

Towards Efficient Learning of Neural Network Ensembles from Arbitrarily Large Datasets
Kang Peng, Zoran Obradovic and Slobodan Vucetic
Center for Information Science and Technology, Temple University303 Wachman Hall, 1805 N Broad St, Philadelphia, PA 19122, USA

Agenda
Introduction Motivation Related Work Proposed Work Experimental Evaluation
Datasets Experimental Setup Results
Conclusions

Introduction
More and more very large datasets become available Geosciences Bioinformatics Intrusion detection Credit fraud detection …
Learning from arbitrarily large datasets is one of the next generation data mining challenges

The MISR Data – a Real Life Example
9 cameras from different angles
4 spectral bands at each angle
Global coverage time of every 9 days
Average data rate 3.3 Megabits per second
3.5 TeraBytes per year
MISR - Multi-angle Imaging SpectroRadiometer, launched into orbit in December 1999 with the Terra satellite, for studying the ecology and climate of Earth

Agenda
Introduction Motivation Related Work Proposed Work Experimental Evaluation
Datasets Experimental Setup Results
Conclusions

Feed-Forward Neural Networks
Feed-forward Neural Network (NN) is a powerful machine learning / data mining technique
Universal approximator – applicable to both classification and regression problems
Learning – weights adjustments (e.g. back-propagation)
y1
x1
x2
1 1
y2
y3
y4biasbias
Inputs OutputsHidden Layer
Output Layer
weights weights
x3

Learning a single NN from an arbitrarily large dataset could be difficult due to The unknown intrinsic complexity of the learning task
Difficult to determine appropriate NN architecture Difficult to determine how much data is necessary for sufficient le
arning
The computational constraints
On the other hand, learning an ensemble of NNs would be advantageous if Each component NN needs only a small portion of data Accuracy is comparable to single NN from all data
Motivation

Motivation
Need: To learn an ensemble of optimal accuracy but with fewest computational effort, one still has to decide Model complexity
The number (E) of component NNs The number (H) of hidden neurons for component NNs
Training sample sizes (N) for component NNs
Open problem: No efficient algorithm exists to find an exact solution (i.e. optimal combination of E, H and N) even if the component NNs are required to have same H and N
Proposed: An iterative procedure that learns near-optimal NN ensembles with reasonable computational e
ffort Adapts to the intrinsic complexity of underlying learning task

Agenda
Introduction Motivation Related Work Proposed Work Experimental Evaluation
Datasets Experimental Setup Results
Conclusions

NN Architecture Selection
Trial-and-error (manual) procedure Training one model with each architecture Trying as many architectures as possible and selecting
the one with highest accuracy Ineffective and inefficient for large datasets
Constructive learning Starting with a small network and gradually adding
neurons as needed Examples
The tiling algorithm The upstart algorithm The cascade-correlation algorithm
Suitable for small datasets

NN Architecture Selection
Network pruning Training a larger-than-necessary NN and then pruning redundant
neurons/weights Examples
Optimal Brain Damage Optimal Brain Surgeon
Suitable for small and medium datasets
Evolutionary algorithms Population-based stochastic search algorithms More efficient in searching NN architecture space Applicable to learning rules selection as well as network training
(weight adjusting) Inefficient for large datasets

Progressive Sampling
To achieve near-optimal accuracy but with significantly less data than if using the whole dataset
Originally proposed for decision tree learning It builds a series of models with increasingly l
arger samples until accuracy no longer improves
The sample sizes follow a sample schedule
S = {n1, n2, …, nk } where ni is sample size for the i-th model
Geometric sampling schedule is efficient in determining nmin
ni = n0* ai ,
where constant n0 is positive integer and a>1sample size
accu
racy
nmin nall
Progressive sampling may not be suitable for NN learning The learning algorithm should be able to adjust model complexity as samples
grow larger – this is not true for back-propagation algorithm

Agenda
Introduction Motivation Related Work Proposed Work Experimental Evaluation
Datasets Experimental Setup Results
Conclusions

An Iterative Procedure for Learning NN Ensembles from Arbitrarily Large Datasets
The idea: Building a series of NNs such that Each NN is trained on a sample much smaller than
the whole dataset The sample sizes for individual NNs are increased
as needed The numbers of hidden neurons for individual NNs i
ncrease as needed The final predictor is the best one of all possible en
sembles constructed from the trained NNs

The Proposed Iterative Procedure
a) H – number of hidden neurons
b) N – number of training sample size
c) The best accuracy of all possible ensembles from trained NNs, estimated on an independent set
d) Could be main memory (maximal sample size ) or cumulative execution time
Accuracyc significantly improved?
Converged OR resource limitsd reached?
Increase H or N
Identify the best ensemble as the final predictor
No
No
Yes
Yes
Train a NN of H hidden neurons with sample S
Draw a sample S of size N from dataset D
Initialize Ha and Nb to certain small values (e.g. 1 and 40)

The Use of Dataset D
Dataset D is divided into 3 disjoint subsets DTR – for training NN
DVS – for accuracy estimation during learning
DTS – for accuracy estimation of the final predictor
To draw a sample of size N from DTR
Assumption - data points are stored in random order Sequentially take N data points Rewind if the end of dataset is encountered

Accuracy Estimation during Learning
Accuracy ACCi (for i-th iteration) is estimated on the independent subset DVS as accuracy of the best possible ensemble from i trained NNs
To determine if ACCi is significantly higher than ACC
i-1, test condition ACCi > ACCi-1 AND CIi-1 CIi = Here,
ACCi is accuracy for i-th iteration,
CIi is the 90% confidence interval for ACCi
calculated as ACCi1.645SE(ACCi),
where SE(ACCi) is standard error of ACCi

Accuracy Standard Error Estimation
For classification problems
For regression problems Draw 1000 bootstrap samples from DVS
Calculate R2 on each bootstrap sample SE(ACCi) = standard deviation of these R2 values
VS
iii D
ACCACCACCSE
1)(

Adjusting Model Complexity and Sample Size
If ACCi is NOT significantly higher than ACCi-1 If ACCi-1 is NOT significantly higher than ACCi-2
If already increased N in the i-1 th iteration
then increase H by a pre-defined amount IH (IH is positive integer) If already increased H in the i-1 th iteration
then multiply N by a pre-defined factor FA (FA > 1)
If ACCi-1 is significantly higher than ACCi-2
(i.e. neither H nor N is increased in the i-1 th iteration)
then multiply N by a pre-defined factor FA (FA > 1)

Convergence Detection
In each (i-th) iteration, test condition
where C is a small positive constant, and
k ranges from i-4 to i
ck
k
ACC
ACC )(mean
)(eviationstandard_d

Agenda
Introduction Motivation Related Work Proposed Work Experimental Evaluation
Datasets Experimental Setup Results
Conclusions

The Waveform Dataset
Synthetic classification problem From UCI Machine Learning Repository 3 classes of waveforms 21 continuous attributes Originally reported accuracy of 86.8%
with an Optimal Bayes classifier
100,000 examples were generated for each class |DTR| = 80,000, |DVS| = 10,000, |DTS| = 10,000

The Covertype Dataset
Real-life classification problem From UCI Machine Learning Repository 7 classes of forest cover types 44 binary and 10 continuous attributes
40 binary attributes (for soil type) were transformed into 7 continuous attributes
Originally reported accuracy of 70% obtained using a neural network classifier
581,012 examples |DTR| = 561,012, |DVS| = 10,000, |DTS| = 10,000

The MISR Dataset
Real-life regression problem From NASA 1 continuous target
retrieved aerosol optical depth
36 continuous attributes constructed from raw MISR data
45,449 examples Retrieved over land for the 48 contiguous United States during a 15-
day period of summer 2002 |DTR| = 35,449, |DVS| = 5,000, |DTS| = 5,000

Experimental Setup
The procedure was repeated 50 times on each dataset Stopped when convergence was reached or the sample size
exceeded a pre-defined upper limit Nmax = 20,000
Parameters IH = 4, FA = 1.5 and C = 0.0025 selected based on preliminary experiments on Waveform dataset
For comparison purpose, “simple” NN ensembles of known parameters were also built Trained and tested on DTR and DTS, respectively Ensemble size (E) {1, 5, 10} Number of hidden neurons (H) {1, 5, 10, 20, 40, 80} Sample size (N) {200, 400, 800, 1600, …, 204800}

Evaluation Criteria
Prediction accuracy Classification – percentage of correct classifications Regression – percentage of variances in target variable that can be
explained by the regression model (coefficient of determination R2)
Computational learning cost Ensembles learnt with the proposed procedure: i=1~E Hi*Ni
where E is ensemble size, Hi is # of hidden neurons for i-th NN, and Ni is training sample size for i-th NN
“Simple” ensembles: H*N*E (since Hi = H and Ni = N for all i = 1~E)
Scatter plot prediction accuracy vs. computational learning cost

Results Summary
For Waveform and MISR datasets The resulting ensembles were comparable to the optimal
solution in terms of accuracy and computational effort
For Covertype data The resulting ensembles were slightly inferior to the opti
mal solution in terms of accuracy, but with near one order of magnitude smaller computational effort
The optimal solution refers to the optimal combination of (E, H, N), assuming exact same component NNs

Results – Waveform
103
104
105
106
107
108
81
82
83
84
85
86
87
H*NS*N
E
acc
ura
cy (
%)
proposed proceduresingle NNensemble of 5 NNensemble of 10 NN
H*N*Ei=1~EHi*Ni or H*N*E

Results – Covertype
103
104
105
106
107
108
60
65
70
75
80
H*NS*N
E
acc
ura
cy (
%)
proposed proceduresingle NNensemble of 5 NNensemble of 10 NN
i=1~EHi*Ni or H*N*E

Results – MISR
103
104
105
106
107
108
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
H*NS*N
E
R2
proposed proceduresingle NNensemble of 5 NNensemble of 10 NN
i=1~EHi*Ni or H*N*E
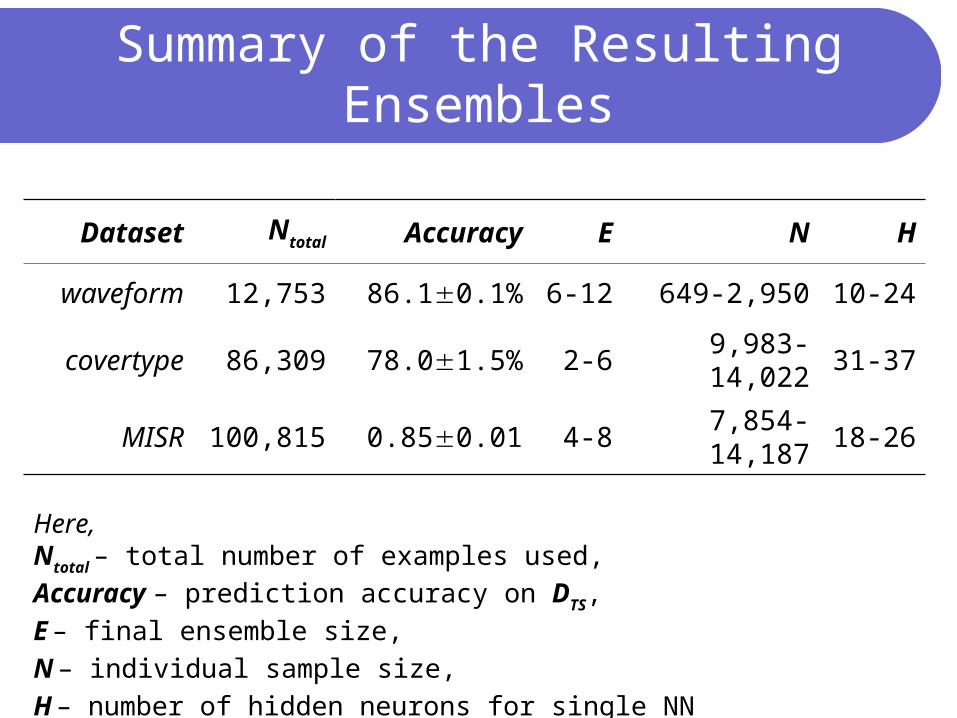
Summary of the Resulting Ensembles
Dataset Ntotal Accuracy E N H
waveform 12,753 86.10.1% 6-12 649-2,950 10-24
covertype 86,309 78.01.5% 2-6 9,983-14,022 31-37
MISR 100,815 0.850.01 4-8 7,854-14,187 18-26
Here,Ntotal – total number of examples used,
Accuracy – prediction accuracy on DTS,
E – final ensemble size,
N – individual sample size,
H – number of hidden neurons for single NN

Agenda
Introduction Motivation Related Work Proposed Work Experimental Evaluation
Datasets Experimental Setup Results
Conclusions

Conclusions
It can learn ensembles of near-optimal accuracy with moderate computational effort
It is adaptive to the inherent complexity of the datasets
It is different from progressive sampling Automatically adjusts model complexity Utilize previously built models to guide the learning
process
A cost-effective iterative procedure was proposed to learn NN ensembles from arbitrarily large datasets
Thanks!







