

2 December 2005
Web TechnologiesWeb Search and SEO
Prof. Beat Signer
Department of Computer Science
Vrije Universiteit Brussel
http://www.beatsigner.com

Beat Signer - Department of Computer Science - [email protected] 2December 16, 2016
Search Engine Result Pages (SERP)

Beat Signer - Department of Computer Science - [email protected] 3December 16, 2016
Vertical Search Result Pages

Beat Signer - Department of Computer Science - [email protected] 4December 16, 2016
Search Engine Market Share (2015)
[http://returnonnow.com/internet-marketing-resources/2015-search-engine-market-share-by-country/]

Beat Signer - Department of Computer Science - [email protected] 5December 16, 2016
Search Engine Result Page
There is a variety of information shown on a search
engine result page (SERP) organic search results
non-organic search results
meta-information about the result (e.g. number of result pages)
vertical navigation
advanced search options
query refinement suggestions
...

Beat Signer - Department of Computer Science - [email protected] 6December 16, 2016
Search Engine History
Early "search engines" include various systems
starting with Bush's Memex
Archie (1990) first Internet search engine
indexing of files on FTP servers
W3Catalog (September 1993) first "web search engine"
mirroring and integration of manually maintained catalogues
JumpStation (December 1993) first web search engine combining crawling, indexing and
searching

Beat Signer - Department of Computer Science - [email protected] 7December 16, 2016
Search Engine History ...
In the following two years (1994/1995) many
new search engines appeared AltaVista, Infoseek, Excite, Inktomi, Yahoo!, ...
Two categories of early Web search solutions full text search
- based on an index that is automatically created by a web crawler in
combination with an indexer
- e.g. AltaVista or InfoSeek
manually maintained classification (hierarchy) of webpages
- significant human editing effort
- e.g. Yahoo

Beat Signer - Department of Computer Science - [email protected] 8December 16, 2016
Information Retrieval
Precision and recall can be used to measure the
performance of different information retrieval algorithms
documents retrieved
documents retrieveddocumentsrelevant precision
documentsrelevant
documents retrieveddocumentsrelevant recall
D1 D2 D4
D6 D7 D10
D3 D5
D8 D9
D1 D3 D8
D9 D10
query
6.05
3precision
75.04
3recall

Beat Signer - Department of Computer Science - [email protected] 9December 16, 2016
Information Retrieval ...
Often a combination of precision and recall, the so-called
F-score (harmonic mean) is used as a single measure
D1 D2 D4
D6 D7 D10
D3 D5
D8 D9
D1 D3
D8 D9 D10
query
57.0precision
1recall
recallprecision
recallprecision2score-F
D1 D2 D4
D6 D7 D10
D3 D5
D8 D9
D1 D3 D8
D9 D10
query
6.0precision
75.0recall
67.0score-F
D5D2
73.0score-F

Beat Signer - Department of Computer Science - [email protected] 10December 16, 2016
Bank
Delhaize
Ghent
Metro
Shopping
Train
D1 D2 D3 D4 D5 D6
1
Boolean Model
Based on set theory and boolean logic
Exact matching of documents to a user query
Uses the boolean AND, OR and NOT operators
query: Shopping AND Ghent AND NOT Delhaize
computation: 101110 AND 100111 AND 000111 = 000110
result: document set {D4,D5}
1 0 0 1 1
1
1
0
1
1
1
0
0
1
0
0
1
1
1
0
0
1
0
1
1
0
1
0
1
0
0
1
0
0
0
... ... ... ... ... ... ...
inverted index

Beat Signer - Department of Computer Science - [email protected] 11December 16, 2016
Boolean Model ...
Advantages relatively easy to implement and scalable
fast query processing based on parallel scanning of indexes
Disadvantages no ranking of output
often the user has to learn a special syntax such as the use of double quotes to search for phrases
Variants of the boolean model form the basis of many
search engines

Beat Signer - Department of Computer Science - [email protected] 12December 16, 2016
Web Search Engines
Most web search engines are based on traditional
information retrieval techniques but they have to be
adapted to deal with the characteristics of the Web immense amount of web resources (>50 billion webpages)
hyperlinked resources
dynamic content with frequent updates
self-organised web resources
Evaluation of performance no standard collections
often based on user studies (satisfaction)
Of course not only the precision and recall but also the
query answer time is an important issue
Beat Signer - Department of Computer Science - [email protected] 13December 16, 2016
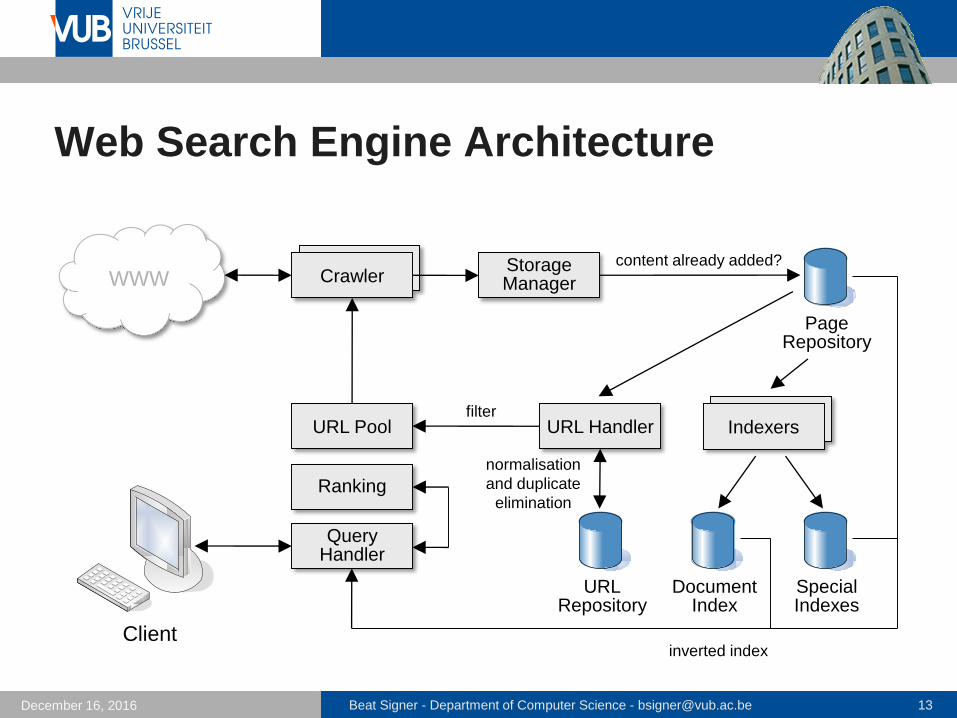
Web Search Engine Architecture
WWW Crawler
URL Pool
StorageManager
PageRepository
content already added?
Document Index
SpecialIndexes
IndexersURL Handler
URLRepository
filter
normalisation
and duplicate
elimination
Client
QueryHandler
inverted index
Ranking

Beat Signer - Department of Computer Science - [email protected] 14December 16, 2016
Web Crawler
A web crawler or spider is used to create an
index of webpages to be used by a web search engine any web search is then based on this index
Web crawler has to deal with the following issues freshness
- the index should be updated regularly (based on webpage update frequency)
quality
- since not all webpages can be indexed, the crawler should give priority to
"high quality" pages
scalabilty
- it should be possible to increase the crawl rate by just adding additional
servers (modular architecture)
- e.g. the estimated number of Google servers in 2013 was 900'000 (including
not only the crawler but the entire Google platform)

Beat Signer - Department of Computer Science - [email protected] 15December 16, 2016
Web Crawler ...
distribution
- the crawler should be able to run in a distributed manner (computer centers all
over the world)
robustness
- the Web contains a lot of pages with errors and a crawler has to deal with
these problems
- e.g. deal with a web server that creates an unlimited number of "virtual web
pages" (crawler trap)
efficiency
- resources (e.g. network bandwidth) should be used in a most efficient way
crawl rates
- the crawler should pay attention to existing web server policies
(e.g. revisit-after HTML meta tag or robots.txt file)
User-agent: *Disallow: /cgi-bin/Disallow: /tmp/ robots.txt

Beat Signer - Department of Computer Science - [email protected] 16December 16, 2016
Pre-1998 Web Search
Find all documents for a given query term use information retrieval (IR) solutions
- boolean model
- vector space model
- ...
ranking based on "on-page factors" problem: poor quality of search results (order)
Larry Page and Sergey Brin proposed to compute the
absolute quality of a page called PageRank based on the number and quality of pages linking
to a page (votes)
query-independent

Beat Signer - Department of Computer Science - [email protected] 17December 16, 2016
Origins of PageRank
Developed as part of an
academic project at Stanford
University research platform to aid under-
standing of large-scale web dataand enable researchers to easilyexperiment with new searchtechnologies
Larry Page and Sergey Brin worked on the project about a new kind of search engine (1995-1998) which finally led to a functional prototype called Google
Larry Page Sergey Brin

Beat Signer - Department of Computer Science - [email protected] 18December 16, 2016
PageRank
A page Pi has a high PageRank Ri if there are many pages linking to it
or, if there are some pages with a high PageRank linking to it
Total score = IR score × PageRank
P1
R1
P2
R2
P3
R3
P4
R4
P5
R5
P6
R6
P7
R7
P8
R8

Beat Signer - Department of Computer Science - [email protected] 19December 16, 2016
Basic PageRank Algorithm
where Bi is the set of pages
that link to page Pi
Lj is the number ofoutgoing links for page Pj
ij BP j
j
iL
PRPR
)()(
P1 P2
P3
P1
1
P2
1
P3
1
P1
1.5
P2
1.5
P3
0.75
P1
1.5
P2
1.5
P3
0.75

Beat Signer - Department of Computer Science - [email protected] 20December 16, 2016
Matrix Representation
Let us define a hyperlink
matrix HP1 P2
P3
otherwise0
if1 ijj
ij
BPLH
0210
001
1210
H iPRRand
HRR
R is an eigenvector of H
with eigenvalue 1

Beat Signer - Department of Computer Science - [email protected] 21December 16, 2016
Matrix Representation ...
We can use the power method to find R sparse matrix H with 40 billion columns and rows but only an
average of 10 non-zero entries in each colum
ttHRR 1
0210
001
1210
HFor our example
this results in or 122R 2.04.04.0

Beat Signer - Department of Computer Science - [email protected] 22December 16, 2016
Dangling Pages (Rank Sink)
Problem with pages that
have no outgoing links (e.g. P2)
Stochastic adjustment if page Pj has no outgoing links then replace column j with 1/Lj
New stochastic matrix S always has a stationary vector R can also be interpreted as a markov chain
P1 P2
01
00H and 00R
210
210C
211
210CHSand
C
C
Beat Signer - Department of Computer Science - [email protected] 23December 16, 2016
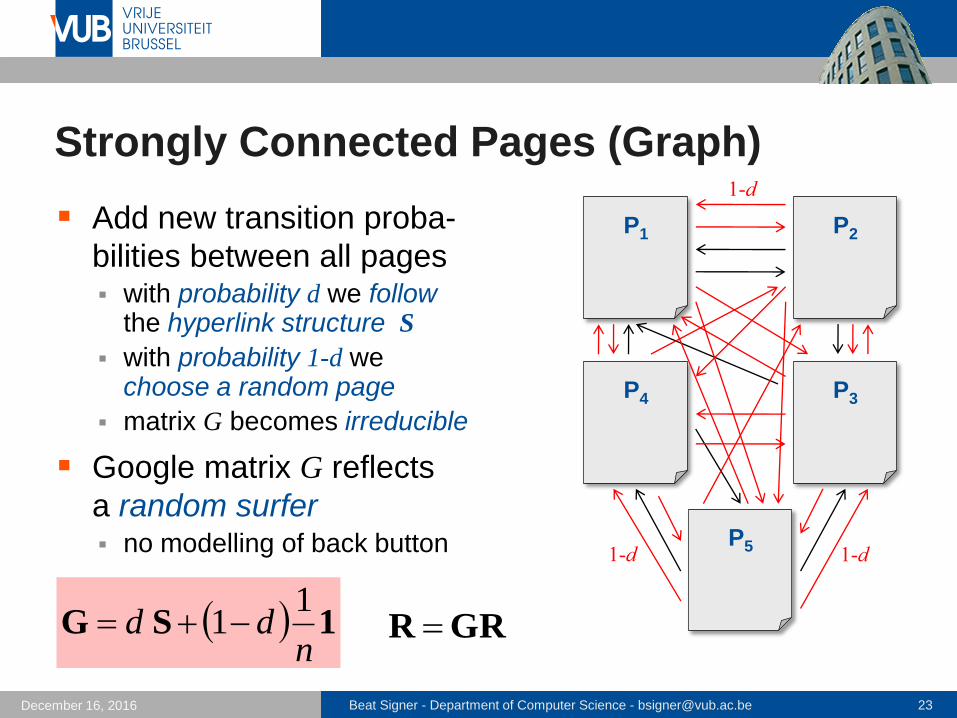
Strongly Connected Pages (Graph)
Add new transition proba-
bilities between all pages with probability d we follow
the hyperlink structure S
with probability 1-d wechoose a random page
matrix G becomes irreducible
Google matrix G reflects
a random surfer no modelling of back button
P1 P2
P3P4
P5
1SGn
dd1
1 GRR
1-d
1-d 1-d

Beat Signer - Department of Computer Science - [email protected] 24December 16, 2016
Examples 1SGn
dd1
1
A1
0.26
A2
0.37
A3
0.37

Beat Signer - Department of Computer Science - [email protected] 25December 16, 2016
Examples ...
A1
0.13
A2
0.185
A3
0.185
B1
0.13
B2
0.185
B3
0.185
5.0AP 5.0BP
1SGn
dd1
1

Beat Signer - Department of Computer Science - [email protected] 26December 16, 2016
Examples
PageRank leakage
A1
0.10
A2
0.14
A3
0.14
B1
0.22
B2
0.20
B3
0.20
38.0AP 62.0BP
1SGn
dd1
1

Beat Signer - Department of Computer Science - [email protected] 27December 16, 2016
Examples ...
A1
0.3
A2
0.23
A3
0.18
B1
0.10
B2
0.095
B3
0.095
71.0AP 29.0BP
1SGn
dd1
1

Beat Signer - Department of Computer Science - [email protected] 28December 16, 2016
Examples
PageRank feedback
A1
0.35
A2
0.24
A3
0.18
B1
0.09
B2
0.07
B3
0.07
77.0AP 23.0BP
1SGn
dd1
1

Beat Signer - Department of Computer Science - [email protected] 29December 16, 2016
Examples ...
A1
0.33
A2
0.17
A3
0.175
B1
0.08
B2
0.06
B3
0.06
80.0AP
20.0BPA4
0.125
1SGn
dd1
1
Beat Signer - Department of Computer Science - [email protected] 30December 16, 2016
Google Webmaster Tools
Various services and infor-
mation about a website
Site configuration
submission of sitemap
crawler access
URLs of indexed pages
Your site on the web
search queries
keywords
internal and external links

Beat Signer - Department of Computer Science - [email protected] 31December 16, 2016
Google Webmaster Tools ...
Diagnostics crawl rates and errors
HTML suggestions
Use HTML suggestions for on-page factor optimisation meta description
- duplicate meta descriptions
- too long meta descriptions
title tag
- missing or duplicate title tags
- too long or too short title tags
non-indexable content
Similar tools offered by other search engines e.g. Bing Webmaster Tools

Beat Signer - Department of Computer Science - [email protected] 32December 16, 2016
XML Sitemaps
List of URLs that should be crawled and indexed
<?xml version="1.0" encoding="UTF-8"?><urlset xmlns="http://www.example.com/sitemap/0.9"><url><loc>https://www.tenera.ch/trommelreibe-classic-p-2259-l-de.html</loc><lastmod>2013-07-06</lastmod><changefreq>weekly</changefreq><priority>0.4</priority>
</url><url><loc>https://www.tenera.ch/universalmesser-weiss-p-34-l-de.html</loc><lastmod>2012-12-05</lastmod><changefreq>weekly</changefreq><priority>0.1</priority>
</url>...
</urlset>

Beat Signer - Department of Computer Science - [email protected] 33December 16, 2016
XML Sitemaps ...
All major search engines support the sitemap format
The URLs of sitemap are not guaranteed to be added to
a search engine's index helps search engine to find pages that are not yet indexed
Additional metadata might be provided to search engines relative page relevance (priority)
date of last modififaction (lastmod)
update frequency (changefreq)

Beat Signer - Department of Computer Science - [email protected] 34December 16, 2016
Questions
Is PageRank fair?
What about Google's power and influence?
What about Web 2.0 or Web 3.0 and web search? "non-existent" webpages such as offered by Rich Internet
Applications (e.g. using AJAX) may bring problems for traditional search engines (hidden web)
new forms of social search
- Delicious
- ...
social marketing

Beat Signer - Department of Computer Science - [email protected] 35December 16, 2016
The Google Effect
A recent study by Sparrow et al. shows that
people less likely remember things that they
believe to be accessible online Internet as a transactive memory
Does our memory work differently in the age of Google?
What implications will the future of the Internet and new
search have?

Beat Signer - Department of Computer Science - [email protected] 36December 16, 2016
Search Engine Marketing (SEM)
For many companies Internet marketing
has become a big business
Search engine marketing (SEM) aims to
increase the visibility of a website search engine optimisation (SEO)
paid search advertising (non-organic search)
social media marketing
SEO should not be decoupled from a website's
content, structure, design and used technologies
SEO has to be seen as an continuous process in a
rapidly changing environment different search engines with regular changes in ranking

Beat Signer - Department of Computer Science - [email protected] 37December 16, 2016
Structural Choices
Keep the website structure as flat a possible minimise link depth
avoid pages with much more than 100 links
Think about your website's internal link structure which pages are directly linked from the homepage?
create many internal links for important pages
be "careful" about where to put outgoing links
- PageRank leakage
use keyword-rich anchor texts
dynamically create links between related content
- e.g. "customer who bought this also bought ..." or "visitors who viewed this
also viewed ..."
Increase the number of pages

Beat Signer - Department of Computer Science - [email protected] 38December 16, 2016
Technological Choices
Use SEO-friendly content management system (CMS)
Dynamic URLs vs. static URLs avoid session IDs and parameters in URL
use URL rewriting to get descriptive URLs containing keywords
Think carefully about the use of dynamic content Rich Internet Applications (RIAs) based on AJAX etc.
content hidden behind pull-down menus etc.
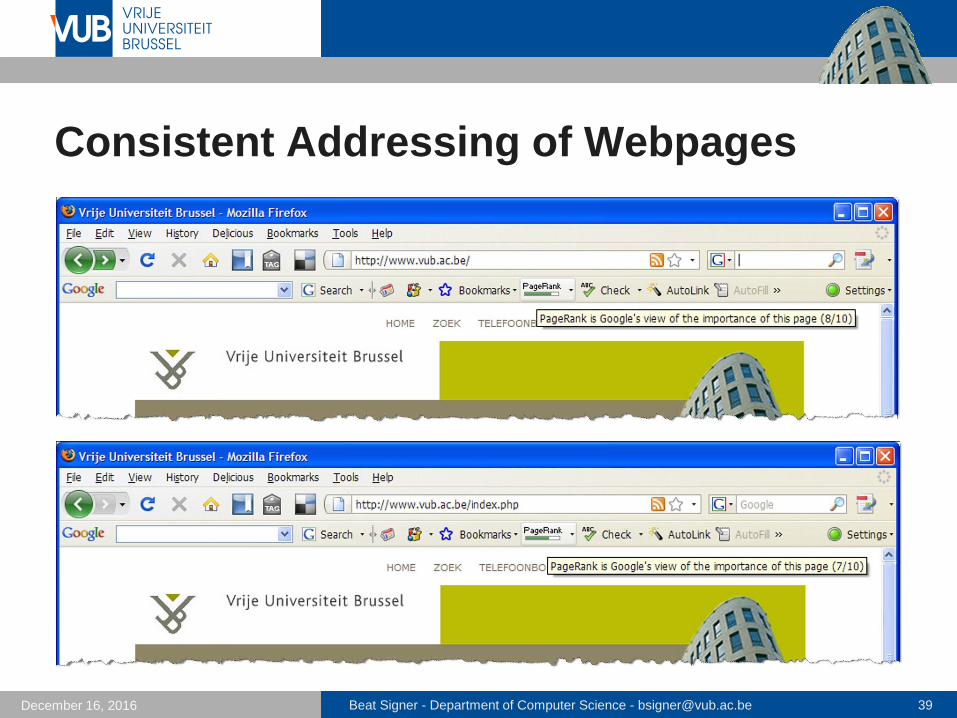
Address webpages consistently http://www.vub.ac.be http://www.vub.ac.be/index.php
Beat Signer - Department of Computer Science - [email protected] 39December 16, 2016
Consistent Addressing of Webpages

Beat Signer - Department of Computer Science - [email protected] 40December 16, 2016
Search Engine Optimisations
Different things can be optimised on-page factors
off-page factors
It is assumed that some search engines use more than
200 on-page and off-page factors for their ranking
Difference between optimisation and breaking the
"search engine rules" white hat and black hat optimisations
A bad ranking or removal from index can cost a company
a lot of money or even mark the end of the company e.g. supplemental index ("Google hell")

Beat Signer - Department of Computer Science - [email protected] 41December 16, 2016
Positive On-Page Factors
Use of keywords at relevant places in title tag (preferably one of the first words)
in URL
in domain name
in header tags (e.g. <h1>)
multiple times in body text
Provide metadata e.g. <meta name="description"> also used by search engines
to create the text snippets on the SERPs
Quality of HTML code
Uniqueness of content across the website
Page freshness (changes from time to time)

Beat Signer - Department of Computer Science - [email protected] 42December 16, 2016
Negative On-Page Factors
Links to "bad neighbourhood"
Link selling in 2007 Google announced a campaign against
paid links that transfer PageRank
Over optimisation penalty (keyword stuffing)
Text with same colour as background (hidden content)
Automatic redirect via the refresh meta tag
Cloaking different pages for spider and user
Malware being hosted on the page

Beat Signer - Department of Computer Science - [email protected] 43December 16, 2016
Negative On-Page Factors ...
Duplicate or similar content
Duplicate page titles or meta tags
Slow page load time
Any copyright violations
...

Beat Signer - Department of Computer Science - [email protected] 44December 16, 2016
Positive Off-Page Factors
Links from pages with a high PageRank
Keywords in anchor text of inbound links
Links from topically relevant sites
High clickthrough rate (CTR) from search engine for a
given keyword
Listed in DMOZ / Open Directory Project (ODP) and
Yahoo directories
High number of shares on social networks e.g. Facebook, Google+ or Twitter

Beat Signer - Department of Computer Science - [email protected] 45December 16, 2016
Positive Off-Page Factors ...
Site age (stability) Google sandbox?
Domain expiration date
...

Beat Signer - Department of Computer Science - [email protected] 46December 16, 2016
Negative Off-Page Factors
Site often not accessible to crawlers e.g. server problem
High bounce rate users immediately press the back button
Link buying rapidly increasing number of inbound links
Use of link farms
Participation in link sharing programmes
Links from bad neighbourhood?
Competitor attack (e.g. via duplicate content)?

Beat Signer - Department of Computer Science - [email protected] 47December 16, 2016
Black Hat Optimisations (Don'ts)
Link farms
Spamdexing in guestbooks, Wikipedia etc. "solution": <a rel="nofollow" href="...">...</a>
Keyword Stuffing overuse of keywords
- content keyword stuffing
- image keyword stuffing
- keywords in meta tags
- invisible text with keywords
Selling/buying links "big" business until 2007
costs based on the PageRank of the linking site

Beat Signer - Department of Computer Science - [email protected] 48December 16, 2016
Black Hat Optimisations (Don'ts) ...
Doorway pages (cloaking) doorway pages are normally just designed for search engines
- user is automatically redirected to the target page
e.g. BMW Germany and Ricoh Germany bannedin February 2006

Beat Signer - Department of Computer Science - [email protected] 49December 16, 2016
Nofollow Link Example
Nofollow value for hyperlinks introduced by Google in
2005 to avoid spamdexing <a rel="nofollow" href="...">...</a>
Links with a nofollow value were not counted in the
PageRank computation division by number of outgoing links
e.g. page with 9 outgoing links and 3 of them are nofollow links
- PageRank divided by 6 and distributed across the 6 "really linked pages"
SEO experts started to use (misuse) the nofollow links
for PageRank sculpting control flow of PageRank within a website

Beat Signer - Department of Computer Science - [email protected] 50December 16, 2016
Nofollow Link Example ...
In June 2009 Google decided to treat nofollow links
differently to avoid PageRank sculpting division by total number of outgoing links
e.g. page with 9 outgoing links and 3 of them are nofollow links
- PageRank divided by 9 and distributed across the 6 "really linked pages"
no longer a good solution to prevent Spamdexing since we loose (diffuse) some PageRank
SEO experts start to use alternative techniques to
replace nofollow links e.g. obfuscated JavaScript links

Beat Signer - Department of Computer Science - [email protected] 51December 16, 2016
Non-Organic Search
In addition to the so-called organic search, websites can
also participate in non-organic web search cost per impression (CPI)
cost- per-click (CPC)
The non-organic web search should be treated
independently from the organic web search
Quality of the landing page can have an impact on the
non-organic web search performance!
The Google AdWords programme is an example of a
commercial non-organic web search service other services include Yahoo! Advertising Solutions,
Facebook Ads, ...

Beat Signer - Department of Computer Science - [email protected] 52December 16, 2016
Google AdWords
pay-per-click (PPC) or
cost-per-thousand (CPM)
Campains and ad groups
Two types of advertising
search
content network
- Google Adsense
Highly customisable ads
region
language
daytime
...

Beat Signer - Department of Computer Science - [email protected] 53December 16, 2016
Google AdWords ...
Excellent control and monitoring for AdWords users cost per conversion
In 2015 Google's total advertising revenues
were 67 billion USD

Beat Signer - Department of Computer Science - [email protected] 54December 16, 2016
Conclusions
Web information retrieval techniques have to deal with
the specific characteristics of the Web
PageRank algorithm absolute quality of a page based on incoming links
based on random surfer model
computed as eigenvector of Google matrix G
PageRank is just one (important) factor
Various implications for website development and SEO

Beat Signer - Department of Computer Science - [email protected] 55December 16, 2016
Exercise 10
Web Search and Security

Beat Signer - Department of Computer Science - [email protected] 56December 16, 2016
References
L. Page, S. Brin, R. Motwani and T. Winograd,
The PageRank Citation Ranking: Bringing Order
to the Web, January 1998
S. Brin and L. Page, The Anatomy of a Large-Scale
Hypertextual Web Search Engine, Computer Networks
and ISDN Systems, 30(1-7), April 1998
Amy N. Langville and Carl D. Meyer, Google's
PageRank and Beyond – The Science of Search Engine
Rankings, Princeton University Press, July 2006

Beat Signer - Department of Computer Science - [email protected] 57December 16, 2016
References …
B. Sparrow, J. Liu and D.M. Wegner, Google
Effects on Memory: Cognitive Consequences of Having
Information at Our Fingertips, Science, July 2011
Google Webmaster Tools http://www.google.com/webmasters/
The W3C Markup Validation Service http://validator.w3.org
Matt Cutts http://www.mattcutts.com/blog/
SEO Book http://www.seobook.com

2 December 2005
Next LectureSecurity, Privacy and Trust







