3D Computer Simulation of the Human Vocal Tract Towards an Extensible Infrastructure for a Three- dimensional Face and Vocal-Tract Model Sid Fels, ECE, Bryan Gick, Linguistics n Vogt, ECE, Ian Wilson, Linguistics, Carol Jae University of British Columbia Vancouver, BC, Canada V6T 1Z4
Transcript
3D Computer Simulation of the Human Vocal Tract
Towards an Extensible Infrastructure for a Three-dimensional Face and Vocal-Tract Model
Sid Fels, ECE, Bryan Gick, LinguisticsFlorian Vogt, ECE, Ian Wilson, Linguistics, Carol Jaeger, ECE
University of British ColumbiaVancouver, BC, Canada
V6T 1Z4
Introduction and Motivation
• Want speech synthesis that is:– low bandwidth, – high quality,– visually coordinated, – physically based,– real-time
• Important developments– computational speed increases– new imaging techniques– better understanding of vocal tract
• Interesting history– sometimes hot (1700s, 2000) and
sometimes not (1800s, 1970-1980s)
• Important now because of “Talking Head” research– McGurk effect
Articulatory Synthesis: Talking Heads
• Visual and auditory signals interact– visual signal can make auditory signal hard to hear
• McGurk Effect Demo• Talking heads important for:
– more natural interaction– dubbing new voices– compact encoding of voice and image
• Can we create good talking head from acoustic signal?– Not so easy: i.e., Bregler, Slaney and Covell– articulatory synthesis provides necessary articulatory movement
with audio waveform• see “Speech Recognition and Sensory Integration”, Massaro and Stork,
American Scientist, Vol. 86, 1998.
Articulatory Synthesis: History
• Kratzenstein resonators (1770 - Imperial Academy of St. Petersburg contest)
Articulatory Synthesis: AVTs
• von Kempelen’s AVT (1791)
Articulatory Synthesis: more T.H.
• R. R. Riesz's talking mechanism, 1937
Articulatory Synthesis: electronic AVTs
• The Voder (Dudley, Riesz and Watson, 1939)
• Example
Articulatory Synthesis: more AVTS
• Alexander G. Bell and Melville Bell– moulded human skull
• Glove-TalkII (Fels and Hinton, 1998)– uses gestural articulator model
Articulatory TTS Synthesis
• Text-to-speech possible:– Pavarobotti, National Center for
Voice and Speech, (U. Iowa) 1, 2
• See also Perry Cook’s work at Princeton (formerly at Stanford (CCRMA))
• http://www.cs.princeton.edu/~prc
• SPASM (example song)• P. R. Cook, "Synthesis of the Singing Voice Using a
Physically Parameterized Model of the Human Vocal Tract," ICMC, 1989.
Where we are going:3D Articulator Synthesis
• Creating infrastructure for research on 3D articulatory synthesis
• Use for:– speech synthesis– speech analysis– articulation analysis
Where we are at:• Developing and extending scenegraph
methodology for model specification– multi-scale and multi-level capable
• Elaborating scenegraph model based on anatomy– base-line for refinement or simplification
• Exploring techniques for synthesis– support 2D to 3D techniques– integrate source-tract models as well
• Developing measurement tools– ultrasound tongue tracking; integrate with Haskins
Articulatory Synthesis: Project Overview
• Build S/W Infrastructure to support modular approach to modeling– extrapolate and abstract from Lee, Waters
and Terzopolous work
Lee, Terzopolous, Waters, 1998 Haber, Kaehler, at al, 2002
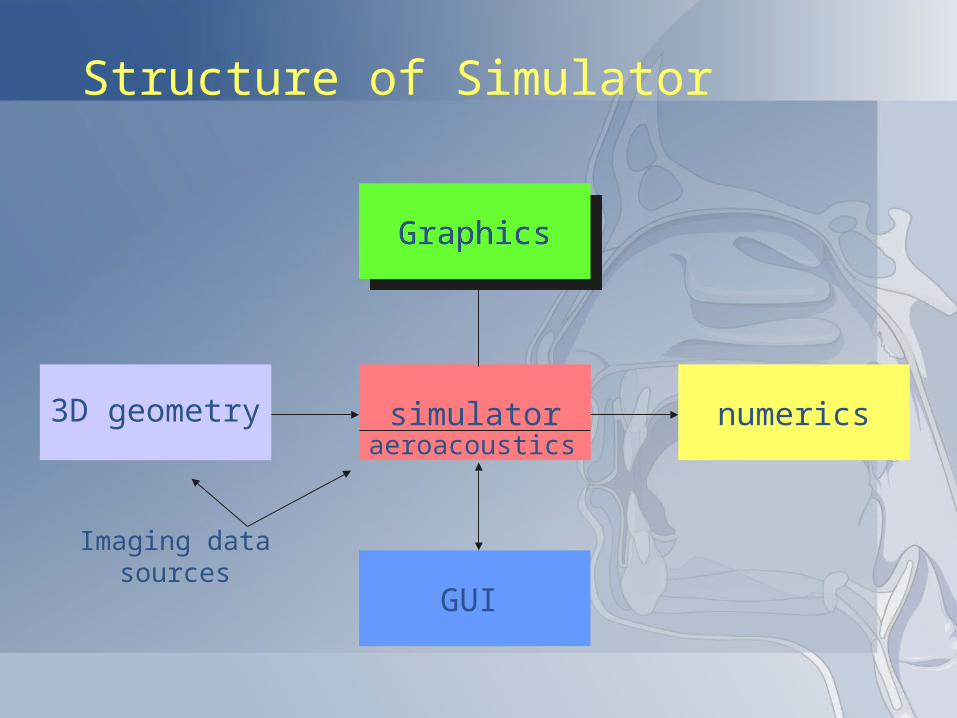
Software Architecture
• 5 main components to deal with:1. simulator engine,
2. three-dimensional geometry module
3. graphical user interface (GUI) module,
4. synthesis engine and
5. numerics engine.
Structure of Simulator
3D geometry
Graphics
simulator numerics
GUI
Imaging datasources
aeroacoustics
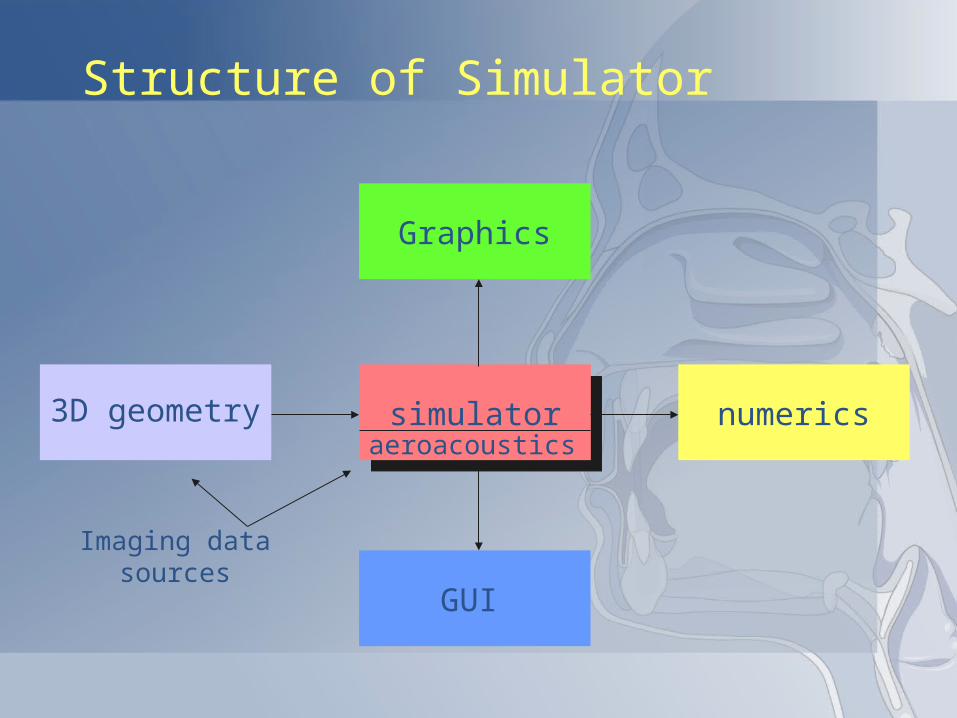
Structure of Simulator
3D geometry3D geometry
Graphics
simulator numerics
GUI
Imaging datasources
aeroacoustics
3D Geometry: Scene Graph
• Base model notation on Scene Graph– basis of 3D animation– nodes for specifying graphical models including
• shapes, cameras, lights, properties, transformation, engines, selection, view etc.
• Extend and add nodes to represent relationships– muscles, constraints, nerves, dynamics– may need multiple passes per iteration
3D Geometry: Scene Graph
• Example decomposition– Head
• Skull• Mouth
– jaw– teeth– tongue
» hyoid– cheek, other soft structures
• Pharynx• Nose• Larynx• Respiratory tract
Using Image Data
• Data from MRI, ultrasound, EMA and other imaging devices– used in real-time or offline– create geometry– provide constraints on system
Structure of Simulator
3D geometry
GraphicsGraphics
simulator numerics
GUI
Imaging datasources
aeroacoustics
Graphics
• Separate out rendering of model• Integrate with other 3D animation tools
e.g. Blender, Maya, 3DMax.
Structure of Simulator
3D geometry
Graphics
simulator numerics
GUIGUI
Imaging datasources
aeroacoustics
GUI
• Separate out to make simulation code clean• Allow multiple access points to reduce