29
1 ©2010 HP Created on xx/xx/xxxx of 29 Rick McGeer HP Labs, University of Victoria November 18, 2010 THE WORLD WIDE W5 A GLOBAL ARCHITECTURE FOR DECISION SUPPORT
| Date post: | 25-Dec-2015 |
| Category: |
Documents |
| Upload: | felix-hart |
| View: | 219 times |
| Download: | 0 times |

1 ©2010 HP Created on xx/xx/xxxxof 29
Rick McGeerHP Labs, University of VictoriaNovember 18, 2010
THE WORLD WIDE W5
A GLOBAL ARCHITECTURE FOR DECISION
SUPPORT

2 ©2010 HP Created on xx/xx/xxxxof 29
MOTIVATION: THE INTERCLOUD
– Internet: set of standards and protocols which permit interconnection of independently-administered networks•Network of networks
– Intercloud: Set of standards and protocols which permit interconnection of independently administered clouds• Term due to Greg Papadopoulos
•Defining infrastructure of 2010’s and beyond
– Question: What will the Intercloud look like? What makes it an intercloud (as opposed to a Cloud)?

3 ©2010 HP Created on xx/xx/xxxxof 29 3
OUTLINE
– The problem of big data
– How to build the world’s greatest digital library
– How to build the world’s greatest decision support engine
– The building blocks• Virtualization: VMs, PlanetLab, Seattle
• Programming Paradigms: MapReduce, Hadoop, Pig
– Next Steps and a Plan

4 ©2010 HP Created on xx/xx/xxxxof 29 4
THE WORLD IS DROWNING IN DATA
– Rise of massive numbers of high-capacity sensors• 5 MP (= 15 MB/frame) sensors now ~ $10 (and dropping)
• Each of these capable of generating 1 GB per second
– Massive deployments and applications• Genomics
• Sloan Digital Sky Survey (200 GB/day)
• ALICE detector at CERN (1 GB/second = 86 TB/day) [only 1 month of the year]
• CASA Atmospheric sensing experiment (100 Mb/s/radar on-board, 4 Mb/s/radar [network limitation]
• SmartSantander (20,000 sensors in a city, Kb/sec –100 Mb/sec, depending…)
• ~ 1 Exabtyte in medical images worldwide…
• Many, many more

5 ©2010 HP Created on xx/xx/xxxxof 29 5
WE NEED TO REDUCE AND COMPUTE ON ALL THIS STUFF– Data needs to be searched, reduced, analyzed
– Ex: Jim Gray and the Digital Telescope (SkyServer)• Make SDSS data available online
• Searchable by astronomers and graduate students
• Resulted in a 100x increase in number of galaxies classified
– Ex: ALICE detector (CERN)• Produces 1 GB/sec of physics data, sustained, one month/year
• Data distributed to LHC Grid Tier-One sites
• Processed and turned into physics, redistributed to Tier-II sites
– Ex: VHA Health Informatics (20TB as of 2007) (courtesy Jim Gray)• Support epidemiological studies
− 7 million enrollee, 5 million patients
− Example Milestones:
• 1 Billionth Vital Sign loaded in April ‘06• 30-minutes to population-wide obesity analysis• Discovered seasonality in blood pressure -- NEJM fall ‘06

6 ©2010 HP Created on xx/xx/xxxxof 29 6
TWO APPROACHES TO ANALYZING DATA
1. Schlep all the data to the processing sitea) Use the network
− This is going to hurt….
− US coast-to-coast TCP performance (Linux 2.6, standard initial window): ~3.5 Mb/s
− Best possible: 10 Gb/s (dedicated fiber, TCP Offload Engine, $$$)
− Can be assisted by prefetch (cf, LambdaRAM, 20x performance increase in cyclone analysis)
b) Send the disk− 100 TB disk, Fed Ex 24-hour delivery (Customs?): ~10 Mb/s
− 24 hour latency for first byte, disk performance (~ 60 Gb/s) thereafter….
− Actually easier just to send the computer (cf Jim Gray)
2. Schlep the processing to the data• Makes a lot more sense
• Processing in general reduces data; results are cheaper to send than data
• Processing power is ubiquitous
• Programs are tiny (always under 1 GB)

7 ©2010 HP Created on xx/xx/xxxxof 29 7
QUESTION: HOW CAN WE BUILD A DISTRIBUTED DATA ANALYSIS SYSTEM?
– Key: Want to run programs at the data
– So….1. Programs have to run where the data is
2. Programs have to be safe
3. Resources must be allocated in a reasonable manner…
– Return to this after a little inspiration

8 ©2010 HP Created on xx/xx/xxxxof 29 8
OUTLINE
– The problem of big data
– How to build the world’s greatest digital library
– How to build the world’s greatest decision support engine
– The building blocks• Virtualization: VMs, PlanetLab, Seattle
• Programming Paradigms: MapReduce, Hadoop, Pig
– Next Steps and a Plan

9 ©2010 HP Created on xx/xx/xxxxof 29 9
BUILDING THE WORLD’S GREATEST DIGITAL LIBRARY: CHOICE 1
– Build a massive database system
– Buy thousands or millions of servers
– Hire tens of thousands of programmers
– Buy out the world supply of hard disks
– Spend billions of dollars
– Cover Kansas in computers (central location, not much else going on, GpENI gives us a start)• Contact James Sterbenz for details….
– Never get it done….

10 ©2010 HP Created on xx/xx/xxxxof 29 10
BUILDING THE WORLD’S GREATEST DIGITAL LIBRARY: CHOICE 2
– Invent a simple protocol by which one computer can send a file to another
– Invent a simple file format which can be easily created on a text editor
– Invent a simple, universal client which can run on anything
– Let nature take its course…
– HTTP
– HTML
– Mosaic (then Navigator, IE, Firefox, Chrome, Safari, Opera…).

11 ©2010 HP Created on xx/xx/xxxxof 29 11
CONCLUSION
– The first method might have worked…
– The second one certainly did• Currently a zettabyte (1021 bytes) stored on the world’s Cloud servers…
• How much is that?
• 6.9 billion people (6.9 x 109 ) people on earth….
• About 1011 bytes (100 gigabytes) for every person on earth
• Average book size: 6 MB (6 x 106) bytes
• 30,000 books for every man, woman, and child on earth….
• Doubling every 18 months….(data from IDC)
– More to the point….• Every trivial fact (fact which can be established by lookup) now “known” by every connected individual
• For the first time since Francis Bacon (1561-1626) one person can “know” everything…

12 ©2010 HP Created on xx/xx/xxxxof 29 12
OUTLINE
– The problem of big data
– How to build the world’s greatest digital library
– How to build the world’s greatest decision support engine
– The building blocks• Virtualization: VMs, PlanetLab, Seattle
• Programming Paradigms: MapReduce, Hadoop, Pig
– Next Steps and a Plan

13 ©2010 HP Created on xx/xx/xxxxof 29 13
BUILDING THE WORLD’S GREATEST DECISION SUPPORT SYSTEM: CHOICE 1
– Build a massive database system
– Buy thousands or millions of servers
– Hire tens of thousands of programmers
– Buy out the world supply of hard disks
– Spend billions of dollars
– Cover Kansas in computers (central location, not much else going on, GpENI gives us a start)• Contact James Sterbenz for details….
– Never get it done….

14 ©2010 HP Created on xx/xx/xxxxof 29 14
BUILDING THE WORLD’S GREATEST DECISION SUPPORT SYSTEM: CHOICE 2
– Invent a simple protocol by which one computer can send a program to another and have it reliably (and safely) executed
– Invent a simple, universal meta schema and API which can be easily implemented in anything
– Invent a simple, universal query system which runs on everything
– Let nature take its course…
– ?
– ?
– ?

15 ©2010 HP Created on xx/xx/xxxxof 29 15
OUTLINE
– The problem of big data
– How to build the world’s greatest digital library
– How to build the world’s greatest decision support engine
– The building blocks• Virtualization: VMs, PlanetLab, Seattle
• Programming Paradigms: MapReduce, Hadoop, Pig
– Next Steps and a Plan

16 ©2010 HP Created on xx/xx/xxxxof 29 16
VIRTUALIZATION: KEY BUILDING BLOCK TECHNOLOGY
– Key problem for software generally: dependence on environment• Instruction set
• Operating system
• Installed libraries
• ….
– Solution (since at least 1965!) virtualization• Essentially, carry the environment around with the program in a “virtual” machine
• First introduced in the IBM 360 line
• Brought to a high art in the late 1990’s, early 2000’s

17 ©2010 HP Created on xx/xx/xxxxof 29 17
VIRTUALIZATION IN THE MODERN ERA
–VMWare: Mendel Rosenblum (Stanford) + very succesful startup•Permitted abstraction of both OS and instruction set
–“Paravirtualization”: Ian Clarke (Cambridge).•Xen system •Abstraction of OS•Permitted running several isolated virtual machines on same hardware•Gave each virtual machine the illusion that it was operating as its own isolated physical machine−Performance and security isolation

18 ©2010 HP Created on xx/xx/xxxxof 29 18
PARAVIRTUALIZATION ENABLES THE CLOUD
– Most applications and web services don’t need a whole machine
– Virtualization lets multiple virtual machines share the same physical machine transparently
– Permits: renting virtual machines for cheap!• Amazon EC2: $.10 for a “micro” instance
– Bandwidth, storage, processing are easy to control on a per-virtual machine basis• Means that offering VM computation services is safe
• Offering VM computation services can be done for fixed, controllable cost
• No longer risky to run someone else’s code…

19 ©2010 HP Created on xx/xx/xxxxof 29 19
BUILDING BLOCK II: STANDARD MODEL OF COMPUTATION OVER DATA
– Observation (due to Google). Most highly-parallel computation can be thought of as a two-stage process:• Map: Perform identical operations over many sets of separate data
• Reduce: merge the results from the Map phase into the solution
– Google: turn this into a programming model• Operate on (key, value) pairs
• Map step works over a list of keys to produce list of (key, value) pairs
• Reduce step operates on list of (key, value) pairs to produce final result
– Can be done recursively
– Key point: map step can be run on different data sets on many difference computers, simultaneously• Map nodes send results to Reduce node
• Reduce nodes form results

20 ©2010 HP Created on xx/xx/xxxxof 29 20
MAP REDUCE EXAMPLE: COUNTING WORDS
def map(lkey, value, outputCollector):
words = breakStringIntoWords(value);
for word in words: outputCollector.add(word, 1)
return outputCollector
def reduce(outputCollector, resultCollector):
for word in outputCollector.keys():
if resultCollector.hasKey(word):
resultCollector[word] += outputCollector[word]
else: resultCollector[word] = outputCollector[word]
return resultCollector
Runs on Map Nodes
Runs on Reduce Nodes

21 ©2010 HP Created on xx/xx/xxxxof 29 21
MAP REDUCE SUCCESS STORIES, IMPLEMENTATIONS, AND KEY NEEDS
– Success stories• Google: used to completely redo their web index
• New York Times: Uses MapReduce instances (Hadoop) running on Amazon EC2 nodes to index 4 TB of image data
– Key Needs• Distributed File System (e.g., “Cassandra” from Facebook)
• Scheduler, “Sharder” for Map jobs
• New networking (“incast” problem).
– Key implementations• Hadoop (Apache project)
• Google, Oracle, Disco, Misco, Twister, Greenplum, Phoenix, Plasma, BashReduce
• Well over 20, many open-source

22 ©2010 HP Created on xx/xx/xxxxof 29 22
QUERY/DECISION SUPPORT FRAMEWORKS OVER MAPREDUCE
– Key: MapReduce programmers must still write code in:• Erlang, Haskell, Ruby, Bash, C, Go, Python, C#, CUDA, Ocaml, or Java
• Many implementations, but all require programming
– Need: High-level query interface• Something like SQL
• Tractable for non-programmers
• Abstract away details of how mapping is done
– Preliminary implementations (open source)• Hive framework (Facebook)
• Pig (Apache project)

23 ©2010 HP Created on xx/xx/xxxxof 29 23
W5

24 ©2010 HP Created on xx/xx/xxxxof 29 24
W5
– Network of large and small clusters, running open query language over MapReduce to answer user queries
– Each cluster has a standard stack:• Cluster manager with resource control (Eucalytpus, Tashi….)
• Virtualization on each node
• Map/Reduce implementation inside virtual machines
• Pig or other query language on Map/Reduce
– “Clusters” can be as small as a single PC!

25 ©2010 HP Created on xx/xx/xxxxof 29 25
PROBLEMS TO SOLVE
– Simple: standardize on common access, resource format
– Key first step: ssh keys, rspecs (GENI)
– Harder: MapReduce across the continents• How does this work with 50ms + in latency between Map and Reduce
• How does one do zero-data-move MapReduce
• Optimization Function?
– Hardest:• Per-user resource and bandwidth allocation across multiple cloud instances
• When to move data, when not to
• Distributed rate control to conserve costs while making performance goals
• Plenty to keep plumbers happy for awhile
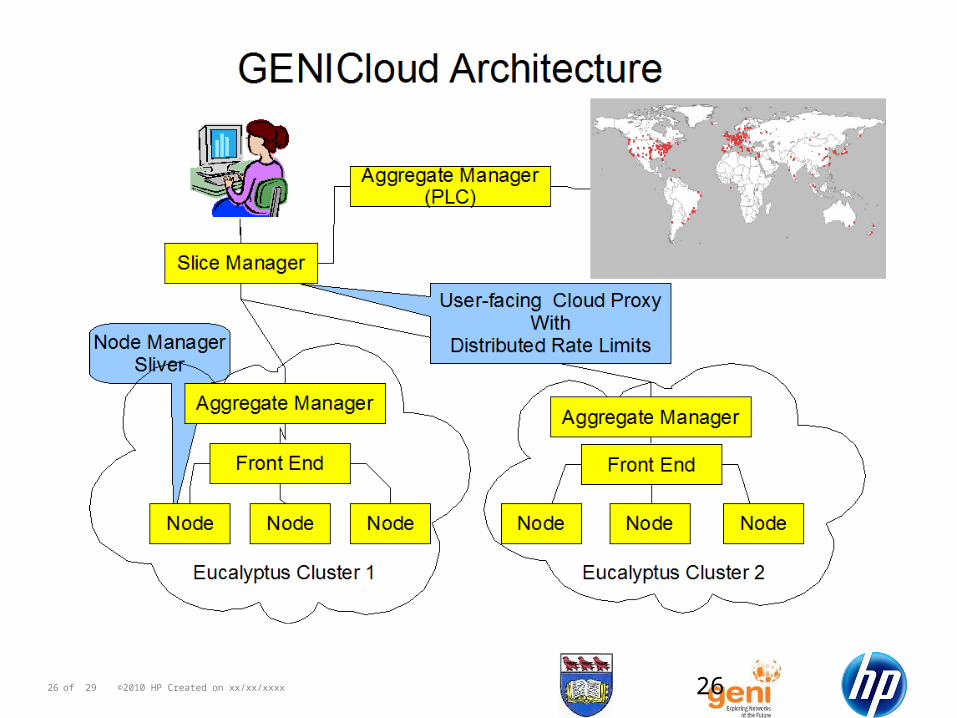
26 ©2010 HP Created on xx/xx/xxxxof 29 26

27 ©2010 HP Created on xx/xx/xxxxof 29 27
OUTLINE
– The problem of big data
– How to build the world’s greatest digital library
– How to build the world’s greatest decision support engine
– The building blocks• Virtualization: VMs, PlanetLab, Seattle
• Programming Paradigms: MapReduce, Hadoop, Pig
– Next Steps and a Plan

28 ©2010 HP Created on xx/xx/xxxxof 29 28
CAN IT WORK?
– Only way to find out is to try it
– Build it, and see what happens
– Build one or more cloud cluster(s) and operate it (them) 24/7• Euclayptus node manager
• Walrus storage instance
• Cassandra distributed file system
• Standard image featuring MapReduce scheduler as a minimum
• Pig queries as a maximum
• Load it up with operational datasets− Neptune, Herzberg, others?
– Invite scientists to use it
– Find out problems, fix them, make it work

29 ©2010 HP Created on xx/xx/xxxxof 29
THANKS!
















![Revised: December 20, 1999 · Web viewJohn Deere xxx-xxx 1234 06/08/2016 Not Reported xx hp FL-XX [Choose which applies:] [Emergency Flare Pilot/Purge Emissions or Emergency Flare](https://static.documents.pub/doc/80x56/5aa547927f8b9a2f048d3553/revised-december-20-1999-viewjohn-deere-xxx-xxx-1234-06082016-not-reported-xx.jpg)
