39
. PGM 2002/3 – Tirgul6 Approximate Inference: Sampling
| Date post: | 22-Dec-2015 |
| Category: |
Documents |
| View: | 228 times |
| Download: | 0 times |

.
PGM 2002/3 – Tirgul6Approximate Inference:
Sampling

Approximation
Until now, we examined exact computation In many applications, approximation are sufficient
Example: P(X = x|e) = 0.3183098861838 Maybe P(X = x|e) 0.3 is a good enough
approximation e.g., we take action only if P(X = x|e) > 0.5
Can we find good approximation algorithms?

Types of ApproximationsAbsolute error An estimate q of P(X = x | e) has absolute
error , ifP(X = x|e) - q P(X = x|e) +
equivalently
q - P(X = x|e) q +
Absolute error is not always what we want: If P(X = x | e) = 0.0001, then an absolute error of
0.001 is unacceptable If P(X = x | e) = 0.3, then an absolute error of
0.001 is overly precise
0
1
q2

Types of Approximations
Relative error An estimate q of P(X = x | e) has relative
error , ifP(X = x|e)(1 - ) q P(X = x|e)(1
+ )equivalently
q/(1 + ) P(X = x|e) q/(1 - )
Sensitivity of approximation depends on actual value of desired result
0
1
q
q/(1+)
q/(1-)

Complexity
Recall, exact inference is NP-hard Is approximate inference any easier?
Construction for exact inference: Input: a 3-SAT problem Output: a BN such that P(X=t) > 0 iff is
satisfiable

Complexity: Relative Error
Suppose that q is an relative error estimate ofP(X = t),
If is not satisfiable, then
P(X = t)(1 - ) q P(X = t)(1 + )0 = P(X = t)(1 - ) q P(X = t)(1 + ) = 0
Thus, if q > 0, then is satisfiable
An immediate consequence:
Thm: Given , finding an -relative error approximation is NP-hard

Complexity: Absolute error
We can find absolute error approximations to P(X = x)
We will see such algorithms shortly However, once we have evidence, the problem is
harder
Thm If < 0.5, then finding an estimate of P(X=x|e)
with absulote error approximation is NP-Hard

Proof Recall our construction
...1
Q1 Q3Q2 Q4 Qn
2 3 k
...A1
... k-1
A2 Ak/2
X
......

Proof (cont.)
Suppose we can estimate with absolute error Let p1 P(Q1 = t | X = t)
Assign q1 = t if p1 > 0.5, else q1 = f Let p2 P(Q2 = t | X = t, Q1 = q1 )
Assign q2 = t if p2 > 0.5, else q2 = f
…
Let pn P(Qn = t | X = t, Q1 = q1, …, Qn-1 = qn-1 )Assign qn = t if pn > 0.5, else qn = f

Proof (cont.)Claim: if is satisfiable, then q1 ,…, qn is a satisfying
assignment Suppose is satisfiable By induction on i there is a satisfying assignment with Q1
= q1, …, Qi = qi
Base case:If Q1 = t in all satisfying assignments,
P(Q1 = t | X = t) = 1 p1 1 - > 0.5 q1 = t
If Q1 = f, in all satisfying assignments, then q1 = fOtherwise, statement holds for any choice of q1

Induction argument:If Qi+1 = t in all satisfying assignments s.t.Q1 = q1, …, Qi = qi
P(Qi+1 = t | X = t, Q1 = q1, …, Qi = qi ) = 1 pi+1 1 - > 0.5 qi+1 = t
If Qi+1 = f in all satisfying assignments s.t.Q1 = q1, …, Qi = qi
then qi+1 = f
Proof (cont.)Claim: if is satisfiable, then q1 ,…, qn is a satisfying
assignment Suppose is satisfiable By induction on i there is a satisfying assignment with Q1
= q1, …, Qi = qi

Proof (cont.)
We can efficiently check whether q1 ,…, qn is a satisfying assignment (linear time)
If it is, then is satisfiable If it is not, then is not satisfiable
Suppose we have an approximation procedure with relative error
we can determine 3-SAT with n procedure calls approximation is NP-hard

Search Algorithms
Idea: search for high probability instances Suppose x[1], …, x[N] are instances with high
mass We can approximate:
If x[i] is a complete instantiation, then P(e|x[i]) is 0 or 1
i
i
[i])[i])P(|P
[i])[i])P(|yYP)yYP
xxe
xxee
(
,(|(

Search Algorithms (cont)
Instances that do not satisfy e, do not play a role in approximation
We need to focus the search to find instances that do satisfy e
Clearly, in some cases this is hard (e.g., the construction from our NP-hardness result
i
i
[i])[i])P(|P
[i])[i])P(|yYP)yYP
xxe
xxee
(
,(|(

Stochastic Simulation
Suppose we can sample instances <x1,…,xn> according to P(X1,…,Xn)
What is the probability that a random sample <x1,…,xn> satisfies e?
This is exactly P(e)
We can view each sample as tossing a biased coin with probability P(e) of “Heads”

Stochastic Sampling
Intuition: given a sufficient number of samples x[1],…,x[N], we can estimate
Law of large number implies that as N grows, our estimate will converge to p with high probability
How many samples do we need to get a reliable estimation?
Use Chernof’s bound for binomial distributions
N
[i])|P
NHeads
)P i
xe
e(
#(

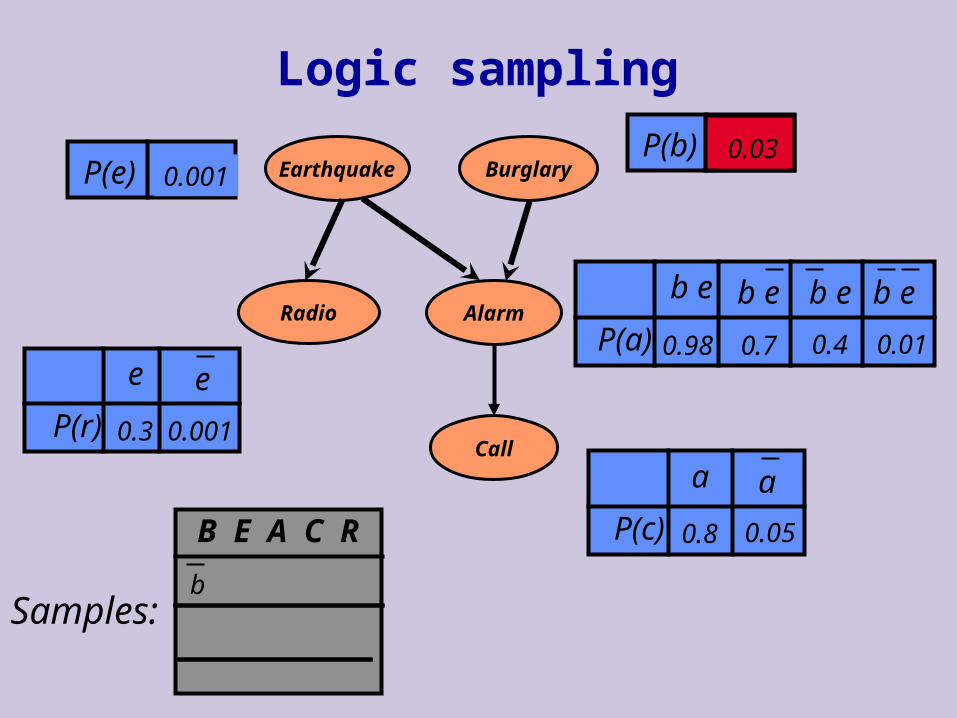
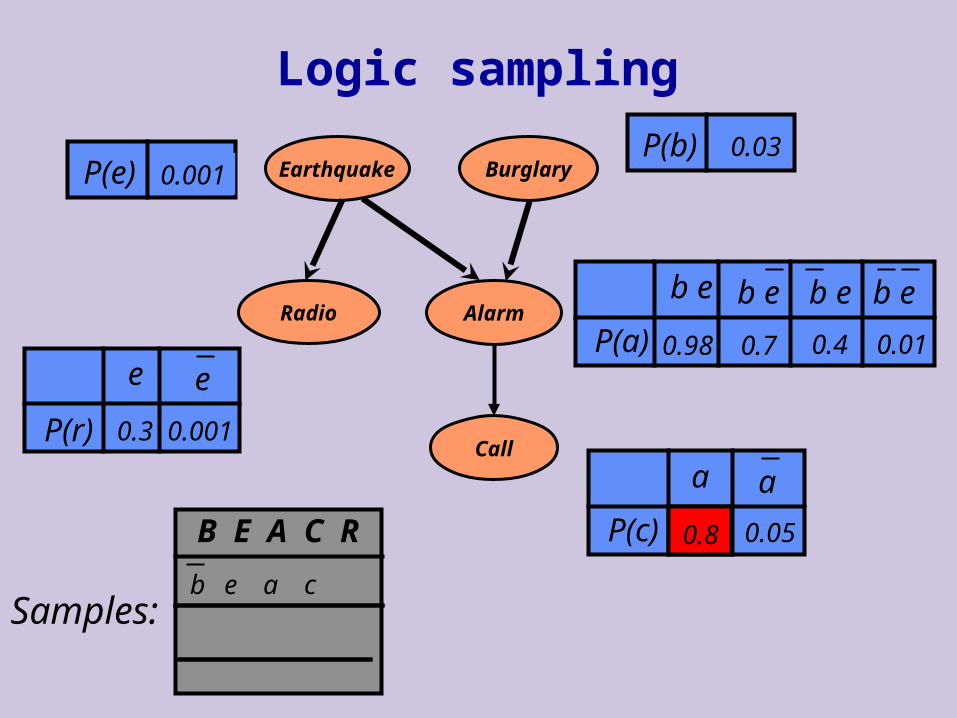
Sampling a Bayesian Network
If P(X1,…,Xn) is represented by a Bayesian network, can we efficiently sample from it?
Idea: sample according to structure of the network Write distribution using the chain rule, and then
sample each variable given its parents
Samples:
B E A C R
Logic sampling
P(b) 0.03P(e) 0.001
P(a)
b e b e b e b e
0.98 0.40.7 0.01
P(c)
a a
0.8 0.05
P(r)
e e
0.3 0.001
b
Earthquake
Radio
Burglary
Alarm
Call
0.03

Samples:
B E A C R
Logic sampling
P(b) 0.03P(e) 0.001
P(a)
b e b e b e b e
0.98 0.40.7 0.01
P(c)
a a
0.8 0.05
P(r)
e e
0.3 0.001
eb
Earthquake
Radio
Burglary
Alarm
Call
0.001

Samples:
B E A C R
Logic sampling
P(b) 0.03P(e) 0.001
P(a)
b e b e b e b e
0.98 0.40.7 0.01
P(c)
a a
0.8 0.05
P(r)
e e
0.3 0.001
e ab
0.4
Earthquake
Radio
Burglary
Alarm
Call
Samples:
B E A C R
Logic sampling
P(b) 0.03P(e) 0.001
P(a)
b e b e b e b e
0.98 0.40.7 0.01
P(c)
a a
0.8 0.05
P(r)
e e
0.3 0.001
e a cb
Earthquake
Radio
Burglary
Alarm
Call
0.8

Samples:
B E A C R
Logic sampling
P(b) 0.03P(e) 0.001
P(a)
b e b e b e b e
0.98 0.40.7 0.01
P(c)
a a
0.8 0.05
P(r)
e e
0.3 0.001
e a cb r
0.3
Earthquake
Radio
Burglary
Alarm
Call

Logic Sampling
Let X1, …, Xn be order of variables consistent with arc direction
for i = 1, …, n do sample xi from P(Xi | pai ) (Note: since Pai {X1,…,Xi-1}, we already
assigned values to them) return x1, …,xn

Logic Sampling
Sampling a complete instance is linear in number of variables Regardless of structure of the network
However, if P(e) is small, we need many samples to get a decent estimate

Can we sample from P(X1,…,Xn |e)?
If evidence is in roots of network, easily If evidence is in leaves of network, we have a
problem Our sampling method proceeds according to
order of nodes in graph
Note, we can use arc-reversal to make evidence nodes root.
In some networks, however, this will create exponentially large tables...

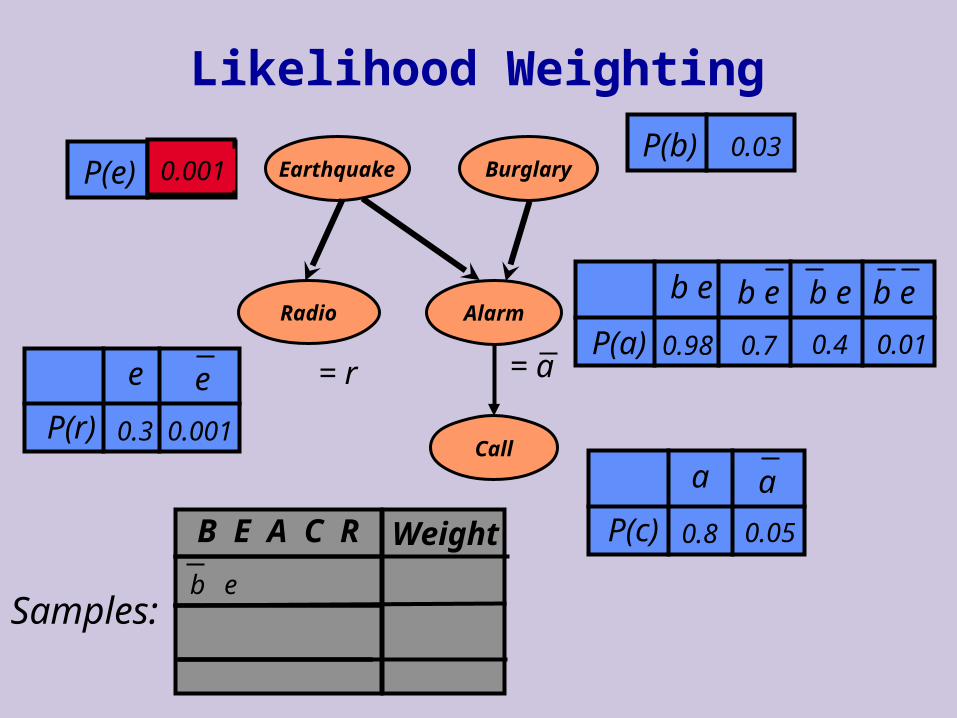
Likelihood Weighting
Can we ensure that all of our sample satisfy e? One simple solution:
When we need to sample a variable that is assigned value by e, use the specified value
For example: we know Y = 1 Sample X from P(X) Then take Y = 1
Is this a sample from P(X,Y |Y = 1) ?
X Y

Likelihood Weighting
Problem: these samples of X are from P(X) Solution:
Penalize samples in which P(Y=1|X) is small
We now sample as follows: Let x[i] be a sample from P(X) Let w[i] be P(Y = 1|X = x [i])
X Y
i
i
iw
[i])x|XPiw)xXP
][
(][1|(
xY

Likelihood Weighting
Why does this make sense? When N is large, we expect to sample NP(X = x)
samples with x[i] = x Thus,
When we normalize, we get approximation of the conditional probability
)1,(
)|1()(][,
YxXNP
xXYPxXNPwxixi
i

Samples:
B E A C R
Likelihood Weighting
P(b) 0.03P(e) 0.001
P(a)
b e b e b e b e
0.98 0.40.7 0.01
P(c)
a
0.8 0.05
P(r)
e e
0.3 0.001
b
Earthquake
Radio
Burglary
Alarm
Call
0.03
Weight
= r
a
= a
Samples:
B E A C R
Likelihood Weighting
P(b) 0.03P(e) 0.001
P(a)
b e b e b e b e
0.98 0.40.7 0.01
P(c)
a a
0.8 0.05
P(r)
e e
0.3 0.001
eb
Earthquake
Radio
Burglary
Alarm
Call
0.001
Weight
= r = a

Samples:
B E A C R
Likelihood Weighting
P(b) 0.03P(e) 0.001
P(a)
b e b e b e b e
0.98 0.40.7 0.01
P(c)
a a
0.8 0.05
P(r)
e e
0.3 0.001
eb
0.4
Earthquake
Radio
Burglary
Alarm
Call
Weight
= r = a
0.6a

Samples:
B E A C R
Likelihood Weighting
P(b) 0.03P(e) 0.001
P(a)
b e b e b e b e
0.98 0.40.7 0.01
P(c)
a a
0.8 0.05
P(r)
e e
0.3 0.001
e cb
Earthquake
Radio
Burglary
Alarm
Call
0.05Weight
= r = a
a 0.6

Samples:
B E A C R
Likelihood Weighting
P(b) 0.03P(e) 0.001
P(a)
b e b e b e b e
0.98 0.40.7 0.01
P(c)
a a
0.8 0.05
P(r)
e e
0.3 0.001
e cb r
0.3
Earthquake
Radio
Burglary
Alarm
Call
Weight
= r = a
a 0.6*0.3

Likelihood Weighting
Let X1, …, Xn be order of variables consistent with arc direction
w = 1 for i = 1, …, n do
if Xi = xi has been observedw w* P(Xi = xi | pai )
elsesample xi from P(Xi | pai )
return x1, …,xn, and w

Importance SamplingA general method for evaluating <f>P(X) when we cannot sample from P(X).
Idea: Choose an approximating distribution
Q(X) and sample from it
Using this we can now sample from Q and then
x XQx
XP XQXP
xfdxXQXQ
xPxfdxxPxfxf)(
)( )()(
)()()(
)()()()()(
W(X)
M
m
M
mXP
mwmxfM
mXfM
xf1 1
)()(])[(
1])[(
1)(
If we could generate samples from P(X)
Now that we generate the sample from Q(X)

(Unnormalized) Importance Sampling1. For m=1:M
Sample X[m] from Q(X)
Calculate W(m) = P(X)/Q(X)
2. Estimate the expectation of f(X) using
Requirements: P(X)>0 Q(X)>0 (do not ignore possible scenarios) It is possible to calculate P(X),Q(X) for a specific X=x It is possible to sample from Q(X)
M
mXP
mwmxfM
xf1
)()(])[(
1)(

Normalized Importance SamplingAssume that we cannot now even evalute P(X=x) but can evaluate P’(X=x) = P(X=x)(for example we can evaluate P(X) but not P(X|e) in a Bayesian network)
We define w’(X) = P’(X)/Q(X). We can then evaluate :
and then:
where in the last step we simply replace with the above equation
xx
XQαxP
XQXP
XQXw )(')()('
)()(')(
)(
)(
)(
)(
)('
)(')()(')(
1)()(
)(')(1
)()(
)()()()()(
XQ
XQ
XQx
xxXP
Xw
XwXfXwXf
αdx
XQXQ
xPxfα
dxXQXQ
xPxfdxxPxfxf

Normalized Importance SamplingWe can now estimate the expectation of f(X) similarly to unnormalized importance sampling by sampling from Q(X) and then
(hence the name “normalized”)
M
m
M
mXP
mw
mwmxfxf
1
1)(
)(
)(])[()(

Importance Sampling to LWWe want to compute P(Y=y|e)? (X is the set of random variables in the network and Y is some subset we are interested in)
1) Define a mutilated Bayesian network BZ=z to be a
network where:• all variables in Z are disconnected from their
parents and are deterministically set to z• all other variables remain unchanged
2) Choose Q to be BE=e
convince yourself that P’(X)/Q(X) is exactly P(Y=y|X)
3) Choose f(x) to be 1(Y[m]=y)/M
4) Plug into the formula and you get exactly Likelihood Weighting
Likelihood weighting is correct!!!

















