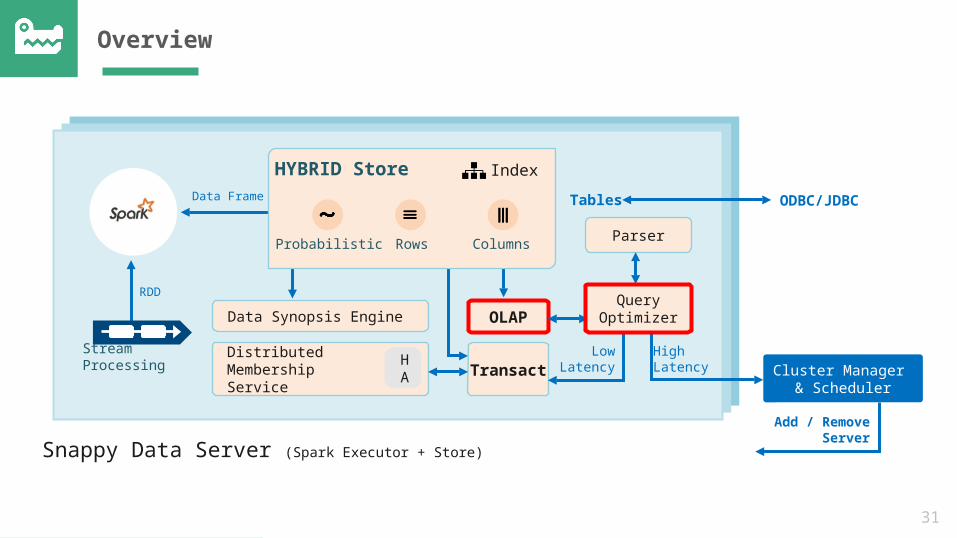
31
Overview
Cluster Manager & Scheduler
Snappy Data Server (Spark Executor + Store)
Parser
OLAP
Transact
Data Synopsis Engine
Distributed Membership Service
HA
Stream Processing
Data Frame
RDD
LowLatency
HighLatency
HYBRID Store
Probabilistic Rows Columns
Index
Query Optimizer
Add / Remove
Server
Tables ODBC/JDBC

Query Optimization
• Bypass the scheduler for transactions and low-latency jobs
• Minimize shuffles aggressively- Dynamic replication for reference data- Retain ‘join indexes’ whenever possible- Collocate related data sets
• Optimized ‘Hash Join’, ‘Scan’, ‘GroupBy’ compared to Spark- Uses more variables in code generation, vectorized
structures• Column segment pruning through statistics
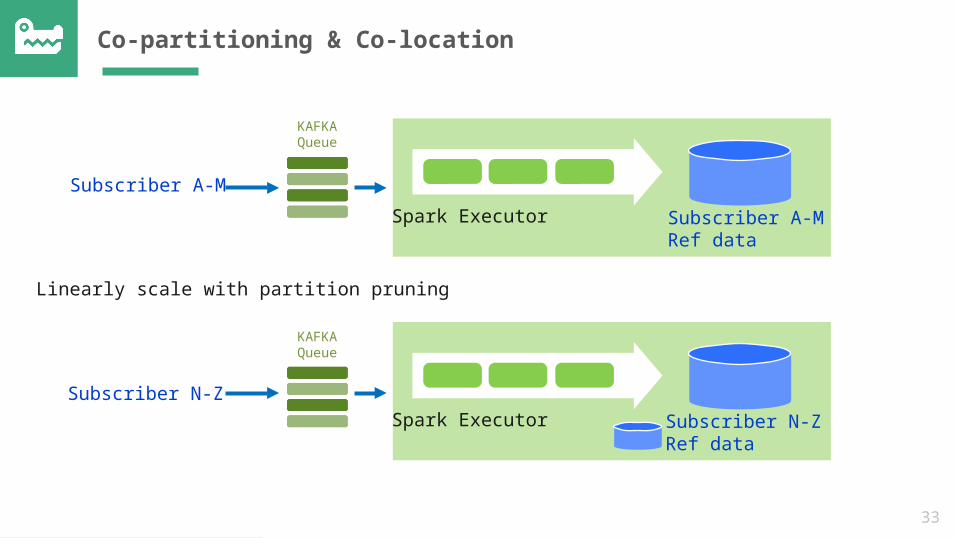
33
Co-partitioning & Co-location
Spark Executor Subscriber A-MRef data
Spark Executor Subscriber N-ZRef data
Linearly scale with partition pruning
Subscriber A-M
Subscriber N-Z
KAFKA Queue
KAFKA Queue
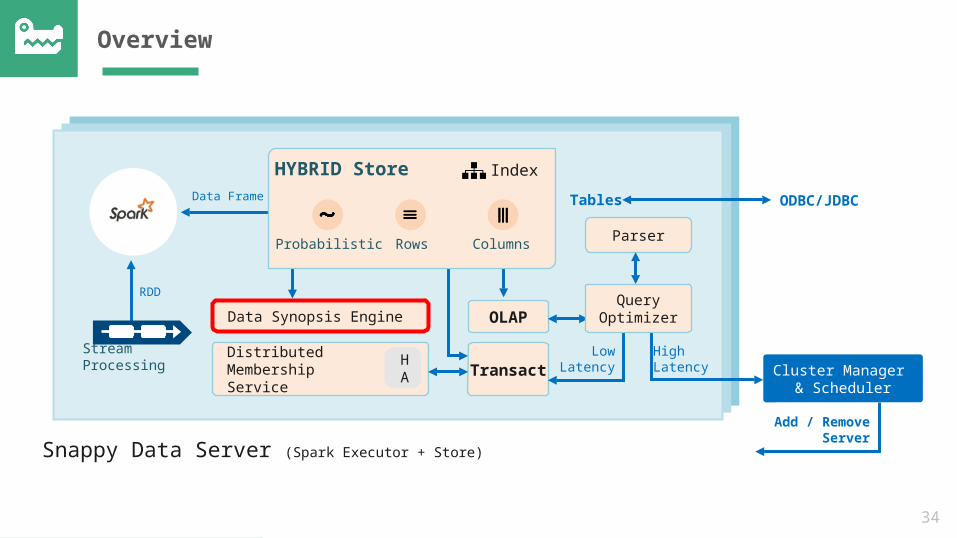
34
Overview
Cluster Manager & Scheduler
Snappy Data Server (Spark Executor + Store)
Parser
OLAP
Transact
Data Synopsis Engine
Distributed Membership Service
HA
Stream Processing
Data Frame
RDD
LowLatency
HighLatency
HYBRID Store
Probabilistic Rows Columns
Index
Query Optimizer
Add / Remove
Server
Tables ODBC/JDBC
35
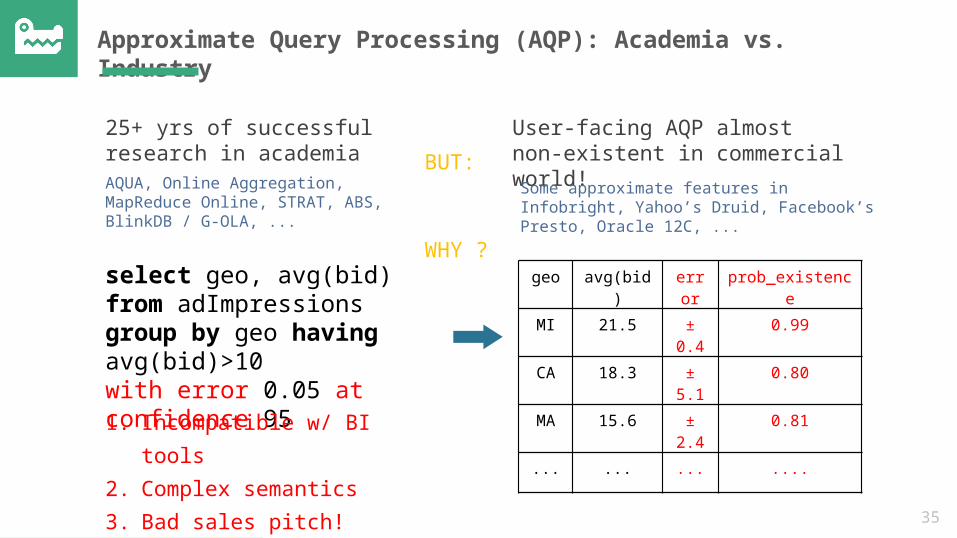
Approximate Query Processing (AQP): Academia vs. Industry
25+ yrs of successful research in academia
User-facing AQP almost non-existent in commercial world!Some approximate features in Infobright, Yahoo’s Druid, Facebook’s Presto, Oracle 12C, ...
AQUA, Online Aggregation, MapReduce Online, STRAT, ABS, BlinkDB / G-OLA, ...
WHY ?
BUT:
select geo, avg(bid) from adImpressionsgroup by geo having avg(bid)>10with error 0.05 at confidence 95
geo avg(bid) error
prob_existence
MI 21.5 ± 0.4
0.99
CA 18.3 ± 5.1
0.80
MA 15.6 ± 2.4
0.81
... ... ... ....
1. Incompatible w/ BI tools2. Complex semantics3. Bad sales pitch!
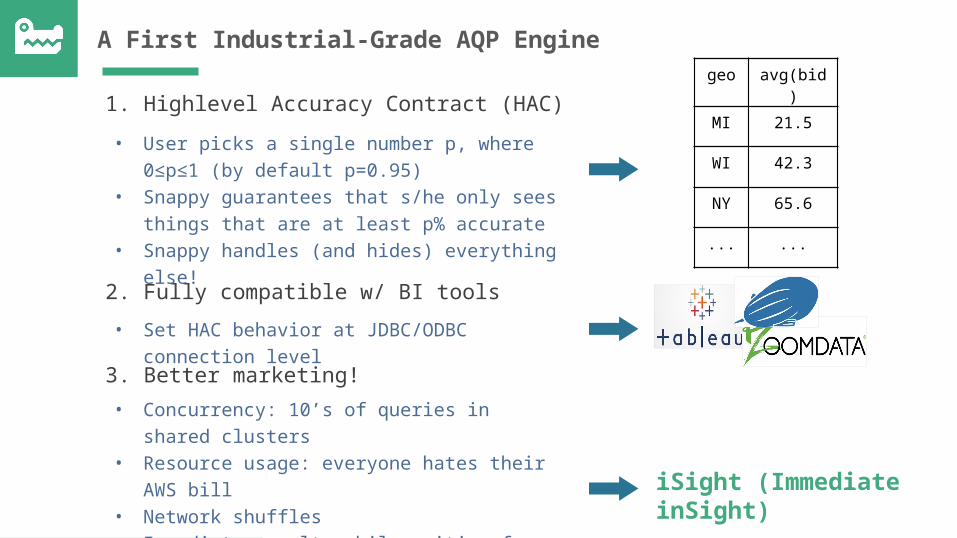
A First Industrial-Grade AQP Engine
1. Highlevel Accuracy Contract (HAC)
• Concurrency: 10’s of queries in shared clusters
• Resource usage: everyone hates their AWS bill
• Network shuffles • Immediate results while waiting for final
results
2. Fully compatible w/ BI tools• Set HAC behavior at JDBC/ODBC connection
level3. Better marketing!
• User picks a single number p, where 0≤p≤1 (by default p=0.95)
• Snappy guarantees that s/he only sees things that are at least p% accurate
• Snappy handles (and hides) everything else!
geo avg(bid)
MI 21.5
WI 42.3
NY 65.6
... ...
iSight (Immediate inSight)

Conclusion

Unified OLAP/OLTP streaming w/ Spark
● Far fewer resources: TB problem becomes GB.○ CPU contention drops
● Far less complex○ single cluster for stream ingestion, continuous queries,
interactive queries and machine learning● Much faster
○ compressed data managed in distributed memory in columnar form reduces volume and is much more responsive

Lessons Learned
2. A unified cluster is simpler, cheaper, and faster- By sharing state across apps, we decouple apps from data servers and provide HA- Save memory, data copying, serialization, and shuffles- Co-partitioning and co-location for faster joins and stream analytics3. Advantages over HTAP engines: Deep stream integration + AQP
1. A unique experience marryings two different breeds of distributed systemslineage-based for high-throughput vs. (consensus-) replication-based for low-latency
- Stream processing ≠ stream analytics- Top-k w/ almost arbitrary predicates + 1-pass stratified sampling over streams4. Commercializing academic work is lots of work but also lots of fun

THANK YOU !
Try our iSight cloud for free: http://snappydata.io/iSight
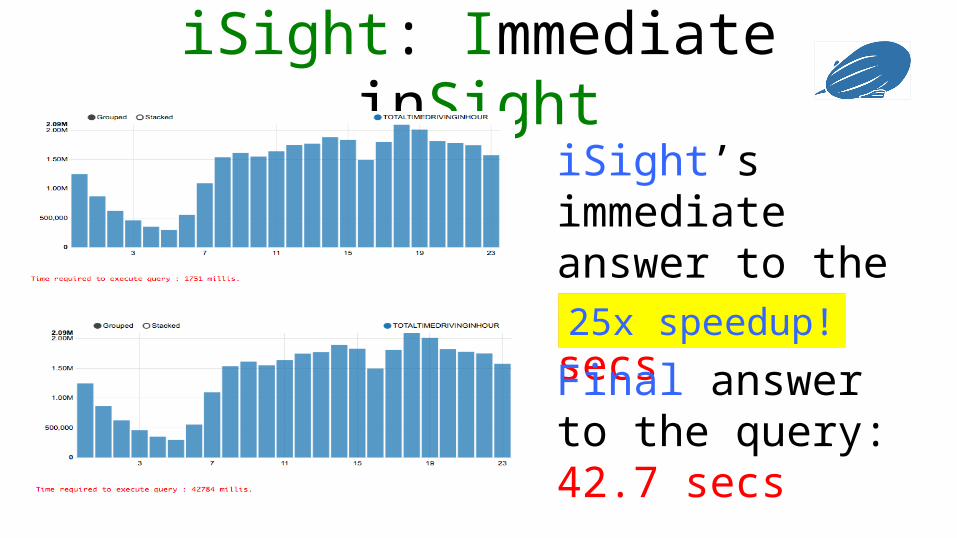
iSight: Immediate inSightiSight’s immediate answer to the query: 1.7 secs
Final answer to the query: 42.7 secs
25x speedup!

Our Solution: Highlevel Accuracy Contract (HAC)
• A single number 0≤p≤1 (by default p=0.95)• We guarantee that you only see things that
are at least p% accurate• We handle (and hide) everything else– Choose a behavior: REPLACE WITH SPECIAL
SYMBOL (default), DO NOTHING, DROP THE ROW)







