

WWW.LEDS-PROJEKT.DE
STREAMING-BASED TEXT MINING USING DEEP LEARNING AND SEMANTICS
MARTIN VOIGT / ONTOS
AGENDA
Use CasesLessons Learned
WILDHORNMINERMarket
Situation
What is required from project partners and customers?
What is good, what not and what are the next steps?
What are the others doing?
How looks Ontos’ approach of a flexible text mining by using Deep Learning?
How to analyze texts from various sources and interlink with existing knowledge graphs?
12. September 20162

USE CASES
What is required from project partners and customers?
12. September 20163

USE CASES FROM LEDS
• Content Augmentation in E-Commerce• Product descriptions imported from various sources as usually unstructured text
• Much manual work is resource consuming and expensive
http://www.walmart.com/ip/The-Revenant-Blu-ray-Digital-HD/5012927712. September 20164

USE CASES FROM CUSTOMERS
• Brand or competitor monitoring• What are the people or journalists writing about my brand?
• What are my competitors doing? How is the market changing?
Monitoring of
web sites
news feeds
social media channels
…
Link with
reports
CRM
Open data
…
12. September 20166
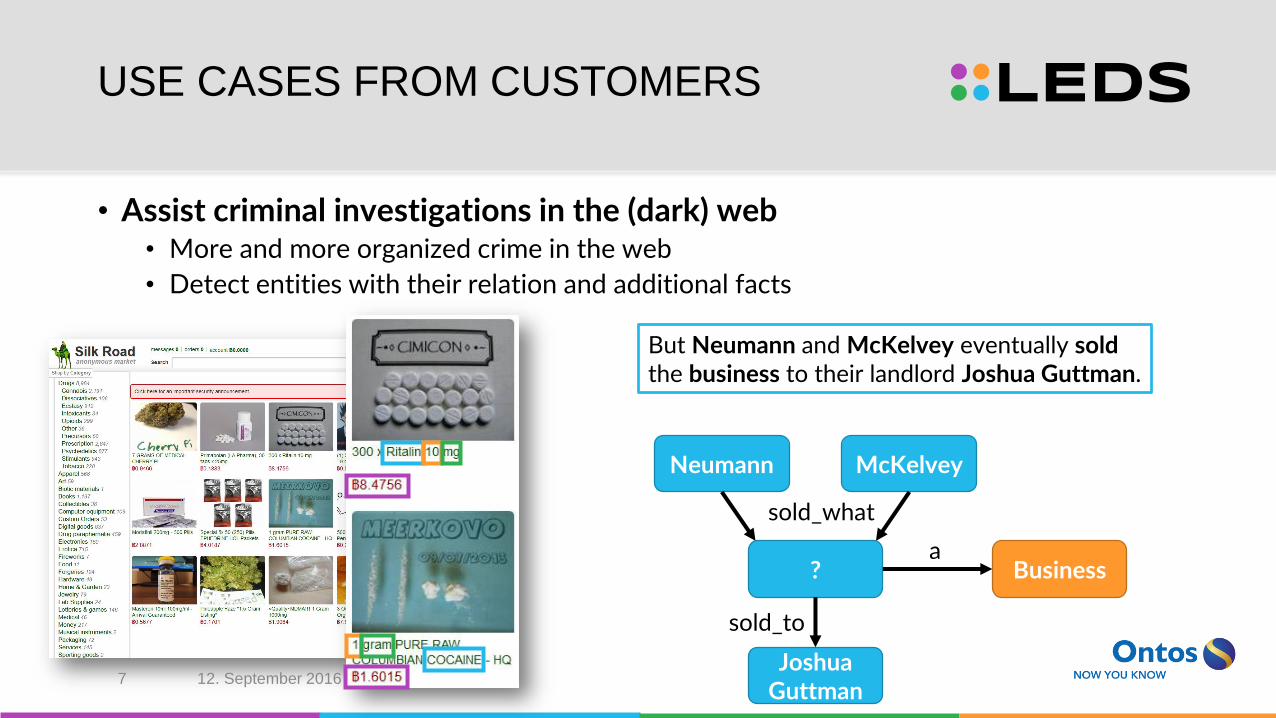
USE CASES FROM CUSTOMERS
• Assist criminal investigations in the (dark) web• More and more organized crime in the web
• Detect entities with their relation and additional facts
But Neumann and McKelvey eventually sold the business to their landlord Joshua Guttman.
Neumann McKelvey
?
Joshua Guttman
Business
sold_what
sold_to
a
12. September 20167

MAIN REQUIREMENTS
• Detection and classification of entities, relations and facts with good F1
• Long, high quality texts vs. short texts with bad / missing grammar in multiple languages
• Training not by linguists but domain experts
• Flexible adaption to new domains and contexts
• Many different data sources
12. September 20168

MARKET SITUATION
What are the others doing?
12. September 20169

MARKET
• MarketsAndMarkets: NLP (all) for 2020• Market: $ 13,4 bn
• CAGR: ~ 18,4%
• ResearchMOZ: Text Analytics 2015-2019• CAGR: ~ 16,1%
• Transparency Market Research: Text Analytics 2016–2024• CAGR: ~ 17,6%
• Driving element: NLP-as-a-Service with CAGR of ~20,2%
http://www.marketsandmarkets.com/PressReleases/natural-language-processing-nlp.asp
http://www.researchmoz.us/global-natural-language-processing-market-2015-2019-report.html
http://www.transparencymarketresearch.com/pressrelease/global-text-analytics-market.htm
12. September 201610

MARKET
• ResearchAndMarkets: 2016 Top 10 Information and Communication Technologies• 7. Natural Language Processing (NLP)
• Increasing Demand for Automation Drives Growth• Funding on the Rise - Start-ups Driving Key Innovations for NLP Applications• High Acceptance of Technology enables the US to Remain on the Top
• Gartner‘s Top 10 Strategic Technology Trends für 2016• 4 - Information of Everything:
• Access to heterogeneous data sources• (Semantic) Linking of data items
• 5 - Advanced Machine Learning:• Deep Learning and Neural Network for NLP
http://www.researchandmarkets.com/research/vd8fr9/2016_top_10
12. September 201611
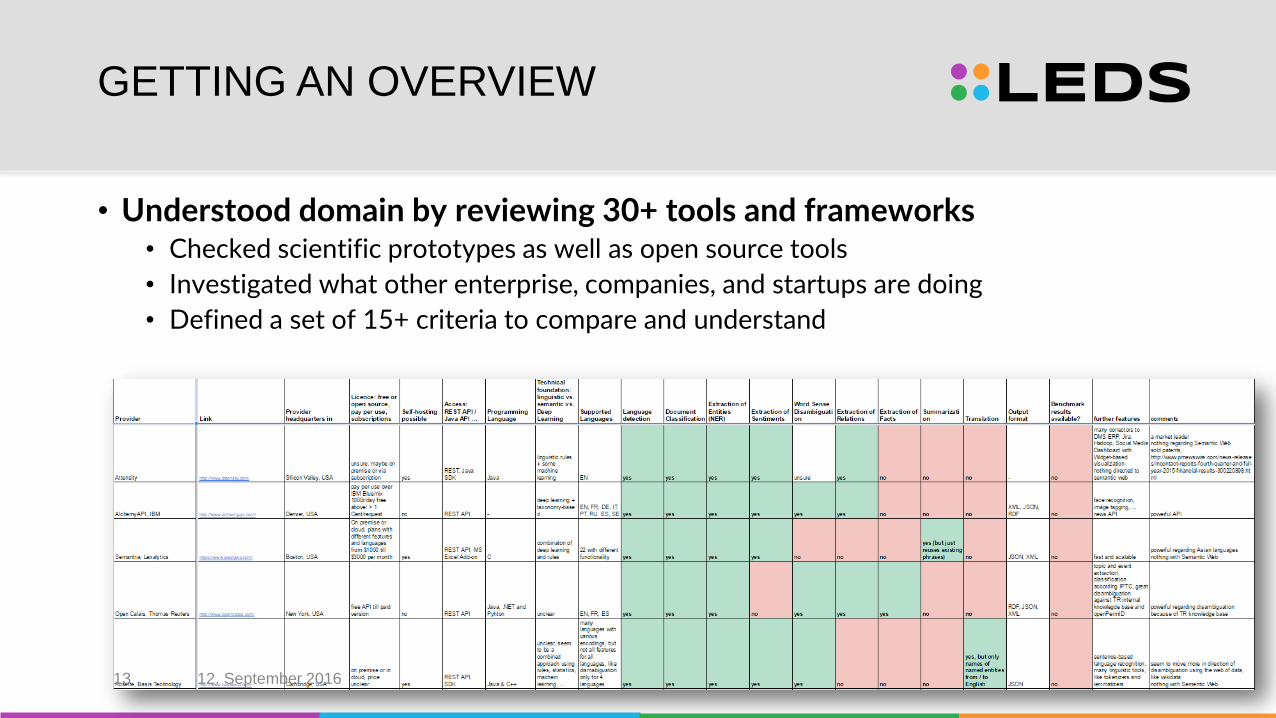
GETTING AN OVERVIEW
• Understood domain by reviewing 30+ tools and frameworks• Checked scientific prototypes as well as open source tools
• Investigated what other enterprise, companies, and startups are doing
• Defined a set of 15+ criteria to compare and understand
12. September 201613

GETTING AN OVERVIEW
• Understood domain by reviewing 30+ tools and frameworks
• Findings• Startups and huge enterprises usually stick to Deep Learning (DL) high flexibility
• Some existing companies loss market share, e.g., Attensity
• Market saturation in U.S., only less companies in Europe (5)
• More and more NLP-as-a-Service
• Only a few use RDF data, e.g., for output or disambiguation (8)
• Only 8 tools could extract relations and facts
• Only 9 open source tools with available benchmarks
12. September 201614
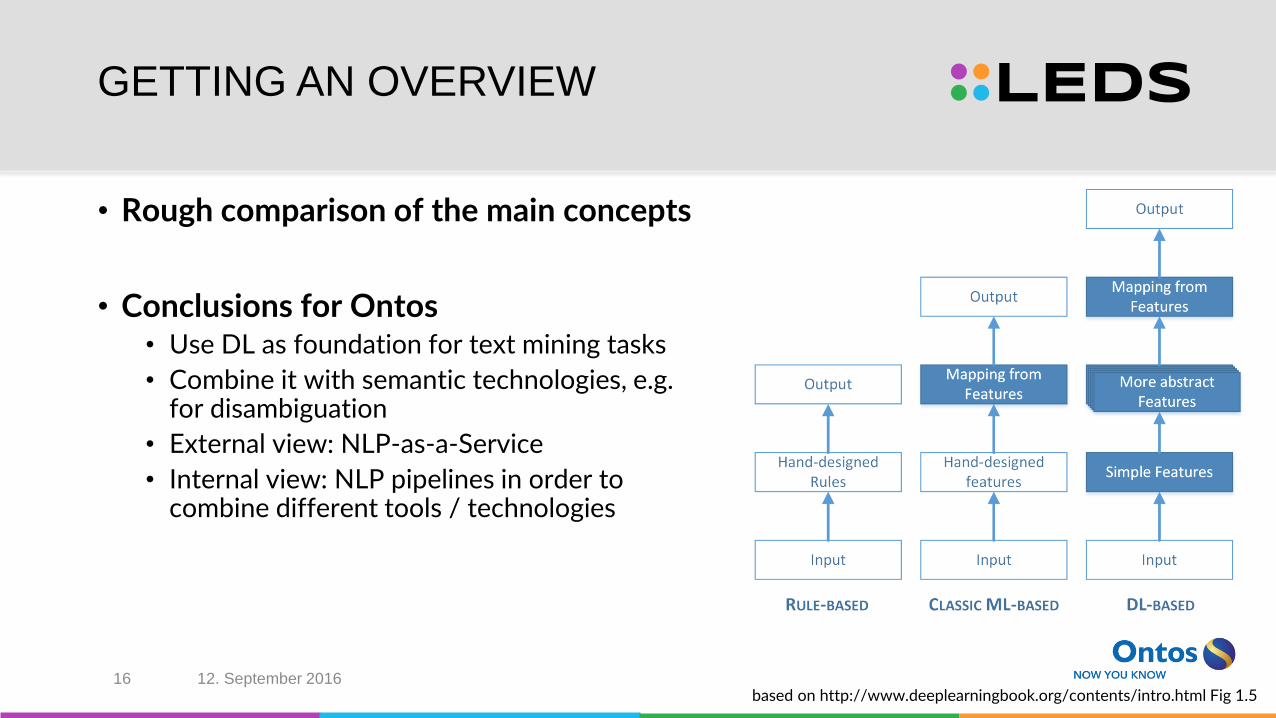
GETTING AN OVERVIEW
• Rough comparison of the main concepts
• Conclusions for Ontos• Use DL as foundation for text mining tasks
• Combine it with semantic technologies, e.g. for disambiguation
• External view: NLP-as-a-Service
• Internal view: NLP pipelines in order to combine different tools / technologies
based on http://www.deeplearningbook.org/contents/intro.html Fig 1.512. September 201616

MINER
How looks Ontos’ approach of a flexible text mining by using Deep Learning?
12. September 201617

MINER - OVERVIEW
Language model generated from Corpora
Model as input for supervised step
Supervised Model
Domain or task specific model for sequence labeling
Trained on specific texts by domain experts
Large collection of texts in a given language or “dialect”, e.g. Social Media / Twitter
Large text corpora Unsupervised Model
12. September 201618

MINER – CORPUS CREATION
• 1 corpus per language / dialect required
• the larger and more heterogeneous the better get and model more contexts for words
• Sources: Common Crawl, Wikipedia, news feeds, domain specific texts, Twitter, …
12. September 201619
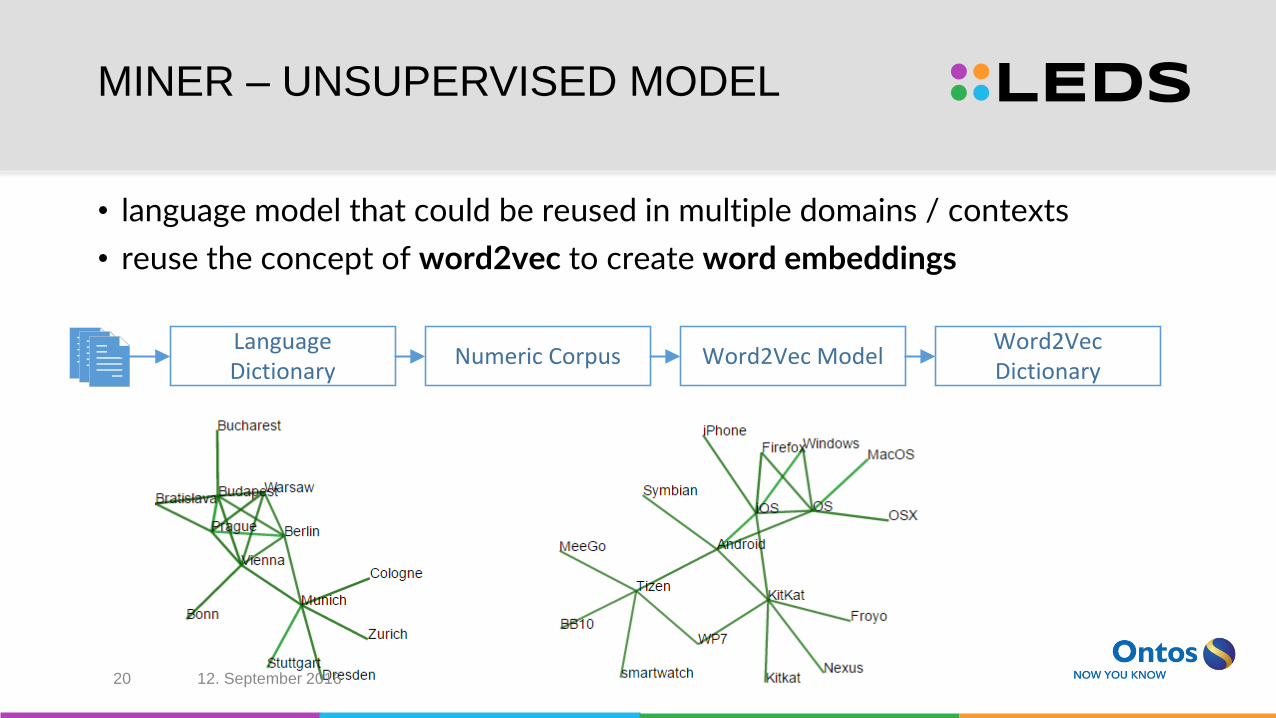
MINER – UNSUPERVISED MODEL
• language model that could be reused in multiple domains / contexts
• reuse the concept of word2vec to create word embeddings
Language Dictionary
Word2Vec ModelWord2Vec Dictionary
Numeric Corpus
12. September 201620

MINER – SUPERVISED MODEL
• Sequence labeling task• use a bi-directional LSTM
(BLSTM)
• Gated Recurrent Unit (GRU) as specialized LSTM
• Output layer• join and normalize
• classification
LEDS is a research project
Word Embeddings
GRU GRU GRU GRU GRU
GRU GRU GRU GRU GRU
Forward GRU
Backward GRU
OUT OUT OUT OUT OUTOutput Layers
0
0
Output
Textual Input
12. September 201621

MINER – IMPLEMENTATION
• Torch framework• matured, efficient GPU support, good packages for neural networks, …
• Scripting with Lua language
• Service implementation with Go because of great integration with Lua
• Integrated in Ontos Eiger workbench
12. September 201622

• Create new “projects” ad-hoc
• Reuse pre-labeled corpora
• Free definition of entity types as required for domain
MINER – IMPLEMENTATION
12. September 201623
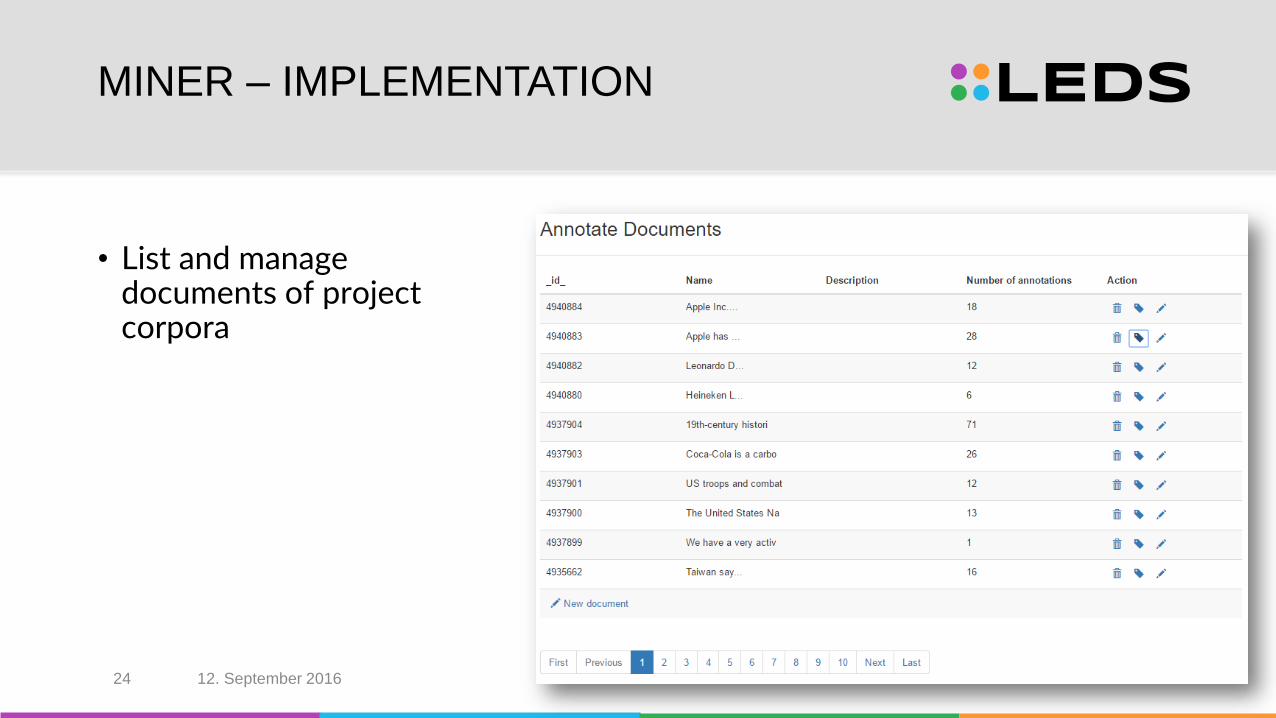
• List and manage documents of project corpora
MINER – IMPLEMENTATION
12. September 201624

• Double-check and annotate new labels
MINER – IMPLEMENTATION
12. September 201625

MINER – IMPLEMENTATION
• English News• ~ 400 English texts from CoNLL 2003 and news feeds
• 5 entity types defined and manually annotated by 2 experts
• 1st value: correct start of entity
• 2nd value: correct end of entity
Class: Person Organization Product Location EventPer class F1:....... 0.976 | 0.990 0.932 | 0.962 0.873 | 0.942 0.958 | 0.976 0.891 | 0.928Per class Recall:... 0.974 | 0.988 0.936 | 0.953 0.845 | 0.926 0.965 | 0.980 0.870 | 0.913Per class Precision: 0.978 | 0.992 0.928 | 0.971 0.902 | 0.959 0.951 | 0.973 0.914 | 0.944
http://www.cnts.ua.ac.be/conll2003/ner/
12. September 201626

MINER – IMPLEMENTATION
• English Twitter• ~ 2400 tweets from Twitter NLP tools / A. Ritter 2011
• 5 entity types defined, some are combined from original source
Class Person Organisation Place Product ThingPer class F1:....... 0.797 | 0.883 0.548 | 0.141 0.725 | 0.669 0.195 | 0.207 0.409 | 0.551Per class Recall:... 0.769 | 0.852 0.487 | 0.085 0.696 | 0.647 0.120 | 0.129 0.337 | 0.529Per class Precision: 0.828 | 0.918 0.627 | 0.414 0.756 | 0.693 0.516 | 0.514 0.520 | 0.574
https://github.com/aritter/twitter_nlp
12. September 201627

WILDHORN
How to analyze texts from various sources and interlink with existing knowledge graphs?
12. September 201628

NLP PIPELINES
• Problem: How to efficiently connect various tools in the data stream?
• Sources• RSS feed reader, crawler, Twitter, FTP servers, …
• Analytics• 1 MINER instance per language
• Disambiguate and link to Knowledge graphsor taxonomies
• Sinks• RDF stores, Apache Solr, HDFS, Apache Cassandra, …
http://www.computernewsme.com/wp-content/uploads/2011/06/Cable-clutter.jpg12. September 201629

NLP PIPELINES
• Best practices – by LinkedIn• http://www.confluent.io/blog/stream-data-platform-1/
• Apache Kafka!
12. September 201630

WILDHORN NLP PIPELINE
Message Broker
Apache Spark Apache Kafka / Confluent
Schema Registry
REST APITechnical Foundation:
Twitter Extractor
RSS Feed CrawlerREST Proxy
Log File Extractor
Web / Darknet Crawler
Taxo Extractor
MINER
AGDISTIS
Named Entity Extraction &
Disambiguation
ENS
RDF Serializer QUAD
NoSQL Serializer Apache Cassandra
Solr Serializer Apache Solr
12. September 201632
Document Classification
Sentiment Analysis

WILDHORN NLP PIPELINE
• Implementation• Apache Spark 1.6 & Confluent 3.0
• Use of Spark Jobserver to manageApache Spark applications
• Ontos Eiger backend ready
• First tests• Simple Mesos cluster with 3 servers
• ~ 1000 message / sec with 1 broker without MINER analytics: no data problem
• Problem: 1 MINER instance currently scales up to 100 message / sec
Kafka Pipeline
Par
t
Producers
Consumers
Topic
Schema
Par
t
Producers
Consumers
Topic
Schema
...https://github.com/spark-jobserver/spark-jobserver
12. September 201633

WILDHORN NLP PIPELINE
https://github.com/spark-jobserver/spark-jobserver
12. September 201634

LESSONS LEARNED
What is good, what not and what are the next steps?
12. September 201635

CURRENT STATUS
• Detection and classification of entities, relations and facts with good F1
• Long, high quality texts vs. short texts with bad / missing grammar in multiple languages
• Training not by linguists but domain experts
• Flexible adaption to new domains and contexts
• Many different data sources
12. September 201636

LESSONS LEARNED
• Neural networks / deep learning provide great concepts & frameworks for flexible, high quality NLP tasks
• Apache Kafka / Confluent Platform in combination with Apache Spark good foundation for data streaming and processing
• Disambiguation and linking of entities to taxonomies and Knowledge Graphs via Semantic Web technologies is a core contribution for data integration
• Hard to find employees with Deep Learning skills
12. September 201637

NEXT STEPS
• Try letter-trigram word hashing to overcome out of dictionary problem of word2vec algorithm
• Relation and fact extraction in MINER
Adam Neumann is the CEO of super-hot office rental company WeWork, the most valuable startup in New York City.
PersonFirst Name
Sentiment
Entity Type
Adam super-hot
Entity
Adam Neumann
Legend Relation Relation Type
firstName1
firstName WhoHow
positive1
positiveSentiment
WeWork
Organization
ThingWhatHow
a has
A1 A2 A3 A4
Annotation
https://arxiv.org/abs/1608.06757
12. September 201638

NEXT STEPS
• Define NLP pipelines in frontend
• Make MINER scalable
• Usable search interface
• Benchmark with GERBIL
12. September 201639
Q & A
Dr. Martin VoigtManaging Director
Ontos GmbHD-04319 Leipzig
M: +49 178 40 222 58E: [email protected]: m_a_r_t_i_n
12. September 201640







