An OpenCL Framework for Heterogeneous Multicores with Local Memory PACT 2010 Jaejin Lee, Jungwon Kim, Sangmin Seo, Seungkyun Kim, Jungho Park, Honggyu Kim, Thanh Tuan Dao, Yongjin Cho, Sung Jong Seo, Seung Hak Lee, Seung Mo Cho, Hyo Jung Song, Sang-Bum Suh, and Jong-Deok Choi School of Computer Science and Engineering, Seoul National University, Seoul 151-744, Korea Samsung Electronics Co., Nongseo-dong, Giheung-gu, Yongin-si, Geonggi- do 446-712, Korea Presenter : Jen-Jung, Cheng
Transcript
An OpenCL Frameworkfor Heterogeneous Multicores with Local
Memory
PACT 2010Jaejin Lee, Jungwon Kim, Sangmin Seo, Seungkyun Kim, Jungho Park,
Honggyu Kim, Thanh Tuan Dao, Yongjin Cho, Sung Jong Seo, Seung Hak Lee,Seung Mo Cho, Hyo Jung Song, Sang-Bum Suh, and Jong-Deok Choi
School of Computer Science and Engineering, Seoul National University, Seoul 151-744, Korea
Samsung Electronics Co., Nongseo-dong, Giheung-gu, Yongin-si, Geonggi-do 446-712, Korea
• Two major challenges in design and implementation of the OpenCL framework– Implements hundreds of virtual PEs with a single
accelerator core and make them efficient– Overcomes the limited size and incoherency of the
local store
OpenCL platform(1/2)
The OpenCL platform model
OpenCL platform(2/2)• OpenCL platform:
a host processor, compute devices, compute units, and processing elements
• Abstract Index Space:global ID, workgroup ID, and local ID
• Memory Region:private, local, constant, and global
• Synchronization:work-group barrier and command-queue barrier
OpenCL runtime(1/3)
Mapping platform components to the target architecture
OpenCL runtime(2/3)
Command Scheduler
Event Queue
Command Queues
…
Ready Queue
CU Status Array
Command Executor
Issue AssignDevice
CU
CU
CU
…
Work-groups
OpenCL
Host thread
OpenCL Runtime thread
The command scheduler and the command executor
DAG
Execution ordering
GPC
OpenCL runtime(3/3)
• The runtime implements a software-managed cache in each APC‘s local store. It caches the contents of the global and constant memory.
• To guarantee OpenCL memory consistency for shared memory objects between commands, the command executor flushes software-managed caches whenever it dequeues a command from the ready-queue or it removes an event object from the DAG after the associated command has completed.
Work-item coalescing(1/3)• Executing work-items on a CU by switching one
work-item to another incurs a significant overhead.
• When a kernel and its callee functions do not contain any barrier, any execution ordering defined between the two statements from different work-items in the same work-group satisfies the OpenCL semantics.
• Work-item coalescing loop(WCL) iterates on the index space of a single work-group.
while (1) { [t = C’; if (!t) break; [S1’ barrier(); [S2’}
Web-based variable expansion(1/5)• A kernel code region that needs to be enclosed
with a WCL is called a work-item coalescing region (WCR).
• A work-item private variable that is defined in one WCR and used in another needs a separate location for different work-items.
• A du-chain for a variable connects a definition of the variable to all uses reached by the definition.
• A web for a variable is all du-chains of the variable that contain a common use of the variable.
Web-based variable expansion(2/5)
… = x
x = … x = …
… = x
t1 = C1
x = …
x = … Entry
if (t1)while
(1)
t2 = C2
if (t2)
x = …
barrier ()
… = x… = x
x = … … = x Exit
WCR
Web-based variable expansion(3/5)
… = x
x = … x = …
… = x
t1 = C1
x = …
x = … Entry
if (t1)while
(1)
t2 = C2
if (t2)
x = …
barrier ()
… = x… = x
x = … … = x Exit
WCR
Identifying du-chains
Web-based variable expansion(4/5)
… = x
x = … x = …
… = x
t1 = C1
x = …
x = … Entry
if (t1)while
(1)
t2 = C2
if (t2)
x = …
barrier ()
… = x… = x
x = … … = x Exit
WCR
Identifying webs
Web-based variable expansion(5/5)
=x1[][][]
x = … x = …
… = x
t1 = C1
x1[][][]=
x1[][][]= x1=malloc()
if (t1)while
(1)
t2 = C2
if (t2)
x1[][][]=
barrier ()
=x1[][][] =x1[][][]
x = … … = x Free(x1)
WCR
Exit
Entry
After variable expansion
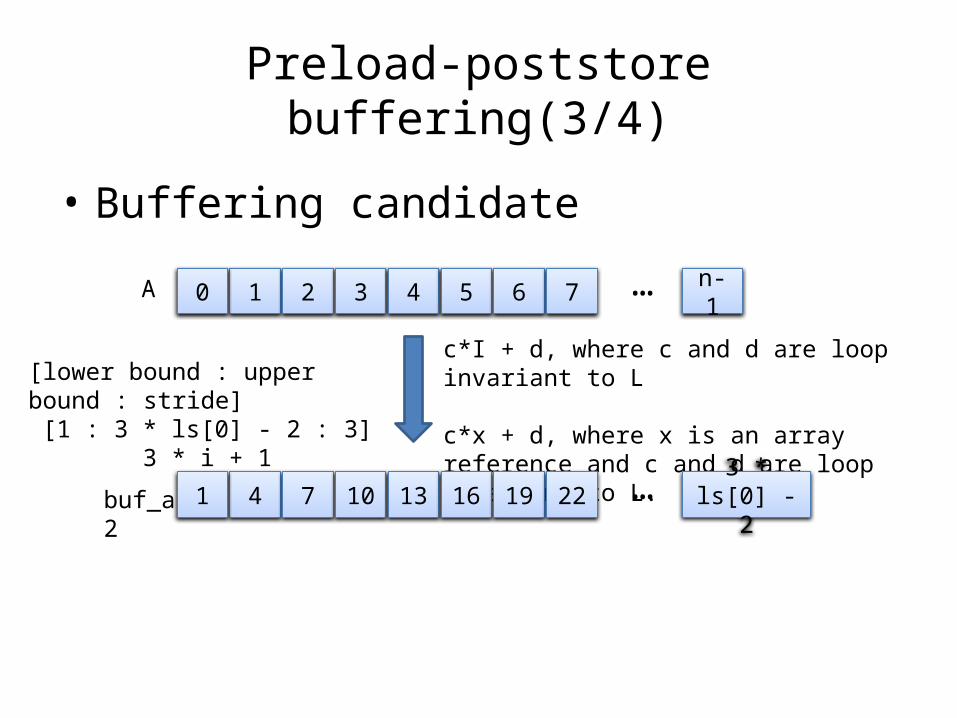
Preload-poststore buffering(1/4)
• Preload-poststore buffering enables gathering DMA transfers together for array accesses and minimizes the time spent waiting for them to complete by overlapping them.
• Condition for single buffer– a loop-independent flow dependence
(read-after-write)– a loop-independent output dependence
(write-after-write)
Evaluation(1/5)
• Experimental Setup– an IBM QS22 Cell blade server with two 3.2GHz
PowerXCell 8i processors.– The Cell BE processor consists of a single Power
Processor Element (PPE) and eight Synergistic Processor Elements (SPEs).
– Fedora Linux 9– SPE has 256KB of local store
Evaluation(2/5)
Applications used
Evaluation(3/5)
speedup
Evaluation(4/5)
Comparison with the IBM OpenCL framework for Cell BE.
Evaluation(5/5)
• two Intel Xeon X5660 hexa-core processors (CPU)
• an NVIDIA Tesla C1060 GPU (GPU).
The speedup of the OpenCL applications with multicore CPUs and a GPU.
Conclusion
• This paper presents the design and implementation of an OpenCL runtime and OpenCL C source-to-source translator that target heterogeneous accelerator multicore architectures with local memory.