

Two Case Studies of Adaptive AI
in Team-Based First
Person Shooter (FPS) Games
Héctor Muñoz-Avila
Dept. of Computer Science & Engineering
Lehigh University

Outline
� Lehigh University
� The InSyTe Laboratory
� Introduction
� Adaptive Game AI
� Domination games in Unreal Tournament©
� Adaptive Game AI with Hierarchical Task Networks� Adaptive Game AI with Hierarchical Task Networks
� Adaptive Game AI with Reinforcement Learning
� Empirical Evaluation
� Final Remarks

LEHIGH
UNIVERSITY

The University
Engineering
Arts & Sciences
Business
Education
Faculty440 full-time
Grad. students2,000+
Undergraduates4,500+
3 Campuses1,600 acres
mountain, woods

Computer Science
& Engineering
� Ph.D. and Masters programs
� Computer Science
� Computer Engineering
� Faculty
� 16 tenured / tenure-track faculty
� Graduate Students� Graduate Students
� >35+ PhD students
� >35+ MS students
Engineering College
top 20% of US PhD Engr schools
University
top 15% of US National Univs.
Home of the
Engineering College

CSE Research Areas
Artificial intelligence
Bioinformatics
Computer architecture
Database systems
Pattern recognition &
computer vision
Robotics
Semantic webDatabase systems
Enterprise information
systems
Electronic voting
Game AI design
Graphics
Networking
Semantic web
Software engineering
Web search

The InSyTe Laboratory
� Basic research in AI. Interest: the intersection of case-
based reasoning (CBR), planning, and machine
learning
TheoryComplexity of plan adaptation/learning
Expressiveness of learned planning constructs
Learning Systems
Graduate
Teaching
Framework for
analysis of case
reuse
Learning
constructs of
varying degrees
of abstraction
AI Game
Programming
Intelligent Decision
Support Systems
Automated
Planning
Problem-solving
by reusing cases
and learned
constructs

Introduction
Game AI, Unreal Tournament

Adaptive Game AI
� Game AI: algorithms controlling the
computer opponents
� Example: Any commercial computer
game (e.g., Unreal Tournament)
Adaptive Game AI: computer � Adaptive Game AI: computer
opponent changes strategies and
tactics according to the environment
� Example: Chess computer players

Adaptive Game AI and Learning
� Why learning?
� Combinatorial explosion of possible situations
� Tactics (e.g., competing teams tactics)
� Game worlds (e.g., map where the game is played)
� Game modes (e.g., domination, capture the flag)
� Little time for development
� Why not learning?
� Difficult to control and predict Game AI
� Difficult to test

Adaptive Game AI and Games
Without Learning With Learning
Static Dynamic Static Dynamic
Symbolic Simple
scripts
planning Trained
VS
Decision
Tree
Sub-
Symbolic
Stored
NNs
Fuzzy
Logic
RL
offline
RL
online
Our contribution: Dynamic Game AI for Team based
First-Person Shooters

Unreal Tournament©
� Online FPS developed by Epic Games Inc.
� Various gameplay modes including team deathmatch and
domination games
� Provides a client-server
architecture for controlling
bots
� High-level script
language: UnrealScript
(Sweeney, 2004)

Application: UT Domination
Games
� A number of fixed domination
locations.
� When a team member steps into
one of these locations, the status
of the location changes to be
under the control of his/her team. under the control of his/her team.
� The team gets a point for every
five seconds that each
domination location remains
under the control of that team.
� The game is won by the first team
that gets a pre-specified amount
of points.

How is Programming of Game AI
currently done in most commercial
games?
� States
� Attack
� Chase
Attack
~E
ED
E
Use of Finite State Machines (FSMs)
� Chase
� Spawn
� Wander
� Events
� E: see an enemy
� S: hear a sound
� D: die
Spawn
Wander
~E
D
E
E
D
~S
ChaseS
S
D

Adaptive Game AI with
Hierarchical Task Networks
HTNBots (Hierarchical Task Network Bots)

Hierarchical Task Network (HTN)
Planning� Complex tasks are decomposed into simpler tasks.
task t1
task t2 task t3
� Seeks to decompose compound tasks into primitivetasks, which define actions changing the world
� Primitive tasks are accomplished by knowledge artifacts called operators
� The knowledge artifacts indicating how to decompose task into subtasks are called methods
task t2 task t3

Why HTN Planning (1)?
� HTN planning has been shown to be more expressive
than classical plan representations (Erol et al, 1994)
� Using methods and operators versus using operators
only
� Even for those domains in which HTN representations
can be translated into classical plan representations, a
much larger number of operators is required to represent
the HTN methods (Lotem & Nau, 2000)
� Fast planning through domain-configurable HTN
planners (SHOP system)

Why HTN Planning (2)?
� Hierarchical planning is natural in many domains
� Military planning
CINC
JCS / NCAStrategic
National
Tactical
Strategic
Theater
CINC
JTFOperational
Therefore, also
natural for many
computer games

Idea of HTNBots
� Use HTNs to generate team strategy. Use of hierarchical task network (HTN) planning techniques to lay out a grand strategy to accomplish gaming tasks
� Use FSMs to control individual bots. Use standard FSMs to allow the bots to react in highly dynamic environments while contributing to the grand task.
UT task: DominationUT task: Domination
Strategy:
secure most
locations
UT action: move Bot1 to
location B

Technical Difficulties of using an
HTN PlannerUT task: Domination
Strategy:
secure most
locations
UT action: move Bot1 to
1. Declarative language
for expressing
conditions is slow to
process
Solution to 1: use built-
in predicates to UT action: move Bot1 to
location B
2. Dealing with
contingencies while
Bots are executing
assigned tasks
in predicates to
represent conditions
Solution to 2: use Java
Bots to represent
actions (FSMs)

Data Flow to generate HTNs
(i.e., HTN Planning)
task
compound? Yes Select applicable
method
Method
library
Selected method’s
subtasks
method
UT Server
library
Evaluate method’s
preconditionsNo
Execute actionUT Bot
UT Bot …
Adaptive: if the situation changes a
new plan is generated on the fly


Video: UT Domination with HTN
Planning

But Planning is NOT more powerful
than FSMs
Pla
nnin
g O
per
ato
rs
•Patrol
�Preconditions:
No Monster
�Effects:
patrolled
•Fight
�Preconditions:Patrol Fight
Monster In Sight
FSM:
Pla
nnin
g O
per
ato
rs
�Preconditions:
Monster in sight
�Effects:
No Monster
No Monster
A resulting plan:
Patrolpatrolled
Fight
No MonsterMonster in sightNeither is
more
powerful
than the
other one

But Planning Gives More
Flexibility
� “Separates implementation from data” --- Orkin
inference knowledge
Pla
nnin
g O
per
ato
rs
•Patrol
�Preconditions:
Many potential plans:
Pla
nnin
g O
per
ato
rs �Preconditions:
No Monster
�Effects:
patrolled
•Fight
�Preconditions:
Monster in sight
�Effects:
No Monster
…
PatrolFightPatrolFightPatrolFightPatrolFight
PatrolFight
…

Adaptive Game AI with
Reinforcement Learning
RETALIATE (Reinforced Tactic Learning in Agent-
Team Environments)

Reinforcement Learning
� Agents learn behavior policies through rewards
and punishments
� Policy - Determines what action to take from a
given state
� Agent’s goal is to maximize some reward
� Maintains a “Q-Table”:
� Q-table: State × Action � value

Exploration vs. Exploitation
� Exploitation = Using old tactics that
worked before
� Exploration = Trying new tactics
For a state s
selects action
a such that:
maxaQ(s, a)
� At the start, the agent must explore,
but when should it stop exploring and
decide that it has the “best” tactic?
For a state s
randomly
selects an
action a

The RETALIATE Algorithm (1)
Controls two or more UT bots� Controls two or more UT bots
� Commands bots to execute actions through the
GameBots API
� The UT server provides sensory information about events in
the UT world and controls all the gameplay events
� Gamebots acts as a middleware between the UT server and
the Game AI
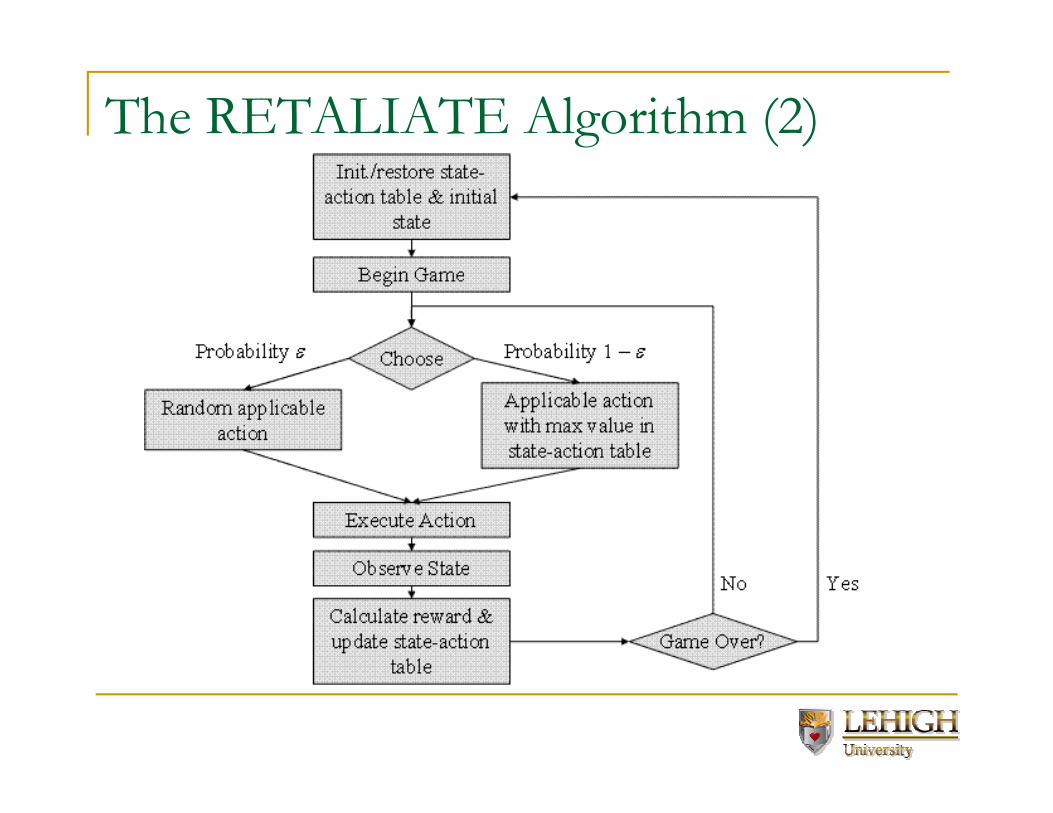
The RETALIATE Algorithm (2)

Initialization
• Game model:
� n is the number of domination points
� (Owner1, Owner2, …, Ownern)• Team 1
• Team 2
• …
• For all states s and for all actions a
•Q[s,a] 0.5
• Actions:
� m is the number of bots in team
� (goto1, goto2, …, gotom)
• …
• None
• loc 1
• loc 2
• …
• loc n

Choosing an action
•ε is set to 0.1
�So most of the times will pick the best action (exploitation)
�But sometimes it will try something different (exploration)

Rewards and Utilities
•U(s) = F(s) – E(s),
� F(s) is the number of friendly locations
� E(s) is the number of enemy-controlled locations
•R = U(s’) – U(s)
•Standard Temporal difference learning ([Sutton & Barto, 1998]):•Standard Temporal difference learning ([Sutton & Barto, 1998]):
� Q(s, a) ← Q(s, a) + α ( R + γ maxa’ Q(s’, a’) – Q(s, a))

Rewards and Utilities
•U(s) = F(s) – E(s),
� F(s) is the number of friendly locations
� E(s) is the number of enemy-controlled locations
•R = U(s’) – U(s)
•Standard Temporal difference learning ([Sutton & Barto, 1998]):•Standard Temporal difference learning ([Sutton & Barto, 1998]):
� Q(s, a) ← Q(s, a) + α ( R + γ maxa’ Q(s’, a’) – Q(s, a))
� “step-size” parameter α was set to 0.2
� discount-rate parameter γ was set to 1
�Thus, most recent state-reward pairs are considered
equally important as earlier state-reward pairs
�But will not necessarily converge to an optimal policy

Video: Initial Policy

Video: Learned Policy

Empirical Evaluation
Game AI, Unreal Tournament

The Competitors
Team Name Description
HTNBot HTN planning.
OpportunisticBot Bots go from one domination location to
the next. If the location is under the
control of the opponent’s team, the bot
captures it. captures it.
PossesiveBot Each bot is assigned a single domination
location that it attempts to capture and
hold during the whole game
GreedyBot Attempts to recapture any location that is
taken by the opponent
RETALIATE Reinforcement Learning

Summary of Results
� Against the opportunistic, possessive, and greedy control
strategies, HTNBots won all 3 games in the tournament.
� From early on HTNBots gain the upper hand
Against the opportunistic, possessive, and greedy control � Against the opportunistic, possessive, and greedy control
strategies, RETALIATE won all 3 games in the tournament.
� within the first half of the first game, RETALIATE
developed a competitive strategy.

Summary of Results:
HTNBots vs RETALIATE (Round 1)
40
50
60
RETALIATE
HTNbots
Difference
-10
0
10
20
30
Time
Score

Summary of Results:
HTNBots vs RETALIATE (Round 2)
40
50
60
RETALIATE
HTNbots
Difference
-10
0
10
20
30
Time
Score

Final Remarks

Final Remarks: Lessons Learned
� From our work with RETALIATE and HTNBots, we learned the following lesson, crucial for any real-world application of RL for these kinds of games:
� Separate individual bot behavior from team strategies.
� Specific to RETALIATE we learned the following two lessons:
Model the problem of learning team tactics through a simple state � Model the problem of learning team tactics through a simple state formulation,
� Do not use discount rates commonly used in Q-learning, in order to keep the strategies adaptive
� Specific to HTNBots we learned the following lesson:
� HTNs can be used to model effective team strategies. A grand strategy is laid out by the HTNs and FSM programming allows the bots to react in this highly dynamic environment while contributing to the grand task.

Final Remarks: HTNBots vs
RETALIATE
� It is very hard to predict all possibilities beforehand
� As a result, RETALIATE was able to find a weakness and exploit it to
produce a winning strategy that HTNBots could not counter
� On the other hand HTNBots produce winning strategies against the
other opponents from the beginning while it took RETALIATE half a
game in some situationsgame in some situations
� Tactics emerging from RETALIATE might be difficult to predict, a
game developer will have a hard time maintaining the Game AI
� This suggest that a combination of HTN Planning to lay down
initial strategies and using Reinforcement Learning to tune these
strategies should address individual weaknesses from both
approaches

References
� Lee-Urban S., Vasta, M., & Munoz-Avila, H. (2008) Learning Winning Policies in Team-Based First-Person Shooter Games. Under review for AI Game Programming Wisdom 4. Charles River Media.
� Vasta, M., Lee-Urban S. & Munoz-Avila, H. (2007) RETALIATE: Learning Winning Policies in First-Person Shooter Games. Proceedings of the Seventeenth Innovative Applications of Artificial Intelligence Conference (IAAI-07). AAAI Press
� Munoz-Avila, H. & Hoang, H. (2006) Coordinating Teams of Bots with � Munoz-Avila, H. & Hoang, H. (2006) Coordinating Teams of Bots with Hierarchical Task Network Planning. To appear In: AI Game Programming Wisdom 3. Charles River Media
� Ponsen, M., Munoz-Avila, H., Spronk, P., Aha, D. (2006) Automatically generating game tactics with evolutionary learning. AI Magazine. AAAI Press.
� Hoang, H., Lee-Urban, S., and Munoz-Avila, H. Hierarchical Plan Representations for Encoding Strategic Game AI. (2005) Proceedings of Artificial Intelligence and Interactive Digital Entertainment Conference (AIIDE-05). AAAI Press

Questions?







