

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
(cloud) Computing for the Enterprise
Increasing Business Agility with Real-time Processing using Apache
Hadoop and Spark
Powered by

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Agenda
• Big Data and Real-time Processing
– Use cases
– Why Hadoop and Spark?
– What’s required?
• Successfully Designing an Elastic Compute Infrastructure
• Solutions Demo– Hadoop and Spark, powered by
Nebula and Scalr
Huy NguyenSr. Director, Product Marketing
Thomas OrozcoProduct Manager
Presenters

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Evolution of Big Data and its Impact
• Businesses are pressed to operate in real-time for competitive edge
• Mere minutes can make the difference between a brilliantly handled crisis and a full-blown social media disaster
• User, machine, or sensor generated data must be processed in real-time
• Weekly reports, scheduled jobs, and batch reporting alone are no longer solutions
• Data after-the-fact is losing competitive advantages
• Data is more relevant to the business if it’s “fresh data”
• Ability to act right now as things are happening

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Batch Processing and Real-time Processing: It’s all about ‘now’
Batch ProcessingActing on
“Data at Rest”
Real-time ProcessingActing on
“Data in Motion”
Static Infrastructure Requires an Elastic Infrastructure
ComputeCompute Compute

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Uses for Real-time, Stream Processing
IT Management: Log processing, analysis, and log driven alerting, infrastructure fault protection, intelligence and surveillance, fraud detection, etc…
Brand Management and Customer Engagement:Sentiment analysis, data mining on social media streams and user-generated content, algorithmic trading, geospatial location , etc…
Conversion Optimization:Clickstream analysis and real-time targeted offer generation

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Why use Hadoop + Spark for Real-Time Processing?
Plenty of alternatives exist:
• Mesos (+ Spark), Storm, Message Queue (+ custom processing tier)
Hadoop + Spark stack offers unique benefits:
• Familiar and high-level API (HDFS distributed storage abstraction, YARN scheduling… and rescheduling).
• Integrates naturally with traditional batch jobs (e.g. process log streams in real-time to flag high-priority events, and run traditional map-reduce jobs on them later on).
© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
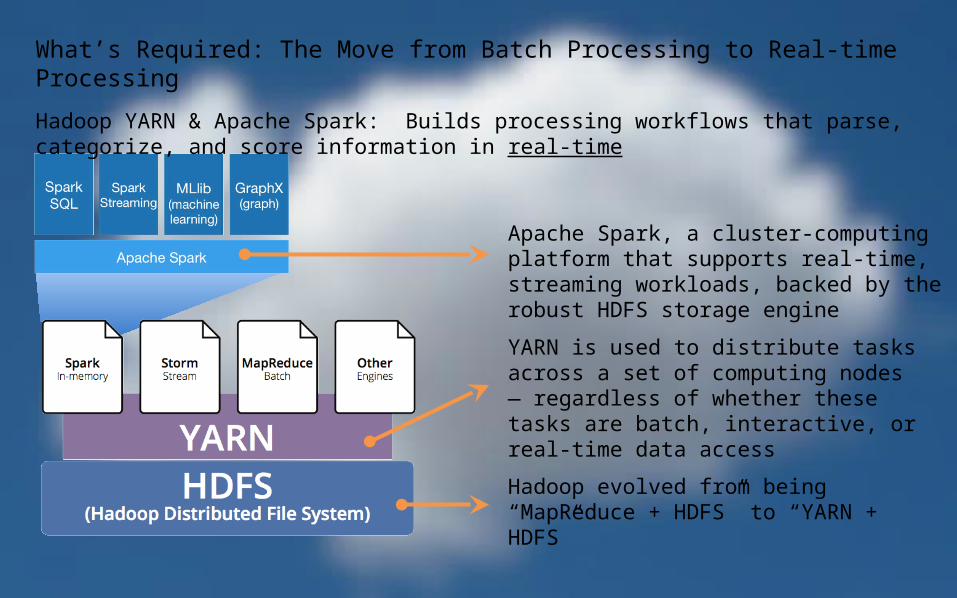
What’s Required: The Move from Batch Processing to Real-time Processing
Hadoop YARN & Apache Spark: Builds processing workflows that parse, categorize, and score information in real-time
Hadoop evolved from being “MapReduce + HDFS” to “YARN + HDFS”
YARN is used to distribute tasks across a set of computing nodes — regardless of whether these tasks are batch, interactive, or real-time data access
Apache Spark, a cluster-computing platform that supports real-time, streaming workloads, backed by the robust HDFS storage engine

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Big Data
Storage
Decouple
Compute
Decouple the compute tier from storage tier for real-time processing
• Dynamically scaling the storage tier would result in major inefficiencies or data loss
Processing Tier
Processing tier (application and infrastructure) must be able to “auto scale” compute resources as the volume, velocity, and variety of big data increases
What’s Required: Decoupling the Compute/Storage Tier & Auto-scaling

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Suggested Architecture for Real-time Big Data Processing
A Hadoop Compute Tier (YARN)• One resource manager• One history server• Multiple node managers
B Hadoop Storage Tier (HDFS)• One name node• Multiple data nodes
BA
C Client Nodes• Dispatch real-time data
processing jobs
C
D Intelligent Cloud Mgmt Platform from Scalr • Orchestration and auto-
scaling of applicationsD
E Turnkey Private Cloud Infrastructure from Nebula • Elastic, on-demand cloud
computing infrastructureE

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
INTRODUCTION TO NEBULA

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Nebula Turnkey Private Cloud
Fastest path to OpenStack
Nebula productizes OpenStack in a highly cost-efficient, fast time-to-value, secure and scalable enterprise-class product
Cost-efficient: Software delivered using appliance with off-the-shelf industry standard servers and storage – freedom of choice
Fast time-to-value: Curated OpenStack (rack integration or multi-rack integration), enabling customers/partners to spend their resources building applications, not building infrastructure
Open, Secure & Scalable: Identical clouds to deliver consistent and predictable performance with open connectors for turnkey eco-system
Enterprise-class: Highly available with connectors to existing enterprise workflows & architecture (identity, storage, networking) for zero disruption to IT

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Nebula Turnkey Private Cloud

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
DevOPs / DevTestWorkloads
Genome SequencingWorkloads
Big Data / Real-timeWorkloads
Media RenderingWorkloads
Self-Service ITProcess Improvements API / Integration
Cosmos Software
StorageCompute Network
Management & Orchestration
Identity/Security
Active Directory
Identity
Storage
Networking
VLANs
Enterprise
Intergration
The Only Enterprise-ready, Turnkey Solution for OpenStack Private Clouds

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Traditional InfrastructureFixed Compute, Storage, Network
Private CloudShared Resource Pool
•As real-time data feeds increase, YARN tier can be provisioned to scale-out across multiple servers
•As data feeds decrease, resources can be de-provisioned and returned to the shared pool
•Nebula enables resource pooling of compute, storage, network services for scale-out readiness
YARN Tier w/ Spark
YARN Tier w/ Spark
YARN Tier w/ Spark
YARN Tier w/ Spark
YARN Tier w/ Spark
YARN Tier w/ Spark
Auto-scaling with Nebula and Scalr

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
INTRODUCTION TO SCALR

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Scalr is used to:
Orchestrate Resources
Provisioning Templating
Auto-scaling…
Define and Enforce Policies
Lease ManagementNetwork Policies
RBAC…
Centrally Manage Clouds
Multi-CloudCost Analytics
SSO, CMDB, ITSM integrations
…

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Scalr is trusted by:

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
SOLUTIONS DEMO

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
www.nebula.com or www.scalr.com
Nebula’s turnkey private cloud and Scalr’s intelligent Cloud Management Platform meet these demands by delivering an orchestrated infrastructure that can auto scale compute and storage resources on-demand to process data feeds in real-time
Summary
Emergent big data technology such as Hadoop YARN and Apache Spark can build processing workflows that parse, categorize, and score information in real-time
Data processing tiers (from application to infrastructure) must be able to auto-scale to accommodate the 3 Vs of Big Data
For more information:
Businesses need to operate in real-time to maintain competitive edge

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
Benefits to Real-Time Processing
React to changing business conditions in real time• Adapt and react quickly to data, market conditions and events happening in the
outside world
Faster time-to-market• Development and deployment
Delivering the best user experience• Personalized experience

© 2015 Nebula, Inc. All rights reserved. © 2015 Scalr, Inc. All rights reserved.
THANK YOU







