45
1 Friday, November 17, 2006 “In the confrontation between the stream and the rock, the stream always wins, not through strength but by perseverance.” - H. Jackson Brown
| Date post: | 20-Dec-2015 |
| Category: |
Documents |
| View: | 214 times |
| Download: | 0 times |

1
Friday, November 17, 2006
“In the confrontation between the stream and the rock,
the stream always wins, not through strength but by perseverance.”
- H. Jackson Brown

2
Bubble Sort
Sequential bubble sort algorithm.

3
2 5 8 1 4 6
2 5 8 1 4 6
Bubble Sort

4
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
Bubble Sort

5
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
Bubble Sort

6
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
2 5 1 8 4 6
Bubble Sort

7
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
2 5 1 8 4 6
2 5 1 4 8 6
Bubble Sort

8
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
2 5 1 8 4 6
2 5 1 4 8 6
2 5 1 4 6 8
Complexity?
Bubble Sort

9
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
2 5 8 1 4 6
2 5 1 8 4 6
2 5 1 4 8 6
2 5 1 4 6 8
O(n2)
Inherently sequential
Bubble Sort

10
Odd-Even Transposition
Sorting n = 8 elements, using the odd-even transposition sort algorithm.

11
Odd-Even Transposition
Sequential odd-even transposition sort algorithm.
Complexity?

12
8 7 6 5 4 3 2 1
7 8 5 6 3 4 1 2
7 5 8 3 6 1 4 2
5 7 3 8 1 6 2 4
5 3 7 1 8 2 6 4
3 5 1 7 2 8 4 6
3 1 5 2 7 4 8 6
1 3 2 5 4 7 6 8
1 2 3 4 5 6 7 8
Odd
Even
Odd
Even
Odd
Even
Odd
Even
Odd

13
Odd-Even
After n phases of odd-even exchanges, the sequence is sorted.
Each phase of the algorithm (either odd or even) requires Θ(n) comparisons.
Serial complexity is Θ(n2).

14
Parallel Odd-Even Transposition
Consider the one item per processor case.
Assume processes are arranged in one-dimensional array.
There are n iterations, in each iteration, each processor does one compare-exchange.
The parallel run time is ?

15
Parallel Odd-Even Transposition
Consider the one item per processor case.
There are n iterations, in each iteration, each processor does one compare-exchange.
The parallel run time of this formulation is Θ(n).
Cost optimal?

16
Parallel Odd-Even Transposition Consider a block of n/p elements per
processor.
The first step is a local sort.
In each subsequent step, the compare exchange operation is replaced by the compare-split operation.
How many odd-even phases will be executed?

17
Compare Split Operation
A compare-split operation. Each process sends its block of size n/p to the other process. Each process merges the received block with its own block and retains only the appropriate half of the merged
block.

18
Parallel Odd-Even Transposition The first step is a local sort.
There are p phases.
The parallel run time of the formulation is

19
Odd Even Sorting

20
Odd Even Sorting

21
Odd Even Sorting

22
Odd Even Sorting

23
2 3 4 5 6 7 8 1
2 3 4 5 6 7 1 8
2 3 4 5 6 1 7 8
2 3 4 5 1 6 7 8
2 3 4 1 5 6 7 8
2 3 1 4 5 6 7 8
2 1 3 4 5 6 7 8
1 2 3 4 5 6 7 8
Odd
Even
Odd
Even
Odd
Even
Odd
Even

24
Shellsort
Let n be the number of elements to be sorted and p be the number of processes.
During the first phase, processes that are far away from each other in the array compare-split their elements.
During the second phase, the algorithm switches to an odd-even transposition sort.

25
0 3 4 5 6 7 2 1
0 2 4 5 6 7 3 1
0 2 4 5 1 3 7 6
0 2 4 5 1 3 6 7
An example of the first phase of parallel shellsort on an eight-process array.
Parallel
Shellsort

26
0 2 4 5 1 3 6 7
0 2 4 5 1 3 6 7
0 2 4 1 5 3 6 7
0 2 1 4 3 5 6 7
0 1 2 3 4 5 6 7
Odd
Even
Odd
Even
Odd

27
Parallel Shellsort Each process performs d = log p compare-split
operations.
With O(p) bisection width, each communication can be performed in time Θ(n/p) for a total time of Θ((nlog p)/p).
In the second phase, l odd and even phases are performed, each requiring time Θ(n/p).
The parallel run time of the algorithm is:

28
Quicksort
Quicksort selects one of the entries in the sequence to be the pivot and divides the sequence into two - one with all elements less than the pivot and other greater.
The process is recursively applied to each of the sublists.

29

30
Quicksort
The performance of quicksort depends critically on the quality of the pivot.

31
Quicksort
Parallel formulation of quick sort.
Do we start with a single process?

32
Parallel Quicksort
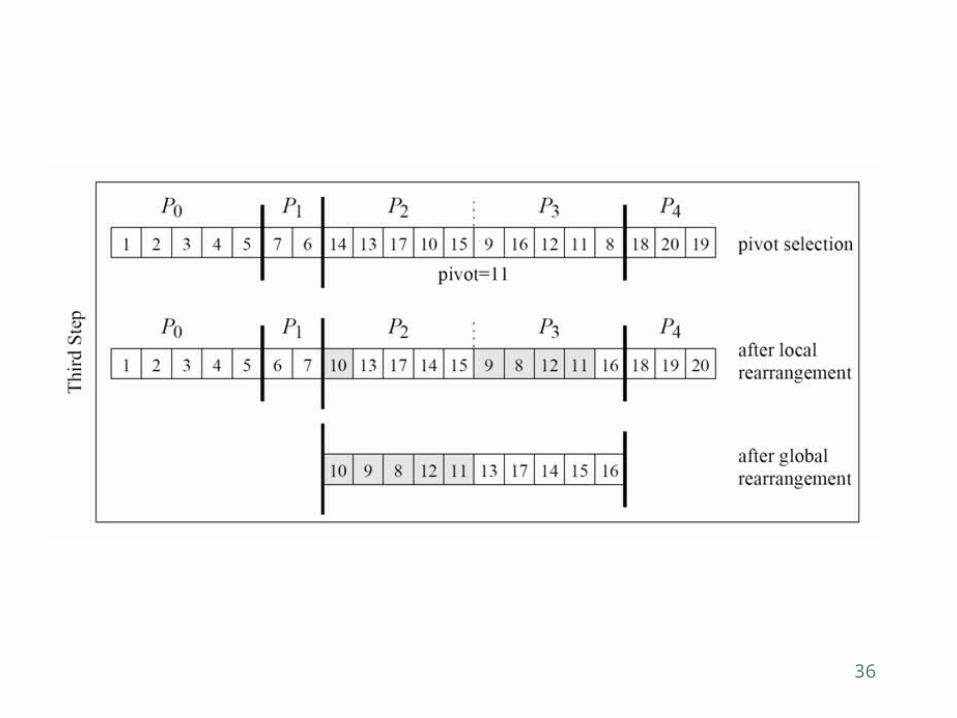
Consider a list of size n equally divided across p processors.
A pivot is selected by one of the processors and made known to all processors.
Each processor partitions its list into two, say Li and Ui, based on the selected pivot.

33
Parallel Quicksort
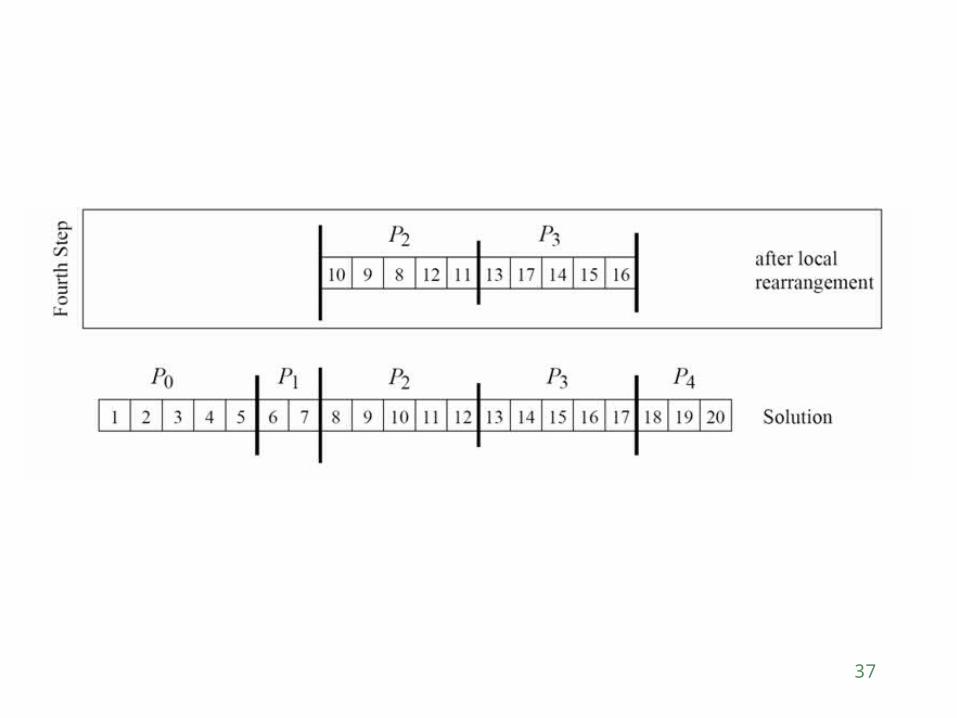
All of the Li lists are merged and all of the Ui lists are merged separately.
The set of processors is partitioned into two (in proportion of the size of lists L and U).
The process is recursively applied to each of the lists.
The recursion stops when a particular sub-block is assigned to a single process. At which point, the lists are sorted locally using serial quick sort.

34

35
36
37

38
Pivot selection

39
OpenMP and MPI
Suitable for multiprocessors?Suitable for multi-computers?

40
Combining MPI and OpenMP
Many commercial multi-computers are collections of centralized multiprocessors.

41
Combining MPI and OpenMP
Hybrid parallel program

42
Combining MPI and OpenMP
Suppose we are executing on a cluster of m multiprocessors, where each multiprocessor has k CPUs
In order to utilize every CPU, MPI program has o create mk processes During communication mk processes are active
Hybrid needs ?

43
Combining MPI and OpenMP
Suppose we are executing on a cluster of m multiprocessors, where each multiprocessor has k CPUs
In order to utilize every CPU, MPI program has o create mk processes
During communication mk processes are active
Hybrid needs m processes and workload is divided among k threads on each multiprocessor.

44
Combining MPI and OpenMP
Suppose we are executing on a cluster of m multiprocessors, where each multiprocessor has k CPUs
In order to utilize every CPU, MPI program has o create mk processes
During communication mk processes are activeHybrid needs m processes and workload is divided
among k threads on each multiprocessor. Lower communication overhead

45
Combining MPI and OpenMP
Suppose a serial program executes in 100 seconds.
5 seconds in inherently sequential operations.
90 seconds are perfectly parallelizable.Remaining 5 percent can be done in parallel
but has a large communication overhead so we replicate these operations.

















