

Static Bus Schedule aware Scratchpad Allocation in Multiprocessors
Sudipta Chattopadhyay
Abhik Roychoudhury
National University of Singapore

Scratchpad Memory (Basics)
Scratchpad Memory A fast and software controlled on-chip memory Each memory access is predictable
Problems Cumbersome and error prone if managed by user Need extensive compiler support for automatic management

Scratchpad Allocation
Worst case optimization vs Average case optimization This work is on worst case
ActualBCET
ActualWCET
Execution Time
ObservedWCET
Estimated BCET
Actual
Observed
Over-estimation
WCET = Worst-case Execution TimeBCET = Best-case Execution Time
ObservedBCET
EstimatedWCET
ActualWCET
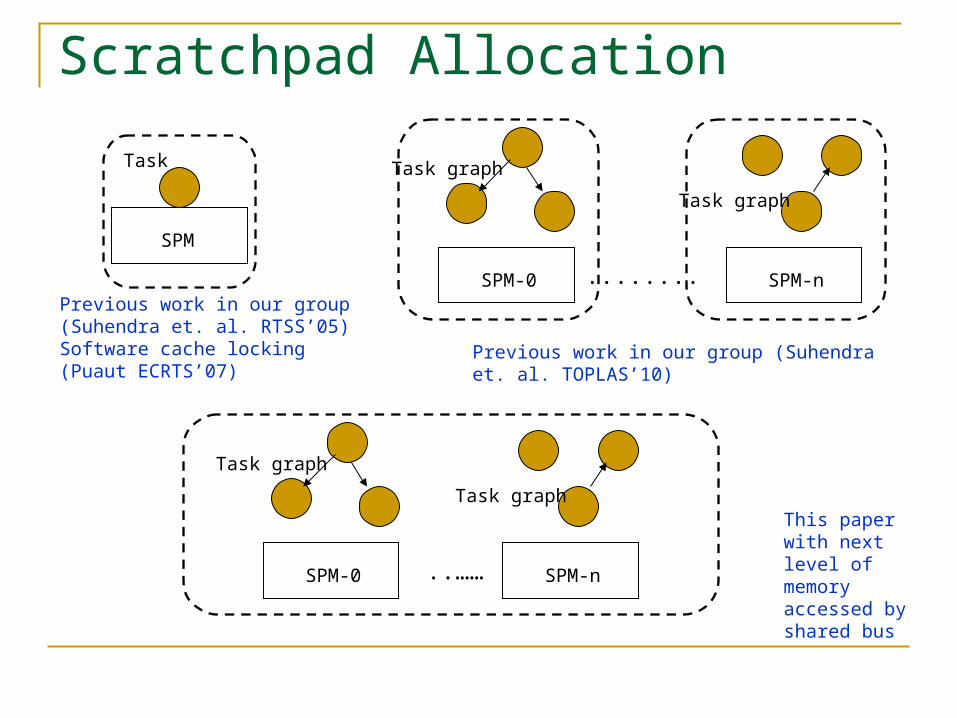
Scratchpad Allocation
SPM
Task
SPM-0 SPM-n........
Task graph
Task graph
Previous work in our group (Suhendra et. al. RTSS’05)Software cache locking (Puaut ECRTS’07)
Previous work in our group (Suhendra et. al. TOPLAS’10)
SPM-0 SPM-n..……
Task graph
Task graphThis paper with next level of memory accessed by shared bus

An MPSoC Architecture
PE-0 PE-1 PE-N
SPM-0 SPM-1 SPM-N
Shared off-chip data bus
Off-chip memory
External Memory Interface
MPSOC
……
Fast on-chip communication media

SPM architecture
Bypassing memory hierarchy Each memory access is predictable – crucial for time
predictable embedded systems
Non-bypassing memory hierarchy Acts like a fully associative cache Spilling and reloading of memory blocks lead to
unpredictable execution time

Allocation strategy
Consider data memory allocation
Variable locations (private SPM, remote SPM or external memory) are computed at compile time
If two variables share the same space, they are guaranteed to have disjoint lifetime
No reloading cost required

Motivation
Why shared bus makes it different ?
Bus slots for other cores(150 cycles)
m m’
Total delay for ref(m) = (150 + LAT) * freq(m)Total delay for ref(m’) = LAT * freq(m’)
150 * freq(m) > LAT * (freq(m’) – freq(m)) (m likely to reduce WCET more than m’)
this core slot
this core slot
Because shared bus delay is variable
freq(m’) > freq(m)

Motivation Why shared SPM space makes it different ?
SPM - 0 SPM - 1
Not so critical task
An SPM allocator unaware of shared scratchpad space cannot allocate memory blocks accessed in critical tasks to SPM-1
Critical task
Allocator’s View

Motivation Why shared SPM space makes it different ?
SPM - 0 SPM - 1
Critical task
Not so critical task
Allocator’s View
Exploiting shared scratchpad space, more performance can be obtained as the critical tasks can also allocate in SPM-1

Allocation framework
Bus-delay awareWCET analysis
Task WCET
Total delay(bus delay + memory latency)
to access variables along WCEP
WCRT analysis
Variable lifetime and critical path
information
Bus aware SPM allocator
Enough space?
SPM allocation decision
Yes
OptimizedWCRT
No
Application task graph

Allocation framework
Bus-delay awareWCET analysis
Task WCET
Total delay(bus delay + memory latency)
to access variables along WCEP
WCRT analysis
Variable lifetime and critical path
information
Bus aware SPM allocator
Enough space?
SPM allocation decision
Yes
OptimizedWCRT
No
Application task graph

Bus delay aware WCET analysis
Shared bus introduces variable latency for each memory access.
Our previous work approximates the total delay incurred by a static memory reference.
This delay is used as a metric by the greedy SPM allocator.

Allocation framework
Bus-delay awareWCET analysis
Task WCET
Total delay(bus delay + memory latency)
to access variables along WCEP
WCRT analysis
Variable lifetime and critical path
information
Bus aware SPM allocator
Enough space?
SPM allocation decision
Yes
OptimizedWCRT
No
Application task graph

WCRT analysis
t3t2
t4
t1(1)
(2) (2)
(1)
Assigned core
Task graph
Task lifetime : [eStart, lFinish]
eStart(t1) = 0eStart(t4) >= eFinish(t2)eFinish(t4) >= eFinish(t3)
eFinish = eStart + BCET
lStart(t4) >= lFinish (t2)lStart(t4) >= lFinish (t3)
t3 can be preempted by t2
lFinish (t3) = lStart(t3) + WCET(t3) + WCET(t2)+ 2 * BUS_SLOT_LENGTH
Computed WCRT = lFinish(t4)
Earliest timecomputation
Latest timecomputation
All tasks have the same period –the period of the entire task graph

Allocation framework
Bus-delay awareWCET analysis
Task WCET
Total delay(bus delay + memory latency)
to access variables along WCEP
WCRT analysis
Variable lifetime and critical path
information
Bus aware SPM allocator
Enough space?
SPM allocation decision
Yes
OptimizedWCRT
No
Application task graph

Bus aware SPM allocator
Using WCRT analysis we also obtain the lifetime information of each variable
Interference graph Each node is a variable accessed in some task An edge exists between two nodes if their lifetimes interfere
Nodes have weights Higher the total access delay (including bus delay), higher the
weight Higher the weight if accessed in critical path

Bus aware SPM allocatorM1 = 10C1 = 30
C2 = 55
C3 = 10M2 = 10
N = 10
N = 5
C4 = 10M1 = 10
Task T1 in PE-0
C5 = 40
C6 = 55
N = 10
M3 = 10
M3 = 10
Task T2 in PE-1
Assume M1, M2 and M3 are only memory accesses
Critical Task = T1M2 suffers more delay to access than M1.Reduce WCRT by reducing the WCRT of critical task T1

Bus aware SPM allocator
M1 = 10C1 = 30
C2 = 55
C3 = 10M2 = 10
N = 10
N = 5
C4 = 10M1 = 10
Task T1 in PE-0
C5 = 40
C6 = 55
N = 10
M3 = 10
M3 = 10
Task T2 in PE-1
SPM-0
SPM-1
M1 M2
M3
[0,690]
[455, 480]
[375,650]
M2
t = 530
t = 480
T1T2
WCRT = 530 cycles
(empty)
Allocation (iteration 1)
Critical Task = T1
Reduce WCRT by reducing the WCRT of critical task T1
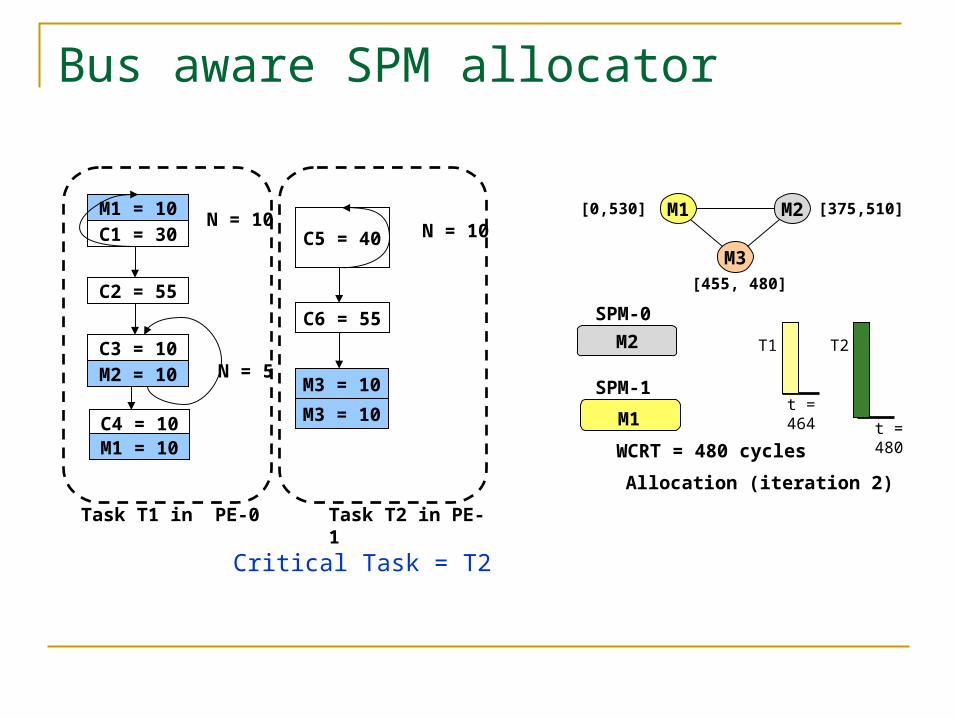
Bus aware SPM allocator
M1 = 10C1 = 30
C2 = 55
C3 = 10M2 = 10
N = 10
N = 5
C4 = 10M1 = 10
Task T1 in PE-0
C5 = 40
C6 = 55
N = 10
M3 = 10
M3 = 10
Task T2 in PE-1
Critical Task = T2
SPM-0
SPM-1
M1 M2
M3
[0,530]
[455, 480]
[375,510]
M2
t = 464
T1 T2
WCRT = 480 cycles
M1 t = 480
Allocation (iteration 2)

Bus aware SPM allocator
M1 = 10C1 = 30
C2 = 55
C3 = 10M2 = 10
N = 10
N = 5
C4 = 10M1 = 10
Task T1 in PE-0
C5 = 40
C6 = 55
N = 10
M3 = 10
M3 = 10
Task T2 in PE-1
M2 and M3 have disjoint lifetimes, allocate same space
SPM-0
SPM-1
M1 M2
M3
[0,464]
[455, 480]
[405,450]
(M2, M3)
t = 464 t = 463
T1 T2
WCRT = 464 cycles
M1
Allocation (iteration 3)

Experimental evaluation
Two real world applications An unmanned aerial vehicle (UAV) controller (papabench) A fragment of an in-orbit spacecraft software (Debie)
Compare WCRT improvement with different SPM size (default: 5% of total data size) Bus slot length (default: 50 cycles to each core) Remote SPM latency (default: 4 cycles)
Compare improvement with bus unaware SPM allocation

WCRT Impr. w.r.t. SPM size
MIS = SPM allocation using our framework
NOBUS = Bus unaware SPM allocator
Improvement over bus unaware allocator = 50%

WCRT impr. w.r.t. bus slot length
Average improvement = 52%

Worst case vs average case
SIM(MIS) - Average case improvement
MIS - Worst case improvement

Allocation framework
Bus-delay awareWCET analysis
Task WCET
Total delay(bus delay + memory latency)
to access variables along WCEP
WCRT analysis
Variable lifetime and critical path
information
Bus aware SPM allocator
Enough space?
SPM allocation decision
Yes
OptimizedWCRT
No
Application task graph

Allocation framework
Bus-delay awareWCET analysis
Task WCET
Total delay(bus delay + memory latency)
to access variables along WCEP
WCRT analysis
Variable lifetime and critical path
information
Bus aware SPM allocator
Enough space?
SPM allocation decision
Yes
OptimizedWCRT
No
Application task graph
Analysisof different
bus arbitration policies

Summary
We have proposed an SPM allocation framework for MPSoCs
Our goal is to reduce the worst case response time (WCRT) of an application
We consider variable bus delays in SPM allocation
Currently, we have the model for TDMA bus only, but the SPM allocation framework can be used for different types of bus arbitration policies







