2Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
2
Agenda
Motivation II: Types of reasoning
A key concept of deductive DBs: Recursion
The process of knowledge discovery (KDD)
KDD: Origins and context
A short overview of key KDD techniques
An algorithm for decision-tree learning: ID3
Motivation I: Application examples
3Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
3
What is the impact of genetically modified organisms?
4Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
4Is our school system good for immigrants and/or children from poor backgrounds?
5Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
5
What are the effects of teaching in English at universities?
6Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
6
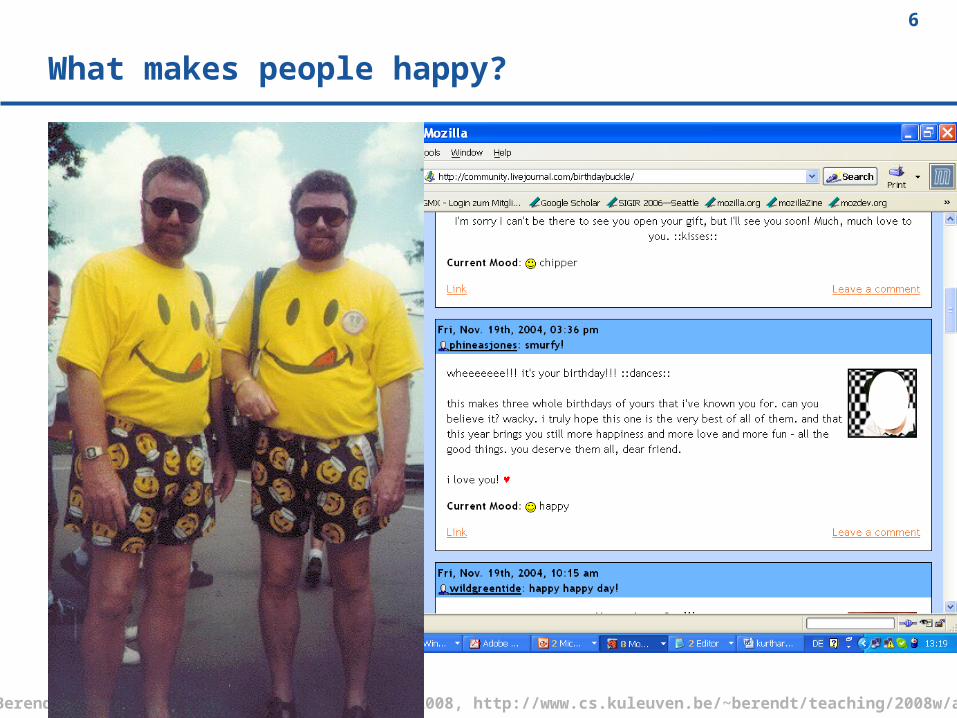
What makes people happy?
7Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
7
What do men and women like?
8Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
8
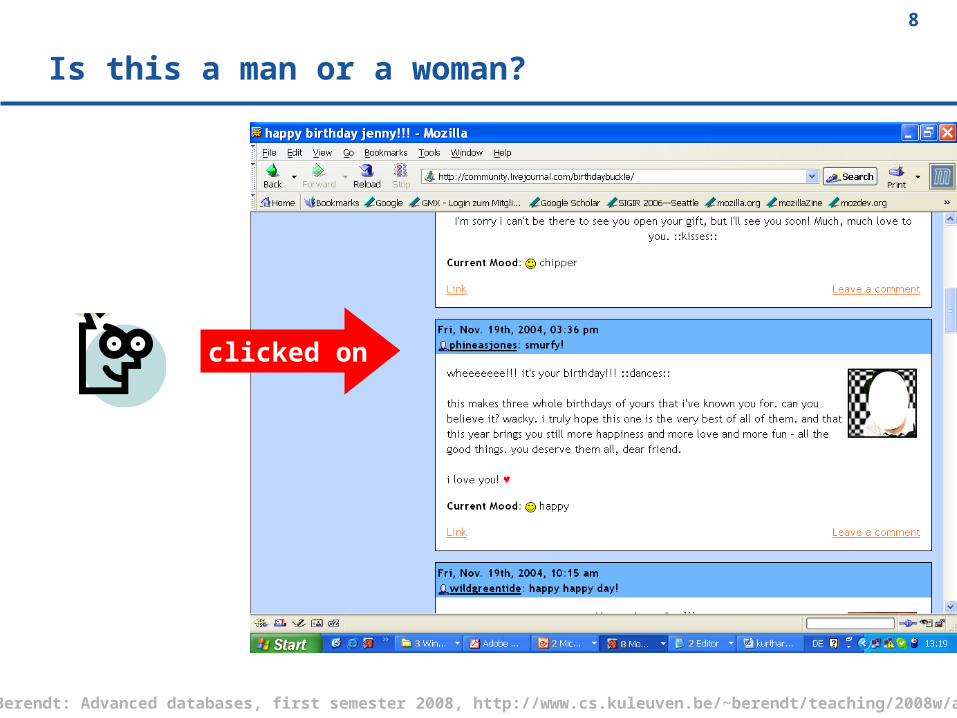
Is this a man or a woman?
clicked on
9Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
9And here‘s a somewhat speculative case ...Who owes money to whom (causing the current financial crisis)?
10Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
10
Agenda
Motivation II: Types of reasoning
A key concept of deductive DBs: Recursion
The process of knowledge discovery (KDD)
KDD: Origins and context
A short overview of key KDD techniques
An algorithm for decision-tree learning: ID3
Motivation I: Application examples
11Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
11
Deductive database languages / Datalog: Motivation
SQL-92 (= SQL2) cannot express some queries:
Are we running low on any parts needed to build a ZX600 sports car?
What is the total component and assembly cost to build a ZX600 at today's part prices??
NB: SQL saw a new version (SQL3) in 1999 and further developments since then. Some DDB concepts are used to support the advanced features of more recent SQL standards.
12Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
12
What is a deductive database (system)?
A deductive database system is a database system which can make deductions (ie: conclude additional facts) based on rules and facts stored in the (deductive) database.
13Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
13
Styles of reasoning: „All swans are white“
Deductive: towards the consequences All swans are white.
Tessa is a swan.
Tessa is white.
Inductive: towards a generalisation of observations Joe and Lisa and Tex and Wili and ... (all observed swans) are
swans.
Joe and Lisa and Tex and Wili and ... (all observed swans) are white.
All swans are white.
Abductive: towards the (most likely) explanation of an observation.
Tessa is white.
All swans are white.
Tessa is a swan.
14Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
14
What about truth?
Deductive:
Given the truth of the assumptions, a valid deduction guarantees the truth of the conclusion
Inductive:
the premises of an argument (are believed to) support the conclusion but do not ensure it
has been attacked several times by logicians and philosophers
Abductive:
formally equivalent to the logical fallacy affirming the consequent
15Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
15
What about new knowledge?
C.S. Peirce:
Introduced „abduction“ to modern logic
(after 1900): used „abduction“ to mean: creating new rules to explain new observations (this meaning is actually closest to induction)
<<Abduction is the only logical process that actually creates anything new.>>
essential for scientific discovery
16Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
16
Agenda
Motivation II: Types of reasoning
A key concept of deductive DBs: Recursion
The process of knowledge discovery (KDD)
KDD: Origins and context
A short overview of key KDD techniques
An algorithm for decision-tree learning: ID3
Motivation I: Application examples
17Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
17
Deductive databases in a Computer Science context
Deductive databases have grown out of the desire to combine logic programming with relational databases to construct systems that support a powerful formalism and are still fast and able to deal with very large datasets.
Deductive databases are more expressive than relational databases but less expressive than logic programming systems.
Deductive databases have not found widespread adoptions outside academia, but some of their concepts are used in today‘s relational databases to support the advanced features of more recent SQL standards (≥ SQL:1999).
18Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
18
Datalog
a query and rule language for deductive databases that syntactically is a subset of Prolog.
Roots in 1970s; the term Datalog was coined in the mid 1980s by a group of researchers interested in database theory.
Query evaluation is sound and complete and can be done efficiently even for large databases.
Query evaluation is usually done using bottom up strategies.
In contrast to Prolog, Datalog
disallows complex terms as arguments of predicates, e.g. P(1, 2) is admissible but not P(f1(1), 2),
imposes certain stratification restrictions on the use of negation and recursion, and
only allows range restricted variables, i.e. each variable in the conclusion of a rule must also appear in a not negated clause in the premise of this rule.
19Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
19
Deductive database languages / Datalog: Motivation
SQL-92 cannot express some queries:
Are we running low on any parts needed to build a ZX600 sports car?
What is the total component and assembly cost to build a ZX600 at today's part prices?
Can we extend the query language to cover such queries?
Yes, by adding recursion.
20Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
20
Datalog
SQL queries can be read as follows: “If some tuples exist in the From tables that satisfy the Where conditions, then the Select tuple is in the answer.”
Datalog is a query language that has the same if-then flavor:
New: The answer table can appear in the From clause, i.e., be defined recursively.
Prolog style syntax is commonly used.
21Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
21
Example
Find the components of a trike?
We can write a relational algebra query to compute the answer on the given instance of Assembly.
But there is no R.A. (or SQL-92) query that computes the answer on all Assembly instances.
trike wheel 3
trike frame 1
frame seat 1
frame pedal 1
wheel spoke 2
wheel tire 1
tire rim 1
tire tube 1
Assembly instancep
art
su
bp
art
nu
mb
er
trike
wheel frame
spoke tire seat pedal
rim tube
3 1
2 1 1 1
1 1
22Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
22
The Problem with Relational Algebra and SQL-92
Intuitively, we must join Assembly with itself to deduce that trike contains spoke and tire.
Takes us one level down Assembly hierarchy.
To find components that are one level deeper (e.g., rim), need another join.
To find all components, need as many joins as there are levels in the given instance!
For any relational algebra expression, we can create an Assembly instance for which some answers are not computed by including more levels than the number of joins in the expression!
23Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
Can read the second rule as follows:“For all values of Part, Subpt and Qty, if there is a tuple (Part, Part2, Qty) in Assembly and a tuple (Part2, Subpt) in Comp, then there must be a tuple (Part, Subpt) in Comp.”
head of rule body of ruleimplication
24Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
24
Using a Rule to Deduce New Tuples
Each rule is a template: by assigning constants to the variables in such a way that each body “literal” is a tuple in the corresponding relation, we identify a tuple that must be in the head relation.
By setting Part=trike, Subpt=wheel, Qty=3 in the first rule, we can deduce that the tuple <trike,wheel> is in the relation Comp.
This is called an inference using the rule.
Given a set of tuples, we apply the rule by making all possible inferences with these tuples in the body.
25Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
25
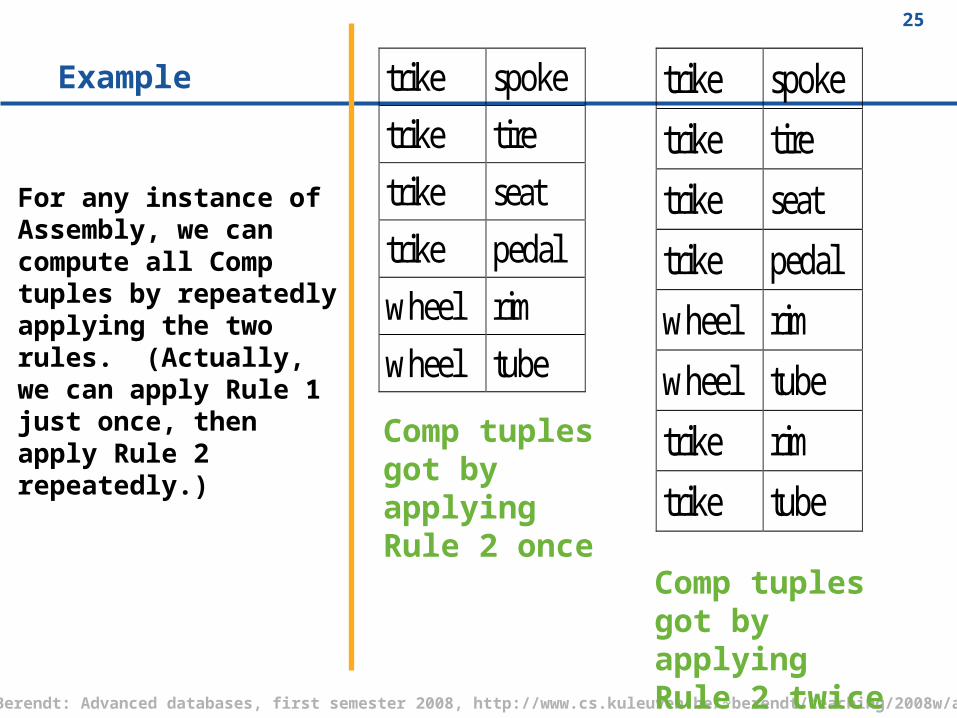
Example
For any instance of Assembly, we can compute all Comp tuples by repeatedly applying the two rules. (Actually, we can apply Rule 1 just once, then apply Rule 2 repeatedly.)
trike spoke
trike tire
trike seat
trike pedal
wheel rim
wheel tube
trike spoke
trike tire
trike seat
trike pedal
wheel rim
wheel tube
trike rim
trike tube
Comp tuples got by applying Rule 2 twice
Comp tuples got by applying Rule 2 once
26Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
26
Datalog vs. SQL:1999 (SQL3) notation
A collection of Datalog rules can be rewritten in SQL syntax, if recursion is allowed (this is the case in SQL:1999).
WITH RECURSIVE Comp(Part, Subpt) AS(SELECT A1.Part, A1.Subpt FROM Assembly A1)UNION(SELECT A2.Part, C1.Subpt FROM Assembly A2, Comp C1 WHERE A2.Subpt=C1.Part)
SELECT * FROM Comp
27Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
27
Agenda
Motivation II: Types of reasoning
A key concept of deductive DBs: Recursion
The process of knowledge discovery (KDD)
KDD: Origins and context
A short overview of key KDD techniques
An algorithm for decision-tree learning: ID3
Motivation I: Application examples
28Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
28
„Data mining“ and „knowledge discovery“
(informal definition):
data mining is about discovering knowledge in (huge amounts of) data
Therefore, it is clearer to speak about “knowledge discovery in data(bases)”
29Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
29
Recall: Data, information, and knowledge
Data represents a fact or statement of event
without relation to other things. Ex: It is raining.
Information embodies the understanding of a relationship of some sort, possibly cause and effect.
Ex: The temperature dropped 15 degrees and then it started raining.
Knowledge represents a pattern that connects and generally provides a high level of predictability as to what is described or what will happen next.
Ex: If the humidity is very high and the temperature drops substantially the atmospheres is often unlikely to be able to hold the moisture so it rains.
(This is from knowledge-management theory. If you want to know about wisdom, check the Web page:
G. Bellinger, D. Castro, & A. Mills: Data, Information, Knowledge, and Wisdom. http://www.systems-thinking.org/dikw/dikw.htm )
30Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
30
Why Data Mining?
The Explosive Growth of Data: from terabytes to petabytes
Data collection and data availability
Automated data collection tools, database systems, Web, computerized
Data mining, data warehousing, multimedia databases, and Web databases
2000s
Stream data management and mining
Data mining and its applications
Web technology (XML, data integration) and global information systems
32Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
32A note on: Data Warehousing for finding implicit knowledge in data – and why I don‘t include this in the course (now)
33Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
33
The KDD process
The non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data - Fayyad, Platetsky-Shapiro, Smyth (1996)
non-trivial process
Multiple process
valid Justified patterns/models
novel Previously unknown
useful Can be used
understandableby human and machine
34Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
34
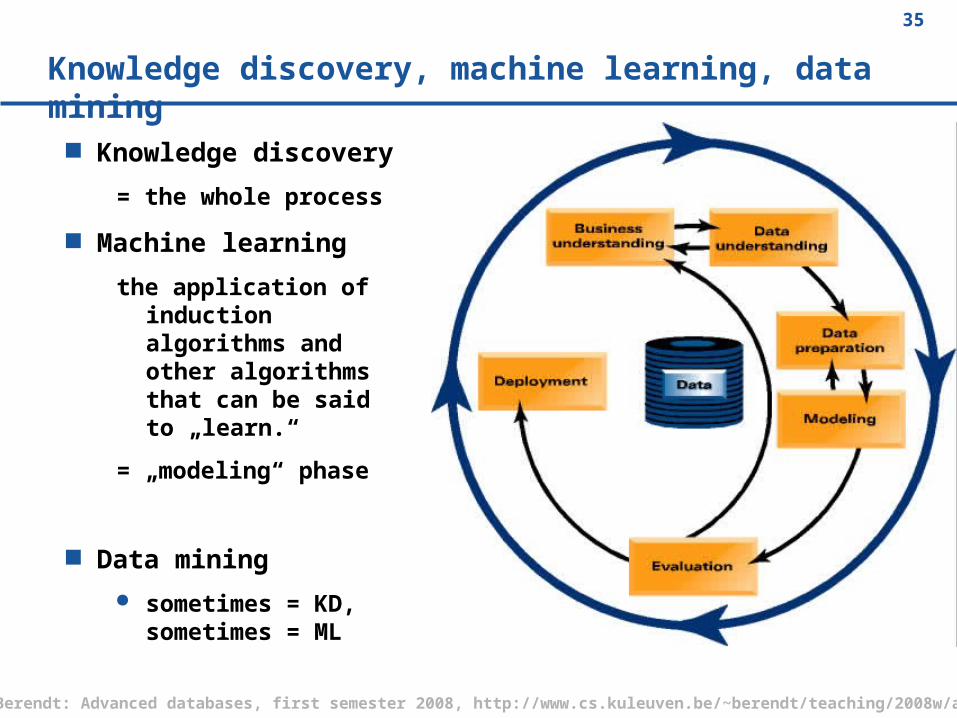
The process part of knowledge discovery
CRISP-DM • CRoss Industry Standard Process for Data Mining• a data mining process model that describes commonly used approaches that expert data miners use to tackle problems.
35Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
35
Knowledge discovery, machine learning, data mining
Knowledge discovery
= the whole process
Machine learning
the application of induction algorithms and other algorithms that can be said to „learn.“
= „modeling“ phase
Data mining
sometimes = KD, sometimes = ML
36Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
44Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
44
If Color = light and Tails = 1 and Nuclei = 2Then Healthy Cell (certainty = 92%)
If Color = dark and Tails = 2 and Nuclei = 2Then Cancerous Cell (certainty = 87%)
Classification: Rule Induction“What factors determine whether a cell is cancerous?”
45Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
45
Color = dark
Color = light
healthy
Classification: Decision Trees
#nuclei=1
#nuclei=2
#nuclei=1
#nuclei=2
#tails=1 #tails=2
cancerous
cancerous healthy
healthy
#tails=1 #tails=2
cancerous
46Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
46
Healthy
Cancerous
“What factors determine whether a cell is cancerous?”
Classification: Neural Networks
Color = dark
# nuclei = 1
…
# tails = 2
47Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
47
“Are there clusters of similar cells?”
Light color with 1 nucleus
Dark color with 2 tails 2 nuclei
1 nucleus and 1 tail
Dark color with 1 tail and 2 nuclei
Clustering
48Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
48
Task: Discovering association rules among items in a transaction database.
An association among two items A and B means that the presence of A in a record implies the presence of B in the same record: A => B.
In general: A1, A2, … => B
Association Rule DiscoveryAssociation Rule Discovery
Association Rule DiscoveryAssociation Rule Discovery
49Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
49
“Are there any associations between the characteristics of the cells?”
If color = light and # nuclei = 1 then # tails = 1 (support = 12.5%;
confidence = 50%)
If # nuclei = 2 and Cell = Cancerousthen # tails = 2 (support = 25%;
confidence = 100%)
If # tails = 1then Color = light (support =
37.5%;confidence = 75%)
Association Rule DiscoveryAssociation Rule Discovery Association Rule DiscoveryAssociation Rule Discovery
50Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
50
Genetic Algorithms
StatisticsBayesian Networks
Rough Sets Time Series
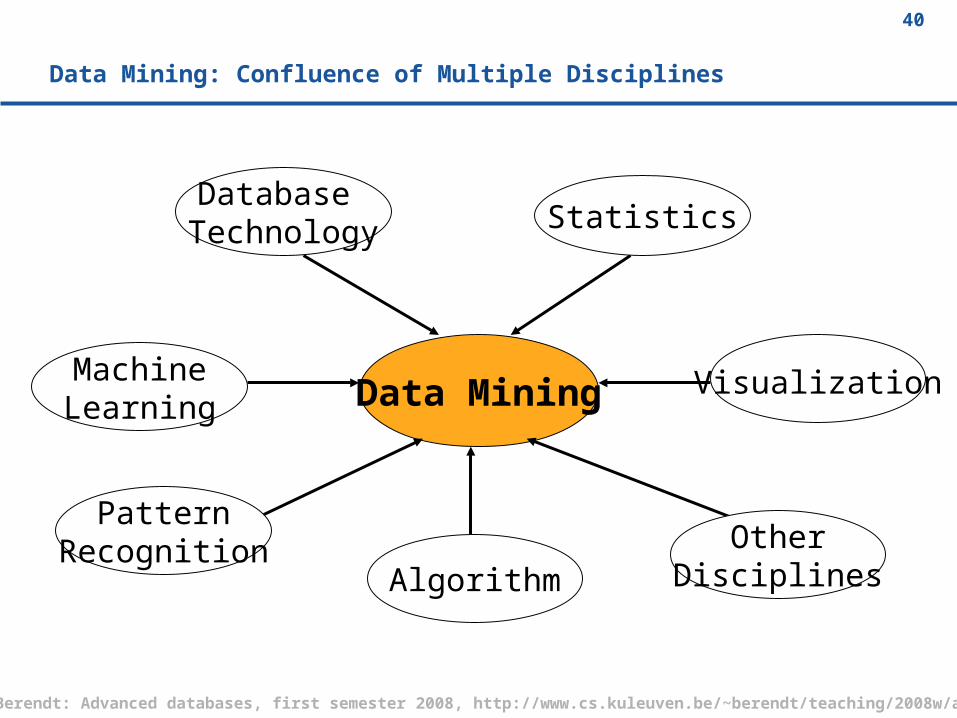
Many Other Data Mining Techniques
Text Mining
51Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
51A goal: From databases to deductive databases to inductive databases
A deductive database system is a database system which can make deductions (ie: conclude additional facts) based on rules and facts stored in the (deductive) database.
inductive databases
contain not only data, but also patterns.
In an IDB, inductive queries can be used to generate (mine), manipulate, and apply patterns.
The IDB framework supports the process of knowledge discovery in databases (KDD):
– the results of one (inductive) query can be used as input for another
– nontrivial multi-step KDD scenarios can be supported, rather than just single data mining operations.
52Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
52
Agenda
Motivation II: Types of reasoning
A key concept of deductive DBs: Recursion
The process of knowledge discovery (KDD)
KDD: Origins and context
A short overview of key KDD techniques
An algorithm for decision-tree learning: ID3
Motivation I: Application examples
53Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
53
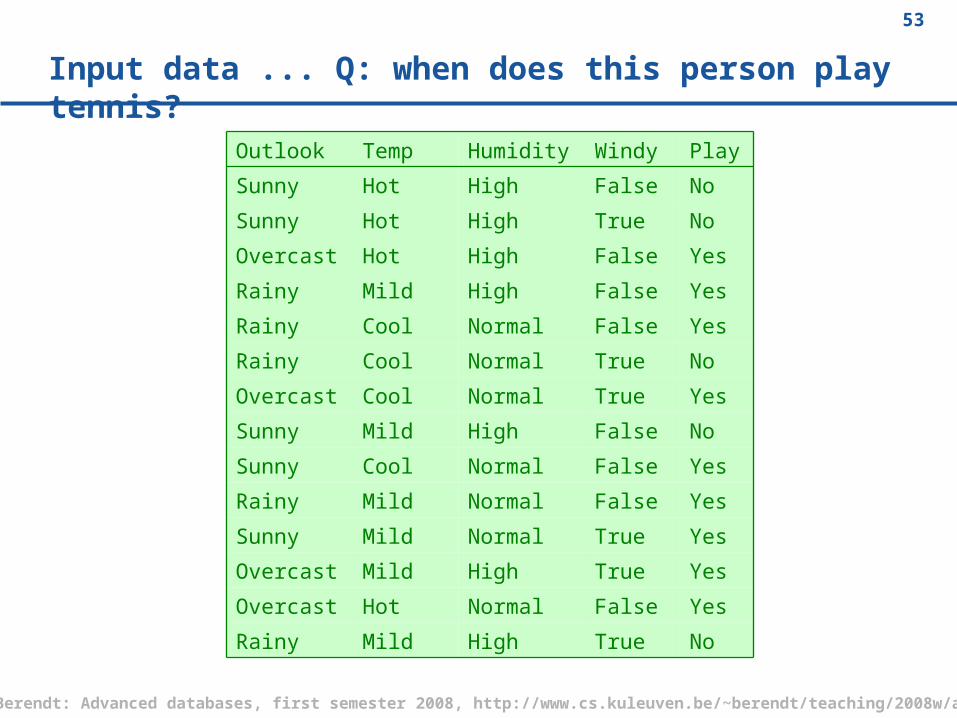
Input data ... Q: when does this person play tennis?
NoTrueHighMildRainy
YesFalseNormalHotOvercast
YesTrueHighMildOvercast
YesTrueNormalMildSunny
YesFalseNormalMildRainy
YesFalseNormalCoolSunny
NoFalseHighMildSunny
YesTrueNormalCoolOvercast
NoTrueNormalCoolRainy
YesFalseNormalCoolRainy
YesFalseHighMildRainy
YesFalseHighHot Overcast
NoTrueHigh Hot Sunny
NoFalseHighHotSunny
PlayWindyHumidityTempOutlook
54Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
54
The goal: a decision tree for classification / prediction
In which weather
will someone play (tennis etc.)?
55Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
55
Constructing decision trees
Strategy: top downRecursive divide-and-conquer fashion
First: select attribute for root nodeCreate branch for each possible attribute value
Then: split instances into subsetsOne for each branch extending from the node
Finally: repeat recursively for each branch, using only instances that reach the branch
Stop if all instances have the same class
56Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
56
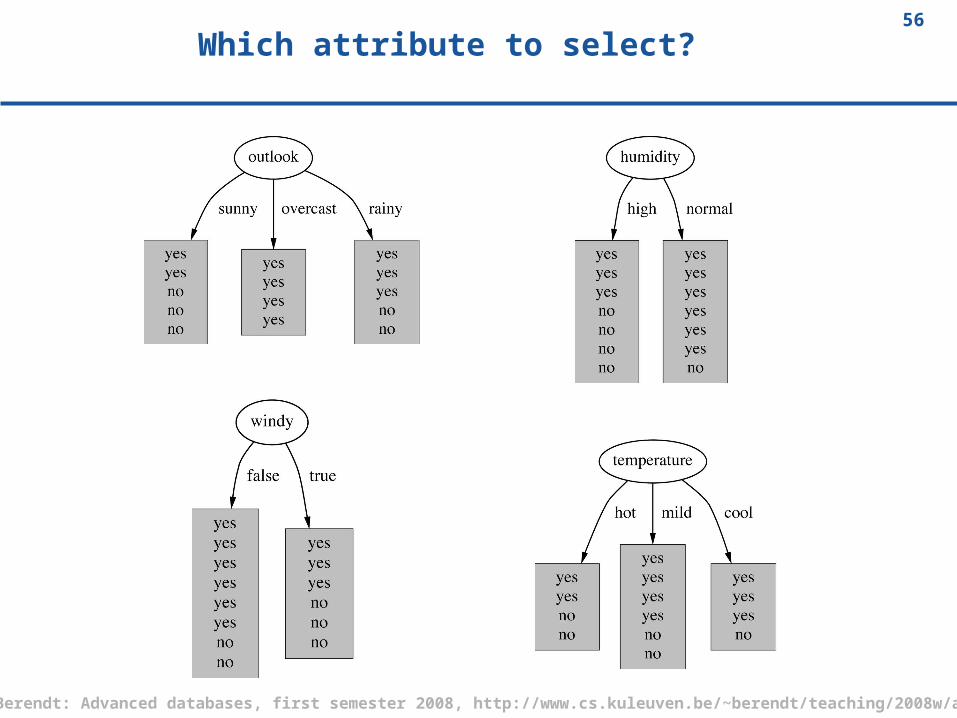
Which attribute to select?
57Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
57
Which attribute to select?
58Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
58
Criterion for attribute selection
Which is the best attribute? Want to get the smallest tree Heuristic: choose the attribute that
produces the “purest” nodes Popular impurity criterion: information
gain Information gain increases with the
average purity of the subsets Strategy: choose attribute that gives
greatest information gain
59Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
59
Computing information
Measure information in bits Given a probability distribution, the info
required to predict an event is the distribution’s entropy
Entropy gives the information required in bits(can involve fractions of bits!)
Formula for computing the entropy:
60Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
63Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
63
Final decision tree
Note: not all leaves need to be pure; sometimes identical instances have different classes
Splitting stops when data can’t be split any further
64Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
64
Wishlist for a purity measure
Properties we require from a purity measure:
When node is pure, measure should be zero When impurity is maximal (i.e. all classes
equally likely), measure should be maximal Measure should obey multistage property
(i.e. decisions can be made in several stages):
Entropy is the only function that satisfies all three properties!
65Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
65
Properties of the entropy
The multistage property:
Simplification of computation:
Note: instead of maximizing info gain we could just minimize information
66Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
66
Discussion / outlook decision trees
Top-down induction of decision trees: ID3, algorithm developed by Ross Quinlan
Various improvements, e.g. C4.5: deals with numeric attributes, missing values, noisy data Gain ratio instead of information gain [see Witten & Frank slides, ch. 4, pp. 40-45]
Similar approach: CART …
67Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
67
Agenda
Motivation II: Types of reasoning
A key concept of deductive DBs: Recursion
The process of knowledge discovery (KDD)
KDD: Origins and context
A short overview of key KDD techniques
An algorithm for decision-tree learning: ID3
Motivation I: Application examples
Mining semistructured and unstructured data
68Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
68
References / background reading
Knowledge discovery is now an established area with some excellent general textbooks. I recommend the following as examples of the 3 main perspectives:
a databases / data warehouses perspective: Han, J. & Kamber, M. (2001). Data Mining: Concepts and Techniques. San Francisco,CA: Morgan Kaufmann. http://www.cs.sfu.ca/%7Ehan/dmbook
a machine learning perspective: Witten, I.H., & Frank, E. (2005). Data Mining. Practical Machine Learning Tools and Techniques with Java Implementations. 2nd ed. Morgan Kaufmann. http://www.cs.waikato.ac.nz/%7Eml/weka/book.html
a statistics perspective: Hand, D.J., Mannila, H., & Smyth, P. (2001). Principles of Data Mining. Cambridge, MA: MIT Press. http://mitpress.mit.edu/catalog/item/default.asp?tid=3520&ttype=2
The CRISP-DM phase model can be found at http://www.crisp-dm.org
69Berendt: Advanced databases, first semester 2008, http://www.cs.kuleuven.be/~berendt/teaching/2008w/adb/
69
Acknowledgements p. 12, 17: http://en.wikipedia.org/wiki/Deductive_database pp. 14, 15: http://en.wikipedia.org/wiki/Abductive_reasoning p. 18: http://en.wikipedia.org/wiki/Datalog pp. 19-26 taken from (with minor modifications):
Ramakrishnan, R. & Gehrke, J. (2002?). Database Management Systems, 3rd Edition 2002. Instructor Slides. Ch. 25 - Deductive Databases. http://pages.cs.wisc.edu/~dbbook/openAccess/thirdEdition/slides/slides3ed-english/Ch25_DedDB-95.pdf
pp. 33, 36, 38, 43-50 were taken from (with minor modifications): Tzacheva, A.A. (2006). SIMS 422. Knowledge Inference Systems & Applications.
The ID3 part is based on Witten, I.H., & Frank, E.(2005). Data Mining. Practical Machine Learning Tools and Techniques
with Java Implementations. 2nd ed. Morgan Kaufmann. http://www.cs.waikato.ac.nz/%7Eml/weka/book.html
In particular, the instructor slides for that book available at http://books.elsevier.com/companions/9780120884070/ (chapters 1-4):http://books.elsevier.com/companions/9780120884070/revisionnotes/01~PDFs/chapter1.pdf (and ...chapter2.pdf, chapter3.pdf, chapter4.pdf) or









































































![1 Bettina Berendt KU Leuven, Dept. of Computer Science, Hypermedia & Databases berendt 3 December 2007 [updated version] Intelligent.](https://static.documents.pub/doc/80x56/56649e5c5503460f94b53c9e/1-bettina-berendt-ku-leuven-dept-of-computer-science-hypermedia-databases.jpg)



