

SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING
Presented By:Ramaninder Singh Jhajj
Seminar on Internet Technologies

AGENDA
• Problem
• Limitation of Map Reduce
• Spark Computing Framework
• Resilient Distributed Datasets
• A Unified Stack
• Who uses Spark?
• Demo
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 2

PROBLEM
• Data growing faster than processing speeds
• Map Reduce:• Restrict the programming interface so that the system can do more
automatically.
• Express jobs as high level operators.
• Map Reduce is efficient (But may be not always)
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 3

LIMITATIONS OF MAPREDUCE
• Work very well with one-pass computation but ineffiecient for multi-pass algorithms.
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 4
Source: http://www.slideshare.net/aknahs/spark-16667619

SOLUTION: IN-MEMORY DATA SHARING
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 5
Source: http://www.slideshare.net/aknahs/spark-16667619

SPARK ... IS WHAT YOU MIGHT CALL A SWISS ARMY KNIFE OF BIG DATA ANALYTICS TOOLS
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 6
- Reynold Xin (@rxin),
Berkeley AMPLab Shark Development Lead
SPARK: IN A TWEET

SPARK COMPUTING FRAMEWORK
• Spark is a fast and general engine for large scale data processing.
• Handles batch, interactive, iterative and real-time application scenarios and provides clean APIs in Java, Scala, Python.
• "Here‘s an operation, run it on all the data": I don‘t care where it runs and how faults will be handled.
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 7

RESILIENT DISTRIBUTED DATASETS (RDD)
• Primary memory abstraction.
• Read only collection of objects partitioned across cluster that can be rebuilt if a partition is lost.
• Can be cached explicitely in memory.
• Two operations: Transformations and Actions
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 8

RDD OPERATIONS
Transform
ations RDD action Value
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 9
Transformations Actions
map reduce
filter collect
flatMap count
mapPartitions first
groupByKey take(n)
reduceByKey saveAsTextFile
join foreach
https://spark.apache.org/docs/latest/programming-guide.html#rdd-operations
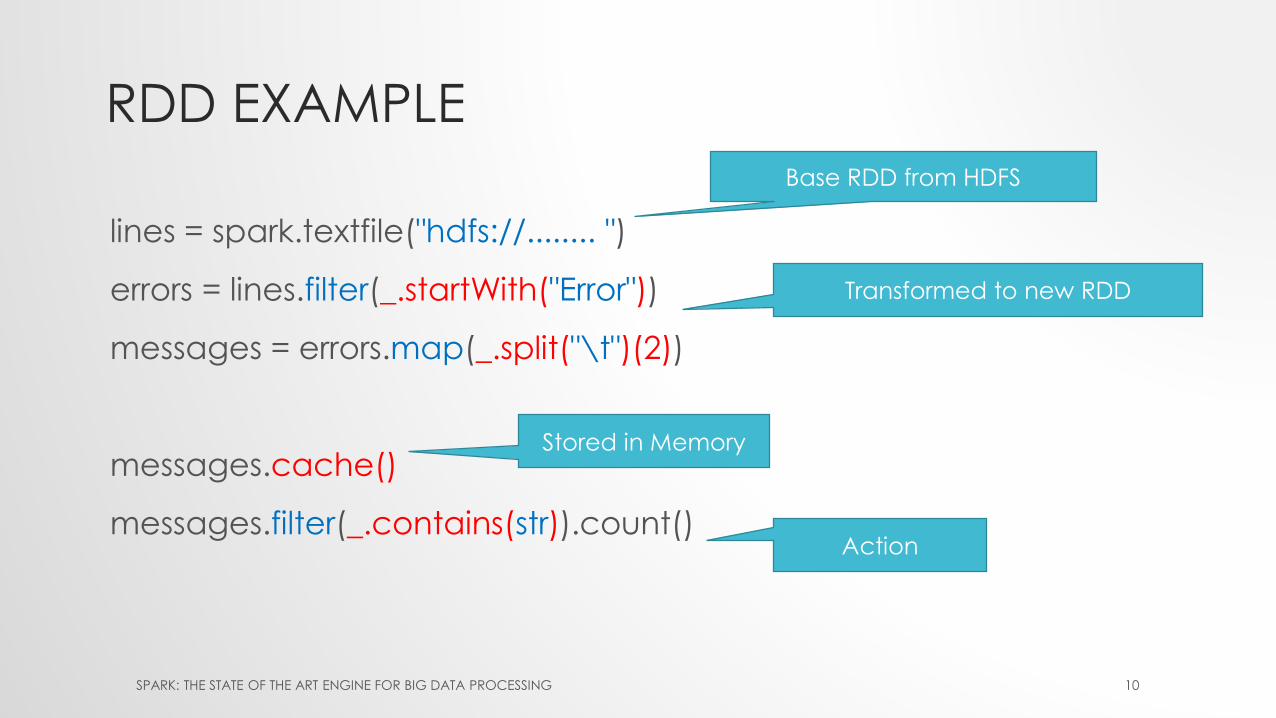
RDD EXAMPLE
lines = spark.textfile("hdfs://........ ")
errors = lines.filter(_.startWith("Error"))
messages = errors.map(_.split("\t")(2))
messages.cache()
messages.filter(_.contains(str)).count()
Base RDD from HDFS
Transformed to new RDD
Stored in Memory
Action
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 10

FAULT TOLERANCE IN RDDS
• Achieved through a notion of lineage.
• Keep track of how it was derived from other RDDs.
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 11
Ex: message = textFile(...).filter(_.contains("error")).map(_.split("\t")(2))

EXAMPLE: WORD COUNT
• Word Count in MapReduce: 50-70 lines of code.
• What about Spark?
Python
Java
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 12

SPARK: A UNIFIED STACK
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 13
Spark Core
RDD APIs Fault ToleranceProcessing

A UNIFIED STACK : SPARK SQL
Spark Core
Spark SQL
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 14
• Spark SQL unifies access to structured data.
• Seamlessly mix SQL queries with Spark programs
sqlCtx.jsonFile("s3n://... ") .registerAsTable("json")schema_rdd = sqlCtx.sql(" " " SELECT * FROM hiveTable JOIN json ... " " ")

Spark Core
Spark SQL
GraphX
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 15
A UNIFIED STACK : SPARK GRAPHX
•GraphX is Apache Spark's API for graphs and graph-parallel computation
•Seamlessly work with both graphs and collections

A UNIFIED STACK : SPARK MLLIB
Spark Core
Spark SQL
GraphX MLLib
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 16
• MLlib is Apache Spark's scalable machine learning library.
• High-quality algorithms, 100x faster than MapReduce.
points = spark.textFile("hdfs://... ").map(parsePoint)
model = KMeans.train(points, k=10)
Spark Core
Spark SQL
GraphX MLLibSpark
Streaming
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 17
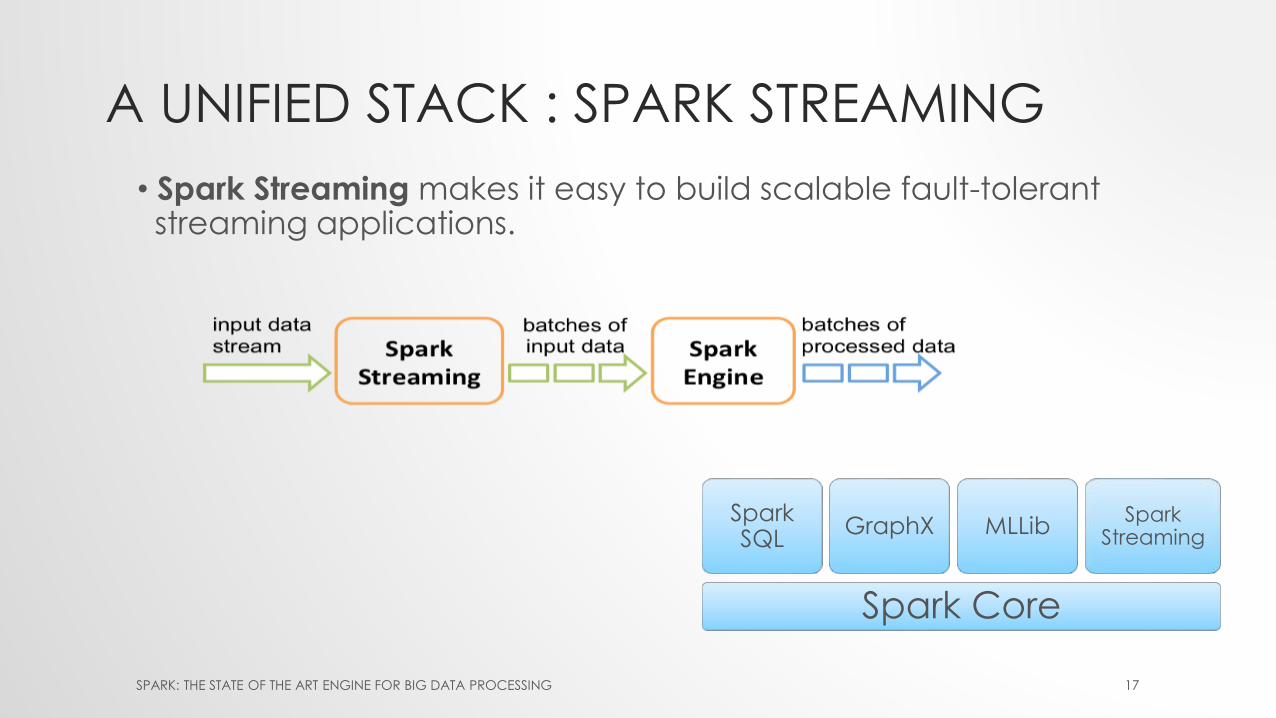
A UNIFIED STACK : SPARK STREAMING
• Spark Streaming makes it easy to build scalable fault-tolerant streaming applications.

WHO USES SPARK?
Source: Spark Wiki (https://cwiki.apache.org/confluence/display/SPARK/Powered+By+Spark)SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 18

DEMO
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 19

CONCLUSION
• Spark is the first system to allow an efficient, general-purpose programming language to be used interactively to process large datasets on a cluster.
• Same engine performs data extraction, model training and interactive queries, no need of separate framework for each function.
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 20

INTERESTED IN READING MORE?
• https://spark.apache.org/
• http://ampcamp.berkeley.edu/
• https://www.youtube.com/channel/UCRzsq7k4-kT-h3TDUBQ82-w
• https://spark.apache.org/documentation.html
• edx.org offering a course „Introduction to Big Data with Apache Spark“
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 21

ANY QUESTIONS?
Thanks you for listening
SPARK: THE STATE OF THE ART ENGINE FOR BIG DATA PROCESSING 18







